Discovering Functionally Selective Brain Regions with a Deep Topographic Multimodal Model
Pith reviewed 2026-06-27 14:06 UTC · model grok-4.3
The pith
A single spatial smoothness principle organizes brain-like clusters across vision, audition, and language in one contiguous model sheet.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
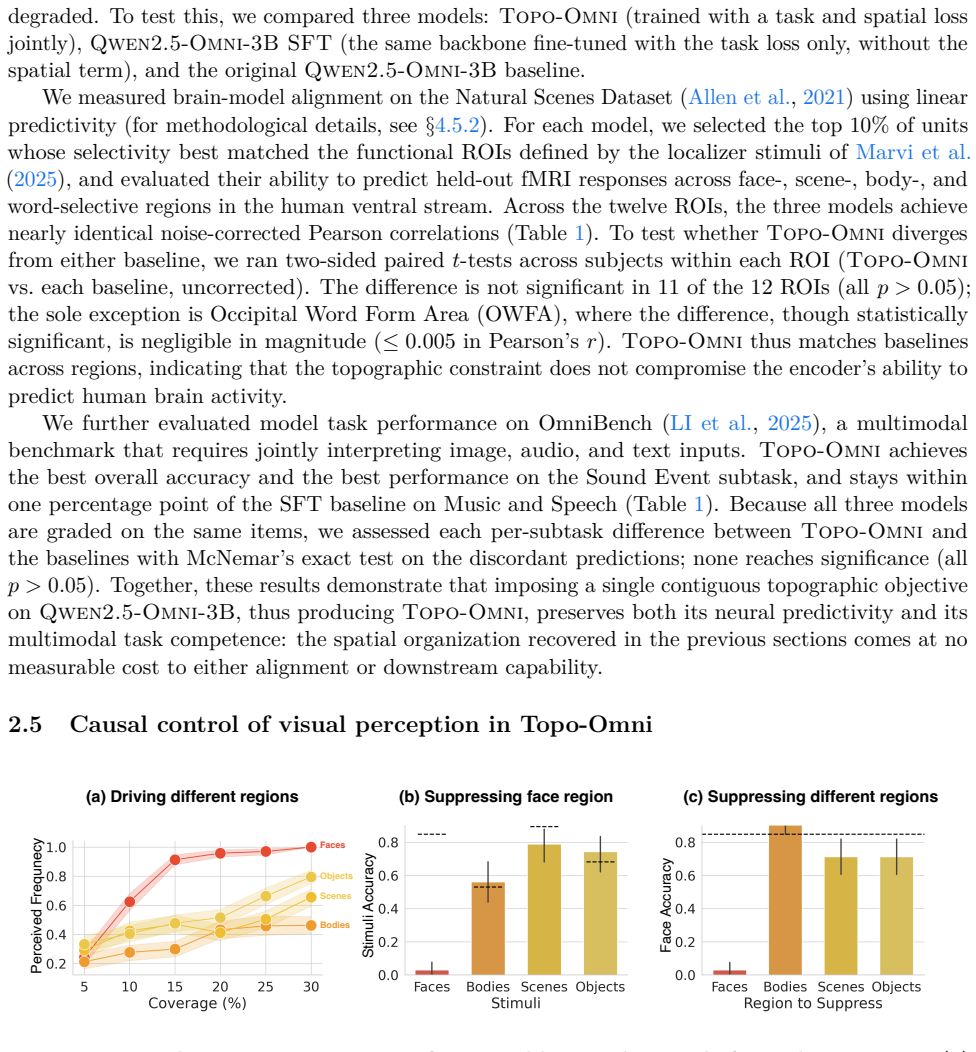
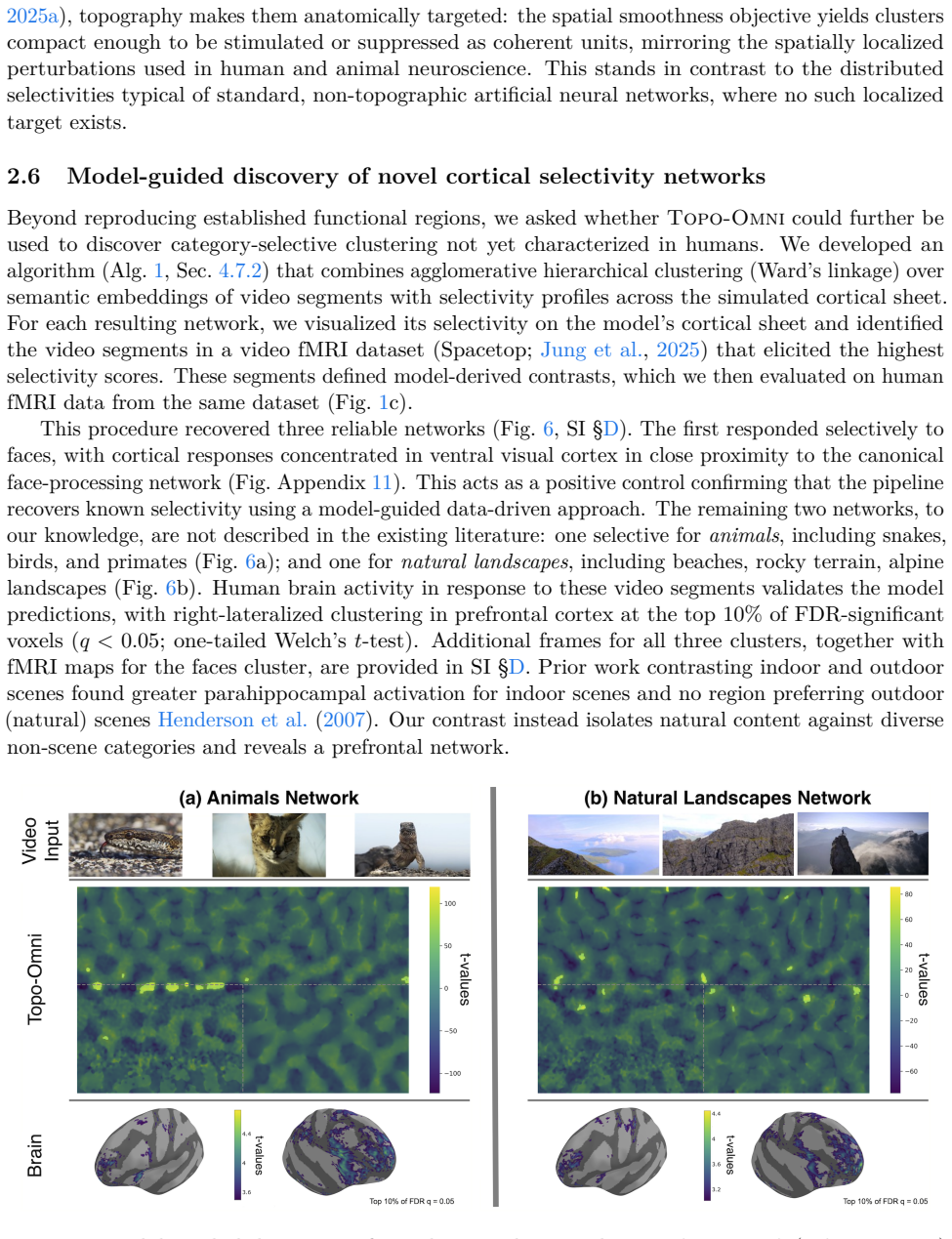
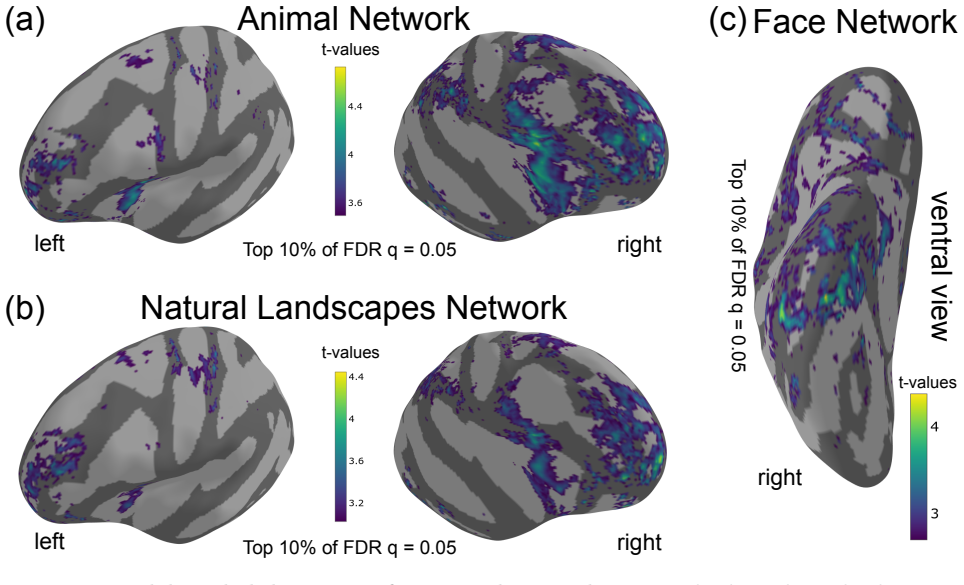
The central claim is that fine-tuning a pretrained foundation model with a spatial smoothness objective