IntentTester: Intent-Driven Multi-agent Framework for Cross-Library Test Migration
Pith reviewed 2026-06-25 19:59 UTC · model grok-4.3
The pith
IntentTester migrates unit tests across libraries and languages by converting them to a language-agnostic description and using multi-agent reasoning to align functional intent with target repository entities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
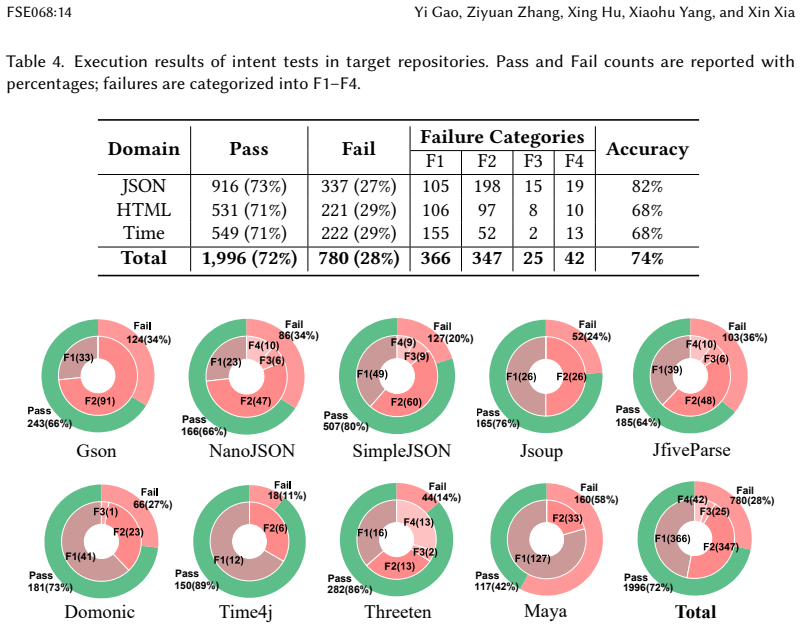
IntentTester abstracts tests into a language-agnostic Test Description Language (TDL), aligns them with semantically related entities and dependencies in a repository graph, and synthesizes executable tests through LLM-guided reasoning and iterative validation. This produces 2,776 syntactically correct tests with 85% correctness and 2,410 successfully executed tests at 74% effectiveness on nine open-source projects, outperforming two structure-mapping baselines at 51% and 43% correctness, and surfaces previously unknown defects such as stack overflows, null dereferences, and parsing inconsistencies that maintainers have acknowledged or patched.
What carries the argument
Language-agnostic Test Description Language (TDL) abstraction plus repository-graph semantic alignment and multi-agent LLM reasoning for synthesis and validation.
If this is right
- Cross-library and cross-language test reuse becomes feasible without relying on matching API signatures or code structure.
- Migrated tests execute successfully at 74% effectiveness and achieve 85% correctness, exceeding the 51% and 43% rates of structure-mapping baselines.
- The same process identifies and surfaces previously unknown defects including stack overflows, null dereferences, and parsing inconsistencies in target libraries.
- Test migration no longer requires manual intervention once the TDL abstraction and graph alignment steps are complete.
Where Pith is reading between the lines
- The same intent-alignment steps could be applied to other forms of cross-project reuse such as documentation or example code.
- Repository graphs built from multiple libraries might allow test migration among more than two languages simultaneously.
- If the TDL step captures domain knowledge reliably, the framework could reduce duplication of testing effort across libraries that implement similar functionality.
- Iterative LLM validation loops may become a general pattern for ensuring semantic fidelity in automated code transformations.
