Masked Diffusion Vision-Language Models for Temporal Action Localization
Pith reviewed 2026-06-29 07:55 UTC · model grok-4.3
The pith
Masked diffusion vision-language models adapt to temporal action localization by keeping boundary tokens editable during bidirectional denoising.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
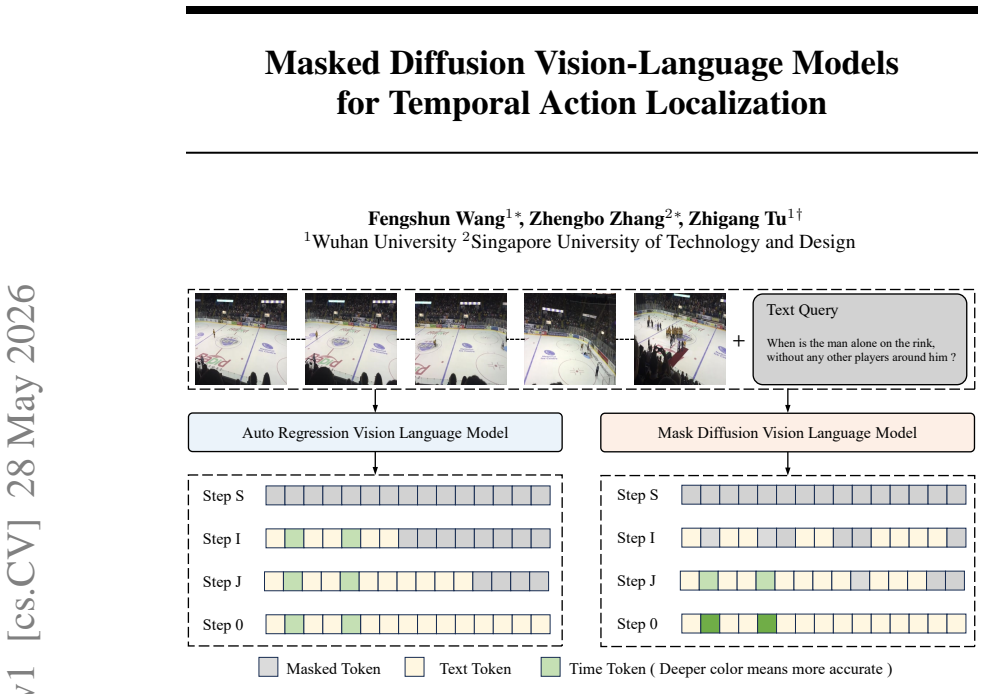
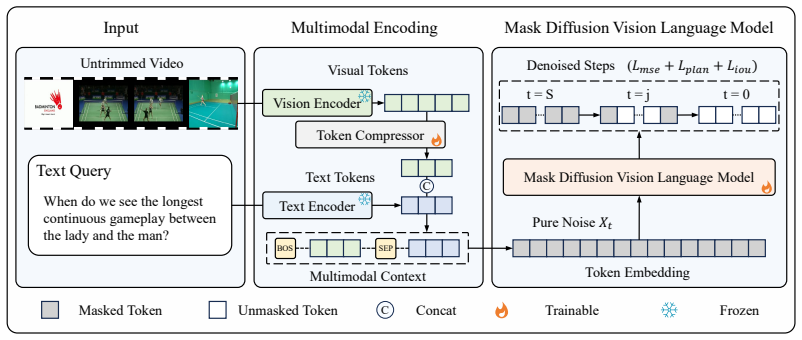
MDVLM-TAL adapts masked diffusion vision-language models to TAL by replacing autoregressive left-to-right decoding with iterative denoising under bidirectional attention, allowing semantic tokens and boundary tokens to remain editable throughout the process; direct adaptation is corrected via a Planned Training Objective that uses boundary-aware masking and step-weighted reconstruction together with a Step-Level IoU Reward, while retaining a base sequence-level cross-entropy term, producing improved temporal reasoning and boundary localization on ActivityNet-RTL, ActivityNet-1.3, and THUMOS-14.
