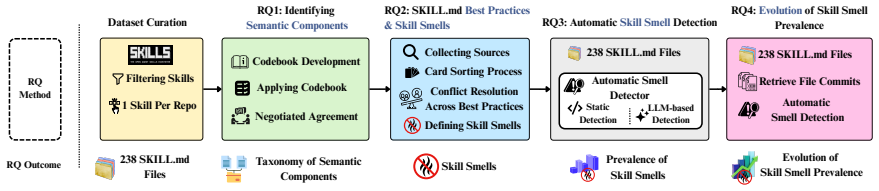
From Anatomy to Smells: An Empirical Study of SKILL.md in Agent Skills
Pith reviewed 2026-07-03 19:04 UTC · model grok-4.3
The pith
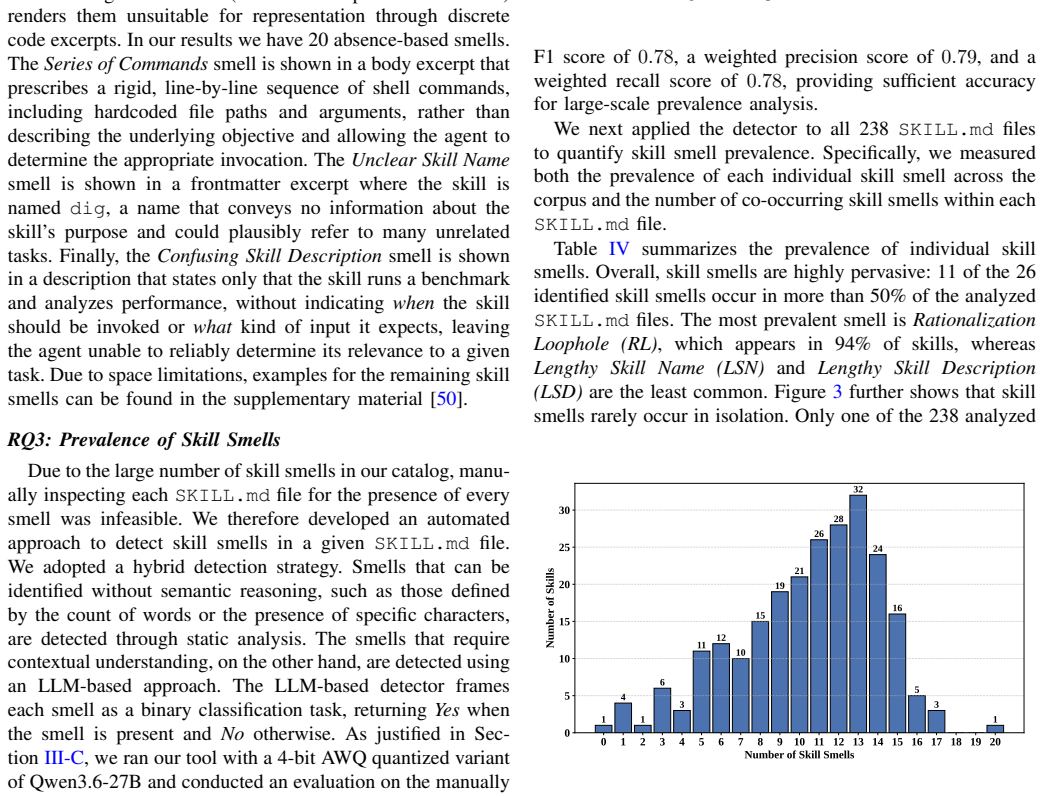
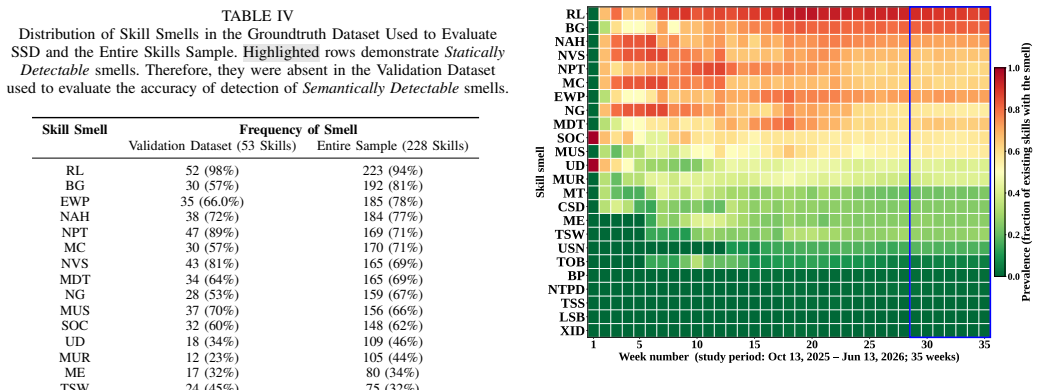
Over 99% of SKILL.md files contain at least one skill smell that rarely disappears over time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that skill smells are widespread, present in over 99% of SKILL.md files, and once introduced, they tend to remain as the skills evolve, revealing a substantial disconnect between recommended authoring guidelines and real-world practice.