Load-bearing premise
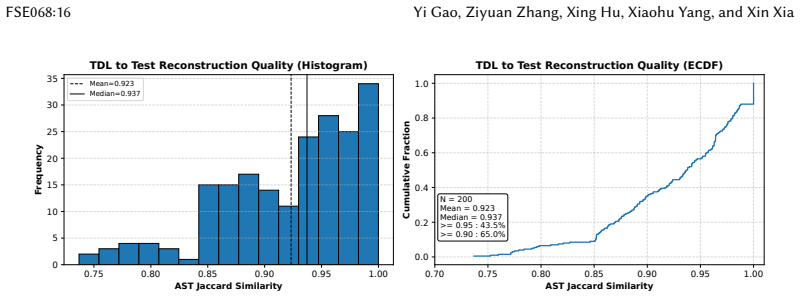
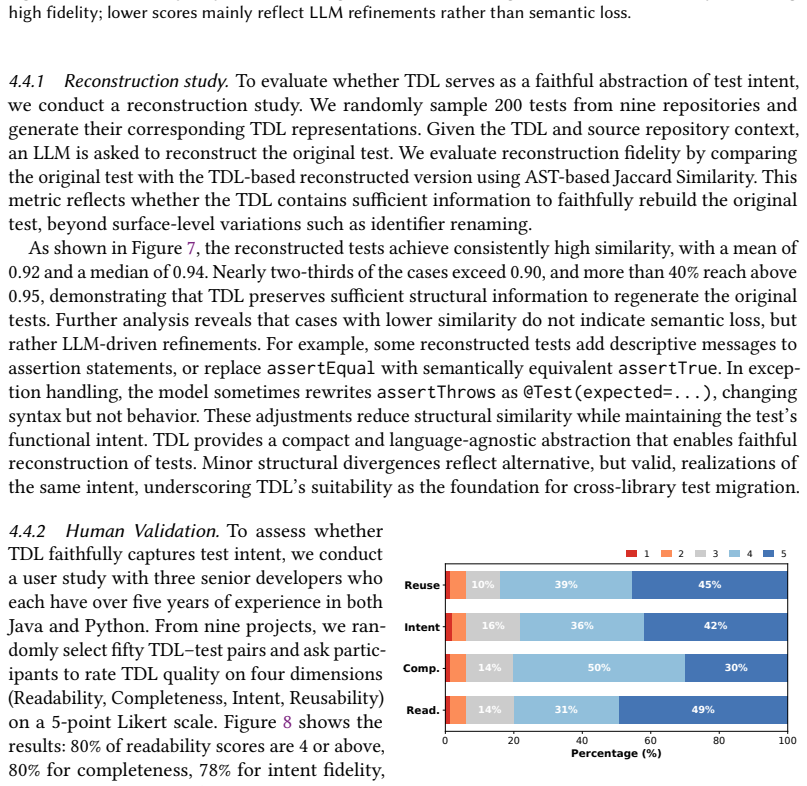
Abstracting a test into a language-agnostic TDL and aligning it via LLM-guided semantic matching with a repository graph preserves the original functional intent well enough to yield executable and correct tests without manual fixes.
What would settle it
Run the original test and the migrated test on equivalent inputs that trigger the same functional behavior; if the migrated test passes when the original would fail (or vice versa) on the same logical condition, the claim of preserved intent fails.