What carries the argument
Planned Training Objective that applies boundary-aware masking and step-weighted reconstruction to rehearse late recovery of time tokens, combined with Step-Level IoU Reward for overlap-aware supervision during denoising.
If this is right
- Later semantic evidence can revise earlier timestamp predictions during denoising.
- Performance improves on ActivityNet-RTL, ActivityNet-1.3, and THUMOS-14 relative to autoregressive vision-language baselines.
- Gains are largest under stricter temporal IoU evaluation criteria.
- Language-conditioned outputs receive more precise start and end times through joint refinement of semantics and boundaries.
Where Pith is reading between the lines
- The same mismatch between token-level losses and interval-overlap metrics may appear in other diffusion-based localization tasks outside video.
- Bidirectional iterative refinement could reduce cumulative error in long untrimmed sequences compared with any strictly causal decoder.
- The boundary-aware masking schedule might generalize to other ordered token problems where certain positions require more context than others.
Load-bearing premise
The two TAL-specific mismatches between standard masked diffusion training and the requirements of time-token prediction are the dominant obstacles, and the proposed boundary-aware masking, step weighting, and IoU reward resolve them without new unaddressed issues.
What would settle it
An ablation on ActivityNet or THUMOS-14 in which MDVLM-TAL with the Planned Training Objective and Step-Level IoU Reward shows no improvement or worse performance than the autoregressive vision-language baseline at high temporal IoU thresholds would falsify the central claim.
Figures
read the original abstract
Temporal action localization (TAL) requires recognizing the target event and localizing its start and end times precisely in untrimmed videos. Recent vision-language formulations improve semantic reasoning and support language-conditioned outputs, but their autoregressive decoders still generate tokens from left to right, preventing later semantic evidence from revising earlier timestamp predictions. We adapt masked diffusion vision-language models (MDVLMs) to TAL so that semantic tokens and boundary tokens remain editable throughout iterative denoising with bidirectional attention, allowing temporal boundaries and semantic content to be refined jointly. Direct adaptation, however, creates two TAL-specific mismatches: standard masked diffusion training corrupts all positions uniformly at random, but the time tokens are more reliable when enough semantic context is available; and token-level cross-entropy does not reflect temporal IoU. To address these mismatches, we introduce a Planned Training Objective that uses boundary-aware masking and step-weighted reconstruction to rehearse the late recovery of time tokens, together with a Step-Level IoU Reward that provides overlap-aware supervision during denoising. A standard sequence-level cross-entropy term provides the base reconstruction signal. Experiments on ActivityNet-RTL, ActivityNet-1.3, and THUMOS-14 show that MDVLM-TAL improves both temporal reasoning and boundary localization over autoregressive vision-language baselines, with especially strong gains under stricter temporal IoU criteria.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper adapts masked diffusion vision-language models (MDVLMs) to temporal action localization (TAL) by replacing autoregressive left-to-right decoding with iterative bidirectional denoising. It identifies two TAL-specific mismatches (uniform random token corruption vs. need for semantic context on time tokens; token-level cross-entropy vs. temporal IoU) and proposes a Planned Training Objective that combines boundary-aware masking with step-weighted reconstruction, together with a Step-Level IoU Reward, while retaining a base sequence-level cross-entropy term. Experiments on ActivityNet-RTL, ActivityNet-1.3 and THUMOS-14 are reported to show gains over autoregressive vision-language baselines, especially at stricter IoU thresholds.
Significance. If the attribution of gains to the proposed components can be substantiated, the work would demonstrate that diffusion-based bidirectional refinement can jointly improve semantic reasoning and boundary precision in TAL, offering a concrete alternative to autoregressive VL formulations on standard benchmarks.
major comments (3)
- [Experiments] Experiments section: no ablation is presented that removes boundary-aware masking (reverting to uniform random corruption) while keeping the rest of the training objective fixed; without this control it remains possible that the reported strict-IoU gains arise from the underlying MDVLM architecture or bidirectional attention rather than the TAL-specific Planned Training Objective.
