Laplace--Fisher Gate Identities for Optimal Matrix-Gated Blended Score Estimation
Pith reviewed 2026-06-25 21:44 UTC · model grok-4.3
The pith
The Laplace-Fisher Gate Identity supplies the variance-optimal matrix gate for blending Tweedie and target-score estimators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Blended score estimation is cast as conditional risk minimization over matrix-valued blending coefficients, or gates, and the variance-optimal gate is derived as G*(y,t) = α_t² (α_t² I_d + γ_t E[H_0(X_0) | Y_t = y])^{-1}, where H_0 = -∇² log p_0, α_t = e^{-t} and γ_t = 1 - e^{-2t}. The formula is called the Laplace-Fisher Gate Identity. Because the Tweedie-TSI disagreement has conditional mean zero, the gate changes estimator variance without changing its expected value. Finite-reference consistency and stability bounds are proved for estimating the gate from weighted reference samples, and the estimator is applied to normalized posterior-density evaluation in Bayesian inverse problems.
What carries the argument
The Laplace-Fisher Gate Identity, which gives the optimal matrix gate as the scaled inverse of a matrix that regularizes the conditional expectation of the target Hessian.
If this is right
- The optimal gate can be estimated consistently from finite weighted reference samples with proved stability bounds.
- When MCMC pilot samples and derivative information are available, the gate produces a normalized posterior-density surrogate.
- The surrogate supports posterior-energy evaluation, model-evidence estimation, and density-based diagnostics beyond sample-based methods.
- On a PDE-constrained inverse-problem benchmark the method improves posterior-density calibration and sampling diagnostics relative to other tested score-estimator classes.
Where Pith is reading between the lines
- The matrix-valued gate naturally accommodates strongly anisotropic or singular targets that defeat scalar blending coefficients.
- Because the gate is estimated from the same reference samples already used for score estimation, the overhead remains modest when derivative information is already computed.
