Trading Utility for Dynamic Fairness in Multiple Resource Division with Sequential Demand
Pith reviewed 2026-06-27 11:12 UTC · model grok-4.3
The pith
Neural allocator achieves higher utility at comparable fairness in sequential multi-resource allocation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
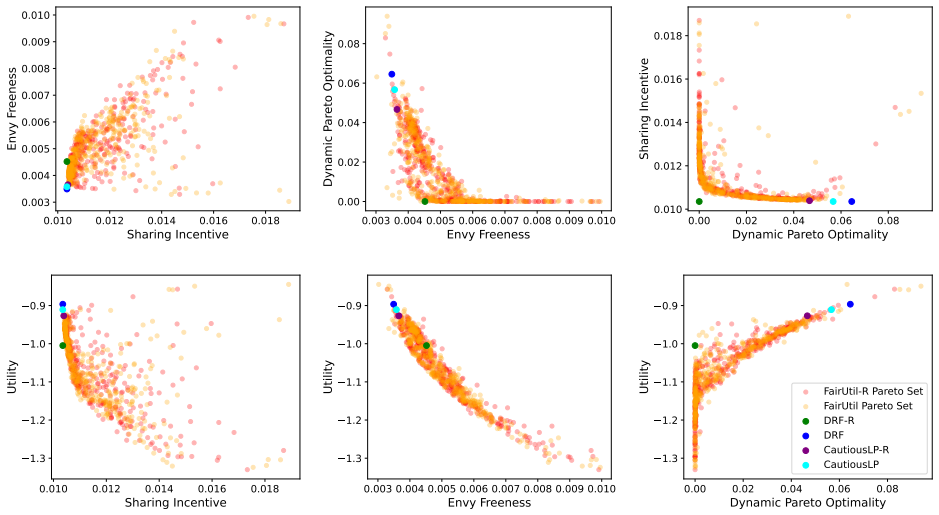
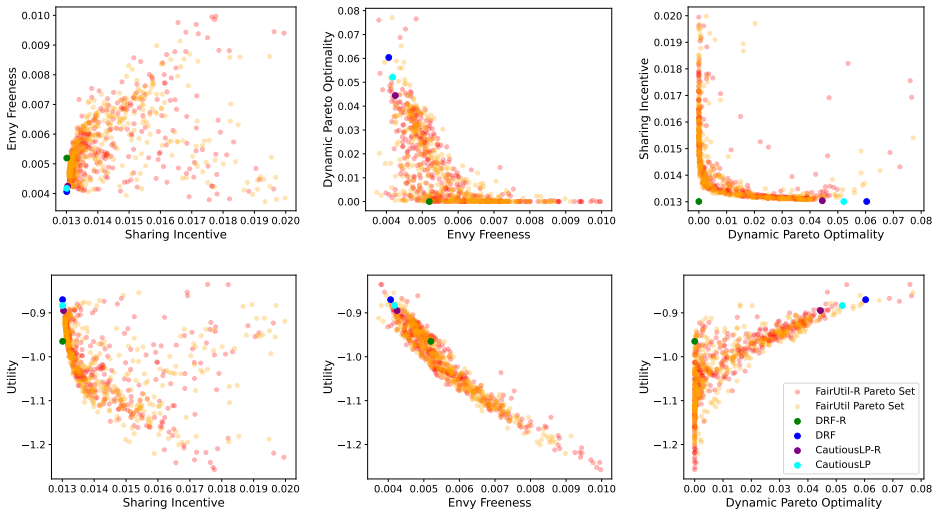
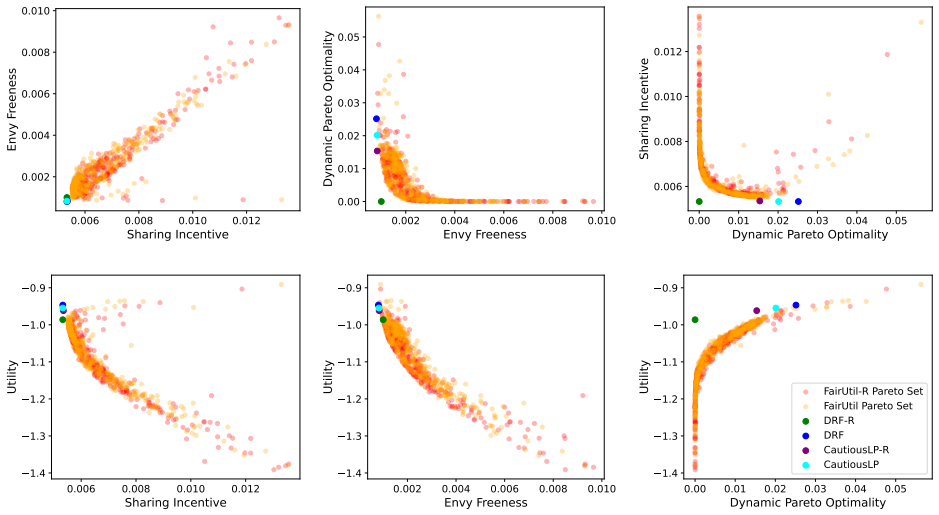
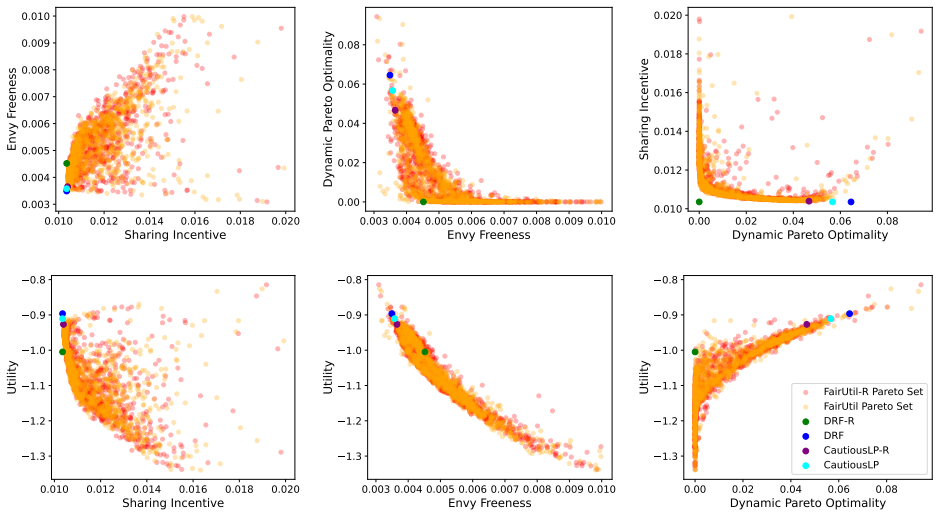
