Optimizing Teacher-Student Partitioning for Scalable Knowledge Distillation on HPC Systems
Pith reviewed 2026-06-29 03:02 UTC · model grok-4.3
The pith
Decoupling teacher and student partitioning in knowledge distillation yields up to 67% higher samples-per-second than symmetric methods on HPC systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that an HPC-aware methodology for knowledge distillation decouples teacher and student partitioning, combines vertical and horizontal model splits, and derives an analytical expression for inflection points between the regimes; when the best strategy is selected this way, the approach achieves up to 67% higher samples-per-second than TRL by eliminating redundant teacher-model data structures and applying topology-aware parallelism on production HPC clusters.
What carries the argument
The analytical expression that locates inflection points between vertical and horizontal splitting regimes, which selects the optimal partitioning strategy for asymmetric teacher-student models.
If this is right
- Avoiding unnecessary teacher-model data structures directly raises samples-per-second throughput.
- Topology-aware parallelism becomes effective once teacher and student partitions are chosen independently.
- The inflection-point expression removes the need for exhaustive search over split strategies.
- GKD training scales better on production HPC clusters without changes to the underlying distillation loss.
Where Pith is reading between the lines
- The same decoupling logic could extend to other compression methods that pair large and small models, such as pruning or quantization-aware training.
- If the inflection expression depends on measured communication costs, it could be recomputed at runtime for dynamic cluster conditions.
- The approach suggests that future KD frameworks should expose separate partitioning APIs rather than assume symmetric data-parallel layouts.
Load-bearing premise
The derived analytical expression for inflection points between vertical and horizontal splitting regimes will continue to identify the optimal strategy on hardware and model sizes different from the tested production clusters.
What would settle it
Measuring actual optimal splits versus the expression's predictions on a different HPC cluster with altered interconnect latency or on models substantially larger or smaller than those tested.
Figures
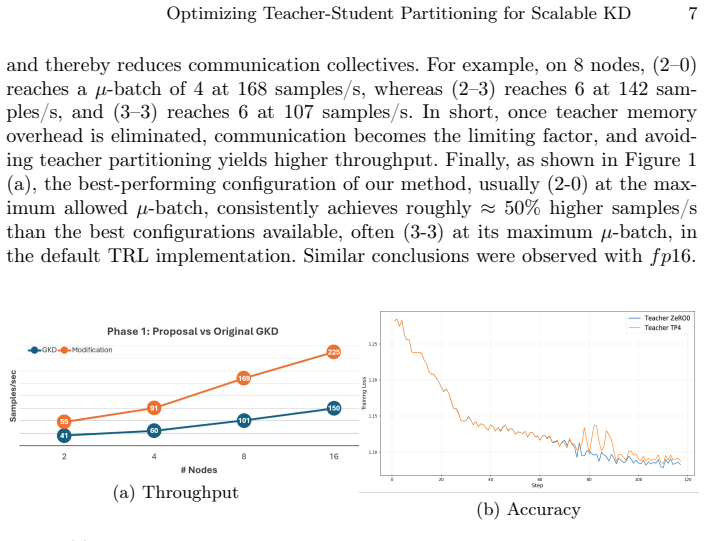
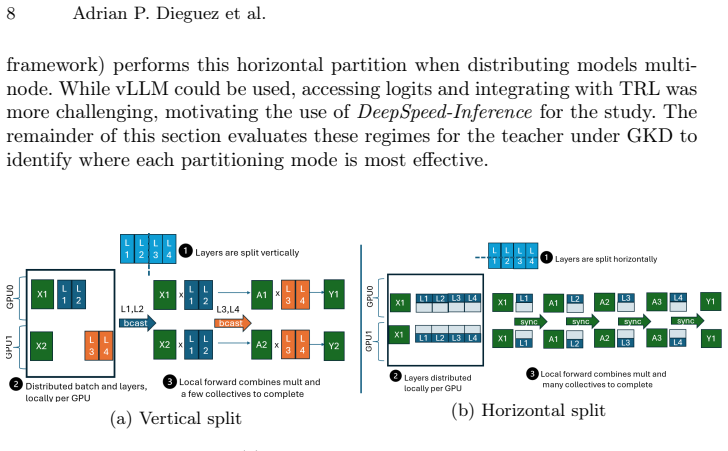
read the original abstract
Knowledge Distillation (KD) enables training smaller student models under the guidance of larger teacher models, and the widely adopted TRL library implements it. Yet, TRL treats both models symmetrically, missing opportunities to exploit their pronounced asymmetry in memory footprint, and communication requirements. This paper presents an HPC-aware methodology for KD that decouples teacher and student partitioning efficiently. Our approach achieves up to 67% higher samples-per-second than TRL by avoiding unnecessary teacher-model data structures and selecting the best split strategy. We combine vertical and horizontal partitioning of models, deriving an analytical expression that identifies the existence of inflection points between splitting regimes. These results showed that exploiting teacher--student asymmetry through topology-aware parallelism notably accelerated GKD training on production HPC clusters at our company