- The separation between variance reduction and expectation preservation may extend to blending other pairs of unbiased estimators whose difference has conditional mean zero.
Load-bearing premise
The disagreement between the Tweedie and target-score identities has conditional mean zero given the noisy observation.
What would settle it
A Monte Carlo check that computes the conditional expectation of the Tweedie-TSI difference given Y_t = y on a large sample and finds it statistically different from zero would falsify preservation of the estimator's expectation.
Figures
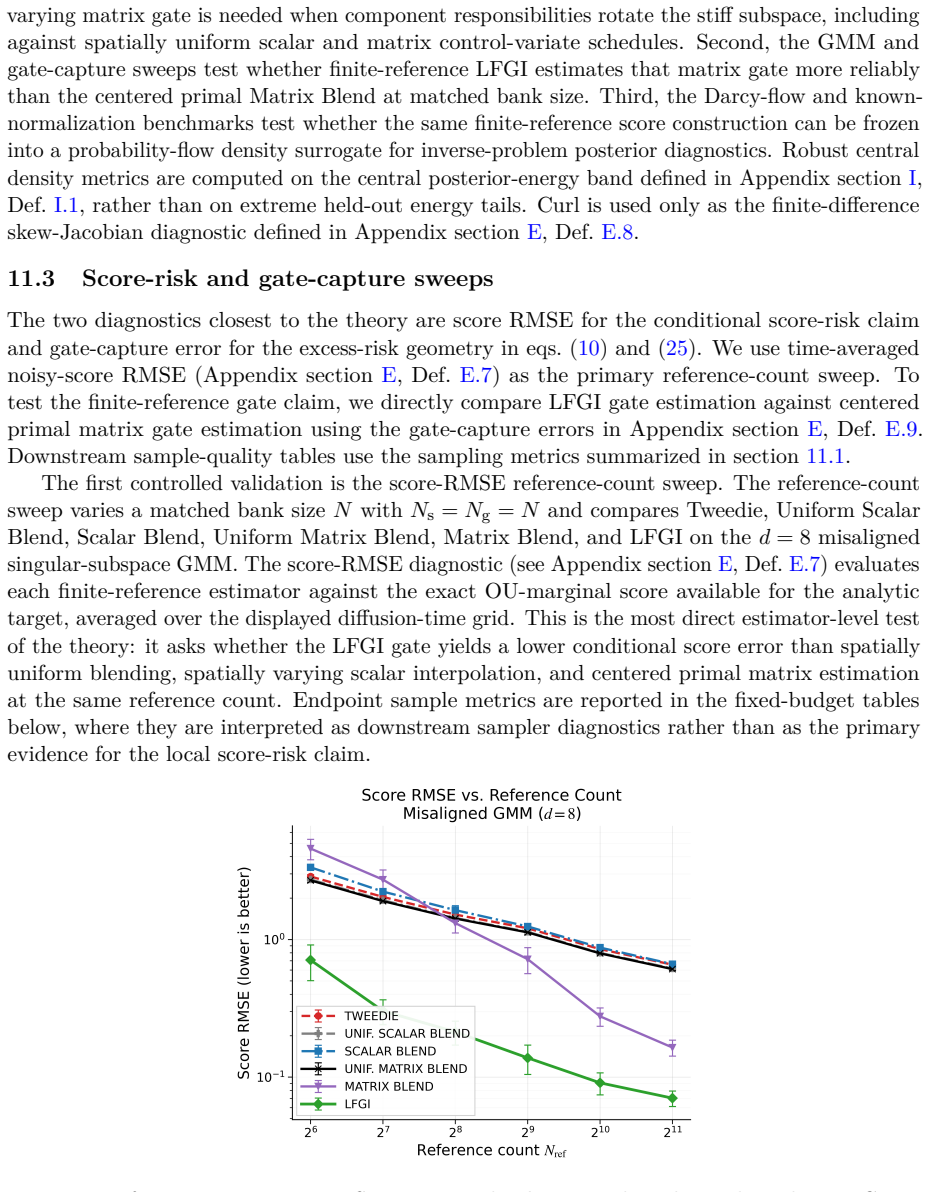



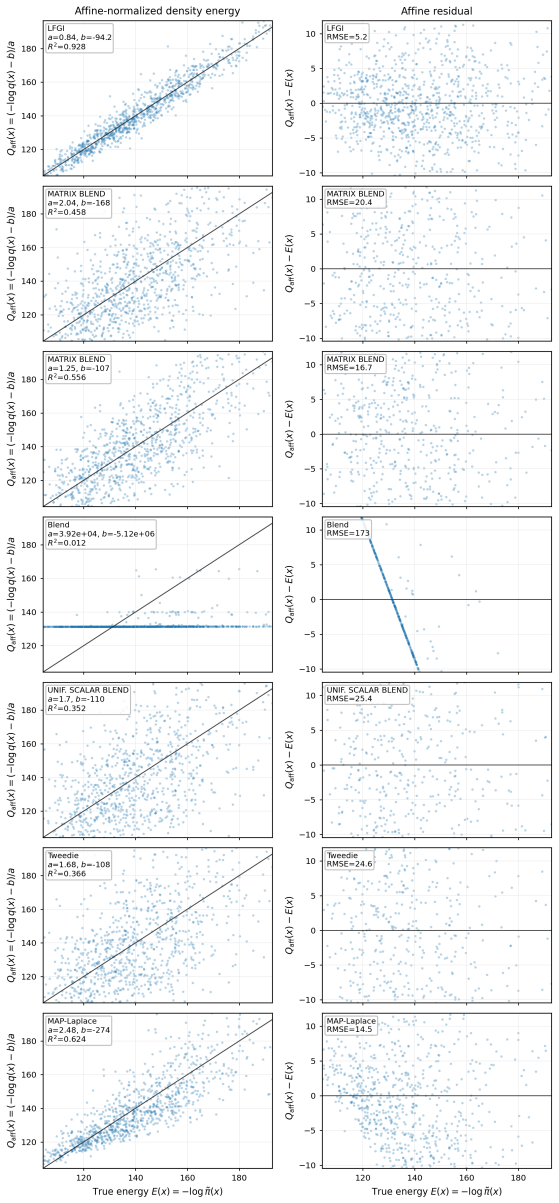
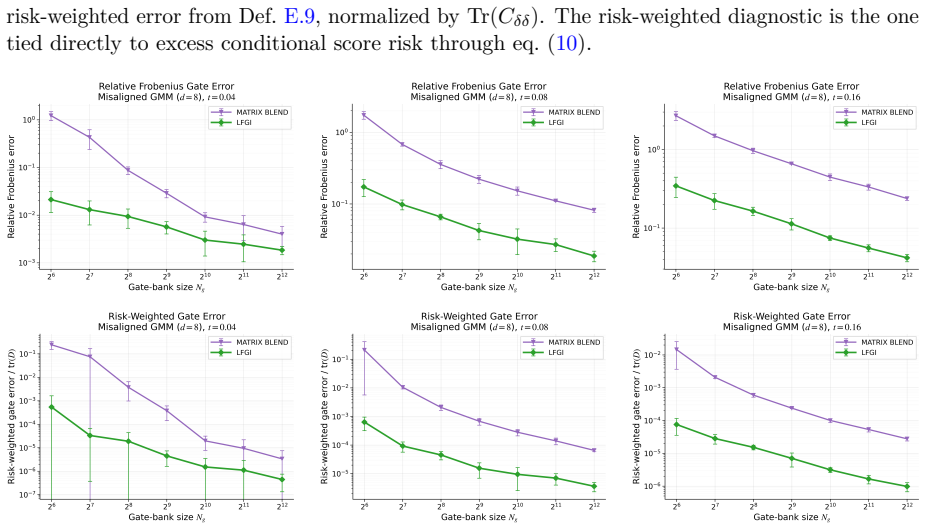
read the original abstract
Sampling from an unnormalized target by reversing an Ornstein--Uhlenbeck diffusion requires the score of each noise-perturbed marginal. Tweedie's identity and a target-score identity give unbiased finite-reference estimators for this score. Scalar blends can reduce variance, but are too rigid for singular or strongly anisotropic targets. We cast blended score estimation as conditional risk minimization over matrix-valued blending coefficients, or gates, and derive the variance-optimal gate [ \Gstar(y,t)=\alphat^2\bigl(\alphat^2 I_d+\gammat,\E[H_0(X_0)\mid Y_t=y]\bigr)^{-1},\qquad H_0=-\nabla^2\log p_0 . ] Here (\alphat=e^{-t}) and (\gammat=1-e^{-2t}). We call this formula the \emph{Laplace--Fisher Gate Identity} (\LFGI{}). Since the Tweedie--TSI disagreement has conditional mean zero, the gate changes estimator variance without changing its expected value. We give the Gaussian special case and prove finite-reference consistency and stability bounds for estimating the gate from weighted reference samples. We apply the finite-reference LFGI estimator to normalized density evaluation for Bayesian inverse problems. When MCMC pilot samples and derivative information are available, LFGI uses these byproducts to construct a normalized posterior-density surrogate. The surrogate enables