on a single contiguous in-silico sheet yields functionally selective clusters consistent with human neuroimaging across modalities and processing stages. Driving or suppressing these clusters selectively biases or impairs perception. Screening the model in-silico reveals new clusters for natural landscapes and animals that match human neuroimaging data.
What carries the argument
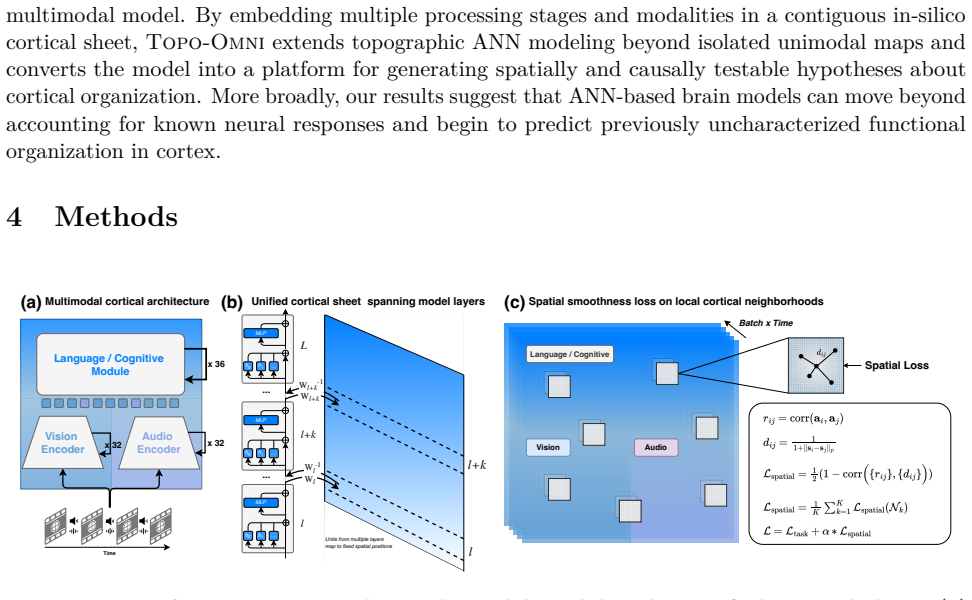
The Topo-Omni architecture, a single contiguous sheet for multimodal processing optimized by a spatial smoothness objective during fine-tuning.