What carries the argument
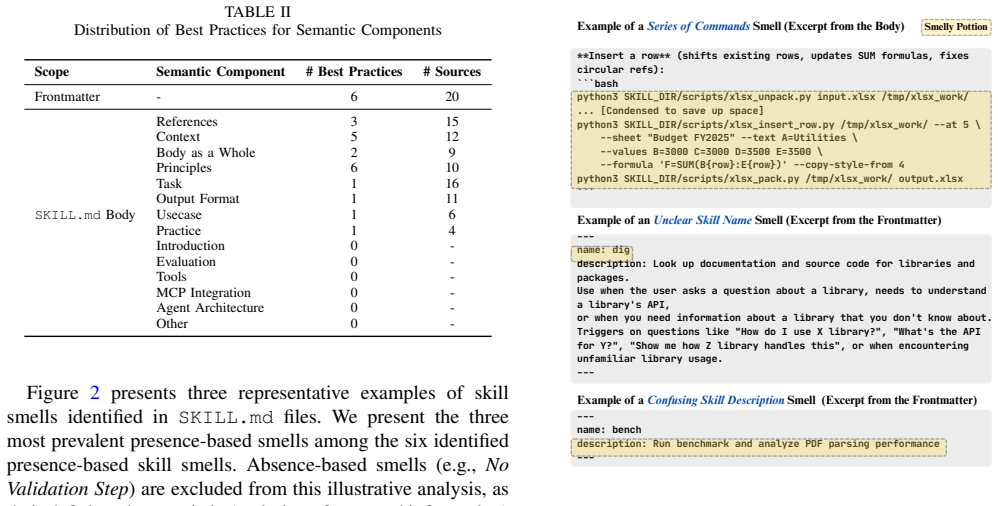
Skill smells, which are violations of best practices for SKILL.md authoring extracted from a multivocal literature review of 29 sources.
If this is right
- Automated detection tools can flag skill smells in existing and new SKILL.md files.
- The taxonomy of 13 higher-level and 44 lower-level components can guide better skill authoring.
- Skill evolution processes should include checks to remove or prevent smells.
- Developer awareness of this quality issue needs to increase to improve Agent Skill quality.
Where Pith is reading between the lines
- Tooling integrated into skill development environments could automatically suggest fixes for common smells.
- Similar smell detection might apply to other unstructured documentation formats used with AI agents.
- The persistence of smells suggests that without intervention, quality issues in agent skills could compound over time.
Load-bearing premise
The best practices drawn from the multivocal literature review of 29 sources correctly and comprehensively represent the authoring guidelines for SKILL.md files.
What would settle it
Reapplying the automated detector to a new, larger collection of SKILL.md files or conducting a longitudinal analysis of smell introduction and removal in evolving skills.