Figures
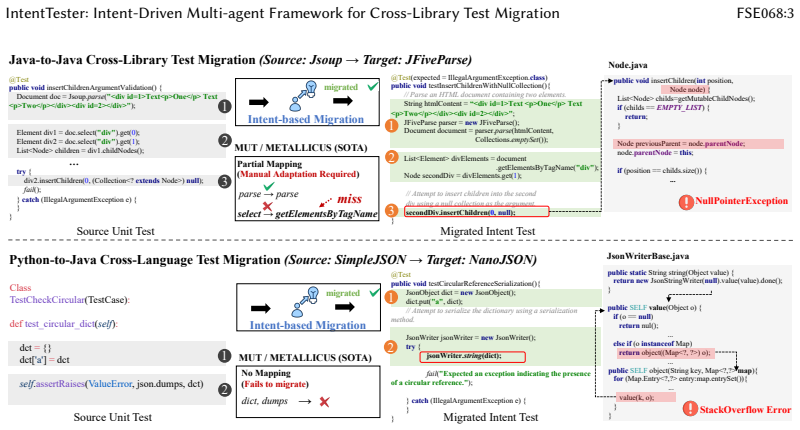
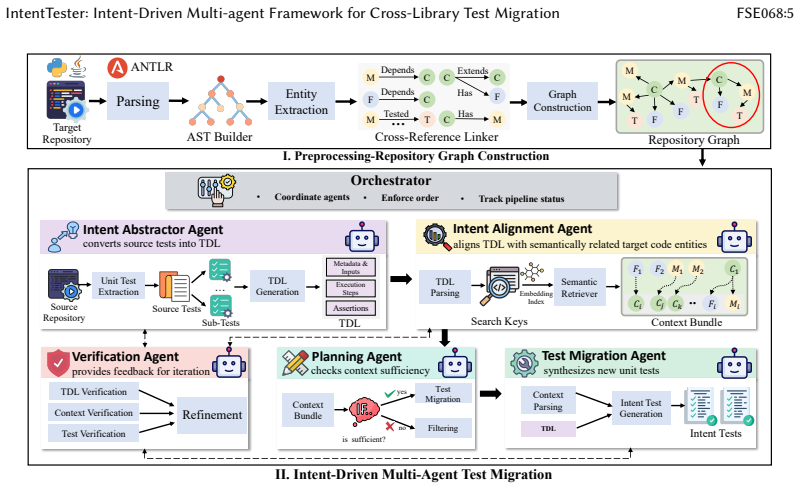
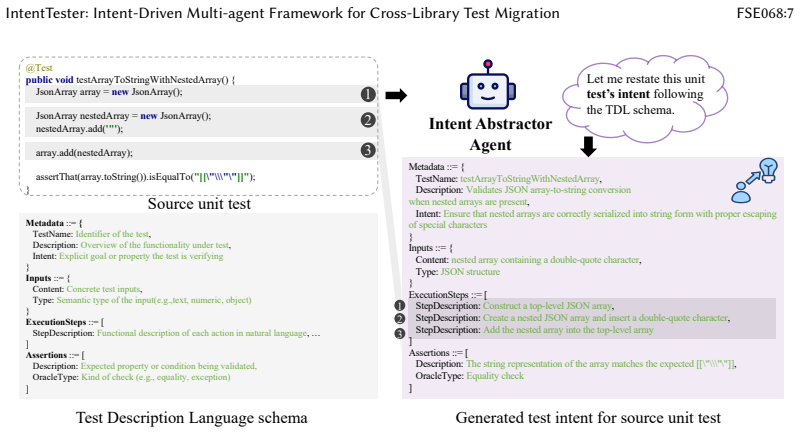
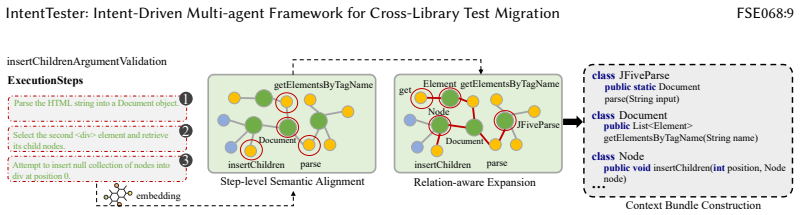
read the original abstract
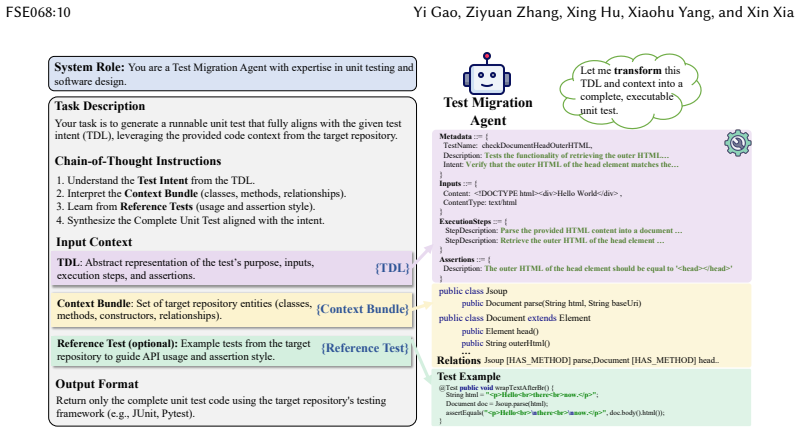
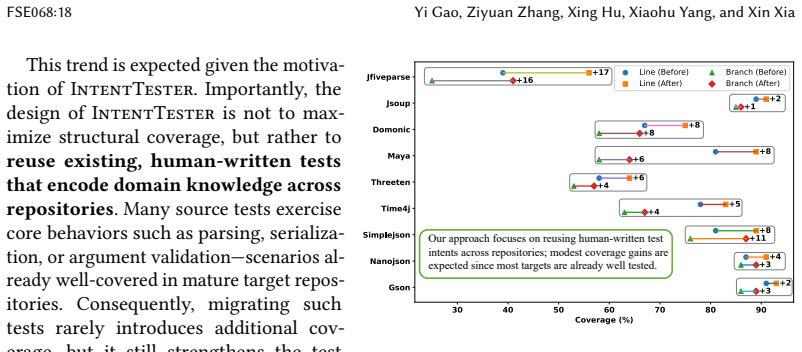
Unit tests capture both functional checks and domain-specific knowledge, but this knowledge remains locked within individual projects and is rarely reused across libraries with overlapping functionality. Existing migration techniques based on structural code mappings (e.g., API signatures) often break down under divergent designs or cross-language settings, resulting in non-executable migrated tests. In this paper, we present IntentTester, a multi-agent framework for intent-driven test reuse. Instead of translating raw code, IntentTester abstracts tests into a language-agnostic Test Description Language (TDL), aligns them with semantically related entities and dependencies in a repository graph, and synthesizes executable tests through LLM-guided reasoning and iterative validation. This design enables cross-library and cross-language migration without manual intervention, producing migrated tests that existing structure-mapping approaches cannot achieve. We evaluate IntentTester on nine open-source projects across three domains (JSON, HTML, and Time) and two languages (Java and Python). IntentTester generates 2,776 syntactically correct tests with 85\% correctness; in comparison, the two baselines achieve 51\% and 43\%. Among them, 2,410 tests executed successfully, yielding a 74\% effectiveness rate. Beyond higher success rates, IntentTester also surfaced previously unknown defects including stack overflows, null dereferences, and parsing inconsistencies, several of which have been acknowledged or patched by maintainers. Our results show that intent-driven migration shifts the focus from code mappings to semantic alignment, allowing practical cross-library and cross-language test reuse while improving test quality and exposing implementation flaws.