Hierarchical Reinforcement Learning for Sparse-Reward Search in Commutative Algebra
Pith reviewed 2026-06-26 09:13 UTC · model grok-4.3
The pith
Hierarchical reinforcement learning on graphs learns temporal abstractions to build counterexamples to Kalai's algebraic Hirsch conjecture.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
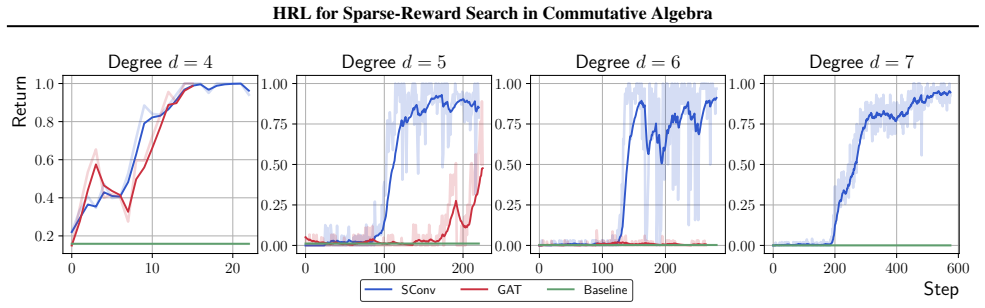
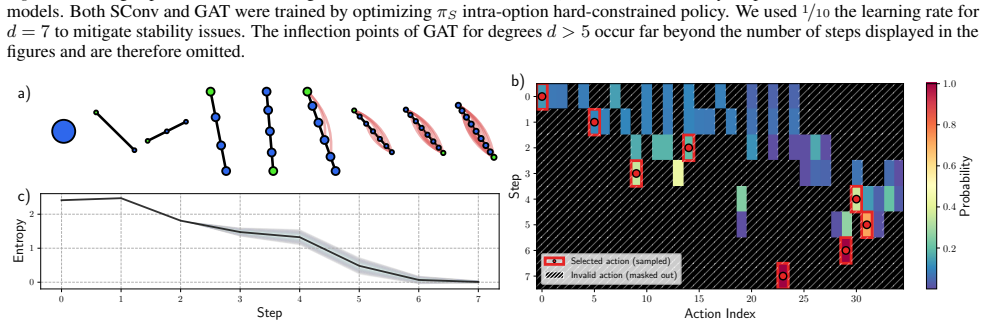
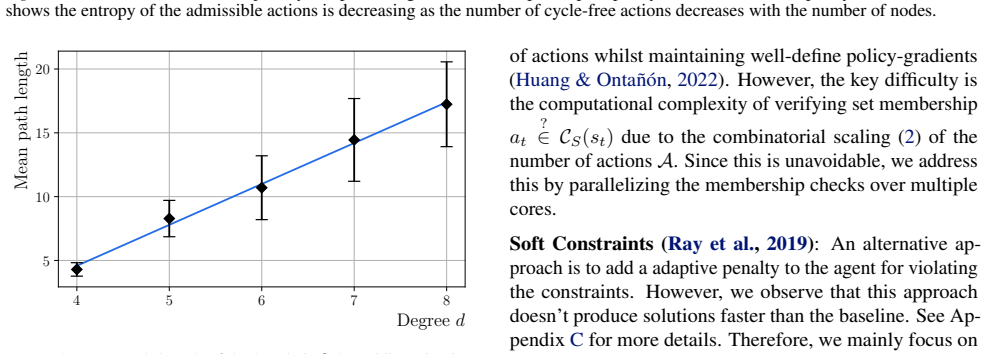
By modeling counterexample construction for Kalai's algebraic Hirsch conjecture as a Markov decision process on graphs, a constrained options-based hierarchical reinforcement learning framework equipped with an equivariant graph neural network policy learns useful temporal abstractions, consistently outperforming classical RL algorithms as well as greedy search over a wide range of degrees and supplying the first application of HRL to a commutative algebra problem.
