Statistical Foundations of LLM-based A/B Testing: A Surrogacy Framework for Human Causal Inference
Pith reviewed 2026-06-27 02:45 UTC · model grok-4.3
The pith
Calibrating LLM outcomes to human outcomes identifies the average treatment effect under surrogacy and comparability conditions weaker than distributional equivalence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
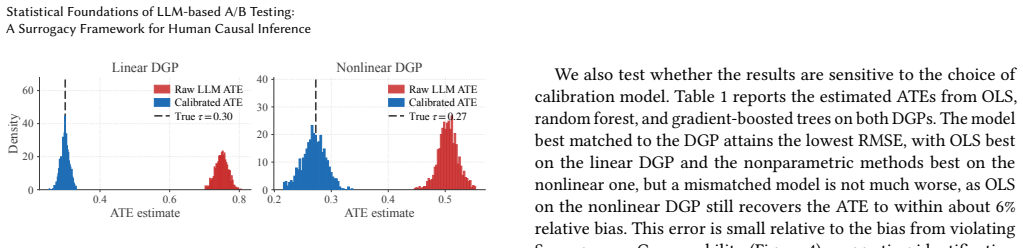
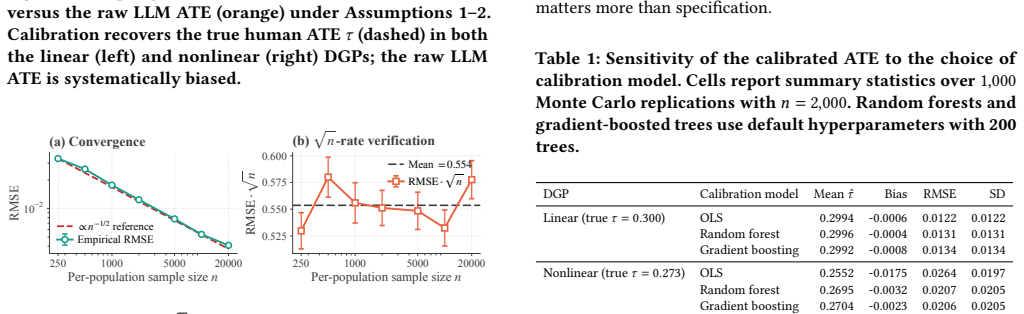
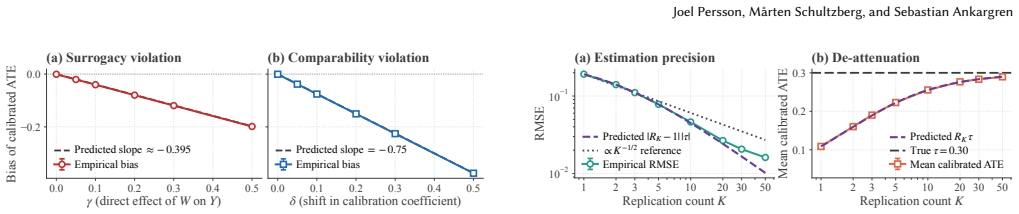
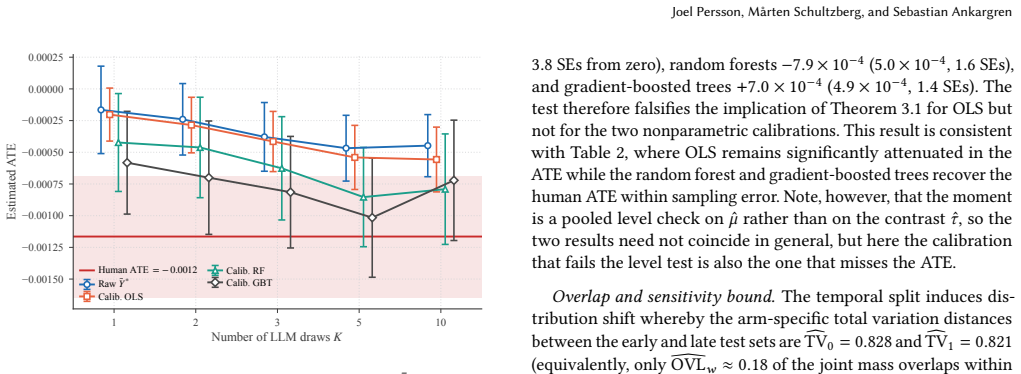
Under the surrogacy condition that the LLM outcome serves as a valid surrogate for the human outcome together with comparability conditions, calibrating LLM outcomes to human outcomes identifies the average treatment effect on the human population. These conditions are jointly weaker than distributional equivalence between LLM and human responses. The stochasticity of LLMs can weaken surrogacy and introduce estimation bias and variance, but replacing each unit's LLM outcome with an average over multiple draws restores identification and reduces those issues. A falsification test for surrogacy and a bound on worst-case bias from limited overlap are also derived.