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces IntentTester, a multi-agent framework for cross-library and cross-language test migration. It abstracts tests into a language-agnostic Test Description Language (TDL), aligns them semantically with a repository graph, and uses LLM-guided reasoning plus iterative validation to synthesize executable tests. Evaluated on nine open-source projects across JSON, HTML, and Time domains in Java and Python, it reports generating 2,776 syntactically correct tests at 85% correctness (versus 51% and 43% for two baselines), 2,410 successful executions (74% effectiveness), and discovery of previously unknown defects acknowledged by maintainers.
Significance. If the performance numbers hold under a transparent and reproducible correctness protocol, the work could meaningfully advance test reuse by prioritizing semantic intent alignment over structural code mappings, enabling scenarios that prior techniques cannot handle. The multi-domain, cross-language evaluation and the outcome of surfacing real defects provide concrete evidence of practical utility.
major comments (1)
- [Evaluation section] Evaluation section (and abstract): The headline claims of 85% correctness (2,776 tests) and 74% effectiveness (2,410 tests) versus baselines at 51% and 43% are presented without an explicit operational definition of 'correctness,' without the experimental protocol, baseline implementation details, inter-rater statistics if human judgment is used, or raw data. This directly undermines verification of the 34-point gap and is load-bearing for the central empirical contribution.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The concern about transparency in the evaluation is valid and central to the paper's claims; we address it directly below.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section (and abstract): The headline claims of 85% correctness (2,776 tests) and 74% effectiveness (2,410 tests) versus baselines at 51% and 43% are presented without an explicit operational definition of 'correctness,' without the experimental protocol, baseline implementation details, inter-rater statistics if human judgment is used, or raw data. This directly undermines verification of the 34-point gap and is load-bearing for the central empirical contribution.
