ZIPP:Zero-shot Image Personalization from Personas
Pith reviewed 2026-06-27 18:08 UTC · model grok-4.3
The pith
ZIPP conditions diffusion models on natural-language personas mined from Reddit graphs to deliver zero-shot image personalization without user data or fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
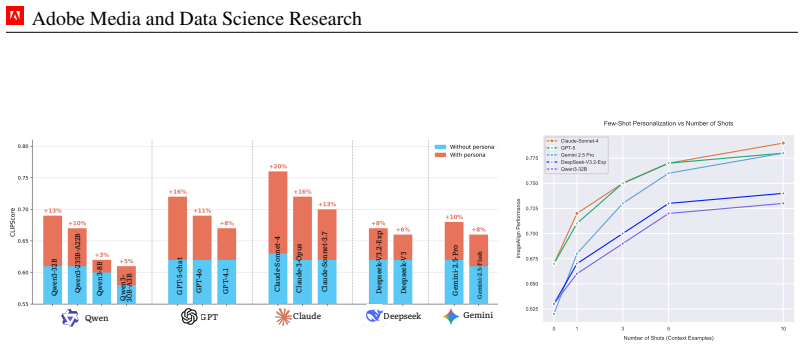
Conditioning image generation on natural-language personas extracted from graph structure enables consistent zero-shot personalization. Across four benchmarks and fourteen LLMs, persona rewriting produces 13-20% gains, with larger models showing the biggest lifts. The same approach reaches or exceeds fine-tuned baselines that use over one hundred examples per user, records the lowest CMMD of 0.16, reduces subpopulation bias on IPF-normalized metrics, and wins 79% of human pairwise comparisons against generic outputs and 58-65% against all fine-tuned baselines.
What carries the argument
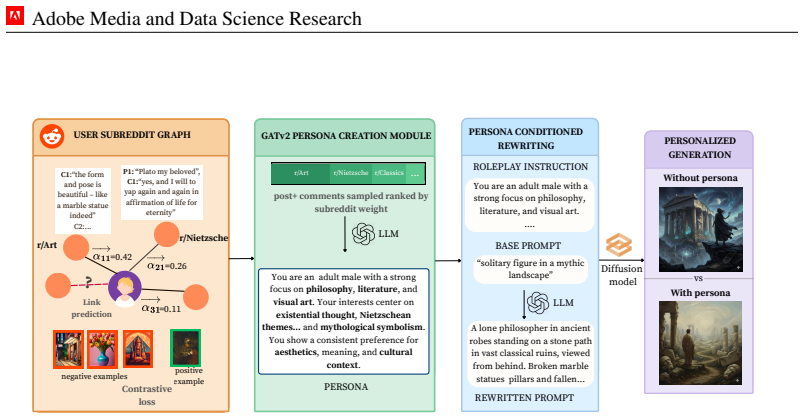
LLM-driven prompt rewriting that steers a diffusion model from the perspective of a natural-language persona, where the persona itself is produced by a graph attention network trained on Reddit interactions and then verbalized by an MLLM.
If this is right
- Persona conditioning produces 13-20% gains on four benchmarks spanning fourteen LLMs from five families.
- In the few-shot regime the method matches or surpasses fine-tuned baselines trained on more than one hundred examples per user.
- It records the lowest preference divergence measured by CMMD at 0.16 compared with 0.55 for prior approaches.
- IPF-normalized demographic checks show substantial reduction in subpopulation bias relative to existing methods.
- Human raters prefer ZIPP outputs 79% of the time over generic generation and 58-65% of the time over all fine-tuned baselines.
Where Pith is reading between the lines
- The same graph-to-persona pipeline could be applied to interaction data from other platforms to test whether the approach generalizes beyond Reddit.
- Periodic re-mining of personas from evolving user graphs might allow the system to track gradual shifts in taste without explicit retraining.
- Combining the zero-shot persona signal with a small number of user-provided reference images could produce a hybrid method that further narrows the remaining gap to fully supervised personalization.
- The prompt-rewriting step itself might be replaced by direct conditioning inside the diffusion model if the persona text can be mapped to a compact embedding.