What carries the argument
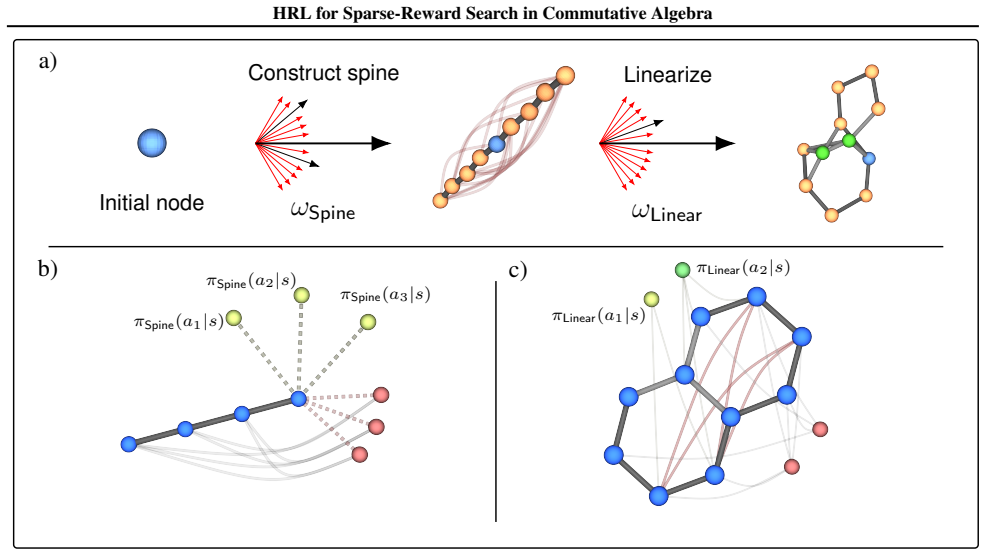
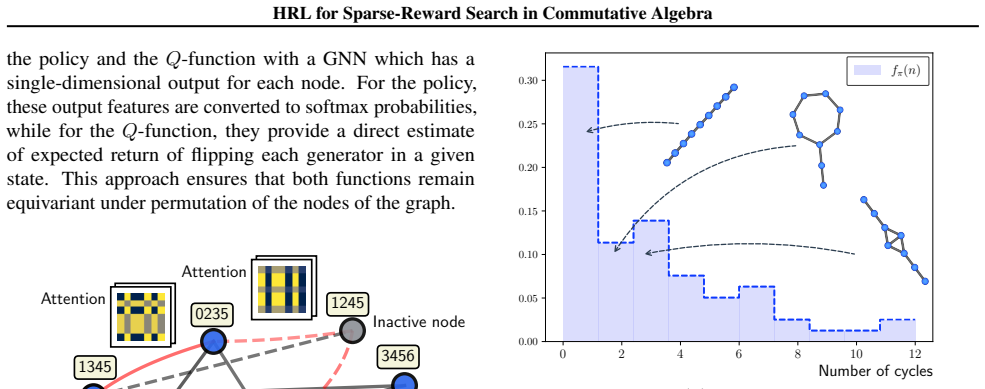
Constrained options-based hierarchical reinforcement learning framework with an equivariant graph neural network policy, which learns temporal abstractions inside a graph MDP for algebraic search.
If this is right
- The approach scales across a wide range of degrees in the algebraic task.
- It yields consistent gains over classical RL algorithms and greedy search.
- It exploits the hierarchical structure of the problem to address extreme reward sparsity.
- The framework supplies the first demonstrated use of HRL inside commutative algebra.