Authors: We accept the criticism. The current manuscript describes the evaluation at a high level but does not supply a standalone operational definition of correctness, the complete experimental protocol, baseline implementation specifics, inter-rater statistics, or raw data. In the revised version we will add a dedicated subsection that (1) defines correctness as the fraction of generated tests whose behavior is semantically equivalent to the source test (determined by two authors via independent review, with Cohen's kappa reported), (2) defines effectiveness as the fraction that execute successfully on the target library, (3) enumerates the full protocol (test selection criteria, TDL construction steps, synthesis and validation loop, and stopping conditions), (4) details baseline re-implementations including any cross-language adaptations, and (5) provides a public repository link containing all raw data, generated tests, and reproduction scripts. These additions will allow independent verification of the reported gaps. revision: yes
Circularity Check
No circularity: empirical framework evaluation independent of inputs
full rationale
The paper presents an empirical software engineering tool (IntentTester) whose central claims rest on reported experimental outcomes from evaluating the framework on nine projects, not on any mathematical derivation, fitted parameters, or self-referential definitions. No equations, uniqueness theorems, ansatzes, or predictions appear in the provided text; the design (TDL abstraction + repository graph + LLM reasoning) is described as a novel construction whose performance is measured externally via syntactic correctness, execution success, and defect discovery rates. These metrics are not shown to reduce to the inputs by construction, and no self-citation chain is invoked to justify load-bearing premises. The evaluation protocol, while potentially underspecified per the skeptic note, does not constitute circularity under the defined patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-guided reasoning and iterative validation can produce functionally equivalent executable tests from TDL abstractions
invented entities (2)
-
Test Description Language (TDL)
no independent evidence
-
repository graph
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2026. Antlr. https://www.antlr.org/
2026
-
[2]
2026. Domonic. https://github.com/byteface/domonic
2026
-
[3]
2026. FAISS. https://github.com/facebookresearch/faiss
2026
-
[4]
2026. Gson. https://github.com/google/gson
2026
-
[5]
IntentTester
2026. IntentTester. https://github.com/testmigrator/intenttest
2026
-
[6]
Jfiveparse
2026. Jfiveparse. https://github.com/digitalfondue/jfiveparse
2026
-
[7]
2026. jsoup. https://github.com/jhy/jsoup
2026
-
[8]
2026. Maya. https://github.com/kennethreitz/maya
2026
-
[9]
2026. MiniLM. https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
2026
-
[10]
Nanojson
2026. Nanojson. https://github.com/mmastrac/nanojson
2026
-
[11]
2026. Neo4j. https://neo4j.com/
2026
-
[12]
Simplejson
2026. Simplejson. https://github.com/simplejson/simplejson
2026
-
[13]
Threeten
2026. Threeten. https://github.com/ThreeTen/threetenbp
2026
-
[14]
2026. Time4j. https://github.com/MenoData/Time4J
2026
-
[15]
Maurício Aniche, Christoph Treude, and Andy Zaidman. 2021. How developers engineer test cases: An observational study.IEEE Transactions on Software Engineering48, 12 (2021), 4925–4946. doi:10.1109/TSE.2021.3129889 Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE068. Publication date: July 2026. FSE068:20 Yi Gao, Ziyuan Zhang, Xing Hu, Xiaohu Yang, and Xin Xia
