Self-Conditioned Positional HNSW for Overlap-Aware Retrieval in Chunked-Document RAG Systems: Method and Industrial Evidence-Quality Audit
Pith reviewed 2026-06-28 13:08 UTC · model grok-4.3
The pith
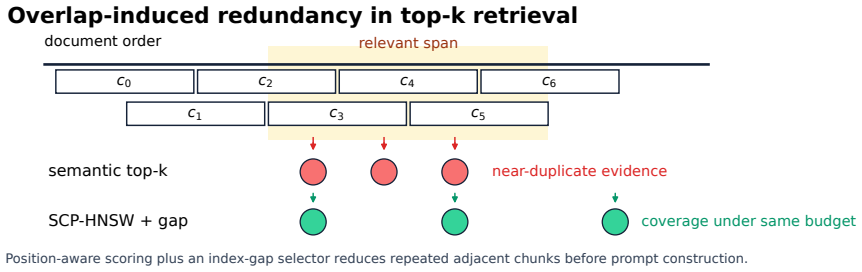
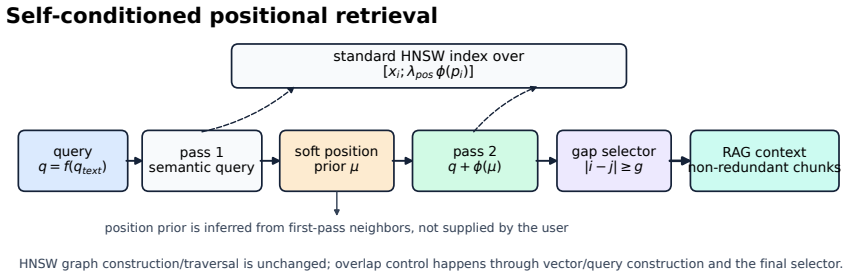
SCP-HNSW appends a low-dimensional positional code to embeddings and applies a two-pass query plus minimum-index-gap selector to cut near-adjacent chunk repeats in RAG retrieval without altering HNSW.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SCP-HNSW leaves HNSW graph construction and traversal unchanged while adding an auditable minimum-index-gap selector for final context construction. It appends a low-dimensional positional code to chunk embeddings and uses a two-pass query procedure to estimate and apply a query-specific document-position prior that reduces near-adjacent chunk retrieval.
What carries the argument
The two-pass query procedure with appended low-dimensional positional code that produces a query-specific document-position prior, followed by the minimum-index-gap selector for context assembly.
Load-bearing premise
The two-pass query and low-dimensional positional code produce a query-specific document-position prior that meaningfully reduces near-adjacent chunk retrieval without changes to the underlying HNSW index or traversal.
What would settle it
A side-by-side retrieval run on the same overlapping chunks showing no measurable drop in near-adjacent pairs returned when the positional code and two-pass procedure are added versus plain HNSW.
Figures
read the original abstract
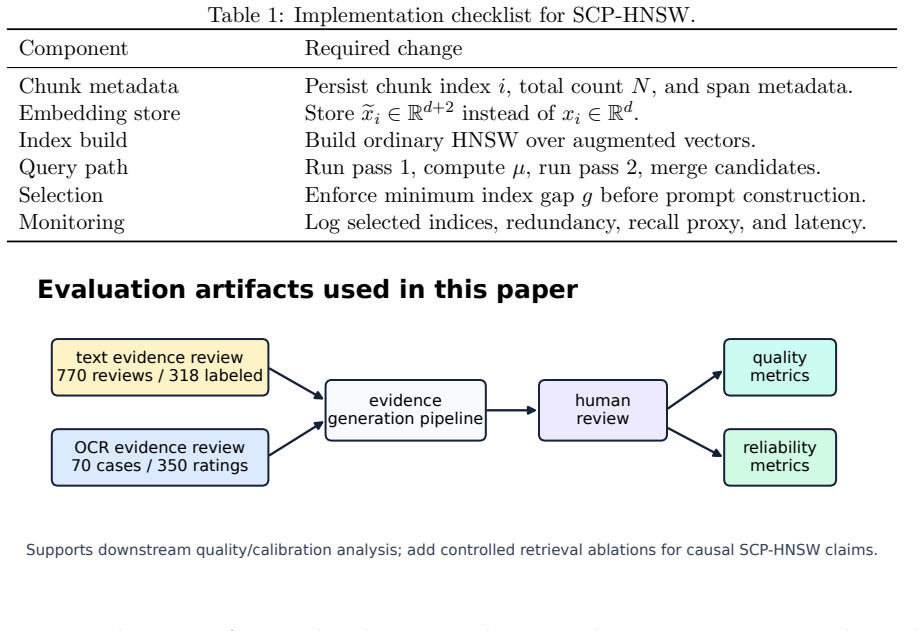
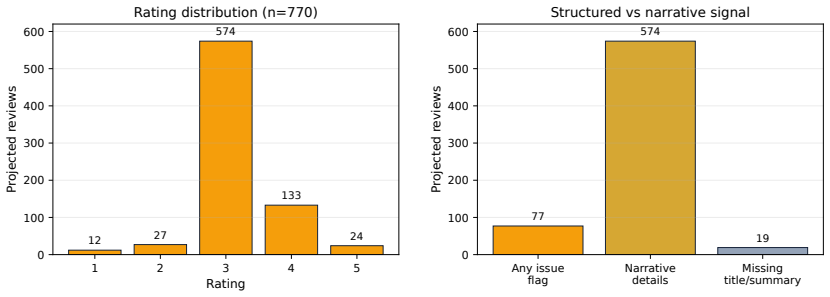
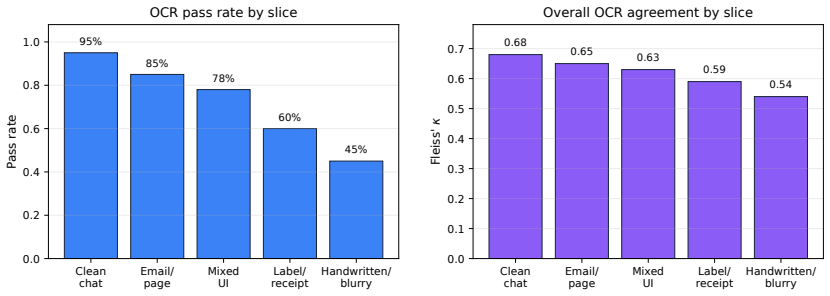
Chunked-document retrieval is a common component of retrieval-augmented generation (RAG) systems. Documents are split into overlapping chunks, embedded, and indexed with approximate nearest-neighbor search such as hierarchical navigable small world graphs (HNSW). Overlap improves boundary coverage but induces a practical failure mode: top-k retrieval often returns near-adjacent chunks that repeat evidence and waste prompt budget. We propose Self-Conditioned Positional HNSW (SCP-HNSW), a lightweight modification that appends a low-dimensional positional code to chunk embeddings and uses a two-pass query procedure to