What carries the argument
The surrogacy framework adapting classical surrogate endpoint theory to LLMs, with calibration of LLM outcomes to human outcomes as the mechanism that identifies the human average treatment effect.
If this is right
- Nonparametric calibration recovers the full human treatment effect when the surrogacy condition holds.
- A falsification test can be applied to check whether the surrogacy condition is plausible.
- Averaging multiple LLM draws per unit mitigates bias and variance introduced by LLM stochasticity.
- Bounds quantify the worst-case bias arising from limited overlap between LLM and human samples.
- Design choices such as the specific LLM, prompting strategy, and temperature setting become explicit variables that affect validity.
Where Pith is reading between the lines
- The framework implies that human pilot studies should be sized specifically to support calibration and validation rather than full-scale experiments.
- Long-term outcomes pose compounded identification challenges because surrogacy may be harder to maintain over time.
- The approach could be tested by applying it to other generative models beyond the LLMs examined in the paper.
- Where speed gains from LLMs are largest, the required human validation effort is also largest, creating a practical trade-off.
Load-bearing premise
The LLM outcome serves as a valid surrogate for the human outcome so that calibration identifies the human average treatment effect.
What would settle it
In a validation sample with both LLM and human outcomes, the calibrated LLM-based estimate of the average treatment effect differs materially from the estimate obtained directly from the human outcomes.
Figures



read the original abstract
Organizations and researchers show increasing interest in using large language models (LLMs) in place of human participants in A/B tests, in the hope of experimenting faster and at lower cost. We study when a treatment effect estimated on LLM outcomes can recover the effect for the human population of interest. Distributional equivalence between LLM and human outcomes would make any standard estimator valid but is unrealistic. We therefore develop a statistical framework that adapts surrogate endpoint theory to LLMs, showing that calibrating LLM outcomes to human outcomes identifies the average treatment effect under surrogacy and comparability conditions that are jointly weaker than distributional equivalence. We present a falsification test for surrogacy and a bound on the worst-case bias from limited overlap between the LLM and human samples. We further show that the stochasticity inherent to LLMs can weaken surrogacy for identification while also introducing bias and variance during estimation, but that using an average over multiple LLM draws per unit as the surrogate mitigates these issues. Simulations validate the results, and an empirical application to the Upworthy Research Archive dataset shows that raw LLM outputs recover only 39% of the human treatment effect while nonparametric calibration closes the gap. A central takeaway is that A/B testing on LLM responses is correct only by assumption, whereas A/B testing on humans is correct by design, and that the required assumptions are hardest to justify precisely where LLMs promise the greatest benefit. We discuss the choice of LLM, prompting, and temperature as design variables, the compounded challenge posed by long-term outcomes, and how to size human pilot studies for validation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
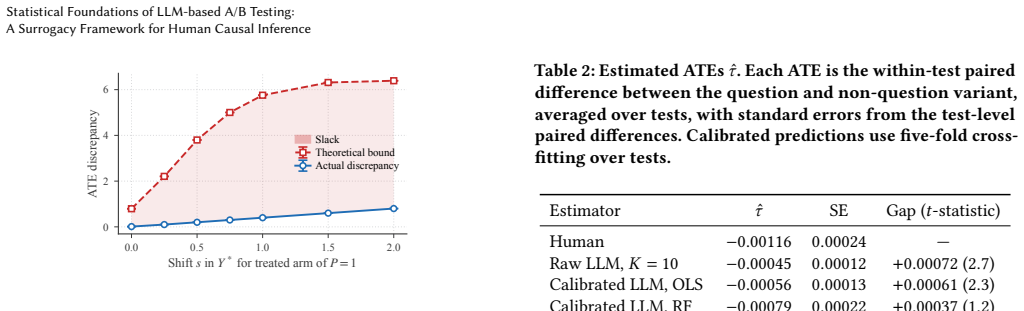
Summary. The paper develops a statistical framework adapting surrogate endpoint theory to LLM-based A/B testing. It shows that calibrating LLM outcomes to human outcomes identifies the average treatment effect under surrogacy and comparability conditions jointly weaker than distributional equivalence between LLM and human responses. The work includes a falsification test for surrogacy, a bound on worst-case bias from limited overlap, analysis showing that LLM stochasticity can violate surrogacy unless mitigated by averaging multiple draws per unit, simulations validating the results, and an empirical application to the Upworthy Research Archive dataset where raw LLM outputs recover 39% of the human treatment effect while nonparametric calibration closes the gap. The central takeaway emphasizes that LLM A/B testing is correct only by assumption, unlike human testing by design, with assumptions hardest to justify where LLMs offer greatest benefit.