-
[16]
Baris Ardic, Carolin Brandt, Ali Khatami, Mark Swillus, and Andy Zaidman. 2025. The qualitative factor in software testing: A systematic mapping study of qualitative methods.Journal of Systems and Software(2025), 112447. doi:10. 1016/J.JSS.2025.112447
arXiv 2025
-
[17]
Farnaz Behrang and Alessandro Orso. 2018. Test migration for efficient large-scale assessment of mobile app coding assignments. InProceedings of the 27th ACM SIGSOFT International Symposium on Software Testing and Analysis. 164–175. doi:10.1145/3213846.3213854
-
[18]
Farnaz Behrang and Alessandro Orso. 2019. Test migration between mobile apps with similar functionality. In2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 54–65. doi:10.1109/ASE.2019.00016
-
[19]
Benyamin Beyzaei, Saghar Talebipour, Ghazal Rafiei, Nenad Medvidović, and Sam Malek. 2025. Automated Test Transfer across Android Apps using Large Language Models.Proceedings of the ACM on Software Engineering2, ISSTA (2025), 2227–2250. doi:10.1145/3728975
-
[20]
Zirui Chen, Xing Hu, Xin Xia, and Xiaohu Yang. 2026. Every Maintenance Has Its Exemplar: The Future of Software Maintenance through Migration.ACM Transactions on Software Engineering and Methodology(2026). doi:10.48550/ ARXIV.2602.14046
arXiv 2026
-
[21]
Yi Gao, Xing Hu, Tongtong Xu, Xin Xia, David Lo, and Xiaohu Yang. 2024. MUT: Human-in-the-Loop Unit Test Migration. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering. 1–12. doi:10.1145/ 3597503.3639124
arXiv 2024
-
[22]
Yi Gao, Xing Hu, Xiaohu Yang, and Xin Xia. 2025. Automated unit test refactoring.Proceedings of the ACM on Software Engineering2, FSE (2025), 713–733. doi:10.1145/3715750
-
[23]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large language models for software engineering: A systematic literature review.ACM Transactions on Software Engineering and Methodology33, 8 (2024), 1–79. doi:10.1145/3695988
-
[24]
Gang Hu, Linjie Zhu, and Junfeng Yang. 2018. AppFlow: using machine learning to synthesize robust, reusable UI tests. InProceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 269–282. doi:10.1145/3236024.3236055
-
[25]
Kaifeng Huang, Bihuan Chen, Congying Xu, Ying Wang, Bowen Shi, Xin Peng, Yijian Wu, and Yang Liu. 2022. Characterizing usages, updates and risks of third-party libraries in Java projects.Empirical Software Engineering27, 4 (2022), 90. doi:10.1007/S10664-022-10131-8
-
[26]
Zhenfei Huang, Junjie Chen, Jiajun Jiang, Yihua Liang, Hanmo You, and Fengjie Li. 2024. Mapping APIs in Dynamic- typed Programs by Leveraging Transfer Learning.ACM Transactions on Software Engineering and Methodology33, 4 (2024), 1–29. doi:10.1145/3641848
-
[27]
Mohayeminul Islam, Ajay Kumar Jha, Ildar Akhmetov, and Sarah Nadi. 2024. Characterizing Python Library Migrations. Proceedings of the ACM on Software Engineering1, FSE (2024), 92–114. doi:10.1145/3643731
-
[28]
Ajay Kumar Jha, Mohayeminul Islam, and Sarah Nadi. 2023. Jtestmigbench and jtestmigtax: A benchmark and taxonomy for unit test migration. In2023 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 713–717. doi:10.1109/SANER56733.2023.00077
-
[29]
Ajay Kumar Jha and Sarah Nadi. 2024. Migrating Unit Tests Across Java Applications. In2024 IEEE International Conference on Source Code Analysis and Manipulation (SCAM). IEEE, 131–142. doi:10.1109/SCAM63643.2024.00022