Where Pith is reading between the lines
- The same graph-MDP framing could be tried on other algebraic conjectures that involve combinatorial search.
- Equivariant policies may prove useful whenever the underlying algebraic objects carry natural symmetries.
- Hierarchical abstraction learning might transfer to other mathematical domains that also suffer from sparse terminal rewards.
Load-bearing premise
The algebraic task of constructing counterexamples can be modeled as a graph MDP whose reward structure admits valid temporal abstractions through constrained options without producing algebraically invalid solutions.
What would settle it
Experiments at higher degrees that produce algebraically invalid solutions or fail to beat the classical RL and greedy baselines would show the framework does not deliver the claimed advantage.
Figures
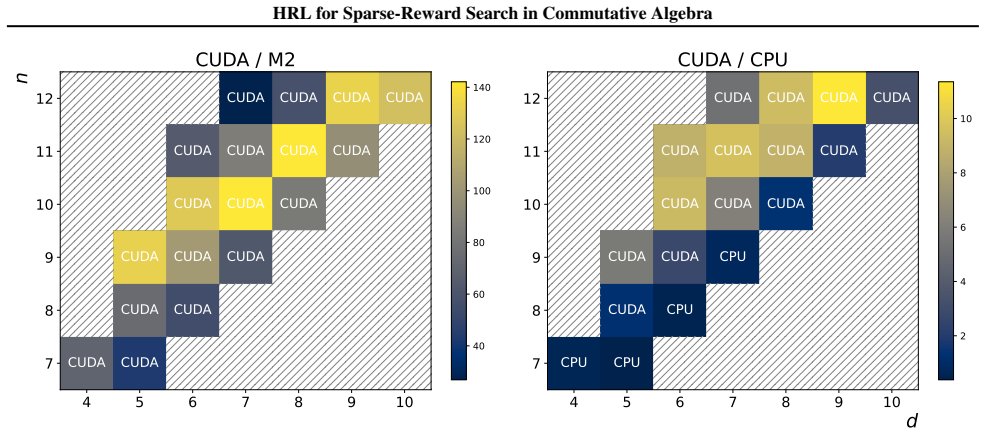
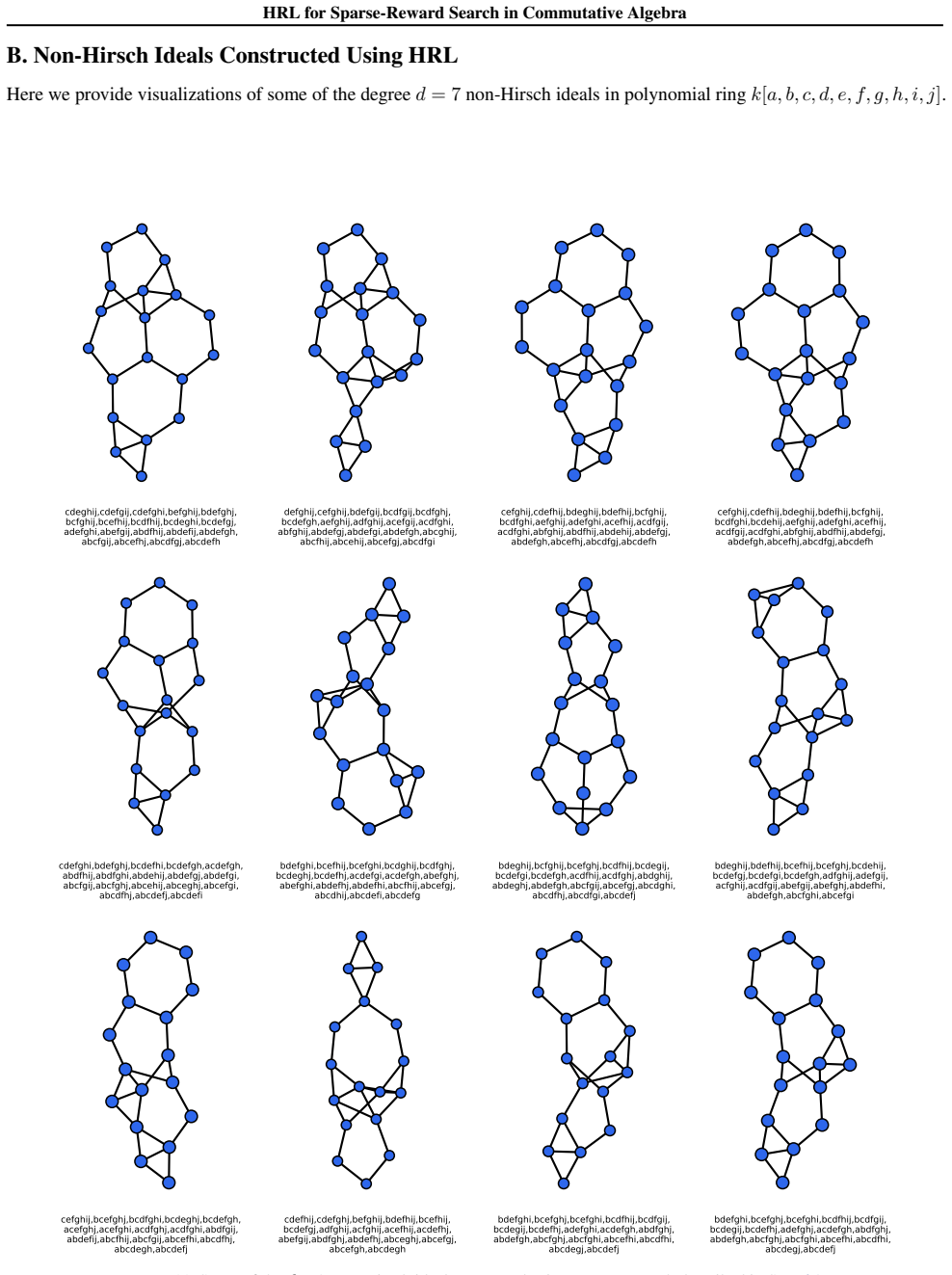
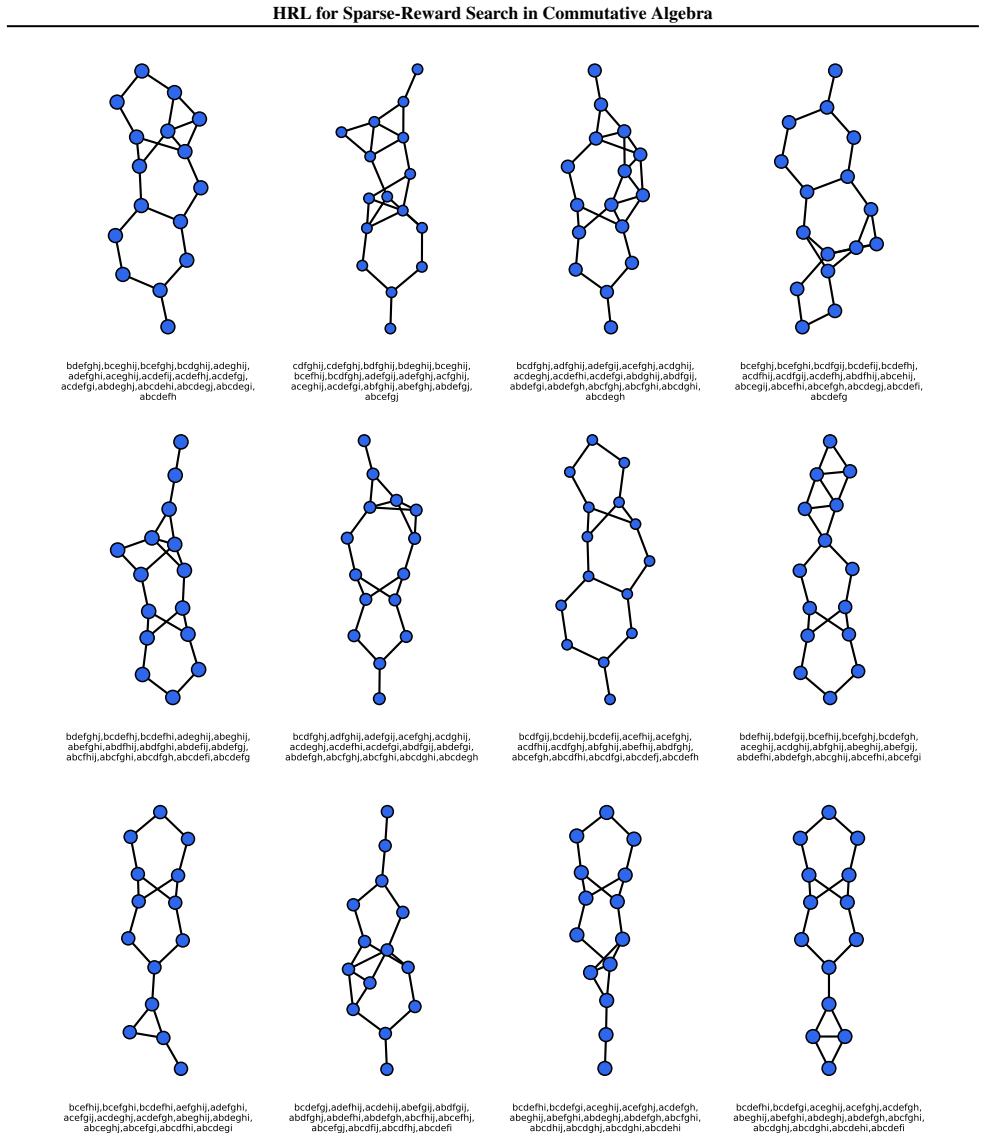
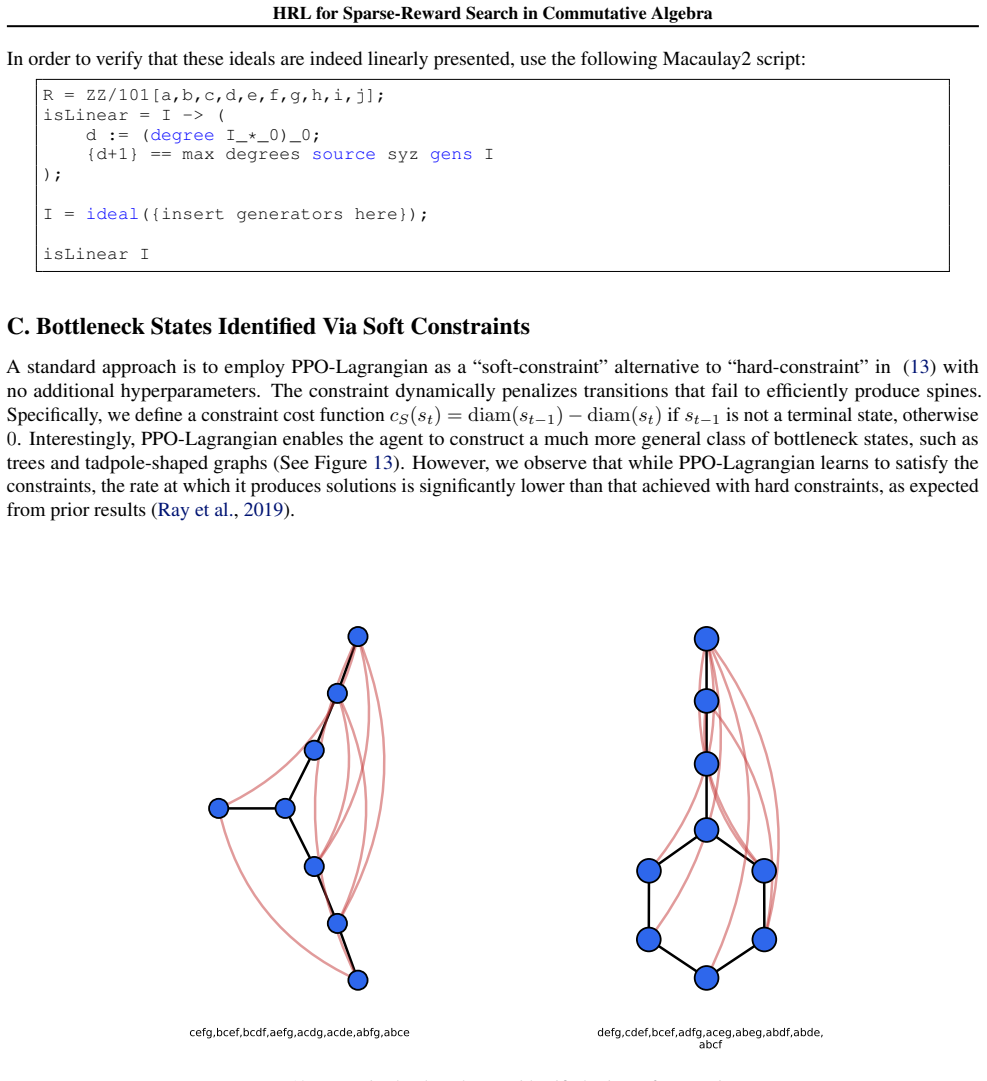
read the original abstract
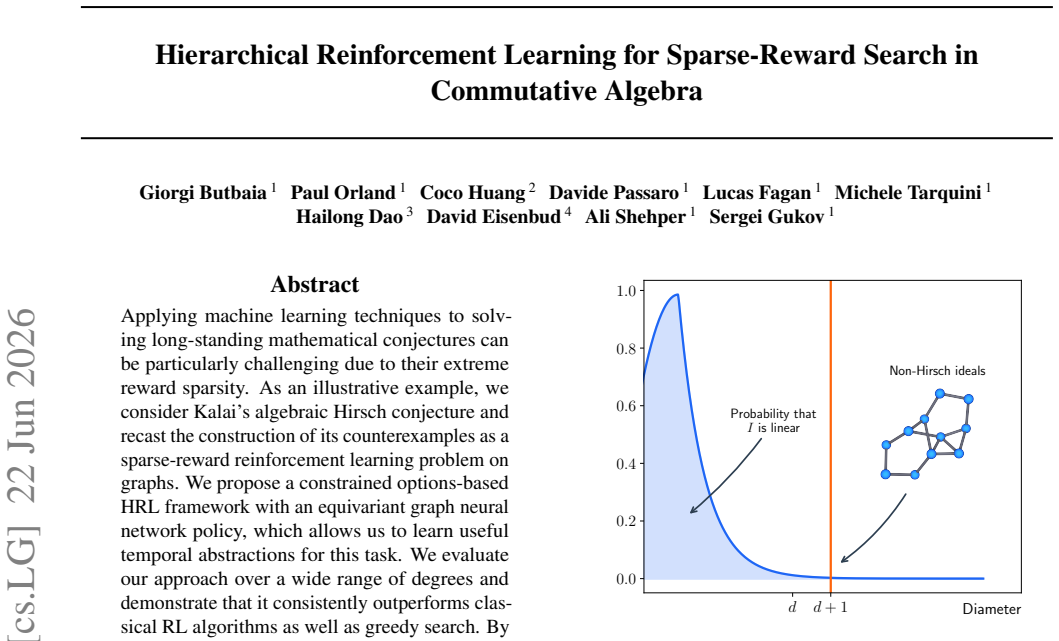
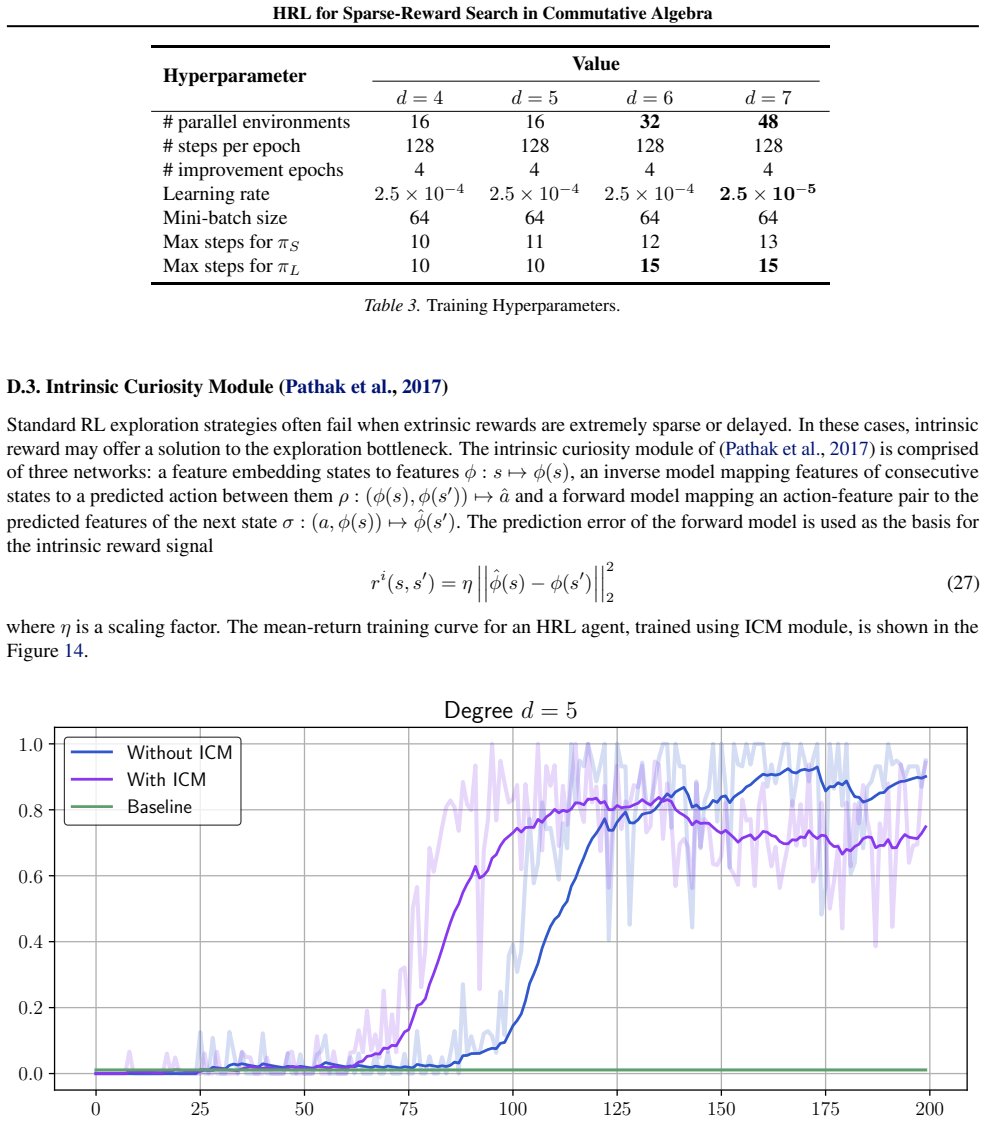
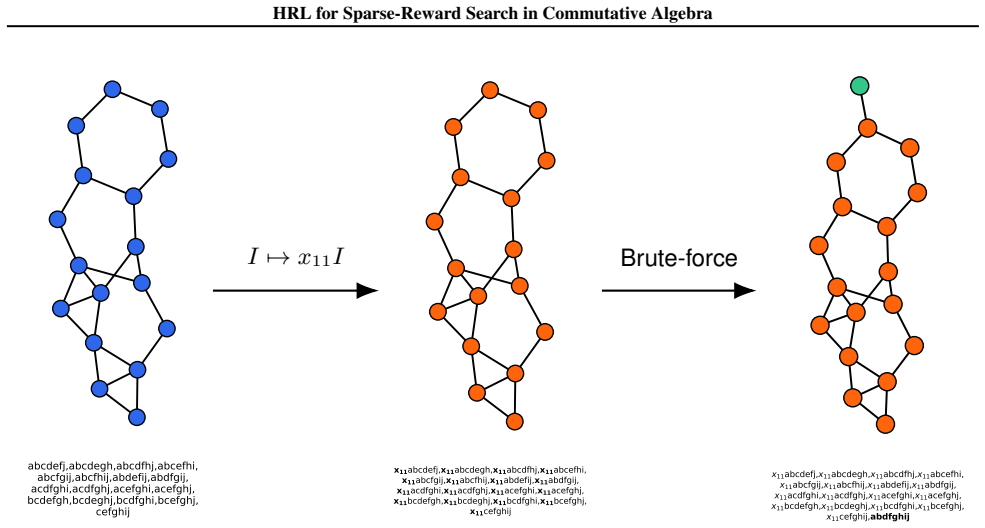
Applying machine learning techniques to solving long-standing mathematical conjectures can be particularly challenging due to their extreme reward sparsity. As an illustrative example, we consider Kalai's algebraic Hirsch conjecture and recast the construction of its counterexamples as a sparse-reward reinforcement learning problem on graphs. We propose a constrained options-based HRL framework with an equivariant graph neural network policy, which allows us to learn useful temporal abstractions for this task. We evaluate our approach over a wide range of degrees and demonstrate that it consistently outperforms classical RL algorithms as well as greedy search. By exploiting the hierarchical structure of the problem, we effectively provide a first-of-its-kind application of HRL to a problem in commutative algebra.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper recasts the search for counterexamples to Kalai's algebraic Hirsch conjecture as a sparse-reward MDP on graphs. It introduces a constrained options-based hierarchical RL framework with an equivariant GNN policy to learn temporal abstractions and reports that this method outperforms standard RL algorithms and greedy search across a range of degrees, constituting the first application of HRL to a commutative-algebra problem.