Load-bearing premise
The spatial smoothness objective applied during fine-tuning of a pretrained foundation model is sufficient to produce clusters consistent with human neuroimaging data across modalities without requiring modality-specific constraints or post-hoc selection.
What would settle it
Human neuroimaging data that does not show the predicted clusters for the newly discovered landscape and animal networks would falsify the claim that the smoothness objective alone produces consistent multimodal organization.
Figures






read the original abstract
Nearby neurons in cortex share similar response profiles, producing systematic spatial organization across sensory and cognitive systems. Recent topographic models reproduce aspects of this structure but remain unimodal and spatially constrain each layer separately, yielding fragmented maps that capture neither the contiguity of cortical processing streams nor their integration across modalities. We introduce Topo-Omni, a topographic multimodal model in which visual, auditory, and language/cognitive processing share a single contiguous in-silico sheet. Built by fine-tuning a pretrained foundation model with a spatial smoothness objective, this architecture develops clusters across modalities that are consistent with human neuroimaging, from sensory to cognitive systems. Driving or suppressing a cluster selectively biases or impairs perception, paralleling human intervention studies. Finally, we use our model to screen for novel clusters in-silico and discover new natural landscape and animal networks which we validate in human data. A single spatial principle thus organizes representations across modalities and processing stages, yielding testable hypotheses about cortical organization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Topo-Omni, a topographic multimodal model constructed by fine-tuning a pretrained foundation model with a single spatial smoothness objective. This produces a contiguous in-silico cortical sheet integrating visual, auditory, and language/cognitive processing. The model yields clusters consistent with human neuroimaging data from sensory to cognitive systems, supports selective interventions that parallel human studies, and enables in-silico discovery of novel functionally selective regions (e.g., natural landscape and animal networks) that are validated against human data. The central claim is that a single spatial principle organizes representations across modalities and processing stages.
Significance. If the quantitative support for cluster consistency, intervention effects, and novel-region validation holds, the work would be significant for demonstrating that a modality-agnostic spatial smoothness objective during fine-tuning can induce cross-modal topographic organization matching human data without separate per-layer or per-modality constraints. The in-silico discovery of new networks subsequently validated in human neuroimaging would constitute a concrete, falsifiable contribution to cortical organization hypotheses.
major comments (2)
- [Abstract] Abstract: the claim that clusters 'are consistent with human neuroimaging' and that interventions 'parallel human intervention studies' supplies no quantitative metrics, statistical tests, control conditions, or details on how consistency or parallelism was measured. This absence is load-bearing for the central claim that a single spatial principle suffices.
- [Abstract] Abstract: the assertion that the spatial smoothness objective alone produces clusters 'across modalities' without modality-specific constraints or post-hoc selection is not accompanied by ablation results or comparisons to models lacking the objective, leaving the sufficiency claim unevaluable from the provided description.
Simulated Author's Rebuttal
We thank the referee for these focused comments on the abstract. The abstract is necessarily concise, but we agree it should better convey the quantitative support present in the full manuscript. We address each point below and will revise the abstract in the next version.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that clusters 'are consistent with human neuroimaging' and that interventions 'parallel human intervention studies' supplies no quantitative metrics, statistical tests, control conditions, or details on how consistency or parallelism was measured. This absence is load-bearing for the central claim that a single spatial principle suffices.
Authors: The full manuscript reports quantitative metrics (e.g., Dice overlap and Pearson correlations with human fMRI parcellations), statistical tests (permutation tests against null models), and control conditions (random cluster interventions) for both cluster consistency and intervention effects. These appear in the Results sections on topographic alignment and causal interventions. To make the abstract self-contained on this load-bearing claim, we will add concise quantitative statements and note the statistical controls. revision: yes
-
Referee: [Abstract] Abstract: the assertion that the spatial smoothness objective alone produces clusters 'across modalities' without modality-specific constraints or post-hoc selection is not accompanied by ablation results or comparisons to models lacking the objective, leaving the sufficiency claim unevaluable from the provided description.
Authors: The manuscript contains ablation experiments that remove the spatial smoothness loss (or replace it with modality-specific constraints) and show degraded cross-modal contiguity and functional selectivity. These comparisons are reported with quantitative metrics in the Methods and Results. We will revise the abstract to briefly reference the ablation outcomes supporting sufficiency of the single objective. revision: yes
Circularity Check
No significant circularity
full rationale
The paper fine-tunes a pretrained model using an explicit spatial smoothness objective and then validates the resulting clusters against independent human neuroimaging data across modalities. The central claim—that a single spatial principle organizes representations—is tested by external comparison rather than by construction from fitted parameters or self-referential definitions. No load-bearing step reduces to a self-citation chain, a fitted input renamed as prediction, or an ansatz smuggled via prior work by the same authors. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Spatial smoothness during fine-tuning of a pretrained foundation model produces functionally selective clusters consistent with human neuroimaging across modalities.