Load-bearing premise
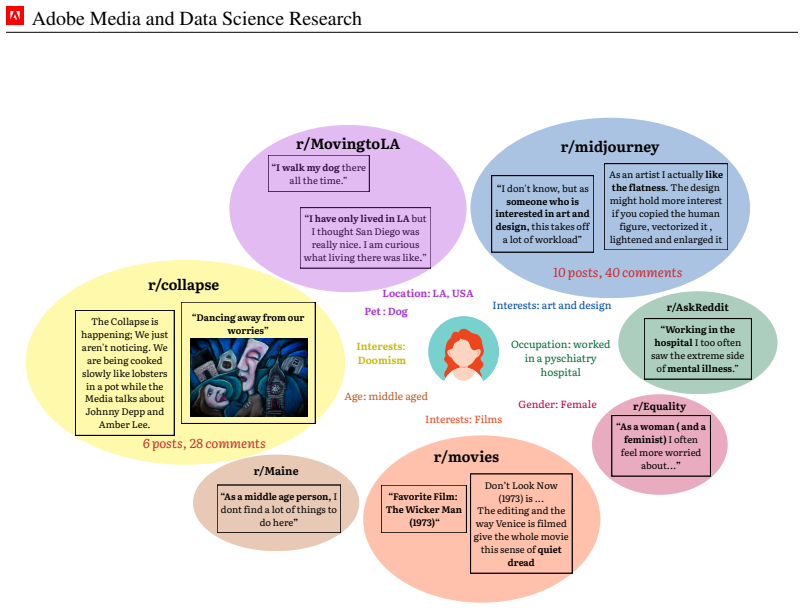
Reddit interaction graphs contain stable aesthetic preferences that transfer to new users and can be turned into accurate natural-language descriptions without any direct visual examples or user feedback.
What would settle it
A blind user study in which participants rate images generated from their own graph-mined personas against images from mismatched or generic personas; if the mined-persona images are not preferred at rates significantly above chance, the central claim is false.
Figures




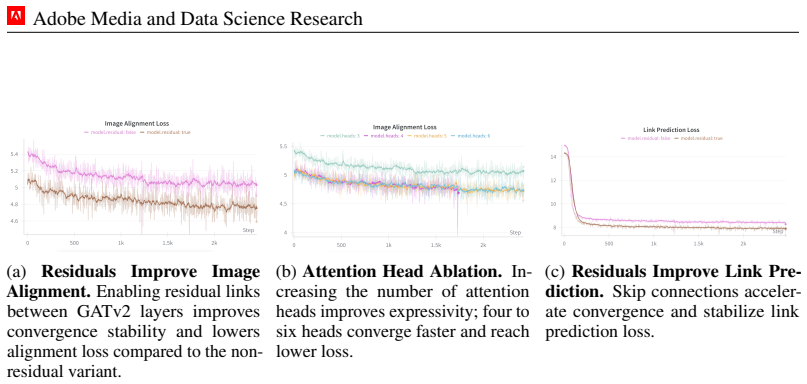
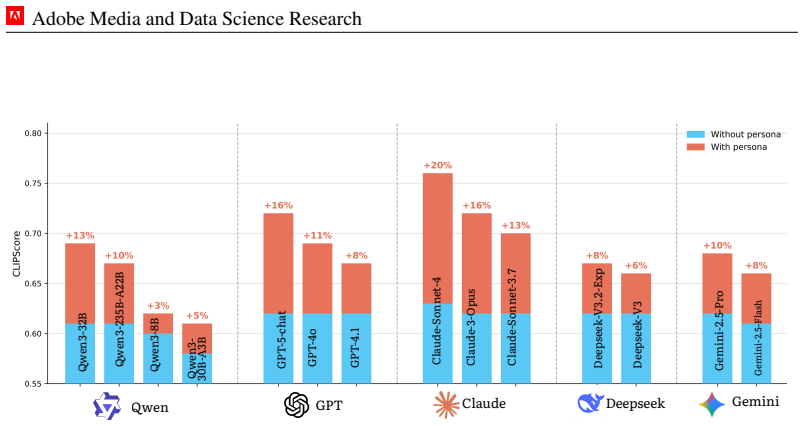
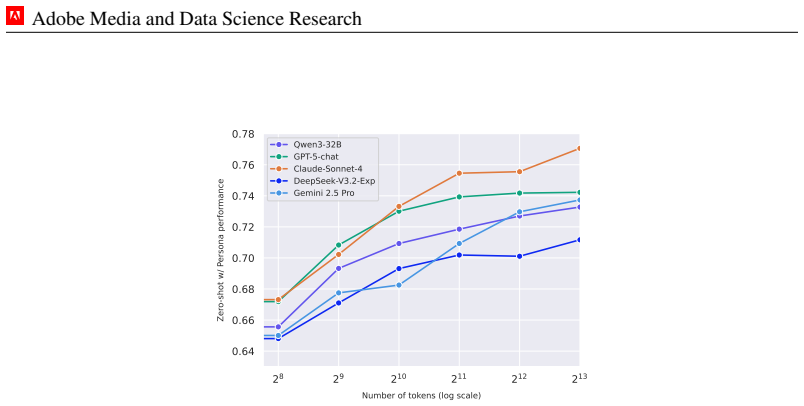

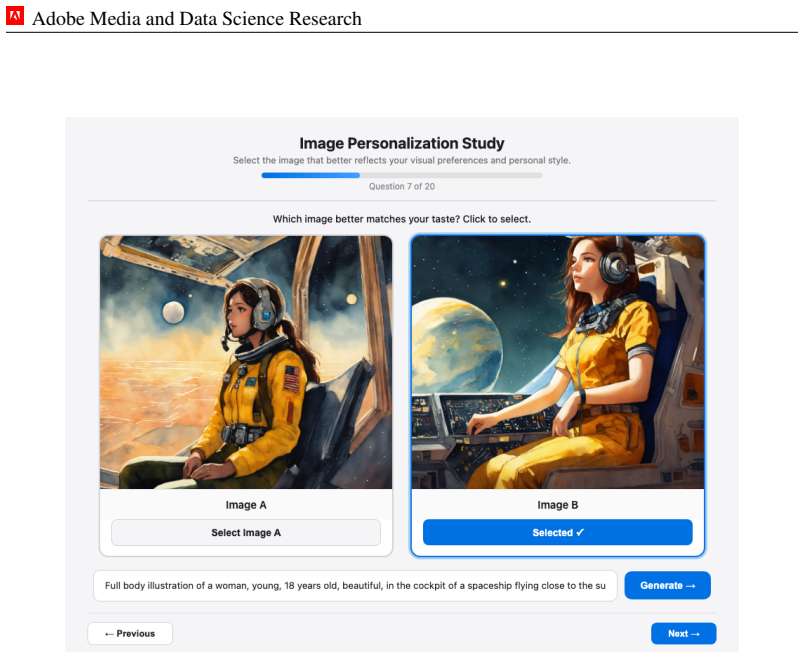
read the original abstract
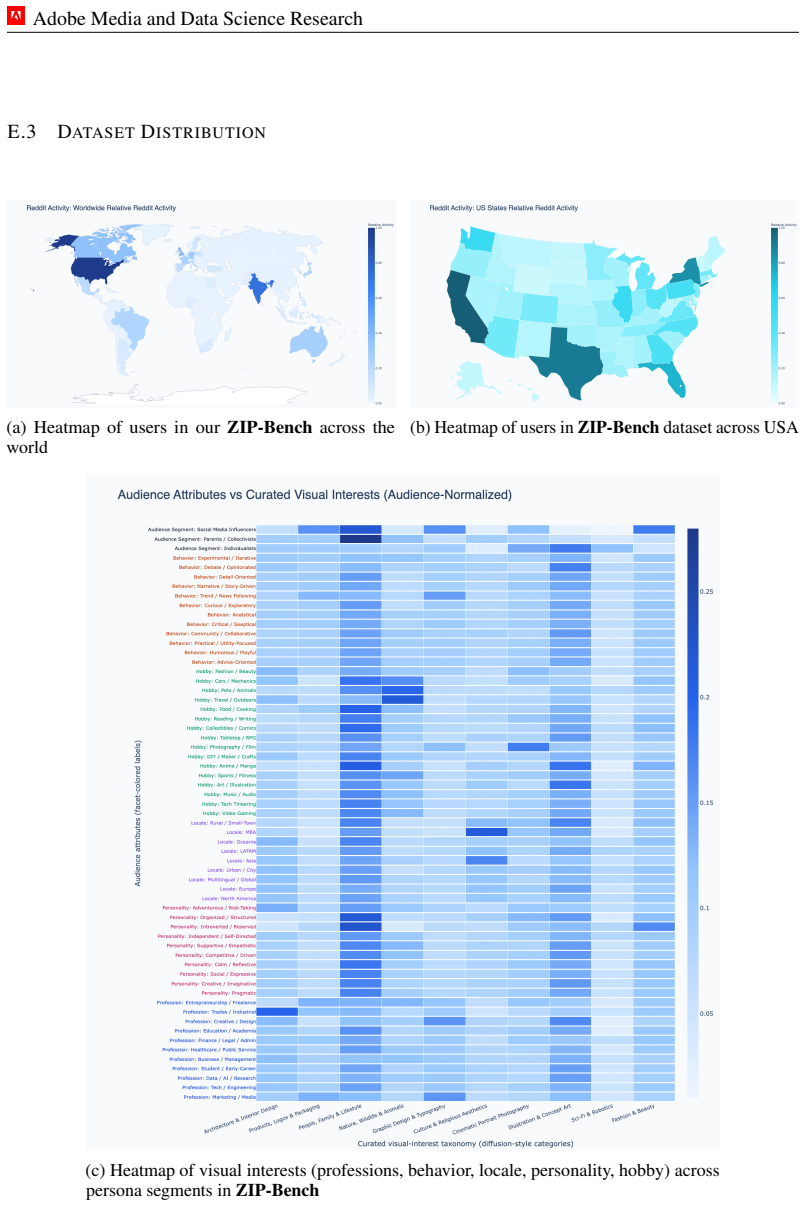
Text-to-image diffusion models are increasingly deployed in open-ended creative contexts, yet their outputs remain impersonal, optimized for aggregate aesthetics rather than individual taste. Human preferences are pluralistic: one user favoring muted, nostalgic portraits may prefer vibrant street photography, while another gravitates