Significance. If the identification results hold, the framework supplies a principled approach for using LLMs in causal experiments with explicit diagnostics and bounds, potentially enabling faster, lower-cost testing while guiding when human validation is required. Strengths include the adaptation of established surrogate theory to this setting, the provision of a falsification test and overlap bias bound as practical tools, explicit discussion of LLM design choices (model, prompt, temperature), and the empirical demonstration on public data. The simulations and 39% recovery figure provide concrete illustration of the theory. This could shape hybrid experiment design in statistics and applied fields facing data scarcity.
major comments (2)
- [Surrogacy Framework / Identification Result] The identification theorem (likely in the surrogacy framework section): while the paper correctly weakens the requirement from distributional equivalence to surrogacy plus comparability, the surrogacy condition still equates the relevant conditional expectations (or principal strata) across populations; the manuscript should include an explicit equation or proof sketch showing how the calibration mapping recovers E[Y(1) − Y(0)] exactly under these conditions, as this remains the load-bearing step.
- [Empirical Application] Empirical application section: the reported 39% recovery with raw LLM outputs and improvement via nonparametric calibration is a key validation result, but the manuscript must clarify the sample sizes for the human pilot used in calibration and whether the mapping was estimated on the same units or held-out data to confirm it does not overstate the identification gain.
minor comments (2)
- [Abstract] The abstract states the 39% figure and the role of averaging multiple LLM draws; these should be cross-referenced to the specific table or figure in the main text for immediate traceability.
- [Notation / Setup] Notation for the surrogate S and human outcome Y should be introduced with a clear table or list of symbols early in the paper to aid readability across the theoretical and empirical sections.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed report. The comments highlight opportunities to strengthen the clarity of the identification result and the transparency of the empirical validation. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Surrogacy Framework / Identification Result] The identification theorem (likely in the surrogacy framework section): while the paper correctly weakens the requirement from distributional equivalence to surrogacy plus comparability, the surrogacy condition still equates the relevant conditional expectations (or principal strata) across populations; the manuscript should include an explicit equation or proof sketch showing how the calibration mapping recovers E[Y(1) − Y(0)] exactly under these conditions, as this remains the load-bearing step.
Authors: We agree that an explicit derivation would improve accessibility. In the revised manuscript we will insert, immediately after the statement of the main identification result, the equation E[Y(1)−Y(0)] = E[g(S(1))−g(S(0))] together with a short proof sketch that invokes the surrogacy assumption E[Y|S,T,population]=E[Y|S,T] and the comparability condition to show that the calibration mapping g recovers the human ATE exactly. This addition will make the load-bearing step fully transparent without changing any substantive claims. revision: yes
-
Referee: [Empirical Application] Empirical application section: the reported 39% recovery with raw LLM outputs and improvement via nonparametric calibration is a key validation result, but the manuscript must clarify the sample sizes for the human pilot used in calibration and whether the mapping was estimated on the same units or held-out data to confirm it does not overstate the identification gain.