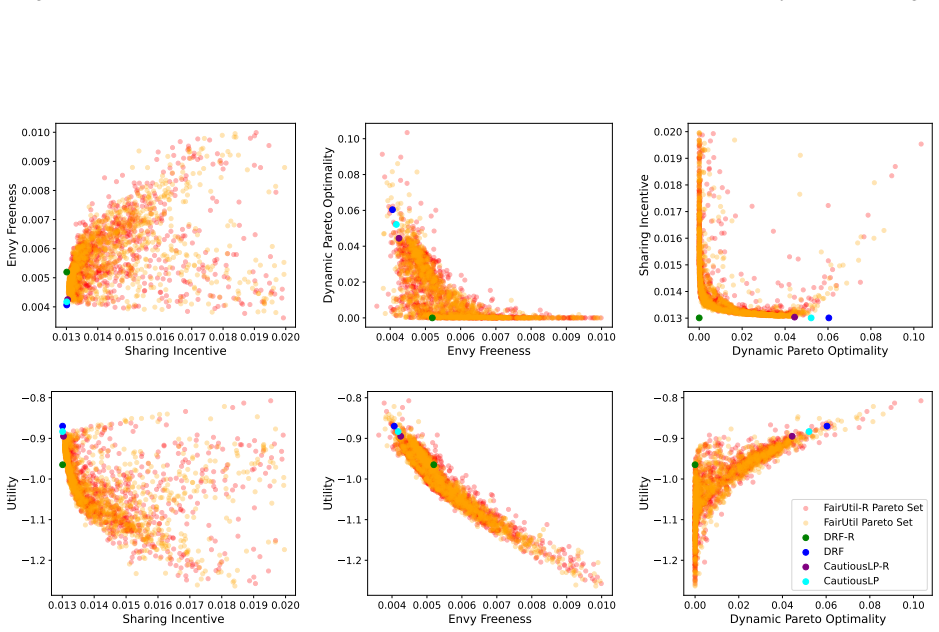
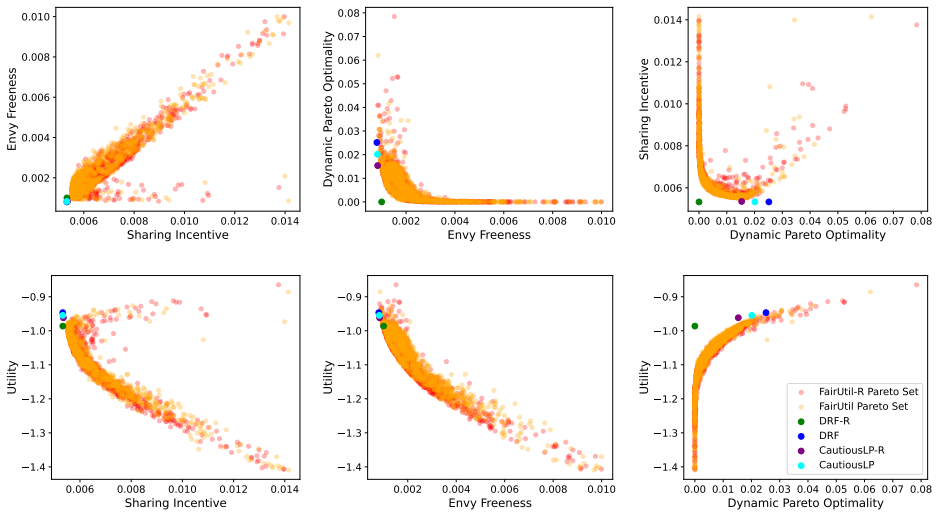
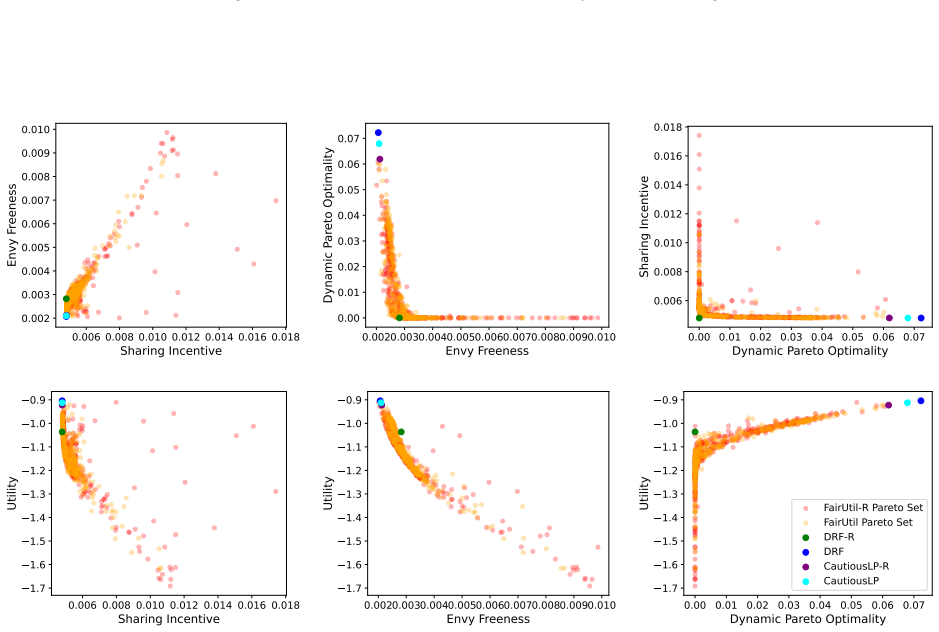
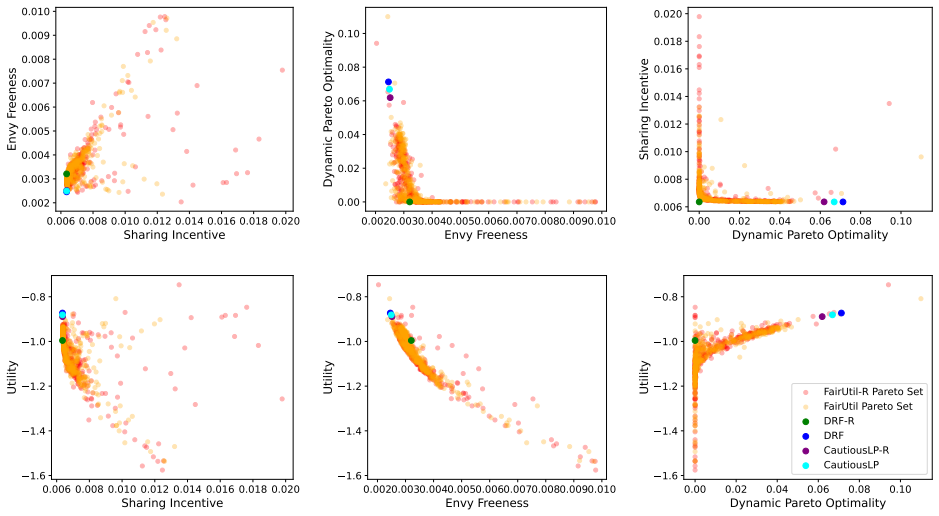
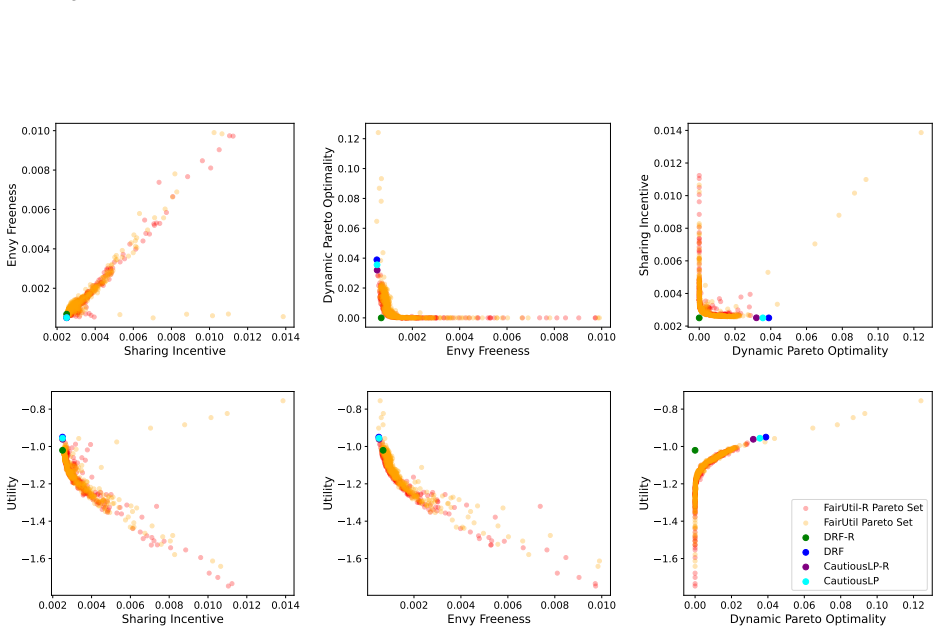
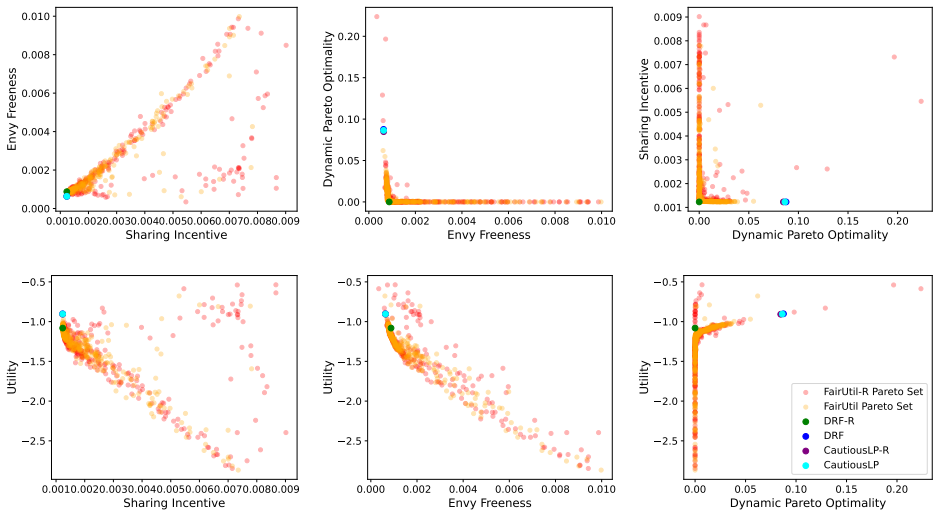