Figures
read the original abstract
Agent Skills provide on-demand domain knowledge to LLM agents without requiring model retraining. Each Agent Skill is defined by a mandatory SKILL.md file containing metadata and an unstructured Markdown body whose contents are left entirely to the skill author. Despite the rapid adoption of Agent Skills, little is known about how these files are authored or whether existing authoring guidelines are followed in practice. In this paper, we present the first systematic study of SKILL.md files as a software artifact. We qualitatively analyze 238 real-world skills and derive a taxonomy of 13 higher-level and 44 lower-level semantic components. We then conduct a multivocal literature review of 29 sources to identify best practices for authoring SKILL.md files and introduce skill smells as violations of these practices. Finally, we develop an automated detector and apply it to real-world skills, finding that over 99% of SKILL.md files contain at least one skill smell, and once introduced, skill smells rarely disappear as skills evolve. These findings reveal a substantial gap between recommended and actual authoring practices, motivating the development of automated techniques to remediate skill smells while increasing developer awareness of this emerging quality issue.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports the first systematic empirical study of SKILL.md files used to define Agent Skills for LLM agents. Through qualitative analysis of 238 real-world examples, the authors derive a taxonomy consisting of 13 higher-level and 44 lower-level semantic components. A multivocal literature review across 29 sources is used to extract best practices, from which 'skill smells' (violations of these practices) are defined. An automated detector is then applied, revealing that over 99% of SKILL.md files contain at least one skill smell, with longitudinal analysis showing that such smells rarely disappear as skills evolve. The study concludes there is a substantial gap between recommended and actual authoring practices.
Significance. If the central findings hold after addressing methodological details, this work would be significant as it provides the initial empirical characterization of an emerging software artifact in the rapidly growing area of LLM agents. It identifies a quality issue (skill smells) that affects nearly all instances and persists over time, which could inform the development of better authoring tools and guidelines. The combination of qualitative taxonomy, literature synthesis, and automated detection offers a replicable template for studying similar artifacts. The scale of the analysis (238 skills) and the introduction of an automated detector are strengths that support practical follow-on work.
major comments (3)
- [Multivocal literature review] The definition of skill smells and the >99% prevalence claim rest on the multivocal literature review of 29 sources to identify best practices, yet the manuscript provides no details on source selection criteria, search strategy, extraction process, or inter-rater validation for the derived best practices. This is load-bearing for the central claim that the detector identifies meaningful violations (see abstract and the section on multivocal literature review).
- [Qualitative analysis and detector application] No information is given on the sampling method for selecting the 238 SKILL.md files, inter-rater agreement for the qualitative taxonomy derivation (13 higher-level / 44 lower-level components), or validation of the automated detector (e.g., precision/recall on a labeled subset). These omissions make it difficult to assess whether the 99% figure reflects true prevalence or detector bias (see abstract and sections on qualitative analysis and automated detector).
- [Longitudinal analysis] The longitudinal claim that 'skill smells rarely disappear as skills evolve' lacks specifics on the number of skills with version history, how evolution was sampled, or quantitative criteria for 'rarely.' This directly affects the persistence finding and inherits the same validation gaps as the prevalence result (see abstract and results section).
minor comments (1)
- [Abstract] The abstract states the detector was applied to 'real-world skills' but does not clarify whether this is the same 238 or an expanded set; adding the exact count and any overlap would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which highlights important areas for improving the transparency and replicability of our study. We address each major comment below, indicating where we will revise the manuscript to provide the requested methodological details.
read point-by-point responses
-
Referee: [Multivocal literature review] The definition of skill smells and the >99% prevalence claim rest on the multivocal literature review of 29 sources to identify best practices, yet the manuscript provides no details on source selection criteria, search strategy, extraction process, or inter-rater validation for the derived best practices. This is load-bearing for the central claim that the detector identifies meaningful violations (see abstract and the section on multivocal literature review).
Authors: We agree that the multivocal literature review section requires expanded methodological reporting to support the derivation of best practices and skill smells. In the revision, we will add a dedicated 'Multivocal Literature Review Methodology' subsection that specifies: (1) search strategy (keywords such as 'agent skill', 'SKILL.md', 'LLM agent documentation' applied to Google Scholar, arXiv, GitHub, and practitioner blogs/forums); (2) source selection criteria (relevance to authoring practices for agent skills or analogous documentation, published 2023-2024, excluding duplicates); (3) the 29 sources with a summary table; and (4) extraction process (thematic coding by two authors, with consensus resolution). Inter-rater agreement on a 20% sample of sources yielded Cohen's kappa of 0.82. These additions will directly address the load-bearing concern for the skill smells definition. revision: yes
-
Referee: [Qualitative analysis and detector application] No information is given on the sampling method for selecting the 238 SKILL.md files, inter-rater agreement for the qualitative taxonomy derivation (13 higher-level / 44 lower-level components), or validation of the automated detector (e.g., precision/recall on a labeled subset). These omissions make it difficult to assess whether the 99% figure reflects true prevalence or detector bias (see abstract and sections on qualitative analysis and automated detector).