toward dreamy film aesthetics. Existing methods require dense interaction histories or per-user fine-tuning, failing in cold-start settings and collapsing context-dependent preferences into a static representation. We introduce zero-shot image personalization from personas (ZIPP), which conditions image generation on natural-language personas (concise descriptors of a user's identity and aesthetic sensibilities) without any user-specific data or weight updates. ZIPP uses an LLM to rewrite prompts from the perspective of a given persona, steering diffusion models toward personalized outputs. To mine personas at scale, we train an inductive Graph Attention Network over a 22M-user Reddit interaction graph with dual contrastive objectives aligning graph structure with visual behavior, then verbalize learned representations into natural-language personas via an MLLM. We introduce ZIPBench, the first zero-shot personalization benchmark with 1.5K users, graph-mined personas, and 40K generated images. Across four benchmarks and 14 LLMs spanning five model families, persona conditioning yields consistent gains (13-20%), with frontier models benefiting most. In the few-shot setting, ZIPP matches or exceeds fine-tuned baselines trained on 100+ examples per user. ZIPP achieves the lowest preference distributional divergence (CMMD 0.16 vs. 0.55), and IPF-normalized demographic evaluation shows it substantially reduces subpopulation bias present in existing methods. Human evaluation confirms a 79% win rate over generic generation and 58-65% over all fine-tuned baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ZIPP, a zero-shot method for personalizing text-to-image generation by conditioning on natural-language personas. These personas are mined at scale from a 22M-user Reddit interaction graph using an inductive GAT trained with dual contrastive objectives that align graph structure to visual behavior, then verbalized via an MLLM. The approach requires no user-specific data or fine-tuning. The authors introduce ZIPBench (1.5K users, 40K images) and report 13-20% gains across four benchmarks and 14 LLMs, a 79% human win rate over generic prompts, 58-65% over fine-tuned baselines, lowest CMMD divergence, and reduced subpopulation bias.