posterior-energy evaluation, model-evidence estimation, and density-based diagnostics beyond those available from samples alone. On a PDE-constrained inverse-problem benchmark, LFGI improves posterior-density calibration and sampling diagnostics relative to the other tested score-estimator classes, and known-evidence experiments check absolute calibration in Gaussian and non-Gaussian settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper casts blended score estimation for Ornstein-Uhlenbeck diffusion reversal as conditional risk minimization over matrix-valued gates and derives the variance-optimal Laplace-Fisher Gate Identity G*(y,t)=α_t²(α_t² I_d + γ_t E[H_0(X_0)|Y_t=y])^{-1} with α_t=e^{-t}, γ_t=1-e^{-2t}. It asserts that the Tweedie-TSI disagreement has conditional mean zero (so the gate is unbiased), proves finite-reference consistency and stability bounds when the gate is estimated from weighted reference samples, gives the Gaussian case, and applies the resulting estimator to construct normalized posterior-density surrogates for Bayesian inverse problems, reporting improved calibration and diagnostics on a PDE-constrained benchmark.
Significance. If the central claims hold, the matrix gate supplies a principled, variance-optimal blending rule that is more flexible than scalar blends for singular or anisotropic targets while preserving unbiasedness; the finite-reference consistency result and the use of MCMC byproducts for normalized density evaluation would be useful additions to the score-estimation and Bayesian-computation literature.
major comments (2)
- [Abstract (LFGI formula and following sentence)] Abstract (statement immediately following the LFGI formula): the claim that the Tweedie-TSI disagreement has conditional mean zero is invoked to guarantee that the gate changes only variance and not expectation, yet no derivation, reference, or explicit verification is supplied; this premise is load-bearing for the unbiasedness of the finite-reference estimator and must be established before the consistency bounds can be accepted.