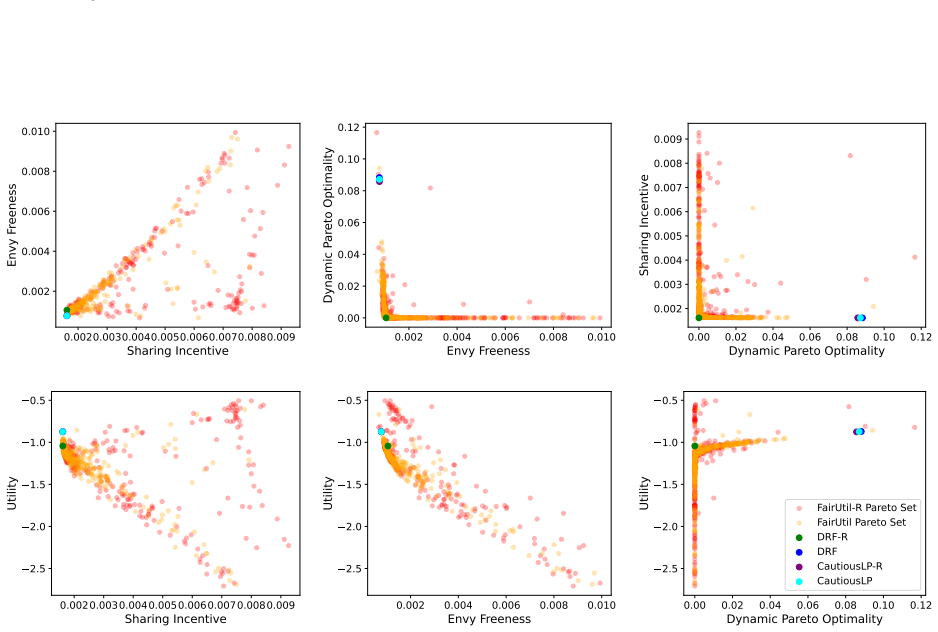
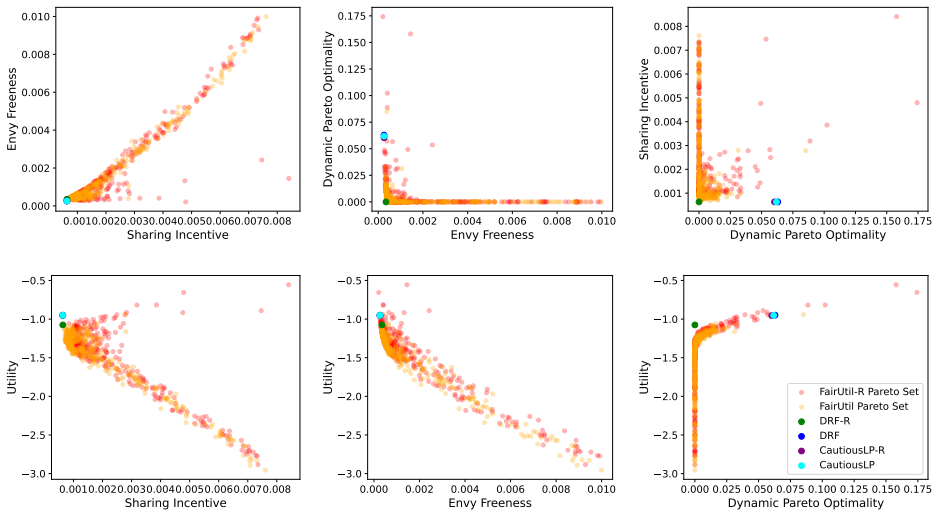
By training a neural allocator with multi-objective optimization over stepwise differentiable losses for Sharing Incentive, Envy Freeness, and Dynamic Pareto Optimality, and by parameterizing allocations within the demand subspace with elastic over-allocation, substantially higher utility is obtained at comparable fairness levels in dynamic sequential settings.
