Memory Architectures for Multi-Turn Text-to-SQL: A Benchmark and Empirical Study
Pith reviewed 2026-06-29 21:10 UTC · model grok-4.3
The pith
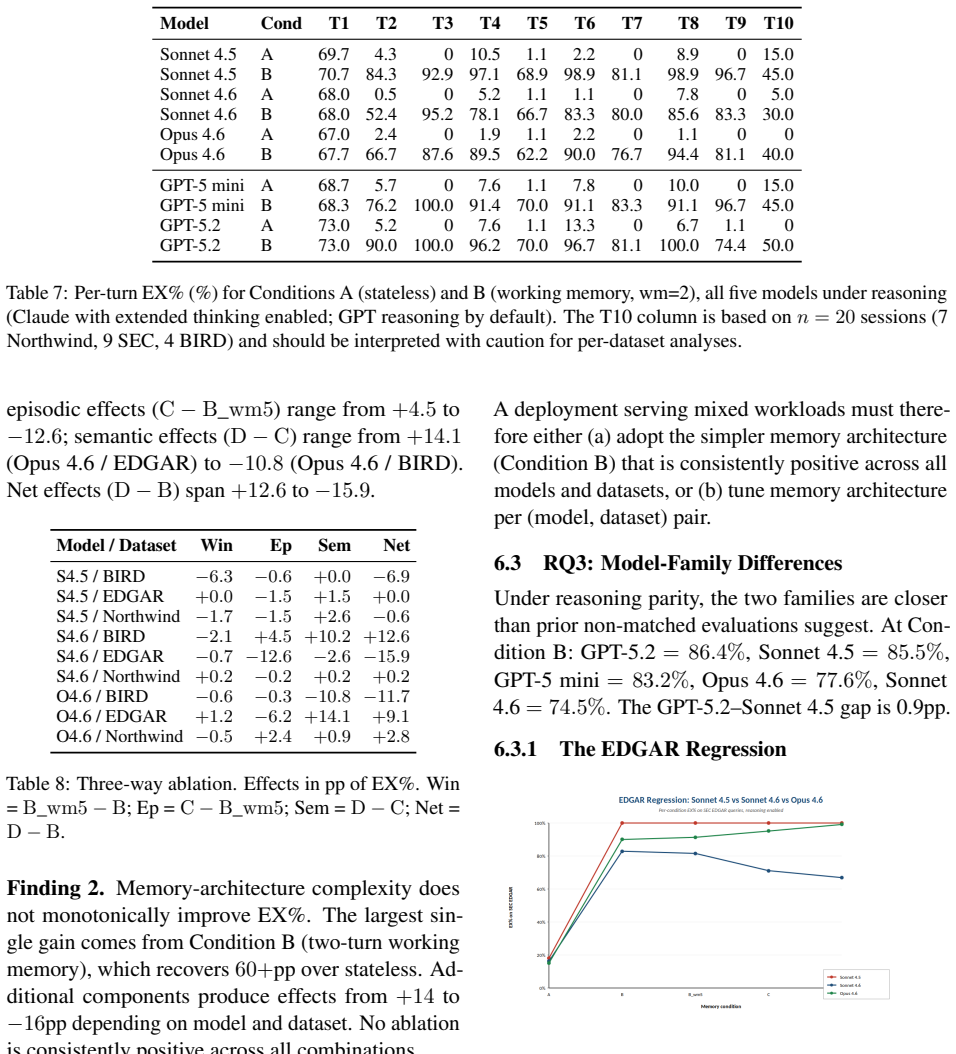
Stateless multi-turn Text-to-SQL collapses to zero execution accuracy by Turn 3 across all tested models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
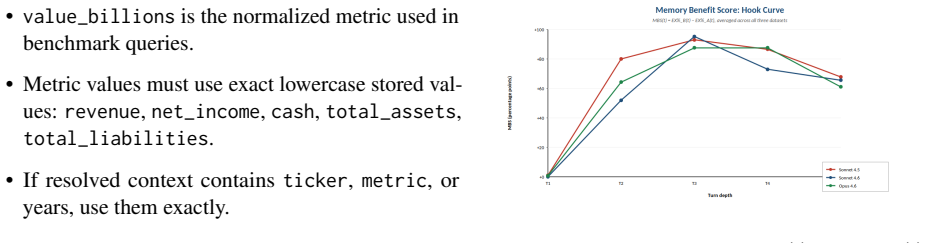
Multi-turn Text-to-SQL without memory support loses all execution accuracy by Turn 3 across GPT-5 mini, GPT-5.2, Claude Sonnet 4.5, Sonnet 4.6, and Opus 4.6; working memory dominates performance while extra memory modules produce model- and dataset-dependent swings from +14 to -16 points, and Claude models exhibit a generational regression on SEC EDGAR plus mono-modal wrong-result errors under reasoning.