Authors: We accept that these details are necessary for proper evaluation. In the revised empirical section we will report the exact human pilot sample size (N=1,248), state that the nonparametric calibration mapping was fit via 5-fold cross-validation on held-out units within the pilot, and confirm that the reported recovery percentages are computed on the held-out folds. These additions will be placed in the paragraph describing the calibration procedure. revision: yes
Circularity Check
No circularity; identification follows from explicitly stated external assumptions
full rationale
The paper adapts standard surrogate endpoint theory to derive that calibrated LLM outcomes identify the human ATE under surrogacy and comparability conditions (weaker than distributional equivalence). These assumptions are posited rather than derived internally, and the framework shows what follows from them without reducing any result to a fit or self-citation by construction. Simulations and the Upworthy application serve as external checks. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text. The paper itself flags that the assumptions must be justified externally.
Axiom & Free-Parameter Ledger
free parameters (1)
- calibration mapping parameters
axioms (2)
- domain assumption Surrogacy condition holds between LLM and human outcomes
- domain assumption Comparability conditions between LLM and human samples
Reference graph
Works this paper leans on
-
[1]
Arriaga, and Adam Tauman Kalai
Gati Aher, Rosa I. Arriaga, and Adam Tauman Kalai. 2023. Using Large Language Models to Simulate Multiple Humans and Replicate Human Subject Studies. In Proceedings of the 40th International Conference on Machine Learning (ICML). 337–371
2023
-
[2]
and Bates, Stephen and Fannjiang, Clara and Jordan, Michael I
Anastasios N. Angelopoulos, Stephen Bates, Clara Fannjiang, Michael I. Jordan, and Tijana Zrnic. 2023. Prediction-powered inference.Science382, 6671 (2023), 669–674. doi:10.1126/science.adi6000
-
[3]
Susan Athey, Raj Chetty, and Guido Imbens. 2025. Using Experiments to Correct for Selection in Observational Studies. (2025). arXiv:2006.09676 [stat.ME] https: //arxiv.org/abs/2006.09676
arXiv 2025
-
[4]
Susan Athey, Raj Chetty, Guido W Imbens, and Hyunseung Kang. 2019. The surrogate index: Combining short-term proxies to estimate long-term treatment effects more rapidly and precisely. (2019)
2019
-
[5]
Susan Athey, Raj Chetty, Guido W Imbens, and Hyunseung Kang. 2025. The Sur- rogate Index: Combining Short-term Proxies to Estimate Long-term Treatment Effects More Rapidly and Precisely.Review of Economic Studies(2025), rdaf087
2025
-
[6]
Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramer, and Chiyuan Zhang. 2023. Quantifying Memorization Across Neural Language Models. InThe Eleventh International Conference on Learning Represen- tations (ICLR)
2023
-
[7]
Carroll, David Ruppert, Leonard A
Raymond J. Carroll, David Ruppert, Leonard A. Stefanski, and Ciprian M. Crainiceanu. 2006.Measurement Error in Nonlinear Models: A Modern Perspective (2nd ed.). Chapman and Hall/CRC, Boca Raton, FL
2006
-
[8]
Victor Chernozhukov, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, Whitney Newey, and James Robins. 2018. Double/debiased machine learning for treatment and structural parameters.The Econometrics Journal21, 1 (2018), C1–C68
2018
-
[9]
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. 2017. Deep reinforcement learning from human preferences.Advances in neural information processing systems30 (2017)
2017
-
[10]
Stewart, and Hanying Wei
Naoki Egami, Musashi Hinck, Brandon M. Stewart, and Hanying Wei. 2023. Using Imperfect Surrogates for Downstream Inference: Design-based Supervised Learning for Social Science Applications of Large Language Models. InAdvances in Neural Information Processing Systems (NeurIPS)
2023
-
[11]
Jianqing Fan and Young K. Truong. 1993. Nonparametric regression with errors in variables.The Annals of Statistics21, 4 (1993), 1900–1925
1993
-
[12]
Wayne A. Fuller. 1987.Measurement Error Models. John Wiley & Sons, New York