- [Abstract (finite-reference consistency and stability bounds)] Abstract (finite-reference consistency claim): the gate formula depends on the conditional expectation E[H_0(X_0)|Y_t=y], which itself must be estimated from the same reference samples used to form the blended score; the dependence structure and any resulting bias in the plug-in estimator are not addressed in the abstract, so the stated consistency and stability bounds cannot yet be verified.
minor comments (1)
- [Abstract] Notation for α_t and γ_t is introduced only after the gate formula; moving the definitions to the first appearance of the formula would improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the identification of points that require clarification in the abstract. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract (LFGI formula and following sentence)] Abstract (statement immediately following the LFGI formula): the claim that the Tweedie-TSI disagreement has conditional mean zero is invoked to guarantee that the gate changes only variance and not expectation, yet no derivation, reference, or explicit verification is supplied; this premise is load-bearing for the unbiasedness of the finite-reference estimator and must be established before the consistency bounds can be accepted.
Authors: The conditional mean-zero property follows because both Tweedie's identity and the target-score identity are unbiased estimators of the same score function ∇log p_t(y); their difference therefore has conditional expectation zero given Y_t = y. This is shown by direct computation in Section 3.1. We will add a parenthetical reference to this section immediately after the claim in the revised abstract. revision: yes
-
Referee: [Abstract (finite-reference consistency and stability bounds)] Abstract (finite-reference consistency claim): the gate formula depends on the conditional expectation E[H_0(X_0)|Y_t=y], which itself must be estimated from the same reference samples used to form the blended score; the dependence structure and any resulting bias in the plug-in estimator are not addressed in the abstract, so the stated consistency and stability bounds cannot yet be verified.
Authors: The consistency and stability bounds (Theorem 4.1 and Corollary 4.2) are proved for the joint plug-in estimator in which both the blended score and the matrix gate (including the estimated conditional expectation E[H_0(X_0)|Y_t=y]) are formed from the same weighted reference samples. The proof uses a uniform concentration argument that accounts for the dependence. We will revise the abstract to state that the reported bounds apply to this joint estimation procedure. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper derives the matrix gate explicitly by minimizing conditional risk over blending coefficients, producing the closed-form expression involving the conditional Hessian expectation. The subsequent statement that the Tweedie-TSI disagreement has conditional mean zero is presented as an independent premise that preserves unbiasedness; it is not obtained by substituting the gate formula back into itself or by any self-referential reduction. Finite-reference consistency and stability bounds are proved separately from the gate identity. No fitted parameter is relabeled as a prediction, no self-citation chain supplies a uniqueness theorem, and no ansatz is smuggled via prior work. The central identities therefore remain independent of their own outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Tweedie identity and target-score identity supply unbiased finite-reference score estimators
- domain assumption Tweedie–TSI disagreement has conditional mean zero
Reference graph
Works this paper leans on
-
[1]
Tara Akhound-Sadegh, Jarrid Rector-Brooks, Avishek Joey Bose, Sarthak Mittal, Pablo Lemos, Cheng-Hao Liu, Marcin Sendera, Siamak Ravanbakhsh, Gauthier Gidel, Yoshua Bengio, Nikolay Malkin, and Alexander Tong. Iterated denoising energy matching for sampling from boltzmann densities.arXiv preprint arXiv:2402.06121, 2024. doi: 10.48550/ arXiv.2402.06121
arXiv 2024
-
[2]
Brian D. O. Anderson. Reverse-time diffusion equation models.Stochastic Processes and their Applications, 12(3):313–326, 1982. doi: 10.1016/0304-4149(82)90051-5
-
[3]
Kernel conditional exponential family
Michael Arbel and Arthur Gretton. Kernel conditional exponential family. InProceedings of the 21st International Conference on Artificial Intelligence and Statistics (AISTATS), volume 84 ofProceedings of Machine Learning Research, pages 1337–1346. PMLR, 2018
2018
-
[4]
Maximum mean discrepancy gradient flow