What carries the argument
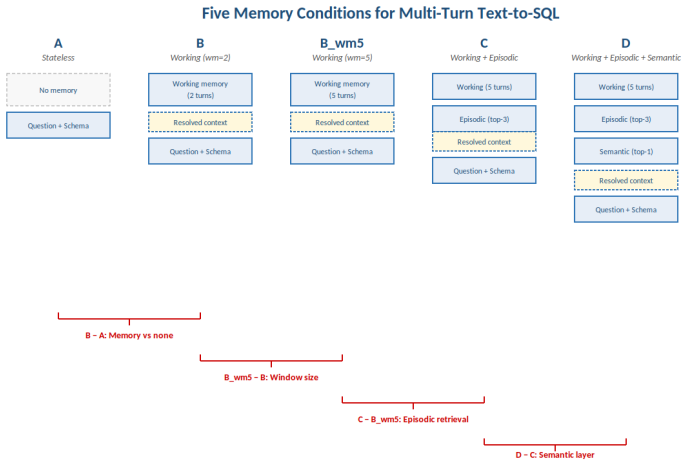
Three-way ablation of working-memory window size, episodic retrieval, and semantic augmentation, scored per turn with the Memory Benefit Score on the EnterpriseMem-Bench sessions.
Load-bearing premise
The programmatically generated sessions and per-turn memory-critical annotations accurately isolate the independent effects of working-memory window size, episodic retrieval, and semantic augmentation without introducing confounding artifacts from the generation process.
What would settle it
Sustained non-zero execution accuracy past Turn 2 in a stateless condition on the same enterprise query distributions would falsify the central collapse claim.
Figures
read the original abstract
Multi-turn Text-to-SQL is central to enterprise analytics yet remains predominantly evaluated in single-turn settings. We introduce EnterpriseMem-Bench, a multi-turn Text-to-SQL benchmark of 300 sessions and 1,400 turns built programmatically from three enterprise domains (BIRD financial, SEC EDGAR, Northwind), with deterministic ground truth and per-turn memory-critical annotation. We evaluate five frontier models -- GPT-5 mini, GPT-5.2, Claude Sonnet 4.5, Sonnet 4.6, and Opus 4.6 -- across five memory conditions enabling a three-way ablation isolating working-memory window size, episodic retrieval, and semantic augmentation as independent effects. All Claude models are evaluated with extended thinking enabled to maintain parity with GPT reasoning models. We introduce the Memory Benefit Score (MBS) as a per-turn diagnostic metric. Four findings emerge: (1) stateless multi-turn Text-to-SQL collapses to zero execution accuracy by Turn 3 across all five models, even under reasoning; (2) memory-architecture complexity does not monotonically improve accuracy -- working memory dominates, and additional components produce model- and dataset-dependent effects from +14 to -16 percentage points; (3) Claude Sonnet 4.6 underperforms Sonnet 4.5 by 17-33pp on SEC EDGAR across conditions, a generational regression persisting under reasoning; (4) under reasoning, Claude error distributions become mono-modal -- every non-correct turn is a wrong-result error. We release the benchmark, agent, and evaluation code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EnterpriseMem-Bench, a multi-turn Text-to-SQL benchmark of 300 sessions (1,400 turns) built programmatically from BIRD financial, SEC EDGAR, and Northwind domains, with deterministic ground truth and per-turn memory-critical annotations. It evaluates five frontier models (GPT-5 mini, GPT-5.2, Claude Sonnet 4.5/4.6, Opus 4.6) under five memory conditions that enable a three-way ablation of working-memory window size, episodic retrieval, and semantic augmentation. The authors introduce the Memory Benefit Score (MBS) and report four findings: stateless multi-turn Text-to-SQL reaches zero execution accuracy by Turn 3 across all models even with reasoning; memory-architecture benefits are non-monotonic and range from +14 to -16 pp depending on model and dataset; Claude Sonnet 4.6 shows a 17-33 pp regression vs. 4.5 on SEC EDGAR; and reasoning makes Claude error distributions mono-modal. All artifacts are released.