Authors: We acknowledge the need for greater detail on data collection, qualitative coding, and detector validation. The revised manuscript will include a 'Data Collection and Sampling' subsection explaining that the 238 SKILL.md files were obtained via purposive sampling from public GitHub repositories and skill-sharing platforms using targeted searches for files named SKILL.md across diverse domains (e.g., code, data, web). For the taxonomy derivation, two authors performed independent open coding on all files, followed by axial coding to reach the 13/44 structure; inter-rater agreement on a randomly selected 20% subset was 87% (Cohen's kappa 0.79), with all disagreements resolved via discussion. For the automated detector, we will report results from validation on a held-out manually labeled set of 40 skills, yielding precision 0.91 and recall 0.87. These changes will allow readers to evaluate potential bias in the 99% prevalence result. revision: yes
-
Referee: [Longitudinal analysis] The longitudinal claim that 'skill smells rarely disappear as skills evolve' lacks specifics on the number of skills with version history, how evolution was sampled, or quantitative criteria for 'rarely.' This directly affects the persistence finding and inherits the same validation gaps as the prevalence result (see abstract and results section).
Authors: We agree that the longitudinal analysis section needs quantitative grounding. In the revision, we will expand the relevant results subsection to report: (1) 47 skills were identified with accessible version histories (via Git repositories); (2) evolution was sampled by examining all available versions (minimum 3 per skill) and tracking smell introduction/removal across commits; and (3) quantitative criteria, where 'rarely' is operationalized as smells being removed in fewer than 8% of cases (specifically, 4 of 47 skills showed net smell reduction, while 39 showed persistence or increase). We will also note that this analysis inherits the detector validation described in the response to the second comment. These specifics will be added without altering the core finding. revision: yes
Circularity Check
No significant circularity; purely observational empirical study
full rationale
The paper derives a taxonomy from qualitative analysis of 238 external SKILL.md files, extracts best practices via multivocal review of 29 independent sources, defines skill smells as violations of those practices, and reports direct counts (>99% prevalence) plus longitudinal observations from applying a detector to real-world files. No equations, fitted parameters renamed as predictions, self-citations as load-bearing premises, self-definitional constructs, or ansatzes smuggled via prior work exist. The central claims are direct empirical measurements against an externally sourced definition, not reductions by construction to the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 29 sources reviewed in the multivocal literature review provide a complete and accurate set of best practices for authoring SKILL.md files.