Significance. If the core claim holds—that graph-derived, verbalized personas faithfully capture stable, transferable aesthetic preferences—the method would enable scalable cold-start personalization without per-user data or updates, addressing a clear limitation of existing fine-tuning approaches. The multi-LLM evaluation spanning five families and the introduction of a dedicated benchmark are strengths that would support broader adoption if the persona fidelity is independently verified.
major comments (3)
- [Abstract] Abstract: The headline quantitative claims (13-20% gains, 79% human win rate, CMMD 0.16) are presented without error bars, statistical significance tests, or ablation studies isolating the GAT contrastive objectives, the verbalization step, or the graph-to-persona pipeline; this makes it impossible to determine whether reported improvements stem from genuine preference alignment or from generic prompt rewriting effects.
- [Abstract] Abstract: No held-out correlation, human fidelity rating of the verbalized personas, or ablation against direct user-provided descriptions is described to validate that the MLLM verbalization of GAT representations captures stable aesthetic preferences rather than noisy or generic signals from the Reddit graph; without such evidence the central transferability claim remains untested and the comparison to fine-tuned baselines cannot be interpreted as personalization.
- [Abstract] Abstract: The circular construction—personas derived from the identical Reddit interaction graph used to train the GAT—creates a risk that evaluation metrics are not independent of the contrastive alignment objectives, yet no cross-validation or out-of-graph testing protocol is mentioned to address this dependence.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below, committing to revisions that improve statistical rigor and evaluation clarity where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline quantitative claims (13-20% gains, 79% human win rate, CMMD 0.16) are presented without error bars, statistical significance tests, or ablation studies isolating the GAT contrastive objectives, the verbalization step, or the graph-to-persona pipeline; this makes it impossible to determine whether reported improvements stem from genuine preference alignment or from generic prompt rewriting effects.
Authors: We agree that error bars, significance tests, and targeted ablations would strengthen the presentation. The reported figures are averages across 14 LLMs and four benchmarks, but we will add standard deviations computed over multiple sampling runs and perform paired statistical tests. We will also include an ablation study isolating the dual contrastive objectives and the verbalization component by comparing against ablated variants. revision: yes
-
Referee: [Abstract] Abstract: No held-out correlation, human fidelity rating of the verbalized personas, or ablation against direct user-provided descriptions is described to validate that the MLLM verbalization of GAT representations captures stable aesthetic preferences rather than noisy or generic signals from the Reddit graph; without such evidence the central transferability claim remains untested and the comparison to fine-tuned baselines cannot be interpreted as personalization.
Authors: The human preference study (79% win rate) and CMMD results on generated images serve as the primary end-to-end validation that the personas transfer stable preferences. Direct user-provided descriptions are unavailable in the zero-shot regime we study. We will add a limited human fidelity rating study on sampled verbalized personas to provide additional direct evidence of alignment. revision: partial
-
Referee: [Abstract] Abstract: The circular construction—personas derived from the identical Reddit interaction graph used to train the GAT—creates a risk that evaluation metrics are not independent of the contrastive alignment objectives, yet no cross-validation or out-of-graph testing protocol is mentioned to address this dependence.
Authors: The contrastive objectives operate only during GAT training; evaluation metrics are computed on downstream image generation with new prompts and independent human judgments, which are decoupled from the training loss. The inductive GAT further supports generalization. We will expand the manuscript with explicit details on the train/evaluation split within ZIPBench and any cross-validation steps to clarify this independence. revision: partial
Circularity Check
No significant circularity; derivation chain is self-contained with independent benchmarks.
full rationale
The paper's core pipeline trains an inductive GAT on a 22M-user Reddit graph with dual contrastive objectives to produce representations, verbalizes them via MLLM into natural-language personas, and applies those personas for zero-shot prompt rewriting in diffusion models. ZIPBench is introduced as a new benchmark with 1.5K users and 40K images, and gains are reported against generic prompts, fine-tuned baselines, and human raters (79% win rate). No equation or step reduces the claimed personalization gains to the training inputs by construction, no self-citations are load-bearing for uniqueness or ansatz, and no fitted parameter is relabeled as a prediction. The evaluation metrics (CMMD, IPF, human preference) are presented as external to the contrastive alignment process.