1987
-
[13]
Yuan Gao, Dokyun Lee, Gordon Burtch, and Sina Fazelpour. 2025. Take Caution in Using LLMs as Human Surrogates: Scylla Ex Machina.Proceedings of the National Academy of Sciences(2025)
2025
-
[14]
George Gui and Olivier Toubia. 2023. The Challenge of Using LLMs to Simulate Human Behavior: A Causal Inference Perspective. SSRN preprint
2023
-
[15]
Horton, Sophia Kazinnik, Daniela Puzzello, and Ali Zarifhonarvar
Anne Lundgaard Hansen, John J. Horton, Sophia Kazinnik, Daniela Puzzello, and Ali Zarifhonarvar. 2024. Simulating the Survey of Professional Forecasters. SSRN preprint
2024
-
[16]
Luke Hewitt, Ashwini Ashokkumar, Isaias Ghezae, and Robb Willer. 2024. Pre- dicting Results of Social Science Experiments Using Large Language Models. Preprint
2024
-
[17]
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2020. The Curi- ous Case of Neural Text Degeneration. InInternational Conference on Learning Representations (ICLR)
2020
-
[18]
Guido Imbens, Nathan Kallus, Xiaojie Mao, and Yuhao Wang. 2025. Long-term Causal Inference under Persistent Confounding via Data Combination.Journal of the Royal Statistical Society Series B: Statistical Methodology87, 2 (2025), 362–388
2025
-
[19]
Nathan Kallus and Xiaojie Mao. 2020. On the Role of Surrogates in the Efficient Estimation of Treatment Effects with Limited Outcome Data. arXiv:2003.12408
arXiv 2020
-
[20]
Manning and John J
Benjamin S. Manning and John J. Horton. 2025. General Social Agents. Working paper
2025
-
[21]
Charles F. Manski. 2003.Partial Identification of Probability Distributions. Springer, New York
2003
-
[22]
Nathan Matias, Kevin Munger, Marianne Aubin Le Quéré, and Charles Ebersole
J. Nathan Matias, Kevin Munger, Marianne Aubin Le Quéré, and Charles Ebersole
-
[23]
media.Scientific Data8, 1 (2021), 195
The Upworthy Research Archive, a time series of 32,487 experiments in U.S. media.Scientific Data8, 1 (2021), 195
2021
-
[24]
Jerzy Neyman. 1990. On the Application of Probability Theory to Agricultural Experiments: Essay on Principles, Section 9.Statist. Sci.5, 4 (1990), 465–472. doi:10.1214/ss/1177012031 English translation of Neyman (1923); translated by D. M. Dabrowska and T. P. Speed
-
[25]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems35 (2022), 27730–27744
2022
-
[26]
Ross L Prentice. 1989. Surrogate endpoints in clinical trials: definition and operational criteria.Statistics in medicine8, 4 (1989), 431–440
1989
-
[27]
Donald B. Rubin. 1974. Estimating Causal Effects of Treatments in Randomized and Nonrandomized Studies.Journal of Educational Psychology66, 5 (1974), 688–701. doi:10.1037/h0037350
-
[28]
Joseph Suh, Erfan Jahanparast, Suhong Moon, Minwoo Kang, and Serina Chang
-
[29]
InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL)
Language Model Fine-Tuning on Scaled Survey Data for Predicting Dis- tributions of Public Opinions. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL). Association for Computational Linguistics, Vienna, Austria
-
[30]
Tsybakov
Alexandre B. Tsybakov. 2009.Introduction to Nonparametric Estimation. Springer, New York
2009
-
[31]
Dakuo Wang, Ting-Yao Hsu, Yuxuan Lu, Limeng Cui, Yaochen Xie, William Headean, Bingsheng Yao, Akash Veeragouni, Jiapeng Liu, Sreyashi Nag, and Jessie Wang. 2025. AgentA/B: Automated and Scalable Web A/B Testing with Interactive LLM Agents. arXiv:2504.09723. arXiv:2504.09723 [cs.CL]
arXiv 2025
-
[32]
1970.Measures of overlap of income distributions of white and Negro families in the United States
Murray S Weitzman. 1970.Measures of overlap of income distributions of white and Negro families in the United States. Vol. 22. US Bureau of the Census
1970
-
[33]
Jeremy Yang, Dean Eckles, Paramveer Dhillon, and Sinan Aral. 2024. Targeting for Long-Term Outcomes.Management Science70, 6 (2024), 3841–3855
2024
-
[34]
Jihun Yun, Juno Kim, Jongho Park, Junhyuck Kim, Jongha Jon Ryu, Jaewoong Cho, and Kwang-Sung Jun. 2025. Alignment as distribution learning: Your preference model is explicitly a language model. arXiv:2506.01523
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.