- [Experiments] Experiments section: no ablation is presented that removes the Step-Level IoU Reward while retaining sequence-level cross-entropy; the central claim that the reward resolves the token-level CE vs. temporal IoU mismatch therefore lacks direct empirical support.
- [Method] §3 (method): the interaction between step-weighted reconstruction and the IoU reward is not analyzed; it is unclear whether the weighting schedule was tuned jointly with the reward or chosen independently, which bears on whether the two components are additive or redundant.
minor comments (2)
- The abstract states 'especially strong gains under stricter temporal IoU criteria' but does not report the exact ΔmAP values or the IoU thresholds used; adding these numbers would improve clarity.
- Notation for the boundary-aware mask and the step-weighting function is introduced without an explicit equation reference; a single numbered equation would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important gaps in the experimental validation of our proposed components. We agree that additional ablations are needed to isolate the contributions of boundary-aware masking and the Step-Level IoU Reward, and we will incorporate these in the revised manuscript. Below we respond point by point.
read point-by-point responses
-
Referee: [Experiments] Experiments section: no ablation is presented that removes boundary-aware masking (reverting to uniform random corruption) while keeping the rest of the training objective fixed; without this control it remains possible that the reported strict-IoU gains arise from the underlying MDVLM architecture or bidirectional attention rather than the TAL-specific Planned Training Objective.
Authors: We agree this ablation is necessary to substantiate the role of boundary-aware masking. In the revision we will add an experiment that replaces boundary-aware masking with uniform random corruption while retaining step-weighted reconstruction, the IoU reward, and the base cross-entropy term. Results will be reported on ActivityNet-1.3 and THUMOS-14 at multiple IoU thresholds. revision: yes
-
Referee: [Experiments] Experiments section: no ablation is presented that removes the Step-Level IoU Reward while retaining sequence-level cross-entropy; the central claim that the reward resolves the token-level CE vs. temporal IoU mismatch therefore lacks direct empirical support.
Authors: We concur that isolating the Step-Level IoU Reward is required. The revised manuscript will include an ablation that trains with only the sequence-level cross-entropy plus Planned Training Objective (no IoU reward) and compares it to the full model. This will directly test whether the reward contributes to the observed improvements in boundary precision. revision: yes
-
Referee: [Method] §3 (method): the interaction between step-weighted reconstruction and the IoU reward is not analyzed; it is unclear whether the weighting schedule was tuned jointly with the reward or chosen independently, which bears on whether the two components are additive or redundant.
Authors: We will expand §3 and the experiments section with an analysis of the interaction. Specifically, we will report results for (i) the weighting schedule chosen independently of the reward and (ii) joint tuning of the schedule and reward weight. This will clarify whether the components are additive and will include sensitivity plots for the step-weighting hyperparameter. revision: yes
Circularity Check
No circularity: empirical adaptation without self-referential derivations or fitted predictions
full rationale
The paper describes an empirical adaptation of existing MDVLMs to TAL via boundary-aware masking, step-weighted reconstruction, and a Step-Level IoU Reward added to sequence-level cross-entropy. No equations, derivations, or first-principles claims appear in the provided text that reduce performance gains to self-definitions, renamed fits, or self-citation chains. The central claims rest on benchmark results (ActivityNet, THUMOS-14) rather than any tautological construction where a 'prediction' equals its input by design. This is a standard empirical methods paper; the reader's score of 1.0 is consistent with the absence of load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bidirectional attention in masked diffusion allows joint refinement of semantic and boundary tokens throughout denoising.