-
[30]
Farideh Khalili, Leonardo Mariani, Ali Mohebbi, Mauro Pezzè, and Valerio Terragni. 2024. Semantic matching in GUI test reuse.Empirical Software Engineering29, 3 (2024), 70. doi:10.1007/S10664-023-10406-8
-
[31]
Ali Khatami and Andy Zaidman. 2023. Quality assurance awareness in open source software projects on GitHub. In 2023 IEEE 23rd International Working Conference on Source Code Analysis and Manipulation (SCAM). IEEE, 174–185. doi:10.1109/SCAM59687.2023.00027
-
[32]
Jia Li, Ge Li, Yongmin Li, and Zhi Jin. 2025. Structured chain-of-thought prompting for code generation.ACM Transactions on Software Engineering and Methodology34, 2 (2025), 1–23. doi:10.1145/3690635
-
[33]
Jun-Wei Lin, Reyhaneh Jabbarvand, and Sam Malek. 2019. Test transfer across mobile apps through semantic mapping. In2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 42–53. doi:10.1109/ ASE.2019.00015
arXiv 2019
-
[34]
Shuqi Liu, Yu Zhou, Tingting Han, and Taolue Chen. 2022. Test reuse based on adaptive semantic matching across android mobile applications. In2022 IEEE 22nd International Conference on Software Quality, Reliability and Security (QRS). IEEE, 703–709. doi:10.1109/QRS57517.2022.00076
-
[35]
Yingwei Ma, Qingping Yang, Rongyu Cao, Binhua Li, Fei Huang, and Yongbin Li. 2024. How to understand whole software repository?arXiv preprint arXiv:2406.01422(2024). doi:10.48550/ARXIV.2406.01422
-
[36]
Leonardo Mariani, Ali Mohebbi, Mauro Pezzè, and Valerio Terragni. 2021. Semantic matching of gui events for test reuse: are we there yet?. InProceedings of the 30th ACM SIGSOFT International Symposium on Software Testing and Analysis. 177–190. doi:10.1145/3460319.3464827 Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE068. Publication date: July 2026. ...
-
[37]
Anh Tuan Nguyen, Hoan Anh Nguyen, Tung Thanh Nguyen, and Tien N Nguyen. 2014. Statistical learning approach for mining API usage mappings for code migration. InProceedings of the 29th ACM/IEEE international conference on Automated software engineering. 457–468. doi:10.1145/2642937.2643010
-
[38]
Xue Qin, Hao Zhong, and Xiaoyin Wang. 2019. Testmig: Migrating gui test cases from ios to android. InProceedings of the 28th ACM SIGSOFT International Symposium on Software Testing and Analysis. 284–295. doi:10.1145/3293882.3330575
-
[39]
Max Schafer, Sarah Nadi, Aryaz Eghbali, and Frank Tip. 2024. An Empirical Evaluation of Using Large Language Models for Automated Unit Test Generation.IEEE Transactions on Software Engineering50, 1 (2024), 85–105. doi:10. 1109/TSE.2023.3334955
arXiv 2024
-
[40]
Yanjie Shao, Tianyue Luo, Xiang Ling, Limin Wang, and Senwen Zheng. 2022. Cross Platform API Mappings based on API Documentation Graphs. In2022 IEEE 22nd International Conference on Software Quality, Reliability and Security (QRS). IEEE, 926–935. doi:10.1109/QRS57517.2022.00097
-
[41]
Devika Sondhi, Mayank Jobanputra, Divya Rani, Salil Purandare, Sakshi Sharma, and Rahul Purandare. 2021. Mining similar methods for test adaptation.IEEE Transactions on Software Engineering48, 7 (2021), 2262–2276. doi:10.1109/ TSE.2021.3057163
arXiv 2021
-
[42]
Yutian Tang, Zhijie Liu, Zhichao Zhou, and Xiapu Luo. 2024. Chatgpt vs sbst: A comparative assessment of unit test suite generation.IEEE Transactions on Software Engineering(2024). doi:10.1109/TSE.2024.3382365
-
[43]