Reference graph
Works this paper leans on
-
[1]
Abraham, A., Pedregosa, F., Eickenberg, M., Gervais, P., Mueller, A., Kossaifi, J., Gramfort, A., Thirion, B., and Varoquaux, G. (2014). Machine learning for neuroimaging with scikit-learn. Frontiers in Neuroinformatics,
2014
-
[2]
AlKhamissi, B., Tuckute, G., Bosselut, A., and Schrimpf, M. (2025a). The LLM language network: A neuroscientific approach for identifying causally task-relevant units. pages 10887–10911. AlKhamissi, B., Tuckute, G., Tang, Y., Binhuraib, T. O. A., Bosselut, A., and Schrimpf, M. (2025b). From language to cognition: How LLMs outgrow the human language networ...
-
[3]
N., Winawer, J., Mezer, A., and Wandell, B
Kay, K. N., Winawer, J., Mezer, A., and Wandell, B. A. (2013b). Compressive spatial summation in human visual cortex.Journal of Neurophysiology, 110(2):481–494. Kell, A. J., Yamins, D. L., Shook, E. N., Norman-Haignere, S. V., and McDermott, J. H. (2018). A task-optimized neural network replicates human auditory behavior, predicts brain responses, and rev...
-
[4]
Kriegeskorte, N., Cusack, R., and Bandettini, P. (2010). How does an fMRI voxel sample the neuronal activity pattern: Compact-kernel or complex spatiotemporal filter?NeuroImage, 49(3):1965–1976. Lee, H., Margalit, E., Jozwik, K. M., Cohen, M. A., Kanwisher, N., Yamins, D. L. K., and DiCarlo, J. J. (2020). Topographic deep artificial neural networks reprod...