Reference graph
Works this paper leans on
-
[1]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al. Qwen3-vl technical report. 2025. doi: 10.48550/arXiv.2511.21631
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.21631 2025
-
[2]
Y .-W. Chao, S. Vijayanarasimhan, B. Seybold, D. A. Ross, J. Deng, and R. Sukthankar. Re- thinking the faster r-cnn architecture for temporal action localization. InCVPR, 2018
2018
-
[3]
Cheng and G
F. Cheng and G. Bertasius. Tallformer: Temporal action localization with a long-memory transformer. InECCV, pages 503–521, 2022
2022
-
[4]
Y . Feng, Z. Zhang, R. Quan, L. Wang, and J. Qin. Refinetad: learning proposal-free refinement for temporal action detection. InACM MM, pages 135–143, 2023. 9
2023
-
[5]
Y . Guo, J. Liu, M. Li, D. Cheng, X. Tang, D. Sui, Q. Liu, X. Chen, and K. Zhao. Vtg-llm: Integrating timestamp knowledge into video llms for enhanced video temporal grounding.AAAI, 39(3):3302–3310, 2025. doi: 10.1609/aaai.v39i3.32341
-
[6]
Heilbron, V
F. Heilbron, V . Escorcia, B. Ghanem, and J. C. Niebles. Activitynet: A large-scale video benchmark for human activity understanding. InCVPR, 2015
2015
-
[7]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
2022
-
[8]
Huang, X
B. Huang, X. Wang, H. Chen, Z. Song, and W. Zhu. Vtimellm: Empower llm to grasp video moments. InCVPR, pages 14271–14280, 2024
2024
-
[9]
D.-A. Huang, S. Liao, S. Radhakrishnan, H. Yin, P. Molchanov, Z. Yu, and J. Kautz. Lita: Language instructed temporal-localization assistant. InECCV, pages 202–218. Springer Nature Switzerland, 2024. doi: 10.1007/978-3-031-73039-9_12
-
[10]
Huang, L
L. Huang, L. Wang, and H. Li. Weakly supervised temporal action localization via representative snippet knowledge propagation. InCVPR, pages 3272–3281, 2022
2022
-
[11]
J. Kim, M. Lee, C.-H. Cho, J. Lee, and J.-P. Heo. Prediction-feedback detr for temporal action detection.AAAI, 39(4):4266–4274, 2025. doi: 10.1609/aaai.v39i4.32448
-
[12]
P. Lee, J. Wang, Y . Lu, and H. Byun. Weakly-supervised temporal action localization by uncertainty modeling.AAAI, 35(3):1854–1862, 2021
2021
-
[13]
K. Li, Y . He, Y . Wang, Y . Li, W. Wang, P. Luo, Y . Wang, L. Wang, and Y . Qiao. Videochat: chat-centric video understanding.Science China Information Sciences, 68(10), 2025. doi: 10.1007/s11432-024-4321-9
-
[14]
Q. Li, D. Liu, J. Kong, S. Li, H. Xu, and J. Wang. Temporal action localization with cross layer task decoupling and refinement. InAAAI, pages 4878–4886, 2025
2025
-
[15]
S. Li, K. Kallidromitis, H. Bansal, A. Gokul, Y . Kato, K. Kozuka, J. Kuen, Z. Lin, K.-W. Chang, and A. Grover. Lavida: A large diffusion model for vision-language understanding. InNeurIPS, 2025
2025
-
[16]
Liberatori, A
B. Liberatori, A. Conti, P. Rota, Y . Wang, and E. Ricci. Test-time zero-shot temporal action localization. InCVPR, pages 18720–18729, 2024
2024
-
[17]
T. Lin, X. Liu, X. Li, E. Ding, and S. Wen. Bmn: Boundary-matching network for temporal action proposal generation. InICCV, pages 3889–3898, 2019
2019
-
[18]
H. Liu, C. Li, Q. Wu, and Y . J. Lee. Visual instruction tuning, 2023
2023
-
[19]
S. Liu, C. Zhao, F. Zohra, M. Soldan, A. Pardo, M. Xu, L. Alssum, M. Ramazanova, J. L. Alcázar, A. Cioppa, S. Giancola, C. Hinojosa, and B. Ghanem. Opentad: A unified framework and comprehensive study of temporal action detection. InCVPR Workshops, pages 2616–2626. IEEE, 2025. doi: 10.1109/CVPRW67362.2025.00247