estimate and apply a query-specific document-position prior. SCP-HNSW leaves HNSW graph construction and traversal unchanged while adding an auditable minimum-index-gap selector for final context construction. We also integrate industrial review artifacts for generated evidence quality: a 770-review text-evidence audit with 318 fully labeled reviews and a 70-case OCR audit with 350 ratings. The text audit shows that 574 of 770 projected reviews are rated 3/5, only 39 fall in the 1-2 range, and narrative reviewer detail appears much more often than structured issue flags. The OCR audit shows slice-level pass rates from 95% for clean chat screenshots to 45% for handwritten/blurry captures, with moderate to strong agreement. These results motivate overlap-aware, audit-friendly RAG retrieval and identify the remaining controlled retrieval ablations needed for causal performance claims.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Self-Conditioned Positional HNSW (SCP-HNSW) for overlap-aware retrieval in chunked-document RAG systems. It appends a low-dimensional positional code to chunk embeddings and uses a two-pass query procedure to estimate a query-specific document-position prior, adding an auditable minimum-index-gap selector for final context construction while leaving HNSW graph construction and traversal unchanged. It also reports industrial evidence-quality audits: a 770-review text-evidence audit (with 318 fully labeled) showing 574 rated 3/5 and a 70-case OCR audit with slice-level pass rates from 95% to 45%.
Significance. If the positional prior demonstrably reduces duplicate near-adjacent chunks without harming recall, the approach would address a common practical inefficiency in overlapping-chunk RAG while remaining compatible with existing HNSW indexes. The inclusion of detailed industrial audit artifacts on evidence quality provides a useful template for auditable RAG evaluation, though the audits do not quantify retrieval improvements.
major comments (2)
- [Abstract] Abstract: the claim that the two-pass positional prior 'meaningfully reduces near-adjacent chunk retrieval' rests on description alone; no retrieval metrics (index-gap distribution, duplicate-evidence rate, recall@K, or ablation results) are supplied to support it, and the audits measure evidence quality rather than retrieval behavior.