Michael Arbel, Anna Korba, Adil Salim, and Arthur Gretton. Maximum mean discrepancy gradient flow. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[5]
Error bounds for flow matching methods.Transactions on Machine Learning Research, 2024
Joe Benton, George Deligiannidis, and Arnaud Doucet. Error bounds for flow matching methods.Transactions on Machine Learning Research, 2024
2024
-
[6]
Girolami
Tan Bui-Thanh and Mark A. Girolami. Solving large-scale PDE-constrained Bayesian inverse problems with Riemann manifold Hamiltonian Monte Carlo.Inverse Problems, 30(11):114014,
-
[7]
doi: 10.1088/0266-5611/30/11/114014
-
[8]
Sequential controlled langevin diffusions
Junhua Chen, Lorenz Richter, Julius Berner, Denis Blessing, Gerhard Neumann, and Anima Anandkumar. Sequential controlled langevin diffusions. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[9]
Ricky T. Q. Chen, Yulia Rubanova, Jesse Bettencourt, and David K. Duvenaud. Neural ordinary differential equations. InAdvances in Neural Information Processing Systems, volume 31, 2018
2018
-
[10]
The probability flow ODE is provably fast
Sitan Chen, Sinho Chewi, Holden Lee, Yuanzhi Li, Jianfeng Lu, and Adil Salim. The probability flow ODE is provably fast. InAdvances in Neural Information Processing Systems, volume 36, 2023. 68
2023
-
[11]
A kernel test of goodness of fit
Krzysztof Chwialkowski, Heiko Strathmann, and Arthur Gretton. A kernel test of goodness of fit. InProceedings of the 33rd International Conference on Machine Learning (ICML), volume 48 ofProceedings of Machine Learning Research, pages 2606–2615. PMLR, 2016
2016
-
[12]
Duncan, Sebastian Reich, and "O
Paula Cordero-Encinar, Andrew B. Duncan, Sebastian Reich, and "O. Deniz Akyildiz. Sampling by averaging: A multiscale approach to score estimation. InAdvances in Neural Information Processing Systems, 2025
2025
-
[13]
Sinkhorn distances: Lightspeed computation of optimal transport
Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. InAdvances in Neural Information Processing Systems, volume 26, 2013
2013
-
[14]
Target score matching.arXiv preprint arXiv:2402.08667, 2024
Valentin De Bortoli, Michael Hutchinson, Peter Wirnsberger, and Arnaud Doucet. Target score matching.arXiv preprint arXiv:2402.08667, 2024. doi: 10.48550/arXiv.2402.08667
-
[15]
Journal of the Royal Statistical Society: Series B (Statistical Methodology) 68, 411–436
Pierre Del Moral, Arnaud Doucet, and Ajay Jasra. Sequential monte carlo samplers.Journal of the Royal Statistical Society: Series B (Statistical Methodology), 68(3):411–436, 2006. doi: 10.1111/j.1467-9868.2006.00553.x
-
[16]
Tweedie's formula and selection bias https://doi.org/10.1198/jasa.2011.tm11181
Bradley Efron. Tweedie’s formula and selection bias.Journal of the American Statistical Association, 106(496):1602–1614, 2011. doi: 10.1198/jasa.2011.tm11181
-
[17]
Andrew Gelman and Xiao-Li Meng. Simulating normalizing constants: From importance sampling to bridge sampling to path sampling.Statistical Science, 13(2):163–185, 1998. doi: 10.1214/ss/1028905934
-
[18]
Mark Girolami and Ben Calderhead. Riemann manifold langevin and hamiltonian monte carlo methods.Journal of the Royal Statistical Society: Series B (Statistical Methodology), 73(2):123–214, 2011. doi: 10.1111/j.1467-9868.2010.00765.x
-
[19]
Will Grathwohl, Ricky T. Q. Chen, Jesse Bettencourt, Ilya Sutskever, and David Duvenaud. FFJORD: Free-form continuous dynamics for scalable reversible generative models. In International Conference on Learning Representations, 2019
2019
-
[20]
Stochas- tic localization via iterative posterior sampling
Louis Grenioux, Maxence Noble, Marylou Gabrié, and Alain Oliviero Durmus. Stochas- tic localization via iterative posterior sampling. InProceedings of the 41st International Conference on Machine Learning, Proceedings of Machine Learning Research. PMLR, 2024
2024
-
[21]
A kernel two-sample test.Journal of Machine Learning Research, 13:723–773, 2012
Arthur Gretton, Karsten Borgwardt, Malte Rasch, Bernhard Schölkopf, and Alexander Smola. A kernel two-sample test.Journal of Machine Learning Research, 13:723–773, 2012
2012
-
[22]
Havens, Benjamin Kurt Miller, Bing Yan, Carles Domingo-Enrich, Anuroop Sriram, Daniel S
Aaron J. Havens, Benjamin Kurt Miller, Bing Yan, Carles Domingo-Enrich, Anuroop Sriram, Daniel S. Levine, Brandon M. Wood, Bin Hu, Brandon Amos, Brian Karrer, Xiang Fu, Guan- Horng Liu, and Ricky T. Q. Chen. Adjoint sampling: Highly scalable diffusion samplers via adjoint matching. InProceedings of the 42nd International Conference on Machine Learning, vo...