-
[20]
X. Liu, Q. Wang, Y . Hu, X. Tang, S. Zhang, S. Bai, and X. Bai. End-to-end temporal action detection with transformer.IEEE Transactions on Image Processing, 31:5427–5441, 2022. doi: 10.1109/TIP.2022.3195321
-
[21]
M. Maaz, H. Rasheed, S. Khan, and F. Khan. Video-chatgpt: Towards detailed video under- standing via large vision and language models. InACL, pages 12585–12602, 2024
2024
-
[22]
S. Nag, X. Zhu, Y .-Z. Song, and T. Xiang. Zero-shot temporal action detection via vision- language prompting. InECCV, pages 681–697. Springer, 2022
2022
-
[23]
S. Nag, X. Zhu, Y .-Z. Song, and T. Xiang. Proposal-free temporal action detection via global segmentation mask learning. InECCV, 2022
2022
-
[24]
S. Nag, X. Zhu, J. Deng, Y .-Z. Song, and T. Xiang. Difftad: Temporal action detection with proposal denoising diffusion. InCVPR, 2023. 10
2023
-
[25]
S. Nie, F. Zhu, Z. You, X. Zhang, J. Ou, J. Hu, J. Zhou, Y . Lin, J.-R. Wen, and C. Li. Large language diffusion models. 2025. doi: 10.48550/arXiv.2502.09992
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.09992 2025
-
[26]
T. Phan, K. V o, D. Le, G. Doretto, D. Adjeroh, and N. Le. Zeetad: Adapting pretrained vision-language model for zero-shot end-to-end temporal action detection. InWACV, pages 7031–7040, 2024
2024
-
[27]
Z. Qing, H. Su, W. Gan, D. Wang, W. Wu, X. Wang, Y . Qiao, J. Yan, C. Gao, and N. Sang. Temporal context aggregation network for temporal action proposal refinement. InCVPR, pages 485–494, 2021
2021
-
[28]
H. Ren, W. Yang, T. Zhang, and Y . Zhang. Proposal-based multiple instance learning for weakly-supervised temporal action localization. InCVPR, pages 2394–2404, 2023
2023
-
[29]
S. Reza, Y . Zhang, M. Moghaddam, and O. Camps. Hat: History-augmented anchor transformer for online temporal action localization. InECCV, pages 205–222. Springer, 2024
2024
-
[30]
D. Shi, Y . Zhong, Q. Cao, J. Zhang, L. Ma, J. Li, and D. Tao. React: Temporal action detection with relational queries. InECCV, 2022
2022
-
[31]
D. Shi, Y . Zhong, Q. Cao, L. Ma, J. Li, and D. Tao. Tridet: Temporal action detection with relative boundary modeling. InCVPR, pages 18857–18866, 2023
2023
-
[32]
Y . Song, D. Kim, M. Cho, and S. Kwak. Online temporal action localization with memory- augmented transformer. InECCV, pages 74–91. Springer, 2024
2024
-
[33]
J. Tan, J. Tang, L. Wang, and G. Wu. Relaxed transformer decoders for direct action proposal generation. InICCV, 2021
2021
-
[34]
T. N. Tang, K. Kim, and K. Sohn. Temporalmaxer: Maximize temporal context with only max pooling for temporal action localization. 2023. doi: 10.48550/arXiv.2303.09055
-
[35]
Y . Wang, K. Li, Y . Li, Y . He, B. Huang, Z. Zhao, H. Zhang, J. Xu, Y . Liu, Z. Wang, et al. Internvideo: General video foundation models via generative and discriminative learning. 2022. doi: 10.48550/arXiv.2212.03191
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.03191 2022
-
[36]
Y . Wang, K. Li, X. Li, J. Yu, Y . He, G. Chen, B. Pei, R. Zheng, Z. Wang, Y . Shi, et al. Internvideo2: Scaling foundation models for multimodal video understanding. InECCV, pages 396–416. Springer, 2024
2024
-
[37]
Y . Wang, X. Li, Z. Yan, Y . He, J. Yu, X. Zeng, C. Wang, C. Ma, H. Huang, J. Gao, et al. Internvideo2.5: Empowering video mllms with long and rich context modeling. 2025. doi: 10.48550/arXiv.2501.12386