- [Abstract] Abstract: the text states that the audits 'identify the remaining controlled retrieval ablations needed for causal performance claims,' confirming that the central effectiveness claim of the SCP-HNSW method lacks the quantitative retrieval validation required to substantiate the overlap-reduction benefit.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly defined the dimensionality of the positional code and the exact mechanics of the minimum-index-gap selector.
Simulated Author's Rebuttal
We thank the referee for identifying the gap between the method description and the lack of supporting retrieval metrics. We agree that the manuscript does not provide quantitative evidence (such as index-gap statistics, duplicate rates, or ablations) for the claimed overlap-reduction benefit, and that the reported audits address evidence quality rather than retrieval performance. We will revise the abstract and related sections to remove overstatements, explicitly scope the contribution to the method proposal plus audit artifacts, and note the need for future controlled experiments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the two-pass positional prior 'meaningfully reduces near-adjacent chunk retrieval' rests on description alone; no retrieval metrics (index-gap distribution, duplicate-evidence rate, recall@K, or ablation results) are supplied to support it, and the audits measure evidence quality rather than retrieval behavior.
Authors: We agree. The manuscript supplies only a descriptive account of the two-pass procedure and minimum-index-gap selector; no retrieval metrics or ablations are present. The audits evaluate generated evidence quality (text-evidence ratings and OCR pass rates) and do not measure retrieval behavior such as near-adjacent chunk frequency or recall. We will revise the abstract to eliminate the unsupported claim of meaningful reduction and to state clearly that retrieval-performance validation remains future work. revision: yes
-
Referee: [Abstract] Abstract: the text states that the audits 'identify the remaining controlled retrieval ablations needed for causal performance claims,' confirming that the central effectiveness claim of the SCP-HNSW method lacks the quantitative retrieval validation required to substantiate the overlap-reduction benefit.
Authors: This reading is correct. The manuscript already acknowledges that the audits do not supply the controlled retrieval ablations required for causal claims about overlap reduction. We will update the abstract wording to align with this limitation, ensuring the central claims are limited to the method design and the evidence-quality audit results that are actually reported. revision: yes
Circularity Check
No circularity: method description remains independent of inputs
full rationale
The abstract and provided text describe SCP-HNSW as appending a positional code and using a two-pass procedure to estimate a document-position prior, followed by an auditable selector, while explicitly leaving HNSW construction and traversal unchanged. No equations, fitted parameters, or self-citations are present that would reduce any claimed prediction or result to the inputs by construction. The audits are presented as separate evidence-quality reviews rather than as part of a derivation chain. No load-bearing self-citation, ansatz smuggling, or renaming of known results is exhibited. The derivation chain is therefore self-contained against the stated claims.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Y. A. Malkov and D. A. Yashunin. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs.IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(4):824–836, 2020
2020
-
[2]
M. Wang, X. Xu, Q. Yue, and Y. Wang. A comprehensive survey and experimental comparison of graph-based approximate nearest neighbor search.Proceedings of the VLDB Endowment, 14(11):1964–1978, 2021
1964
-
[3]
Gollapudi et al
S. Gollapudi et al. Filtered-DiskANN: Graph algorithms for approximate nearest neighbor search with filters. InProceedings of the ACM Web Conference, pages 3406–3416, 2023
2023
-
[4]
C. Zuo, M. Qiao, W. Zhou, F. Li, and D. Deng. SeRF: Segment graph for range-filtering approximate nearest neighbor search.Proceedings of the ACM on Management of Data, 2(1):69:1–69:26, 2024
2024
-
[5]
Patel, P
L. Patel, P. Kraft, C. Guestrin, and M. Zaharia. ACORN: Performant and predicate-agnostic search over vector embeddings and structured data.Proceedings of the ACM on Management of Data, 2024
2024
-
[6]
Carbonell and J
J. Carbonell and J. Goldstein. The use of MMR, diversity-based reranking for reordering documents and producing summaries. InProceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 335–336, 1998. 10
1998
-
[7]
Vaswani et al
A. Vaswani et al. Attention is all you need. InAdvances in Neural Information Processing Systems, 2017
2017
-
[8]
J. J. Rocchio. Relevance feedback in information retrieval. InThe SMART Retrieval System: Experiments in Automatic Document Processing, pages 313–323. Prentice-Hall, 1971
1971
-
[9]
Lewis et al
P. Lewis et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems, 2020
2020
-
[10]
J. Cohen. Weighted kappa: Nominal scale agreement with provision for scaled disagreement or partial credit.Psychological Bulletin, 70(4):213–220, 1968
1968
-
[11]
J. L. Fleiss. Measuring nominal scale agreement among many raters.Psychological Bulletin, 76(5):378–382, 1971. 11
1971
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.