-
[5]
25 Mehrer, J., Lonnqvist, B., Mitola, A., Papale, P., and Schrimpf, M. (2026). Model-guided microstimu- lation steers primate visual behavior. Mehrer, J., Spoerer, C. J., Jones, E. C., Kriegeskorte, N., and Kietzmann, T. C. (2021). An ecologically motivated image dataset for deep learning yields better models of human vision.Proceedings of the National Ac...
2026
-
[6]
Rimsky, N., Gabrieli, N., Schulz, J., Tong, M., Hubinger, E., and Turner, A. (2024). Steering llama 2 via contrastive activation addition. pages 15504–15522. Saygin, Z. M., Osher, D. E., Norton, E. S., Youssoufian, D. A., Beach, S. D., Feather, J., Gaab, N., Gabrieli, J. D. E., and Kanwisher, N. (2016). Connectivity precedes function in the development of...
-
[7]
Schrimpf, M., McGrath, P., Margalit, E., and DiCarlo, J. J. (2024). Do Topographic ANNs Predict the Behavioral Effects of Neural Interventions in Primate IT Cortex?Bioarxiv. Shen, G., Zhao, D., Dong, Y., Zhang, Q., and Zeng, Y. (2025). Alignment between brains and ai: Evidence for convergent evolution across modalities, scales and training trajectories.ar...
-
[8]
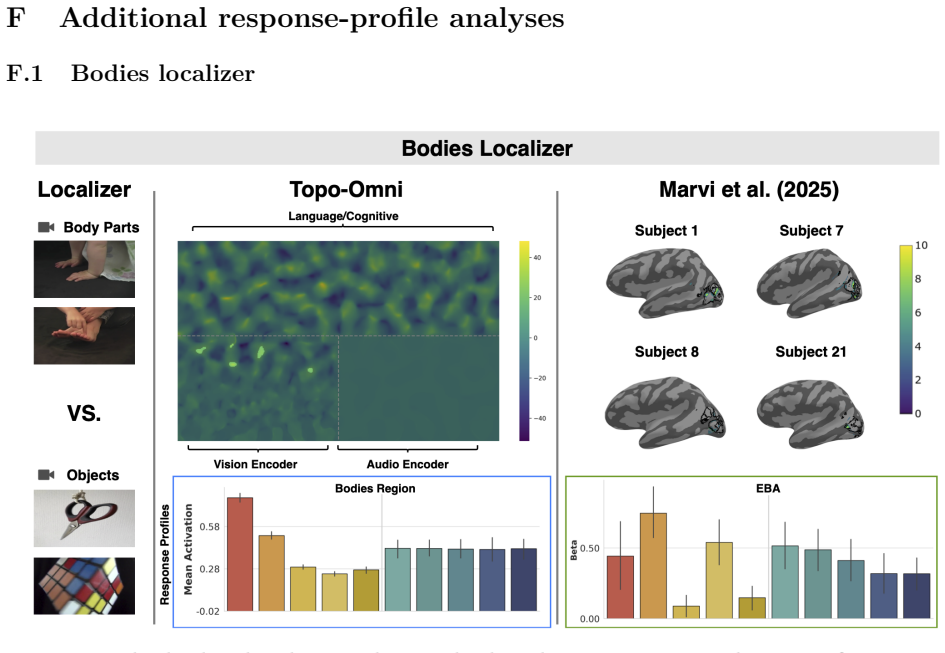
(2025), using the 6 participants (nr
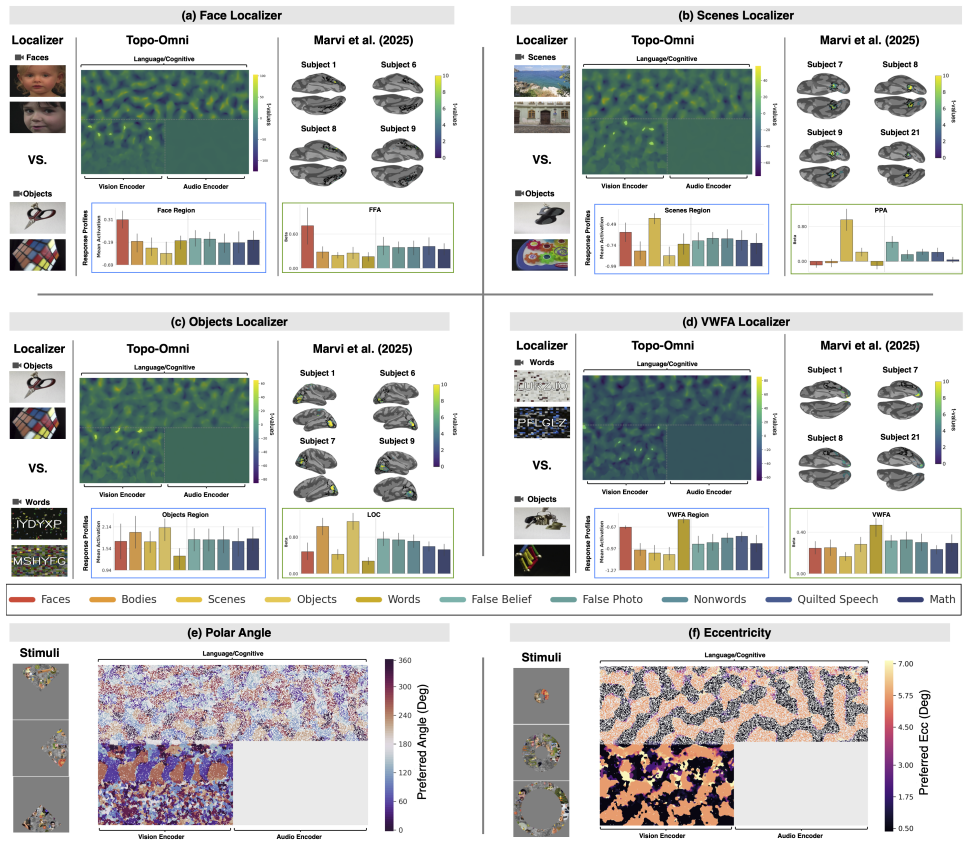
A fMRI data processing: Vision, Audio, Higher-level Cognition fMRI Dataset and Participants.We analyzed all publicly available fMRI data from Marvi et al. (2025), using the 6 participants (nr. 1, 6, 7, 8, 9, and