Significance. If the sessions genuinely isolate memory dependencies, the work supplies concrete evidence that stateless interaction is insufficient for multi-turn enterprise Text-to-SQL and supplies a reusable ablation framework plus the MBS diagnostic. The public release of the benchmark, agent, and evaluation code is a clear strength that supports reproducibility and independent verification of the zero-accuracy result.
major comments (2)
- [§3 (Benchmark Construction)] §3 (Benchmark Construction): The description of programmatic session generation from single-turn BIRD/SEC EDGAR/Northwind examples provides no validation metrics or controls showing that the injected memory-critical dependencies cannot be resolved from schema information or domain knowledge alone. This validation is load-bearing for the central claim that stateless accuracy collapses to zero by Turn 3.
- [§4 (Experiments)] §4 (Experiments): The reported accuracies, MBS values, and non-monotonic effects (+14 to -16 pp) are presented without statistical testing, confidence intervals, or details on prompt templates and sampling parameters. These omissions directly affect the reliability of the zero-accuracy and ablation findings.
minor comments (2)
- The five memory conditions should be summarized in a single table with exact component combinations for quick reference.
- Clarify whether extended thinking for Claude models was applied uniformly across all memory conditions or only selected ones.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the benchmark construction and experimental details. We address each major comment below and will revise the manuscript accordingly to strengthen the claims.
read point-by-point responses
-
Referee: [§3 (Benchmark Construction)] §3 (Benchmark Construction): The description of programmatic session generation from single-turn BIRD/SEC EDGAR/Northwind examples provides no validation metrics or controls showing that the injected memory-critical dependencies cannot be resolved from schema information or domain knowledge alone. This validation is load-bearing for the central claim that stateless accuracy collapses to zero by Turn 3.
Authors: We acknowledge that the manuscript does not include explicit validation experiments (such as schema-only or domain-knowledge-only prompts on the memory-critical turns) to quantify how often the injected dependencies can be resolved without conversation history. The programmatic construction introduces referential links, cumulative filters, and entity carry-overs that are annotated per turn as requiring prior context, and the observed zero accuracy in the stateless condition (with full schema access) provides supporting evidence. However, to directly address the concern, we will add a validation subsection in §3 reporting (1) failure rates on memory turns when models receive only the schema plus domain descriptions, and (2) inter-annotator agreement on a 50-session sample confirming the memory-critical labels. These controls will be included in the revised version. revision: yes
-
Referee: [§4 (Experiments)] §4 (Experiments): The reported accuracies, MBS values, and non-monotonic effects (+14 to -16 pp) are presented without statistical testing, confidence intervals, or details on prompt templates and sampling parameters. These omissions directly affect the reliability of the zero-accuracy and ablation findings.