-
[23]
Training neural samplers with reverse diffusive KL divergence
Jiajun He, Wenlin Chen, Mingtian Zhang, David Barber, and José Miguel Hernández-Lobato. Training neural samplers with reverse diffusive KL divergence. InProceedings of The 28th International Conference on Artificial Intelligence and Statistics, Proceedings of Machine Learning Research. PMLR, 2025. 69
2025
-
[24]
Zeroth-order sampling methods for non-log-concave distributions: Alleviating metastability by denoising diffusion
Ye He, Kevin Rojas, and Molei Tao. Zeroth-order sampling methods for non-log-concave distributions: Alleviating metastability by denoising diffusion. InAdvances in Neural Information Processing Systems, volume 37, pages 71122–71161, 2024
2024
-
[25]
Denoising diffusion prob- abilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion prob- abilistic models. InAdvances in Neural Information Processing Systems (NeurIPS), 2020. URL https://proceedings.neurips.cc/paper/2020/file/ 4c5bcfec8584af0d967f1ab10179ca4b-Paper.pdf
2020
-
[26]
Reverse diffusion monte carlo
Xunpeng Huang, Hanze Dong, Yifan Hao, Yian Ma, and Tong Zhang. Reverse diffusion monte carlo. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=esc8PjUQ8e
2024
-
[27]
Estimation of non-normalized statistical models by score matching.Journal of Machine Learning Research, 6:695–709, 2005
Aapo Hyvärinen. Estimation of non-normalized statistical models by score matching.Journal of Machine Learning Research, 6:695–709, 2005
2005
-
[28]
On a formula for the product-moment coefficient of any order of a normal frequency distribution in any number of variables.Biometrika, 12(1/2):134–139, 1918
Leon Isserlis. On a formula for the product-moment coefficient of any order of a normal frequency distribution in any number of variables.Biometrika, 12(1/2):134–139, 1918
1918
-
[29]
Khaled Kahouli, Romuald Elie, Klaus-Robert Müller, Quentin Berthet, Oliver T. Unke, and Arnaud Doucet. Control variate score matching for diffusion models.arXiv preprint arXiv:2512.20003, 2025. doi: 10.48550/arXiv.2512.20003
-
[30]
Latent target score matching, with an application to simulation-based inference
Joohwan Ko and Tomas Geffner. Latent target score matching, with an application to simulation-based inference. InMachine Learning and the Physical Sciences Workshop, NeurIPS, 2025
2025
-
[31]
Kolmogorov
Andrey N. Kolmogorov. Sulla determinazione empirica di una legge di distribuzione.Giornale dell’Istituto Italiano degli Attuari, 4:83–91, 1933
1933
-
[32]
Liu, and Wing Hung Wong
Augustine Kong, Jun S. Liu, and Wing Hung Wong. Sequential imputations and bayesian missing data problems.Journal of the American Statistical Association, 89(425):278–288, 1994
1994
-
[33]
Kernel stein discrepancy descent
Anna Korba, Pierre-Cyril Aubin-Frankowski, Szymon Majewski, and Pierre Ablin. Kernel stein discrepancy descent. InInternational Conference on Machine Learning (ICML), volume 139 ofProceedings of Machine Learning Research. PMLR, 2021
2021
-
[34]
Liu.Monte Carlo Strategies in Scientific Computing
Jun S. Liu.Monte Carlo Strategies in Scientific Computing. Springer Series in Statistics. Springer, New York, 2001
2001
-
[35]
Stein variational gradient descent: A general purpose bayesian inference algorithm
Qiang Liu and Dilin Wang. Stein variational gradient descent: A general purpose bayesian inference algorithm. InAdvances in Neural Information Processing Systems (NeurIPS), 2016. URLhttps://arxiv.org/abs/1608.04471
arXiv 2016
-
[36]
A kernelized stein discrepancy for goodness-of-fit tests
Qiang Liu, Jason Lee, and Michael Jordan. A kernelized stein discrepancy for goodness-of-fit tests. InProceedings of the 33rd International Conference on Machine Learning (ICML), volume 48 ofProceedings of Machine Learning Research, pages 276–284. PMLR, 2016