Significance. If the graph MDP and option constraints are shown to preserve algebraic validity, the result would demonstrate that hierarchical methods can address extreme reward sparsity in mathematical search tasks and provide a concrete example of RL-driven discovery in algebra.
major comments (2)
- [MDP formulation and reward definition] The central claim requires that trajectories in the graph MDP correspond to algebraically valid counterexamples (monomial ideal membership, degree bounds, Hirsch-conjecture criteria). The manuscript must supply an explicit mapping or verification (e.g., in the section defining states, actions, and rewards) showing that no invalid solutions are admitted by the option constraints or reward function; without it the performance comparison does not address the original conjecture.
- [Experimental evaluation] The evaluation claims consistent outperformance “over a wide range of degrees,” yet the abstract supplies no implementation details, baseline code, statistical tests, or ablation results. A load-bearing empirical claim requires these elements to be reported and reproducible.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback. We address each major comment below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [MDP formulation and reward definition] The central claim requires that trajectories in the graph MDP correspond to algebraically valid counterexamples (monomial ideal membership, degree bounds, Hirsch-conjecture criteria). The manuscript must supply an explicit mapping or verification (e.g., in the section defining states, actions, and rewards) showing that no invalid solutions are admitted by the option constraints or reward function; without it the performance comparison does not address the original conjecture.
Authors: We agree that an explicit verification is necessary to substantiate the central claim. Section 3 of the manuscript defines states as graphs encoding monomial ideals, actions as monomial additions respecting degree bounds, and rewards tied to Hirsch-conjecture violation criteria, with option constraints restricting to valid commutative-algebra operations. However, we acknowledge that a dedicated mapping paragraph is absent. We will revise Section 3 to include an explicit subsection providing the mapping from MDP components to algebraic conditions, together with an argument that the constraints prevent invalid trajectories. revision: yes
-
Referee: [Experimental evaluation] The evaluation claims consistent outperformance “over a wide range of degrees,” yet the abstract supplies no implementation details, baseline code, statistical tests, or ablation results. A load-bearing empirical claim requires these elements to be reported and reproducible.
Authors: Abstracts are intentionally concise and omit implementation details by design. The full manuscript reports the evaluation in Sections 4–5, including comparisons against classical RL algorithms and greedy search across degrees, with performance metrics. To improve reproducibility we will add a public code repository link, expanded hyperparameter tables, statistical significance tests, and further ablation results on the hierarchical and equivariant components in the revised version. revision: yes
Circularity Check
No circularity: empirical performance comparison on modeled search task
full rationale
The paper recasts counterexample search for Kalai's conjecture as a graph MDP and reports that a constrained-options HRL agent with equivariant GNN policy outperforms classical RL and greedy baselines across degrees. This is an empirical claim whose validity rests on experimental runs, not on any derivation that reduces outputs to inputs by construction. The MDP formulation, reward sparsity handling, and option constraints are presented as modeling decisions whose algebraic fidelity is an assumption tested indirectly by relative performance; they are not fitted parameters renamed as predictions, nor is any uniqueness theorem imported via self-citation. No load-bearing step matches the enumerated circularity patterns. The central result remains falsifiable by independent replication of the RL experiments on the same graph representation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Hindsight experience replay , author=. Advances in neural information processing systems , volume=
-
[2]
The International FLAIRS Conference Proceedings , volume=
A Closer Look at Invalid Action Masking in Policy Gradient Algorithms , author=. The International FLAIRS Conference Proceedings , volume=
-
[3]
Recipe for a general, powerful, scalable graph transformer , year =
Ramp\'. Recipe for a general, powerful, scalable graph transformer , year =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =
-
[4]
6th International Conference on Learning Representations , keywords =
Veličković, Petar and Cucurull, Guillem and Casanova, Arantxa and Romero, Adriana and Liò, Pietro and Bengio, Yoshua , biburl =. 6th International Conference on Learning Representations , keywords =
-
[5]
Sutton, R. S. and Precup, D. and Singh, S. , title =. 1998 , publisher =
1998
-
[6]