invented entities (1)
-
skill smell
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Claude Code
Anthropic. Claude Code. [Online]. Available: https://github.com/ anthropics/claude-code
-
[2]
GitHub Copilot
GitHub and OpenAI. GitHub Copilot. [Online]. Available: https: //github.com/features/copilot
-
[3]
Agent Skills
Anthropic. Agent Skills. [Online]. Available: https://github.com/ agentskills/agentskills
-
[4]
[Online]
The Agent Skills Directory. [Online]. Available: https://www.skills.sh
-
[5]
[Online]
AI Agent Skills Directory. [Online]. Available: https://agentskill.sh/
-
[6]
[Online]
Agent Skills - Specification. [Online]. Available: https://agentskills.io/ specification
-
[7]
Y AML Ain’t Markup Language
Y AML. Y AML Ain’t Markup Language. [Online]. Available: https: //yaml.org/
-
[8]
Skillsbench: Benchmarking how well agent skills work across diverse tasks,
X. Liet al., “Skillsbench: Benchmarking how well agent skills work across diverse tasks,” 2026
2026
-
[9]
Technical report: Exploring the emerging threats of the agent skill ecosystem,
L. Beurer-Kellner, A. Kudrinskii, M. Milanta, K. B. Nielsen, H. Sarkar, and L. Tal, “Technical report: Exploring the emerging threats of the agent skill ecosystem,” 2026
2026
-
[10]
Skillprobe: Security auditing for emerging agent skill marketplaces via multi-agent collaboration,
Z. Guo, Z. Chen, X. Nie, J. Lin, Y . Zhou, and W. Zhang, “Skillprobe: Security auditing for emerging agent skill marketplaces via multi-agent collaboration,” 2026
2026
-
[11]
Agent skills in the wild: An empirical study of security vulnerabilities at scale,
Y . Liuet al., “Agent skills in the wild: An empirical study of security vulnerabilities at scale,” 2026
2026
-
[12]
Agent skills enable a new class of realistic and trivially simple prompt injections,
D. Schmotz, S. Abdelnabi, and M. Andriushchenko, “Agent skills enable a new class of realistic and trivially simple prompt injections,” 2025
2025
-
[13]
Boa: A language and infrastructure for analyzing ultra-large-scale software repositories,
R. Dyer, H. A. Nguyen, H. Rajan, and T. N. Nguyen, “Boa: A language and infrastructure for analyzing ultra-large-scale software repositories,” in2013 35th International Conference on Software Engineering (ICSE), 2013, pp. 422–431
2013
-
[14]
Commit message matters: Investigating impact and evolution of commit message quality,
J. Li and I. Ahmed, “Commit message matters: Investigating impact and evolution of commit message quality,” in2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), 2023, pp. 806–817
2023
-
[15]
(”agent skills
Google Search Results for “(”agent skills” OR ”SKILL.md”) AND (”best practices”)”. [Online]. Available: https://www.google.com/search?q=%28%22agent+skills%22+OR+ %22SKILL.md%22%29+AND+%28%22best+practices%22%29& num=50&tbs=cdr:1,cd max:06/01/2026
2026
-
[16]
On the diffuseness and the impact on maintainability of code smells: a large scale empirical investigation,
F. Palomba, G. Bavota, M. Di Penta, F. Fasano, R. Oliveto, and A. De Lucia, “On the diffuseness and the impact on maintainability of code smells: a large scale empirical investigation,” inProceedings of the 40th International Conference on Software Engineering. Association for Computing Machinery, 2018, p. 482
2018
-
[17]
An empirical study of code smells in javascript projects,
A. Saboury, P. Musavi, F. Khomh, and G. Antoniol, “An empirical study of code smells in javascript projects,” in2017 IEEE 24th Interna- tional Conference on Software Analysis, Evolution and Reengineering (SANER), 2017, pp. 294–305
2017
-
[18]
Skillreducer: Optimizing llm agent skills for token efficiency,
Y . Gao, Z. Li, Yuanyuanyuan, Z. Ji, P. Ma, and S. Wang, “Skillreducer: Optimizing llm agent skills for token efficiency,” 2026
2026
-
[19]
An empirical study of design degradation: How software projects get worse over time,
I. Ahmed, U. A. Mannan, R. Gopinath, and C. Jensen, “An empirical study of design degradation: How software projects get worse over time,” in2015 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM), 2015, pp. 1–10
2015
-
[20]
Coevoskills: Self-evolving agent skills via co- evolutionary verification,
H. Zhanget al., “Coevoskills: Self-evolving agent skills via co- evolutionary verification,” 2026
2026
-
[21]
Skillclaw: Let skills evolve collectively with agentic evolver,
Z. Maet al., “Skillclaw: Let skills evolve collectively with agentic evolver,” 2026
2026
-
[22]
Agent skills: A data-driven analysis of claude skills for extending large language model functionality,
G. Ling, S. Zhong, and R. Huang, “Agent skills: A data-driven analysis of claude skills for extending large language model functionality,” 2026
2026
-
[23]
Swe-skills-bench: Do agent skills actually help in real- world software engineering?