What carries the argument
Stepwise differentiable loss functions for the three fairness notions, used in multi-objective optimization during sequential rollout, together with demand-subspace parameterization of allocations.
If this is right
- The allocator operates without knowledge of future demands.
- Multi-objective training reveals Pareto frontiers between utility and each fairness metric.
- Non-wasteful allocations are enforced by the subspace constraint.
- Elastic over-allocation is permitted only when spare resources exist.
Where Pith is reading between the lines
- The same loss-based training could be applied to other sequential allocation problems with conflicting constraints.
- Deployment in cloud computing platforms would allow direct measurement of whether utility gains reduce operational costs.
- Hybrid systems combining the neural allocator with exact methods for small instances could be tested for scalability.
Load-bearing premise
The three fairness notions can be adequately represented by differentiable stepwise loss functions that, when minimized, produce allocations satisfying the original fairness properties.
What would settle it
A controlled experiment that measures actual fairness violations and total utility on a large set of held-out demand sequences, comparing the neural allocator against baseline methods that enforce fairness exactly.
Figures
read the original abstract
Dynamic multi-resource allocation is a central problem in shared computing environments, where users' demands arrive sequentially and resources must be distributed fairly without knowledge of future demands. Existing methods emphasize fairness guarantees such as Sharing Incentive, Envy Freeness, and Dynamic Pareto Optimality, but often overlook system utility. Moreover, these fairness criteria are mutually incompatible, preventing strict enforcement of them at the same time. We propose a neural allocation mechanism that reconciles fairness with utility through multi-objective optimization during sequential rollout. We first formalize fairness in the dynamic setting via stepwise loss functions for Sharing Incentive, Envy Freeness, and Dynamic Pareto Optimality, enabling differentiable training. Leveraging non-wastefulness, we parameterized the solutions by constraining allocations to the subspace of demand while allowing elastic over-allocation when resources remain available. Empirical results demonstrate that our learned allocator achieves substantially higher utility at comparable levels of fairness, uncovering clear Pareto-frontier-like tradeoffs across metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a neural allocation mechanism for dynamic multi-resource division under sequential user demands. It formalizes the fairness notions of Sharing Incentive, Envy Freeness, and Dynamic Pareto Optimality as stepwise differentiable loss functions, parameterizes allocations via non-wastefulness constraints on the demand subspace, and trains the allocator through multi-objective optimization to trade off these losses against system utility. The central empirical claim is that the learned allocator achieves substantially higher utility at comparable fairness levels, revealing clear Pareto-frontier-like tradeoffs across the metrics.
Significance. If the stepwise losses prove to be faithful proxies, the work would provide a practical, trainable approach to balancing utility and dynamic fairness in sequential resource allocation settings, which is relevant for shared computing systems. A strength is the explicit parameterization leveraging non-wastefulness and the empirical exploration of multi-objective tradeoffs; however, the absence of direct verification weakens the interpretability of the reported Pareto frontiers.
major comments (1)
- [Empirical Results] Empirical Results section: The claim of 'substantially higher utility at comparable levels of fairness' and the 'Pareto-frontier-like tradeoffs' rests on the training losses serving as faithful proxies for the original (non-differentiable) fairness properties. No post-training verification is described that measures the fraction of produced allocations satisfying the exact definitions of Sharing Incentive, Envy Freeness, and Dynamic Pareto Optimality on the final allocations. Because the properties are mutually incompatible in the sequential setting, this verification is load-bearing for interpreting the empirical results as meaningful tradeoffs.
minor comments (1)
- [Abstract] Abstract: The description of the 'stepwise loss functions' and the multi-objective optimization procedure lacks any concrete details on their functional form, weighting scheme, or training hyperparameters, which would aid reproducibility even at the abstract level.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for direct verification of the fairness properties. We address the comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Empirical Results] Empirical Results section: The claim of 'substantially higher utility at comparable levels of fairness' and the 'Pareto-frontier-like tradeoffs' rests on the training losses serving as faithful proxies for the original (non-differentiable) fairness properties. No post-training verification is described that measures the fraction of produced allocations satisfying the exact definitions of Sharing Incentive, Envy Freeness, and Dynamic Pareto Optimality on the final allocations. Because the properties are mutually incompatible in the sequential setting, this verification is load-bearing for interpreting the empirical results as meaningful tradeoffs.