2025
-
[9]
who completed the Efficient Multifunction fMRI Localizer experiment (EMFL). The EMFL comprises 5 runs of approximately 3 minutes each (total∼14 minutes scan time), in which participants viewed video stimuli drawn from 5 visual categories (faces, bodies, scenes, objects, words-on-scrambled-background) while simultaneously listening to auditory stimuli from...
2025
-
[10]
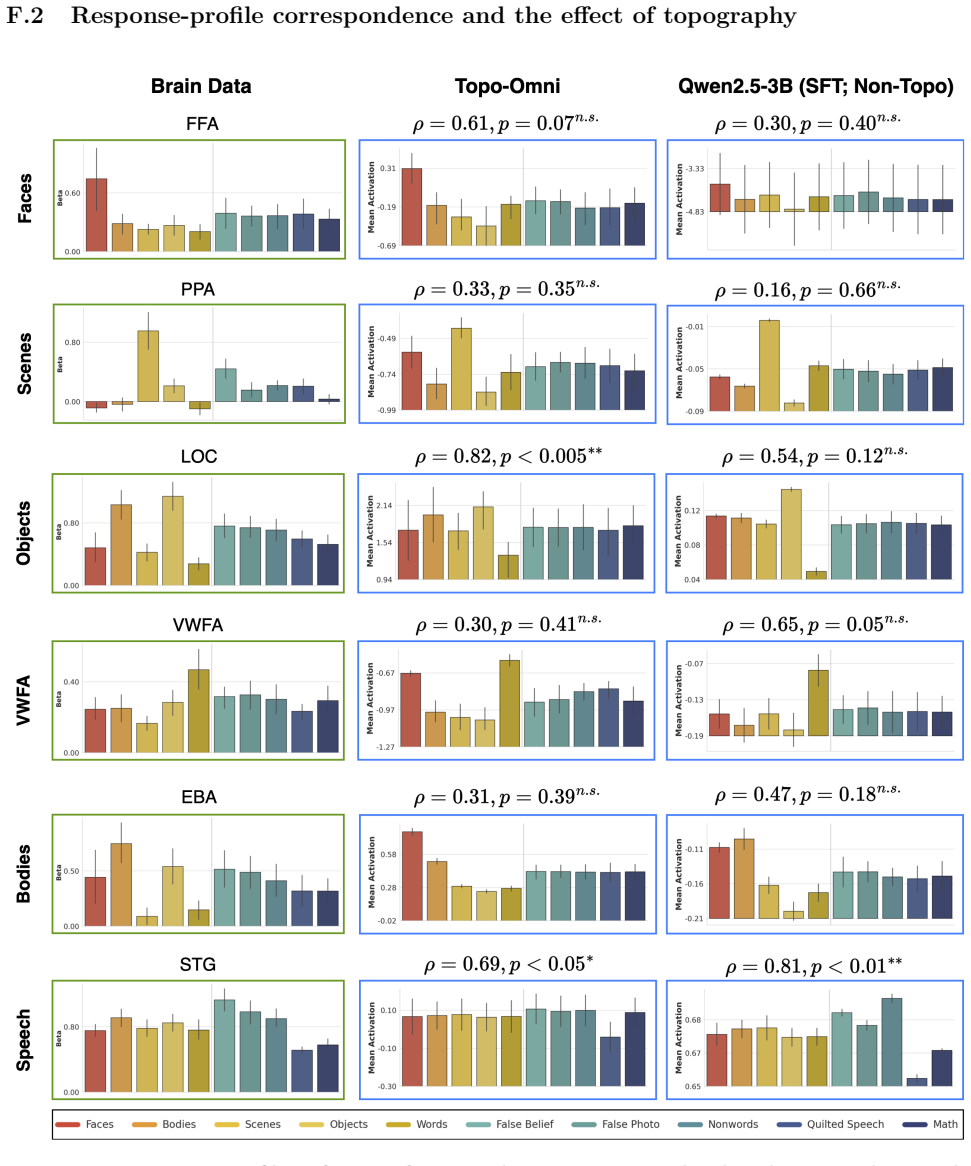
We computed the following nine EMFL contrasts, matching the contrasts reported in Table 3 in Marvi et al
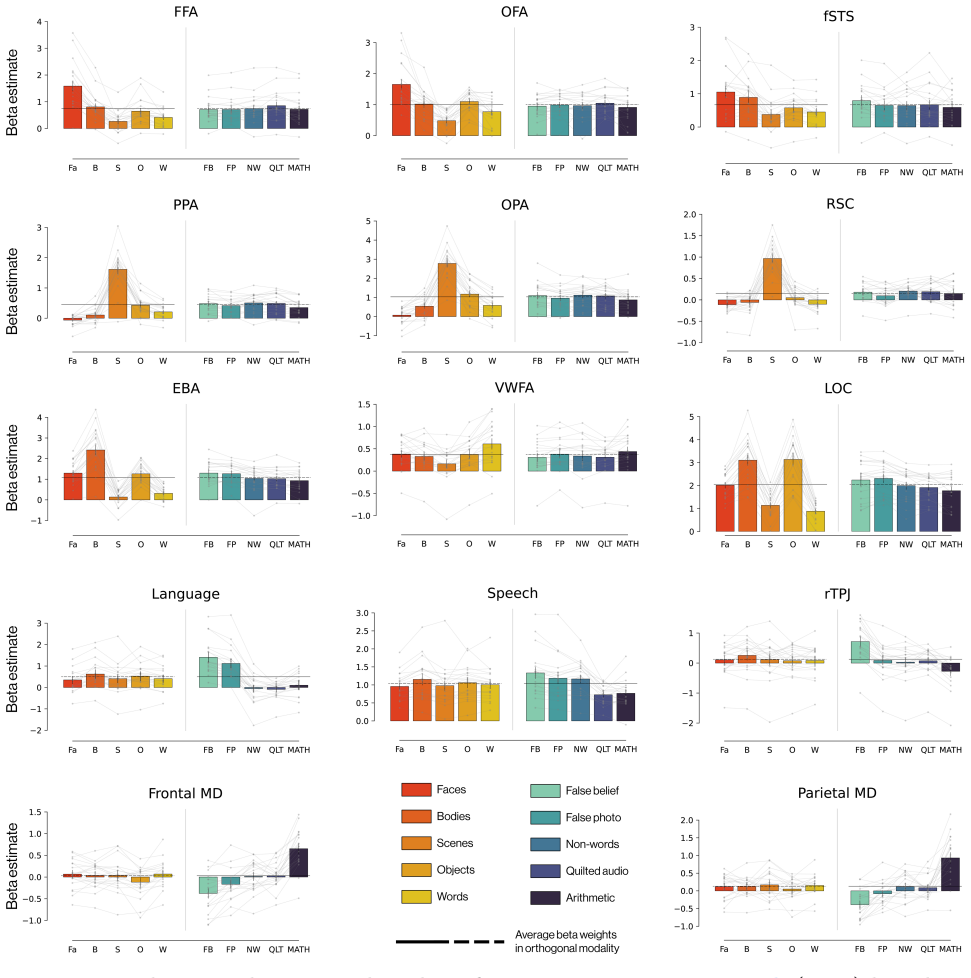
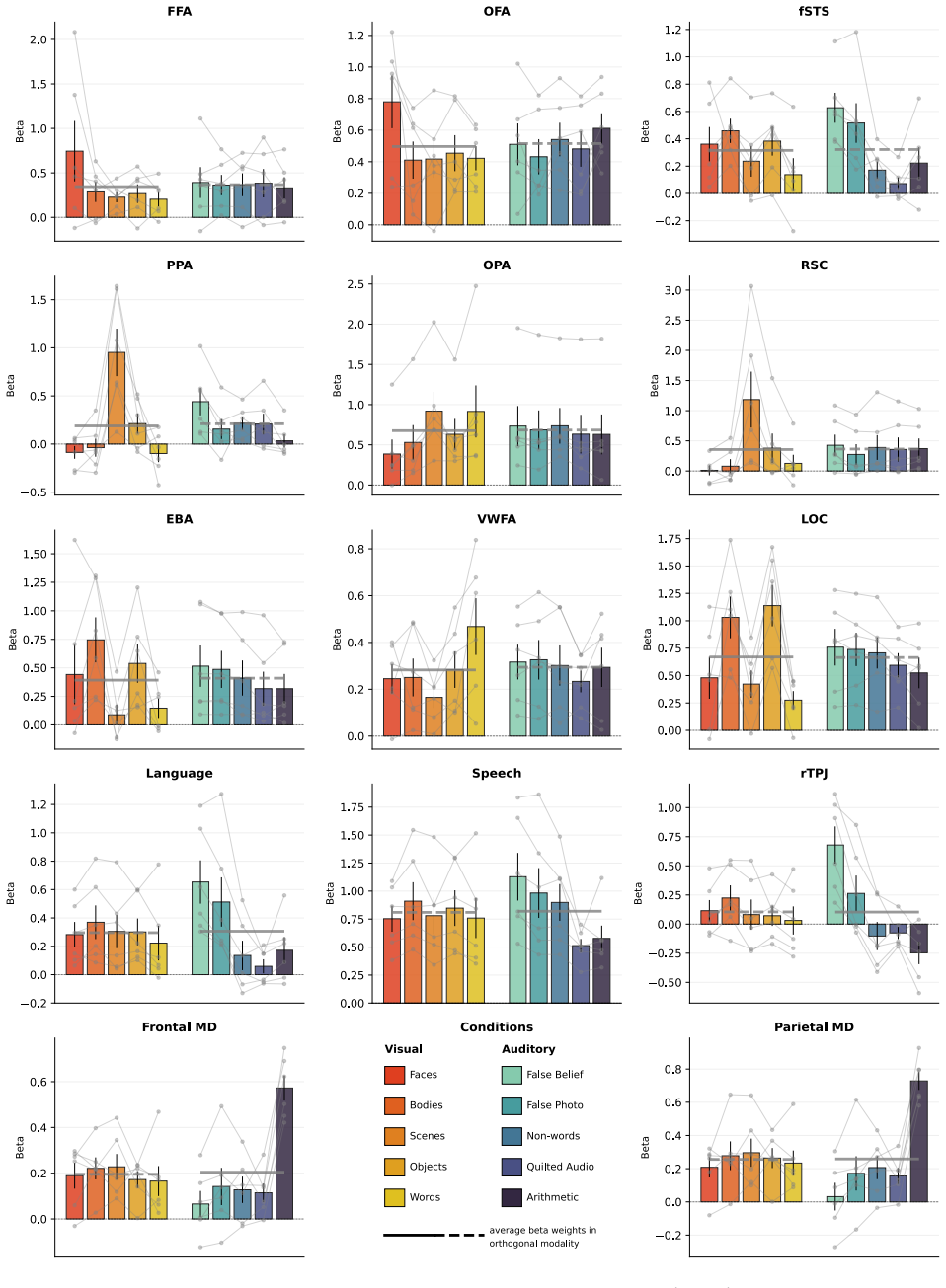
and odd runs (runs 1, 3, and 5). We computed the following nine EMFL contrasts, matching the contrasts reported in Table 3 in Marvi et al. (2025): Contrast Formula Target ROI Faces>Objects faces−objects FFA, OFA, fSTS Scenes>Objects scenes−objects PPA, OPA, RSC Bodies>Objects bodies−objects EBA Words>Objects words_scr_objects−objects VWFA Objects>Words ob...
2025
-
[11]
and extracted condition responses using even runs (2, 4). 28 For each of the 10 conditions, we extracted mean beta estimates by averaging within the fROI mask across voxels and across held-out runs, then averaged across both cross-validation splits (A and B), and finally averaged across subjects. We display results as group mean±SEM with individual subjec...