Cédric Teyton, Jean-Rémy Falleri, and Xavier Blanc. 2013. Automatic discovery of function mappings between similar libraries. In2013 20th Working Conference on Reverse Engineering (WCRE). IEEE, 192–201. doi:10.1109/WCRE.2013. 6671294
-
[44]
Junjie Wang, Yuchao Huang, Chunyang Chen, Zhe Liu, Song Wang, and Qing Wang. 2024. Software testing with large language models: Survey, landscape, and vision.IEEE Transactions on Software Engineering(2024). doi:10.1109/TSE. 2024.3368208
work page doi:10.1109/tse 2024
-
[45]
Ying Wang, Bihuan Chen, Kaifeng Huang, Bowen Shi, Congying Xu, Xin Peng, Yijian Wu, and Yang Liu. 2020. An empirical study of usages, updates and risks of third-party libraries in java projects. In2020 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 35–45. doi:10.1109/ICSME46990.2020.00014
-
[46]
Juyeon Yoon, Robert Feldt, and Shin Yoo. 2024. Intent-driven mobile gui testing with autonomous large language model agents. In2024 IEEE Conference on Software Testing, Verification and Validation (ICST). IEEE, 129–139. doi:10. 1109/ICST60714.2024.00020
arXiv 2024
-
[47]
Zhiqiang Yuan, Mingwei Liu, Shiji Ding, Kaixin Wang, Yixuan Chen, Xin Peng, and Yiling Lou. 2024. Evaluating and improving chatgpt for unit test generation.Proceedings of the ACM on Software Engineering1, FSE (2024), 1703–1726. doi:10.1145/3660783
-
[48]
Junwei Zhang, Xing Hu, Xin Xia, Shing-Chi Cheung, and Shanping Li. 2026. Automated Unit Test Generation via Chain-of-Thought Prompt and Reinforcement Learning from Coverage Feedback.ACM Transactions on Software Engineering and Methodology35, 4 (2026), 1–30
2026
-
[49]
Yakun Zhang, Chen Liu, Xiaofei Xie, Yun Lin, Jin Song Dong, Dan Hao, and Lu Zhang. 2024. LLM-based Abstraction and Concretization for GUI Test Migration.arXiv preprint arXiv:2409.05028(2024). doi:10.48550/ARXIV.2409.05028
-
[50]
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. 2024. Autocoderover: Autonomous program improvement. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 1592–1604. doi:10.1145/3650212.3680384
-
[51]
Yakun Zhang, Wenjie Zhang, Dezhi Ran, Qihao Zhu, Chengfeng Dou, Dan Hao, Tao Xie, and Lu Zhang. 2024. Learning- based widget matching for migrating gui test cases. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering. 1–13. doi:10.1145/3597503.3623322
-
[52]
Yakun Zhang, Qihao Zhu, Jiwei Yan, Chen Liu, Wenjie Zhang, Yifan Zhao, Dan Hao, and Lu Zhang. 2024. Synthesis- Based Enhancement for GUI Test Case Migration. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 869–881. doi:10.1145/3650212.3680327
-
[53]
Zejun Zhang, Minxue Pan, Tian Zhang, Xinyu Zhou, and Xuandong Li. 2020. Deep-diving into documentation to develop improved java-to-swift api mapping. InProceedings of the 28th International Conference on Program Comprehension. 106–116. doi:10.1145/3387904.3389282
-
[54]
Yixue Zhao, Justin Chen, Adriana Sejfia, Marcelo Schmitt Laser, Jie Zhang, Federica Sarro, Mark Harman, and Nenad Medvidovic. 2020. Fruiter: a framework for evaluating ui test reuse. InProceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 1190–1201. doi:10.1145/33680...
-
[55]
Bingzhe Zhou, Xinying Wang, Shengbin Xu, Yuan Yao, Minxue Pan, Feng Xu, and Xiaoxing Ma. 2023. Hybrid API migration: A marriage of small API mapping models and large language models. InProceedings of the 14th Asia-Pacific Symposium on Internetware. 12–21. doi:10.1145/3609437.3609466 Received 2025-09-03; accepted 2025-12-22 Proc. ACM Softw. Eng., Vol. 3, N...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.