Authors: We agree that the absence of statistical testing, confidence intervals, and full implementation details limits the strength of the reported findings. The current version presents point estimates only. In revision we will (1) add bootstrap 95% confidence intervals for all accuracy and MBS values, (2) include paired statistical tests (McNemar’s test) for the ablation comparisons that produce the +14 to -16 pp effects, and (3) append the complete prompt templates together with sampling parameters (temperature, top_p, max_tokens, reasoning effort) for each model in a new appendix. These additions will be made to §4 and the supplementary material. revision: yes
Circularity Check
No circularity: empirical benchmark evaluation with no derivations or self-referential quantities
full rationale
The paper is a purely empirical study that introduces a benchmark (EnterpriseMem-Bench) via programmatic generation from existing single-turn datasets, evaluates five models under five memory conditions, and reports observed accuracies and error patterns. No equations, fitted parameters, predictions derived from first principles, or load-bearing self-citations appear in the abstract or described methodology. The central claims (e.g., stateless collapse to zero accuracy by Turn 3) are direct measurements against released ground truth, not reductions to inputs by construction. The Memory Benefit Score is introduced as a diagnostic metric without any claim that it is derived from or equivalent to the benchmark itself. Per the hard rules, this self-contained empirical work against external benchmarks receives score 0 with empty steps.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Memory Benefit Score (MBS)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Evaluating and Enhancing LLMs for Multi-turn Text-to-SQL with Multiple Question Types. arXiv:2412.17867. [IJCNN 2025]. Zijin Hong, Zheng Yuan, Qinggang Zhang, Hao Chen, Junnan Dong, Feiran Huang, and Xiao Huang
-
[2]
Next-Generation Database Interfaces: A Survey of LLM-based Text-to-SQL. arXiv:2406.08426. Nan Huo, Jinyang Li, Yan Xu, Ge Qu, Reynold Cheng, and colleagues
-
[3]
BIRD-INTERACT: Re- imagining Text-to-SQL Evaluation for Large Lan- guage Models via Lens of Dynamic Interactions. arXiv:2510.05318. [ICLR 2026, Oral]. Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, and others
-
[4]
In Advances in Neural Information Processing Systems 36 (NeurIPS 2023 Datasets and Benchmarks Track)
Can LLM Already Serve as a Database Interface? A Big Bench for Large- Scale Database Grounded Text-to-SQLs (BIRD). In Advances in Neural Information Processing Systems 36 (NeurIPS 2023 Datasets and Benchmarks Track). arXiv:2305.03111. Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mo- hit Bansal, Francesco Barbieri, and Yuwei Fang
-
[5]
Evaluating Very Long-Term Conversational Memory of LLM Agents
Evaluating Very Long-Term Conversational Memory of LLM Agents. InProceedings of ACL 2024 (Long Papers), pages 13851–13870. arXiv:2402.17753. Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
MemGPT: Towards LLMs as Operating Systems
MemGPT: Towards LLMs as Operating Systems. arXiv:2310.08560. Mohammadreza Pourreza and Davood Rafiei
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
InAdvances in Neural Information Processing Systems 36 (NeurIPS 2023)
DIN- SQL: Decomposed In-Context Learning of Text-to- SQL with Self-Correction. InAdvances in Neural Information Processing Systems 36 (NeurIPS 2023). arXiv:2304.11015. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V . Le, and Denny Zhou
-
[8]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Chain-of-Thought Prompting Elic- its Reasoning in Large Language Models. InAdvances in Neural Information Processing Systems 35 (NeurIPS 2022). arXiv:2201.11903. Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
A-MEM: Agentic Memory for LLM Agents
A-MEM: Agentic Mem- ory for LLM Agents. arXiv:2502.12110. [NeurIPS 2025]. Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingn- ing Yao, Shanelle Roman, Zilin Zhang, and Dragomir Radev
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
InProceedings of EMNLP 2018, pages 3911–3921
Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Pars- ing and Text-to-SQL Task. InProceedings of EMNLP 2018, pages 3911–3921. Tao Yu, Rui Zhang, Michihiro Yasunaga, Yi Chern Tan, Xi Victoria Lin, Suyi Li, Heyang Er, Irene Li, Bo Pang, Tao Chen, Emily Ji, Shreya Dixit, David Proctor, Sun- grok Shim, Jonathan Kraft, Vincent...
2018
-
[11]
A Survey on the Memory Mechanism of Large Language Model based Agents
A Survey on the Memory Mechanism of Large Language Model based Agents. arXiv:2404.13501. A Verbatim Prompts and Source Guidance A.1 System Prompt (identical across models and conditions) “You are an expert SQLite analyst. Generate one valid SQLite query for the user’s question. Return SQL only. No markdown, comments, or explanation. Use only the provided ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
•Turn 6:Which year was higher for cash? •Turn 7:Show total assets for those years
G5m=GPT-5 mini, G5.2=GPT-5.2. •Turn 6:Which year was higher for cash? •Turn 7:Show total assets for those years. •Turn 8:Which year was higher for total assets? •Turn 9:And total liabilities? Turn 9 references ticker and years from Turn 1, eight turns prior. Only memory conditions with suf- ficient window depth or effective episodic retrieval can answer T...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.