Authors: We agree that the absence of post-training verification against the exact (non-differentiable) definitions limits the strength of the empirical claims. In the revised version we will add a dedicated evaluation subsection that, after training, measures the fraction of final allocations satisfying the precise definitions of Sharing Incentive, Envy Freeness, and Dynamic Pareto Optimality. We will report these fractions for each point on the reported tradeoff curves, thereby allowing readers to assess how closely the stepwise losses track the original properties. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces stepwise differentiable loss functions to approximate the fairness notions (Sharing Incentive, Envy Freeness, Dynamic Pareto Optimality) for training a neural allocator under multi-objective optimization, then reports empirical utility gains at comparable loss levels. This is a standard optimization setup with no reduction of claims to self-definitions, fitted inputs renamed as predictions, or load-bearing self-citations. The abstract and described approach contain no equations or steps that equate outputs to inputs by construction, and the method remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network weights
axioms (1)
- domain assumption Fairness criteria (SI, EF, DPO) can be formalized as differentiable stepwise loss functions
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 8th USENIX Symposium on Networked Systems Design and Implementation (NSDI) , pages=
Dominant resource fairness: Fair allocation of multiple resource types , author=. Proceedings of the 8th USENIX Symposium on Networked Systems Design and Implementation (NSDI) , pages=
-
[2]
2011 , eprint=
Online Cake Cutting (published version) , author=. 2011 , eprint=
2011
-
[3]
Proceedings of the 11th International Conference on Autonomous Agents and Multiagent Systems - Volume 2 , pages =
Gutman, Avital and Nisan, Noam , title =. Proceedings of the 11th International Conference on Autonomous Agents and Multiagent Systems - Volume 2 , pages =. 2012 , isbn =
2012
-
[4]
Ghodsi, Ali and Sekar, Vyas and Zaharia, Matei and Stoica, Ion , title =. 2012 , issue_date =. doi:10.1145/2377677.2377679 , month = aug, pages =
-
[5]
2003 , publisher=
Fair Division and Collective Welfare , author=. 2003 , publisher=
2003
-
[6]
and Shah, Nisarg , title =
Kash, Ian and Procaccia, Ariel D. and Shah, Nisarg , title =. Proceedings of the 2013 International Conference on Autonomous Agents and Multi-Agent Systems , pages =. 2013 , isbn =
2013
-
[7]
Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence,
Fair Division of Indivisible Goods: A Survey , author =. Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence,. 2022 , month =. doi:10.24963/ijcai.2022/756 , url =
-
[8]
2024 , eprint=
Temporal Fairness in Decision Making Problems , author=. 2024 , eprint=
2024
-
[9]
Friedman, Eric and Psomas, Christos-Alexandros and Vardi, Shai , title =. 2015 , isbn =. doi:10.1145/2764468.2764495 , pages =
-
[10]
Dynamic Fair Division with Partial Information , volume =
Benade, Gerdus and Halpern, Daniel and Psomas, Alexandros , booktitle =. Dynamic Fair Division with Partial Information , volume =
-
[11]
2020 , isbn =
Mahajan, Kshiteej and Balasubramanian, Arjun and Singhvi, Arjun and Venkataraman, Shivaram and Akella, Aditya and Phanishayee, Amar and Chawla, Shuchi , title =. 2020 , isbn =
2020
-
[12]
Karma: Resource Allocation for Dynamic Demands , booktitle =
Midhul Vuppalapati and Giannis Fikioris and Rachit Agarwal and Asaf Cidon and Anurag Khandelwal and. Karma: Resource Allocation for Dynamic Demands , booktitle =. 2023 , isbn =
2023
-
[13]
Alibaba Cluster Trace Program , year =
-
[14]
2020 , howpublished =
Microsoft Azure , title =. 2020 , howpublished =
2020
-
[15]
Zeng, David and Psomas, Alexandros , title =. 2020 , isbn =. doi:10.1145/3391403.3399467 , booktitle =
-
[16]
2025 , author =
Finding representative group fairness metrics using correlation estimations , journal =. 2025 , author =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.