2016
-
[37]
Maximum likelihood training for score-based diffusion ODEs by high-order denoising score matching
Cheng Lu, Kaiwen Zheng, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Maximum likelihood training for score-based diffusion ODEs by high-order denoising score matching. InProceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research, pages 14429–14460. PMLR, 2022. 70
2022
-
[38]
Wilcox, Carsten Burstedde, and Omar Ghattas
James Martin, Lucas C. Wilcox, Carsten Burstedde, and Omar Ghattas. A stochastic Newton MCMC method for large-scale statistical inverse problems with application to seismic inversion.SIAM Journal on Scientific Computing, 34(3):A1460–A1487, 2012. doi: 10.1137/110845598
-
[39]
Effective sample size for importance sampling based on discrepancy measures.Signal Processing, 131:386–401, 2017
Luca Martino, Víctor Elvira, and Francisco Louzada. Effective sample size for importance sampling based on discrepancy measures.Signal Processing, 131:386–401, 2017
2017
-
[40]
Simulating ratios of normalizing constants via a simple identity: A theoretical exploration.Statistica Sinica, 6(4):831–860, 1996
Xiao-Li Meng and Wing Hung Wong. Simulating ratios of normalizing constants via a simple identity: A theoretical exploration.Statistica Sinica, 6(4):831–860, 1996
1996
-
[41]
Radford M. Neal. Annealed importance sampling.Statistics and Computing, 11(2):125–139,
-
[42]
doi: 10.1023/A:1008923215028
-
[43]
Learned reference-based diffusion sampler for multi-modal distributions
Maxence Noble, Louis Grenioux, Marylou Gabrié, and Alain Oliviero Durmus. Learned reference-based diffusion sampler for multi-modal distributions. InThe Thirteenth Interna- tional Conference on Learning Representations, 2025
2025
-
[44]
Jorge Nocedal and Stephen J. Wright.Numerical Optimization. Springer, New York, 2 edition, 2006. doi: 10.1007/978-0-387-40065-5
-
[45]
Owen.Monte Carlo: Theory, Methods and Examples
Art B. Owen.Monte Carlo: Theory, Methods and Examples. Stanford University, 2013. URLhttps://artowen.su.domains/mc/. Online book
2013
-
[46]
Particle denoising diffusion sampler.arXiv preprint arXiv:2402.06320, 2024
Angus Phillips, Hai-Dang Dau, Michael John Hutchinson, Valentin De Bortoli, George Deligiannidis, and Arnaud Doucet. Particle denoising diffusion sampler.arXiv preprint arXiv:2402.06320, 2024. doi: 10.48550/arXiv.2402.06320
-
[47]
Improved sampling via learned diffusions
Lorenz Richter and Julius Berner. Improved sampling via learned diffusions. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview. net/forum?id=F2cS6SozN9
2024
-
[48]
Robert and George Casella.Monte Carlo Statistical Methods
Christian P. Robert and George Casella.Monte Carlo Statistical Methods. Springer, New York, 2 edition, 2004. ISBN 978-0387212395
2004
-
[49]
CRC press, 1986
Bernard W Silverman.Density Estimation for Statistics and Data Analysis. CRC press, 1986
1986
-
[50]
2006, Bayesian Analysis, 1, 833 , doi: 10.1214/06-BA127
John Skilling. Nested sampling for general bayesian computation.Bayesian Analysis, 1(4): 833–859, 2006. doi: 10.1214/06-BA127
-
[51]
Nikolai V. Smirnov. Table for estimating the goodness of fit of empirical distributions.The Annals of Mathematical Statistics, 19(2):279–281, 1948
1948
-
[52]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InProceedings of the 32nd International Conference on Machine Learning, volume 37 ofProceedings of Machine Learning Research, pages 2256–2265. PMLR, 2015. URLhttps://proceedings.mlr.press/v37/ sohl-dickstein15.html
2015
-
[53]
Maximum likelihood training of score-based diffusion models
Yang Song, Conor Durkan, Iain Murray, and Stefano Ermon. Maximum likelihood training of score-based diffusion models. InAdvances in Neural Information Processing Systems, volume 34, pages 1415–1428, 2021. 71