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that by decoupling teacher and student partitioning in knowledge distillation using a combination of vertical and horizontal splits on HPC systems, and using a derived analytical expression to identify inflection points for choosing the optimal strategy, they achieve up to 67% higher samples-per-second than the TRL library. This is validated on production HPC clusters at the authors' company.
Significance. If the analytical expression for inflection points generalizes beyond the tested clusters and the performance gains are reproducible, this work could provide a valuable methodology for scalable knowledge distillation by exploiting teacher-student asymmetry in memory and communication requirements. The topology-aware parallelism is a practical contribution for large-scale training on HPC.
major comments (2)
- [§3 (Methodology)] §3 (Methodology): The analytical expression identifying inflection points between vertical and horizontal partitioning regimes is stated without derivation steps, explicit assumptions about memory footprints or interconnect characteristics, or proof of its parameter-free nature. This is load-bearing for the central claim that the expression selects the best split strategy.
- [§5 (Results)] §5 (Results): The reported 67% throughput gain lacks error bars, details on the number of runs, dataset sizes, or model dimensions used in the experiments. Without these, it is unclear whether the gain holds under the stated conditions or depends on post-hoc tuning specific to the production clusters.
minor comments (2)
- [Abstract] Abstract: The abstract mentions 'GKD training' without defining the acronym on first use.
- [Figure 2] Figure 2: The figure comparing split strategies would benefit from clearer labels on the axes indicating the inflection point location.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the methodology and experimental reporting. We address each major comment below and will revise the manuscript to improve clarity and completeness.
read point-by-point responses
-
Referee: [§3 (Methodology)] §3 (Methodology): The analytical expression identifying inflection points between vertical and horizontal partitioning regimes is stated without derivation steps, explicit assumptions about memory footprints or interconnect characteristics, or proof of its parameter-free nature. This is load-bearing for the central claim that the expression selects the best split strategy.
Authors: We agree that the derivation was insufficiently detailed. In the revised version we will expand §3 to include the full step-by-step derivation of the inflection-point expression, the explicit assumptions on memory footprints and interconnect bandwidth/latency, and a short argument establishing its parameter-free character under the stated model. This will directly support the claim that the expression selects the optimal regime. revision: yes
-
Referee: [§5 (Results)] §5 (Results): The reported 67% throughput gain lacks error bars, details on the number of runs, dataset sizes, or model dimensions used in the experiments. Without these, it is unclear whether the gain holds under the stated conditions or depends on post-hoc tuning specific to the production clusters.