Axiom & Free-Parameter Ledger
free parameters (2)
- GAT contrastive loss weights
- Persona verbalization temperature
axioms (2)
- domain assumption Reddit user interactions reflect stable aesthetic preferences independent of content topic
- domain assumption LLM prompt rewriting faithfully captures persona-specific visual taste without introducing its own biases
Reference graph
Works this paper leans on
-
[1]
FirstName LastName , title =
-
[2]
FirstName Alpher , title =
-
[3]
Journal of Foo , volume = 13, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe , title =. Journal of Foo , volume = 13, number = 1, pages =
-
[4]
Journal of Foo , volume = 14, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe and FirstName Gamow , title =. Journal of Foo , volume = 14, number = 1, pages =
-
[5]
FirstName Alpher and FirstName Gamow , title =
-
[6]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[7]
Pew Research Center: Numbers, Facts and Trends Shaping Your World , year =
-
[8]
The Annals of Mathematical Statistics , volume=
On a least squares adjustment of a sampled frequency table when the expected marginal totals are known , author=. The Annals of Mathematical Statistics , volume=. 1940 , publisher=
1940
-
[9]
arXiv preprint arXiv:2511.19458 , year=
Personalized Reward Modeling for Text-to-Image Generation , author=. arXiv preprint arXiv:2511.19458 , year=
-
[10]
2023 , eprint=
Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis , author=. 2023 , eprint=
2023
-
[11]
International conference on machine learning , pages=
Whose opinions do language models reflect? , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[12]
Behavioral and brain sciences , volume=
The weirdest people in the world? , author=. Behavioral and brain sciences , volume=. 2010 , publisher=
2010
-
[13]
2024 , eprint=
Rethinking FID: Towards a Better Evaluation Metric for Image Generation , author=. 2024 , eprint=
2024
-
[14]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Steering Guidance for Personalized Text-to-Image Diffusion Models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[15]
European Conference on Computer Vision , pages=
Fabric: Personalizing diffusion models with iterative feedback , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[16]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
ImageGem: In-the-wild Generative Image Interaction Dataset for Generative Model Personalization , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[17]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Draw Your Mind: Personalized Generation via Condition-Level Modeling in Text-to-Image Diffusion Models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[18]
Proceedings of the ACM on Web Conference 2025 , pages=
Personalized image generation with large multimodal models , author=. Proceedings of the ACM on Web Conference 2025 , pages=
2025
-
[19]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Tailored visions: Enhancing text-to-image generation with personalized prompt rewriting , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[20]
arXiv preprint arXiv:2306.00983 , year=
Styledrop: Text-to-image generation in any style , author=. arXiv preprint arXiv:2306.00983 , year=
-
[21]
arXiv preprint arXiv:2208.01618 , year=
An image is worth one word: Personalizing text-to-image generation using textual inversion , author=. arXiv preprint arXiv:2208.01618 , year=
-
[22]
arXiv preprint arXiv:2405.17532 , year=
Classdiffusion: More aligned personalization tuning with explicit class guidance , author=. arXiv preprint arXiv:2405.17532 , year=
-
[23]
2024 , eprint=
ViPer: Visual Personalization of Generative Models via Individual Preference Learning , author=. 2024 , eprint=
2024
-
[24]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Multi-concept customization of text-to-image diffusion , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[25]
arXiv preprint arXiv:2406.20094 , year=
Scaling synthetic data creation with 1,000,000,000 personas , author=. arXiv preprint arXiv:2406.20094 , year=
-
[26]
International Journal of Human-Computer Studies , volume=