2021
-
[54]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations (ICLR), 2021. URLhttps:// openreview.net/forum?id=PxTIG12RRHS
2021
-
[55]
Density estimation in infinite dimensional exponential families.Journal of Machine Learning Research, 18(57):1–59, 2017
Bharath K Sriperumbudur, Kenji Fukumizu, Arthur Gretton, Aapo Hyvärinen, and Revant Kumar. Density estimation in infinite dimensional exponential families.Journal of Machine Learning Research, 18(57):1–59, 2017
2017
-
[56]
A bound for the error in the normal approximation to the distribution of a sum of dependent random variables
Charles Stein. A bound for the error in the normal approximation to the distribution of a sum of dependent random variables. InProceedings of the Sixth Berkeley Symposium on Mathematical Statistics and Probability, Volume 2: Probability Theory, pages 583–602. University of California Press, 1972
1972
-
[57]
Andrew M. Stuart. Inverse problems: A bayesian perspective.Acta Numerica, 19:451–559,
-
[58]
doi: 10.1017/S0962492910000061
-
[59]
Luke Tierney and Joseph B. Kadane. Accurate approximations for posterior moments and marginal densities.Journal of the American Statistical Association, 81(393):82–86, 1986. doi: 10.1080/01621459.1986.10478240
-
[60]
Joel A. Tropp. User-friendly tail bounds for sums of random matrices.Foundations of Computational Mathematics, 12(4):389–434, 2012. doi: 10.1007/s10208-011-9099-z
-
[61]
van der Vaart.Asymptotic Statistics
Aad W. van der Vaart.Asymptotic Statistics. Cambridge University Press, 1998
1998
-
[62]
Transport meets variational inference: Controlled monte carlo diffusions
Francisco Vargas, Shreyas Padhy, Denis Blessing, and Nikolas N"usken. Transport meets variational inference: Controlled monte carlo diffusions. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id= PP1rudnxiW
2024
-
[63]
Cambridge University Press, 2018
Roman Vershynin.High-Dimensional Probability. Cambridge University Press, 2018
2018
-
[64]
A connection between score matching and denoising autoencoders https://doi.org/10.1162/NECO_a_00142
Pascal Vincent. A connection between score matching and denoising autoencoders.Neural Computation, 23(7):1661–1674, 2011. doi: 10.1162/NECO_a_00142
-
[65]
Wainwright.High-Dimensional Statistics
Martin J. Wainwright.High-Dimensional Statistics. Cambridge University Press, 2019
2019
-
[66]
Wenliang, Danica J
Li K. Wenliang, Danica J. Sutherland, Heiko Strathmann, and Arthur Gretton. Learning deep kernels for exponential family densities. InInternational Conference on Machine Learning (ICML), volume 97 ofProceedings of Machine Learning Research, pages 6737–6746. PMLR, 2019
2019
-
[67]
Naesseth, and John P
Luhuan Wu, Yi Han, Christian A. Naesseth, and John P. Cunningham. Reverse diffusion sequential monte carlo samplers. InAdvances in Neural Information Processing Systems,
-
[68]
URLhttps://arxiv.org/abs/2508.05926
-
[69]
James Matthew Young, Paula Cordero-Encinar, Sebastian Reich, Andrew Duncan, and "O. Deniz Akyildiz. Diffusion path samplers via sequential monte carlo.arXiv preprint arXiv:2601.21951, 2026. URLhttps://arxiv.org/abs/2601.21951
Pith/arXiv arXiv 2026
-
[70]
Path integral sampler: A stochastic control approach for sampling
Qinsheng Zhang and Yongxin Chen. Path integral sampler: A stochastic control approach for sampling. InInternational Conference on Learning Representations, 2022. URLhttps: //openreview.net/forum?id=_uCb2ynRu7Y. 72
2022
-
[71]
Nonparametric score estimators
Yuhao Zhou, Jiaxin Shi, and Jun Zhu. Nonparametric score estimators. InInternational Conference on Machine Learning (ICML), volume 119 ofProceedings of Machine Learning Research, pages 11513–11523. PMLR, 2020. 73
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.