Alec Solway and Carlos Diuk and Natalia C \'o rdova and Debbie Yee and Barto, \ Andrew G.\ and Yael Niv and Botvinick, \ Matthew M.\. Optimal Behavioral Hierarchy. PLoS computational biology. 2014. doi:10.1371/journal.pcbi.1003779
-
[7]
International Conference on Learning Representations , year=
Eigenoption Discovery through the Deep Successor Representation , author=. International Conference on Learning Representations , year=
-
[8]
Proceedings of the AAAI conference on artificial intelligence , volume=
The option-critic architecture , author=. Proceedings of the AAAI conference on artificial intelligence , volume=. 2017 , doi=
2017
-
[9]
Learnings Options End-to-End for Continuous Action Tasks
Learnings Options End-to-End for Continuous Action Tasks. arXiv e-prints , keywords =. doi:10.48550/arXiv.1712.00004 , archivePrefix =. 1712.00004 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1712.00004
-
[10]
and Harada, Daishi and Russell, Stuart J
Ng, Andrew Y. and Harada, Daishi and Russell, Stuart J. , title =. Proceedings of the Sixteenth International Conference on Machine Learning , pages =. 1999 , isbn =
1999
-
[11]
, address =
Eisenbud, David. , address =. Commutative algebra with a view toward algebraic geometry / David Eisenbud. , year =. Commutative algebra with a view toward algebraic geometry , isbn =
-
[12]
Rüdiger Gebauer and H. Michael Möller , abstract =. On an installation of Buchberger's algorithm , journal =. 1988 , issn =. doi:https://doi.org/10.1016/S0747-7171(88)80048-8 , url =
-
[13]
Research in the Mathematical Sciences , volume=
Linearity of free resolutions of monomial ideals , author=. Research in the Mathematical Sciences , volume=. 2022 , publisher=
2022
-
[14]
and Stillman, Michael E
Grayson, Daniel R. and Stillman, Michael E. , title =
-
[15]
International conference on machine learning , pages=
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[16]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[17]
Advances in Neural Information Processing Systems , volume=
Heuristic-guided reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
Advances in neural information processing systems , volume=
Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation , author=. Advances in neural information processing systems , volume=. 2016 , publisher=
2016
-
[19]
A counterexample to the Hirsch conjecture
Santos, Francisco. A counterexample to the Hirsch conjecture. Ann. Math
-
[20]
arXiv preprint arXiv:2502.05199 , year=
Advancing geometry with AI: Multi-agent generation of polytopes , author=. arXiv preprint arXiv:2502.05199 , year=
-
[21]
URL https://cdn
Benchmarking safe exploration in deep reinforcement learning.(2019) , author=. URL https://cdn. openai. com/safexp-short. pdf , volume=
2019
-
[22]
International conference on machine learning , pages=
Curiosity-driven exploration by self-supervised prediction , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[23]
Dantzig , title =
George B. Dantzig , title =
-
[24]
Ralf Fr. On. Topics in Algebra, Part 2 (Warsaw, 1988), Banach Center Publications , volume =. 1990 , publisher =
1988
-
[25]
Eagon and Victor Reiner , title =
John A. Eagon and Victor Reiner , title =. Journal of Pure and Applied Algebra , volume =. 1998 , doi =
1998
-
[26]
Journal of Combinatorial Theory, Series A , volume =
Ali Soleyman Jahan and Xinxian Zheng , title =. Journal of Combinatorial Theory, Series A , volume =. 2010 , doi =
2010
-
[27]
2009 , title =
Gil Kalai , howpublished =. 2009 , title =
2009
-
[28]
Monomial ideals with 3-linear resolutions , journal =
Marcel Morales and Abbas Nasrollah Nejad and Ali Akbar. Monomial ideals with 3-linear resolutions , journal =. 2014 , doi =
2014
-
[29]
Nature , volume=
First return, then explore , author=. Nature , volume=. 2021 , publisher=
2021
-
[30]
2019 , eprint =
Why Does Hierarchy (Sometimes) Work So Well in Reinforcement Learning? , author =. 2019 , eprint =
2019
-
[31]
Proceedings of the 34th International Conference on Machine Learning , series =
Vezhnevets, Alexander Sasha and Osindero, Simon and Schaul, Tom and Heess, Nicolas and Jaderberg, Max and Silver, David and Kavukcuoglu, Koray , title =. Proceedings of the 34th International Conference on Machine Learning , series =. 2017 , publisher =
2017
-
[32]
Advances in Neural Information Processing Systems , volume =
Nachum, Ofir and Gu, Shixiang Shane and Lee, Honglak and Levine, Sergey , title =. Advances in Neural Information Processing Systems , volume =
-
[33]
International Conference on Learning Representations , year =
Levy, Andrew and Konidaris, George and Platt, Robert and Saenko, Kate , title =. International Conference on Learning Representations , year =
-
[34]
Fawzi, Alhussein and Balog, Matej and Huang, Aja and Hubert, Thomas and Romera-Paredes, Bernardino and Barekatain, Mohammadamin and Novikov, Alexander and Ruiz, Francisco J. R. and Schrittwieser, Julian and Swirszcz, Grzegorz and Silver, David and Hassabis, Demis and Kohli, Pushmeet , title =. Nature , volume =. 2022 , doi =
2022
-
[35]
International conference on machine learning , pages=
Constrained policy optimization , author=. International conference on machine learning , pages=. 2017 , organization=
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.