PersonaCraft: Leveraging language models for data-driven persona development , author=. International Journal of Human-Computer Studies , volume=. 2025 , publisher=
2025
-
[27]
Proceedings of the 2024 ACM Designing Interactive Systems Conference , pages=
Understanding human-AI workflows for generating personas , author=. Proceedings of the 2024 ACM Designing Interactive Systems Conference , pages=
2024
-
[28]
Park, Joon Sung and O'Brien, Joseph and Cai, Carrie Jun and Morris, Meredith Ringel and Liang, Percy and Bernstein, Michael S. , title =. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology , articleno =. 2023 , isbn =. doi:10.1145/3586183.3606763 , abstract =
-
[29]
Tseng, Yu-Min and Huang, Yu-Chao and Hsiao, Teng-Yun and Chen, Wei-Lin and Huang, Chao-Wei and Meng, Yu and Chen, Yun-Nung. Two Tales of Persona in LLM s: A Survey of Role-Playing and Personalization. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.969
-
[30]
arXiv preprint arXiv:2404.13957 , year=
How well can LLMs echo us? evaluating AI chatbots' role-play ability with ECHO , author=. arXiv preprint arXiv:2404.13957 , year=
-
[31]
arXiv preprint arXiv:2305.11482 , year=
Enhancing personalized dialogue generation with contrastive latent variables: Combining sparse and dense persona , author=. arXiv preprint arXiv:2305.11482 , year=
-
[32]
2023 , eprint=
PALR: Personalization Aware LLMs for Recommendation , author=. 2023 , eprint=
2023
-
[33]
2024 , eprint=
Cognitive Personalized Search Integrating Large Language Models with an Efficient Memory Mechanism , author=. 2024 , eprint=
2024
-
[34]
arXiv preprint arXiv:2507.21509 , year=
Persona vectors: Monitoring and controlling character traits in language models , author=. arXiv preprint arXiv:2507.21509 , year=
-
[35]
arXiv preprint arXiv:2502.11078 , year=
Deeper insight into your user: Directed persona refinement for dynamic persona modeling , author=. arXiv preprint arXiv:2502.11078 , year=
-
[36]
2024 , eprint=
Better Zero-Shot Reasoning with Role-Play Prompting , author=. 2024 , eprint=
2024
-
[37]
Teaching Human Behavior Improves Content Understanding Abilities Of
Somesh Kumar Singh and Harini S I and Yaman Kumar Singla and Changyou Chen and Rajiv Ratn Shah and Veeky Baths and Balaji Krishnamurthy , booktitle=. Teaching Human Behavior Improves Content Understanding Abilities Of. 2025 , url=
2025
-
[38]
arXiv preprint arXiv:2102.12092 , year =
Zero-Shot Text-to-Image Generation , author =. arXiv preprint arXiv:2102.12092 , year =
-
[39]
2025 , howpublished =
Gemini 2.5 Flash Image (Nano Banana): Multimodal Diffusion for Image Generation , author =. 2025 , howpublished =
2025
-
[40]
2024 , howpublished =
Adobe Firefly: Generative AI for Creative Content , author =. 2024 , howpublished =
2024
-
[41]
2024 , note =
OpenAI , title =. 2024 , note =
2024
-
[42]
arXiv preprint arXiv:2508.02324 , year =
Qwen-Image Technical Report , author =. arXiv preprint arXiv:2508.02324 , year =
-
[43]
Advances in neural information processing systems , volume=
Pick-a-pic: An open dataset of user preferences for text-to-image generation , author=. Advances in neural information processing systems , volume=
-
[44]
Graph convolutional neural networks for web-scale recommender systems,
Ying, Rex and He, Ruining and Chen, Kaifeng and Eksombatchai, Pong and Hamilton, William L. and Leskovec, Jure , year=. Graph Convolutional Neural Networks for Web-Scale Recommender Systems , url=. doi:10.1145/3219819.3219890 , booktitle=
-
[45]
2022 , eprint=
How Attentive are Graph Attention Networks? , author=. 2022 , eprint=
2022
-
[46]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[47]
arXiv preprint arXiv:2510.25536 , year=
TwinVoice: A Multi-dimensional Benchmark Towards Digital Twins via LLM Persona Simulation , author=. arXiv preprint arXiv:2510.25536 , year=
-
[48]
Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval , pages=
Lightgcn: Simplifying and powering graph convolution network for recommendation , author=. Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval , pages=
-
[49]
2018 , eprint=
Inductive Representation Learning on Large Graphs , author=. 2018 , eprint=
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.