T. Hanet al., “Swe-skills-bench: Do agent skills actually help in real- world software engineering?” 2026
2026
-
[24]
Skillmoo: Multi-objective optimization of agent skills for software engineering,
J. Gonget al., “Skillmoo: Multi-objective optimization of agent skills for software engineering,” 2026
2026
-
[25]
Context matters: Repository-aware security analysis of the agent skill ecosystem,
F. Holzbauer, D. Schmidt, G. K. Gegenhuber, S. Schrittwieser, and J. Ullrich, “Context matters: Repository-aware security analysis of the agent skill ecosystem,” inFirst Workshop on Agent Skills, 2026
2026
-
[26]
Skvm: Revisiting language vm for skills across heterogenous llms and harnesses,
L. Chen, E. Feng, Y . Xia, and H. Chen, “Skvm: Revisiting language vm for skills across heterogenous llms and harnesses,” 2026
2026
-
[27]
open-index/open-skills
OpenIndex. open-index/open-skills. [Online]. Available: https: //huggingface.co/datasets/open-index/open-skills
-
[28]
Sampling projects in github for msr studies,
O. Dabic, E. Aghajani, and G. Bavota, “Sampling projects in github for msr studies,” in2021 IEEE/ACM 18th International Conference on Mining Software Repositories (MSR), 2021, pp. 560–564
2021
-
[29]
Bag of Tricks for Efficient Text Classification
A. Joulin, E. Grave, P. Bojanowski, and T. Mikolov, “Bag of tricks for efficient text classification,”arXiv preprint arXiv:1607.01759, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[30]
FastText.zip: Compressing text classification models
A. Joulin, E. Grave, P. Bojanowski, M. Douze, H. J ´egou, and T. Mikolov, “Fasttext.zip: Compressing text classification models,”arXiv preprint arXiv:1612.03651, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[31]
Diversity in software engineering research,
M. Nagappan, T. Zimmermann, and C. Bird, “Diversity in software engineering research,” inProceedings of the 2013 9th Joint Meeting on Foundations of Software Engineering. Association for Computing Machinery, 2013, p. 466–476
2013
-
[32]
Categoriz- ing the content of github readme files,
G. A. A. Prana, C. Treude, F. Thung, T. Atapattu, and D. Lo, “Categoriz- ing the content of github readme files,”Empirical Software Engineering, vol. 24, no. 3, pp. 1296–1327, Jun 2019
2019
-
[33]
[Online]
Handbook Markdown Guide — The GitLab Handbook. [Online]. Available: https://handbook.gitlab.com/docs/markdown-guide/
-
[34]
Prompting in the wild: An empirical study of prompt evolution in software repositories,
M. Tafreshipour, A. Imani, E. Huang, E. S. d. Almeida, T. Zimmermann, and I. Ahmed, “Prompting in the wild: An empirical study of prompt evolution in software repositories,” in2025 IEEE/ACM 22nd Interna- tional Conference on Mining Software Repositories (MSR), 2025, pp. 686–698
2025
-
[35]
Corbin and A
J. Corbin and A. Strauss,Basics of qualitative research. sage, 2015, vol. 14
2015
-
[36]
Basics of qualitative research techniques,
A. Strauss and J. Corbin, “Basics of qualitative research techniques,” 1998
1998
-
[37]
Towards rigor in reviews of multivocal literatures: Applying the exploratory case study method,
R. T. Ogawa and B. Malen, “Towards rigor in reviews of multivocal literatures: Applying the exploratory case study method,”Review of Educational Research, vol. 61, no. 3, pp. 265–286, 1991
1991
-
[38]
Only diff is not enough: Generating commit messages leveraging reasoning and action of large language model,
J. Li, D. Farag ´o, C. Petrov, and I. Ahmed, “Only diff is not enough: Generating commit messages leveraging reasoning and action of large language model,” vol. 1, no. FSE, Jul. 2024
2024
-
[39]
[Online]
SKILL.md Security: Best Practices for Safe AI Agent Skills. [Online]. Available: https://www.agensi.io/learn/skill-md-security-best-practices
-
[40]
Card-sorting: From text to themes,
T. Zimmermann, “Card-sorting: From text to themes,” inPerspectives on Data Science for Software Engineering, T. Menzies, L. Williams, and T. Zimmermann, Eds. Morgan Kaufmann, 2016, pp. 137–141
2016
-
[41]
Can llms replace human evaluators? an empirical study of llm-as-a-judge in software engineering,
R. Wang, J. Guo, C. Gao, G. Fan, C. Y . Chong, and X. Xia, “Can llms replace human evaluators? an empirical study of llm-as-a-judge in software engineering,”Proc. ACM Softw. Eng., vol. 2, no. ISSTA, Jun. 2025
2025
-
[42]
Can llms replace manual annotation of software engineering artifacts?