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12386 2025
-
[38]
L. Xu, Y . Zhao, D. Zhou, Z. Lin, S. K. Ng, and J. Feng. Pllava: Parameter-free llava extension from images to videos for video dense captioning. 2024. doi: 10.48550/arXiv.2404.16994
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.16994 2024
-
[39]
M. Xu, C. Zhao, D. S. Rojas, A. Thabet, and B. Ghanem. G-tad: Sub-graph localization for temporal action detection. InCVPR, 2020
2020
-
[40]
M. Xu, M. Soldan, J. Gao, S. Liu, J.-M. Pérez-Rúa, and B. Ghanem. Boundary-denoising for video activity localization, 2023
2023
-
[41]
M. Xu, M. Gao, Z. Gan, H.-Y . Chen, Z. Lai, H. Gang, K. Kang, and A. Dehghan. Slowfast-llava: A strong training-free baseline for video large language models. 2024. doi: 10.48550/arXiv. 2407.15841
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[42]
J. Yang, P. Wei, Z. Ren, and N. Zheng. Gated multi-scale transformer for temporal action localization.IEEE Transactions on Multimedia, 26:5705–5717, 2024. doi: 10.1109/TMM.2023. 3338082
-
[43]
J. Yang, P. Wei, and N. Zheng. Cross time-frequency transformer for temporal action localization. IEEE Transactions on Circuits and Systems for Video Technology, 34(6):4625–4638, 2024. doi: 10.1109/TCSVT.2023.3326692. 11
-
[44]
S. Yu, J. Cho, P. Yadav, and M. Bansal. Sevila: Self-chained image-language model for video localization and question answering, 2023
2023
-
[45]
Y . Zeng, Y . Zhong, C. Feng, and L. Ma. Unimd: Towards unifying moment retrieval and temporal action detection. InECCV, pages 286–304. Springer Nature Switzerland, 2024. doi: 10.1007/978-3-031-72952-2_17
-
[46]
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sigmoid loss for language image pre-training. InICCV, pages 11975–11986, 2023
2023
-
[47]
Y . Zhai, L. Wang, W. Tang, Q. Zhang, N. Zheng, D. Doermann, J. Yuan, and G. Hua. Adaptive two-stream consensus network for weakly-supervised temporal action localization.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(4):4136–4151, 2023. doi: 10.1109/TPAMI.2022.3189662
-
[48]
Zhang, J
C.-L. Zhang, J. Wu, and Y . Li. Actionformer: Localizing moments of actions with transformers. InECCV, pages 492–510. Springer, 2022
2022
-
[49]
H. Zhang, X. Li, and L. Bing. Video-llama: An instruction-tuned audio-visual language model for video understanding. InEMNLP Demo, pages 543–553. Association for Computational Linguistics, 2023. doi: 10.18653/v1/2023.emnlp-demo.49
-
[50]
RLAIF-V: open-source AI feedback leads to super GPT-4V trustworthiness
Q. Zhang, J. Fang, R. Yuan, X. Tang, Y . Qi, K. Zhang, and C. Yuan. Weakly supervised temporal action localization via dual-prior collaborative learning guided by multimodal large language models. InCVPR, pages 24139–24148. IEEE, 2025. doi: 10.1109/CVPR52734.2025.02248
-
[51]
J. Zhou, L. Huang, L. Wang, S. Liu, and H. Li. Improving weakly supervised temporal action localization by bridging train-test gap in pseudo labels. InCVPR, pages 23003–23012, 2023
2023
-
[52]
Y . Zhu, G. Zhang, J. Tan, G. Wu, and L. Wang. Dual detrs for multi-label temporal action detection. InCVPR, pages 18559–18569. IEEE, 2024. doi: 10.1109/CVPR52733.2024.01756
-
[53]
Z. Zhu, W. Tang, L. Wang, N. Zheng, and G. Hua. Enriching local and global contexts for temporal action localization. InICCV, pages 13516–13525, 2021. 12
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.