2025
-
[12]
(2025) based on 6 publicly available subjects.For the original results based on 20 subjects, please see Fig
30 Figure 9:Localizer results: re-analysis of data from Marvi et al. (2025) based on 6 publicly available subjects.For the original results based on 20 subjects, please see Fig. 8 31 B fMRI data processing: Human Voice-Selective Areas fMRI Dataset and Participants.We analyzed publicly available fMRI data from all 218 partici- pants who completed the exper...
2025
-
[13]
(2015), which was originally implemented in SPM12b
following the volumetric analysis pipeline described in Pernet et al. (2015), which was originally implemented in SPM12b. For each participant, we applied the following steps in sequence: (1) slice timing correction, (2) motion correction using a 6-degree-of-freedom (DOF) rigid-body model, (3) coregistration of the T1-weighted anatomical image to the mean...
2015
-
[14]
All group-level maps are in MNI152 2 mm isotropic space (99×117×95 voxels)
We applied family-wise error (FWE) correction via Gaussian random field theory at p < 0.05, corresponding to a t-threshold of 1.96, with a minimum cluster extent of 10 voxels. All group-level maps are in MNI152 2 mm isotropic space (99×117×95 voxels). Surface Visualization.For display purposes, we projected the group-level t-statistic map from MNI152 volu...