Authors: We acknowledge the omission of statistical and experimental details. The revised §5 will report error bars computed over multiple independent runs, the exact number of runs, the dataset sizes employed, and the model dimensions (parameter counts and layer configurations) for both teacher and student. These additions will allow readers to assess reproducibility on the described HPC clusters. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper reports an empirical 67% throughput gain measured directly on production HPC clusters and presents a derived analytical expression for inflection points between partitioning regimes. No provided equations, self-citations, or steps reduce the reported performance numbers or the inflection-point selector to a fitted parameter or self-referential definition by construction. The central claims rest on external measurements and first-principles derivation rather than internal re-labeling of inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions about model memory footprint and communication requirements in distributed training on HPC clusters
Reference graph
Works this paper leans on
-
[1]
In: International Conference on Learning Representations (ICLR) (2024)
Agarwal, R., Vieillard, N., Zhou, Y., Stanczyk, P., Ramos, S., Geist, M., Bachem, O.: On-policy distillation of language models: Learning from self-generated mis- takes. In: International Conference on Learning Representations (ICLR) (2024)
2024
-
[2]
arXiv preprint arXiv:2207.00032 , year =
Aminabadi, R.Y., Rajbhandari, S., Zhang, M., Awan, A.A., Li, C., Li, D., Zheng, E., Rasley, J., Smith, S., Ruwase, O., He, Y.: Deepspeed inference: Enabling ef- ficient inference of transformer models at unprecedented scale. arXiv preprint arXiv:2207.00032 (2022),https://arxiv.org/abs/2207.00032
-
[3]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. arXiv (2015),https://arxiv.org/abs/1503.02531
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[4]
co/docs/trl/index(2026), accessed: Mar 10, 2026
Hugging Face: Trl — transformer reinforcement learning.https://huggingface. co/docs/trl/index(2026), accessed: Mar 10, 2026
2026
-
[5]
In: Proceedings of the 29th Symposium on Operating Systems Principles
Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C.H., Gonzalez, J., Zhang, H., Stoica, I.: Efficient memory management for large language model serving with pagedattention. In: Proceedings of the 29th Symposium on Operating Systems Principles. p. 611–626. SOSP ’23, ACM (2023)
2023
-
[6]
In: Proceedings of the International Workshop on Reproducible Research in Pattern Recognition (RRPR)
Matsubara, Y.: torchdistill: A modular, configuration-driven framework for knowl- edge distillation. In: Proceedings of the International Workshop on Reproducible Research in Pattern Recognition (RRPR). Lecture Notes in Computer Science, vol. 12636, pp. 24–44. Springer (2021)
2021
-
[7]
Dieguez et al
Microsoft: Deepspeed: Accelerating deep learning training and inference.https: //github.com/microsoft/DeepSpeed(2024), accessed: 2025-08-06 14 Adrian P. Dieguez et al
2024
-
[8]
In: Proceedings of the SC ’25 Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis
Pérez Diéguez, A., Batlle Casellas, A., Torres, A., Teague, H., Ros, J.: Pretrain- ing llms at scale: Tuning strategies and performance portability. In: Proceedings of the SC ’25 Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis. p. 1512–1523. ACM (2025)
2025
-
[9]
ArXiv (May 2020)
Rajbhandari, S., Rasley, J., Ruwase, O., He, Y.: Zero: Memory optimizations to- ward training trillion parameter models. ArXiv (May 2020)
2020
-
[10]
In: Proceedings of the 5th Workshop on Energy Efficient Machine Learning and Cognitive Computing (EMC2) at NeurIPS (2019)
Sanh, V., Debut, L., Chaumond, J., Wolf, T.: Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. In: Proceedings of the 5th Workshop on Energy Efficient Machine Learning and Cognitive Computing (EMC2) at NeurIPS (2019)
2019
-
[11]
Shoeybi, M., Patwary, M., Puri, R., LeGresley, P., Casper, J., Catanzaro, B.: Megatron-lm: Training multi-billion parameter language models using model par- allelism (2020),https://arxiv.org/abs/1909.08053
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [12]
-
[13]
In: Advances in Neural Information Processing Systems (NeurIPS) (2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems (NeurIPS) (2017)
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.