2015
-
[15]
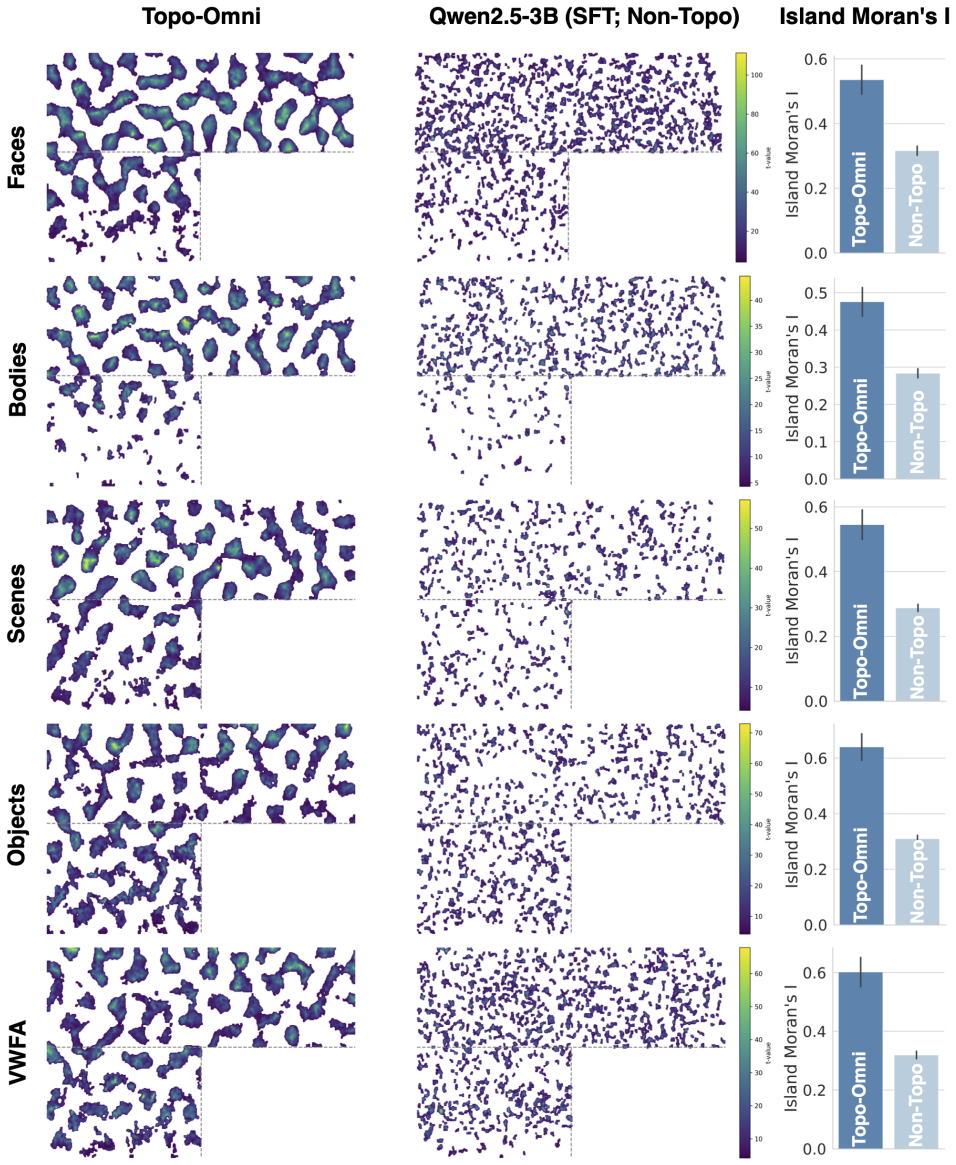
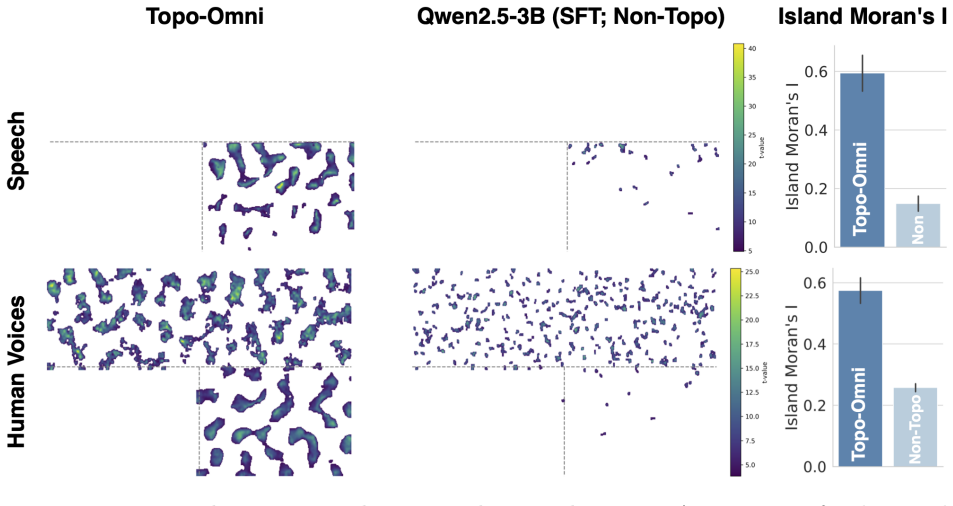
We identified contiguous clusters of FDR-significant vertices (q <0.05, minimum island size: 32 8 vertices) and computed Moran’s I within each cluster
Clustering analysis.To quantify the clustering of the vocal-selective activation pattern, we computed island Moran’s I on the group-level vocal> non-vocal t-map projected to the fsaverage6 surface. We identified contiguous clusters of FDR-significant vertices (q <0.05, minimum island size: 32 8 vertices) and computed Moran’s I within each cluster. The mea...
2015
-
[16]
atq <0.05. Only units passing this criterion were retained, and their preferred- frequency estimates were plotted on the model’s two-dimensional sheet to test whether spectral preferences vary smoothly across model space. We find that the audio encoder ofTopo-Omnidevelops spatially organized frequency preferences, with neighboring units tending to share s...
2026
-
[17]
We performed one-sided group-level t-statistics at each fsaverage6 vertex and converted them to p-values
atq <0.05. We performed one-sided group-level t-statistics at each fsaverage6 vertex and converted them to p-values. The correction was applied jointly across both hemispheres (81,924 vertices) within each contrast independently. For visualization, maps are further restricted to the top 10% of significant vertices by t-statistic after the correction of mu...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.