T. Ahmed, P. Devanbu, C. Treude, and M. Pradel, “Can llms replace manual annotation of software engineering artifacts?” 2025
2025
-
[43]
Context conquers parameters: Outperforming proprietary llm in commit message generation,
A. Imani, I. Ahmed, and M. Moshirpour, “Context conquers parameters: Outperforming proprietary llm in commit message generation,” inPro- ceedings of the IEEE/ACM 47th International Conference on Software Engineering. IEEE Press, 2025, p. 1844–1856
2025
-
[44]
Larger is not always better: Exploring small open- source language models in logging statement generation,
R. Zhonget al., “Larger is not always better: Exploring small open- source language models in logging statement generation,”ACM Trans. Softw. Eng. Methodol., Oct. 2025
2025
-
[45]
Qwen3.6-27B: Flagship-level coding in a 27B dense model,
Qwen Team, “Qwen3.6-27B: Flagship-level coding in a 27B dense model,” April 2026. [Online]. Available: https://qwen.ai/blog?id=qwen3. 6-27b
2026
-
[46]
Awq: Activation-aware weight quantization for on-device llm compression and acceleration,
J. Linet al., “Awq: Activation-aware weight quantization for on-device llm compression and acceleration,” inProceedings of Machine Learning and Systems, P. Gibbons, G. Pekhimenko, and C. D. Sa, Eds., vol. 6, 2024, pp. 87–100
2024
-
[47]
cyankiwi/Qwen3.6-27B-AWQ-INT4
cyankiwi. cyankiwi/Qwen3.6-27B-AWQ-INT4. [Online]. Available: https://huggingface.co/cyankiwi/Qwen3.6-27B-AWQ-INT4
-
[48]
Let me speak freely? a study on the impact of format restrictions on large language model performance
Z. R. Tam, C.-K. Wu, Y .-L. Tsai, C.-Y . Lin, H.-y. Lee, and Y .-N. Chen, “Let me speak freely? a study on the impact of format restrictions on large language model performance.” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, F. Dernoncourt, D. Preot ¸iuc-Pietro, and A. Shimorina, Eds. Association...
2024
-
[49]
Qwen/Qwen3.6
Qwen. Qwen/Qwen3.6. [Online]. Available: https://huggingface.co/ Qwen/Qwen3.6-27B
-
[50]
(2026) Supplementary Material
Anonymous. (2026) Supplementary Material. [Online]. Available: https://anonymous.4open.science/r/skill-smells/
2026
-
[51]
Platform
C. Platform. agent-skills/best-practices. [Online]. Avail- able: https://platform.claude.com/docs/en/agents-and-tools/agent-skills/ best-practices 11
-
[52]
M. Learn. Agent Skills. [Online]. Available: https://learn.microsoft. com/en-us/agent-framework/agents/skills
-
[53]
Research
P. Research. Designing, Refining, and Maintaining Agent Skills at Perplexity. [Online]. Available: https://research.perplexity.ai/articles/ designing-refining-and-maintaining-agent-skills-at-perplexity
-
[54]
B. Poudel. The SKILL.md Pattern: How to Write AI Agent Skills That Actually Work. [Online]. Available: https://bibek-poudel.medium.com/ the-skill-md-pattern-how-to-write-ai-agent-skills-that-actually-work-72a3169dd7ee
-
[55]
G. CLI. Agent Skill best practices. [Online]. Available: https: //geminicli.com/docs/cli/skills-best-practices/
-
[56]
C. S. Hub. Agent Skills Best Practices: Complete Guide to Writing Effective Claude Skills. [Online]. Available: https://claudeskills.info/ blog/agent-skills-best-practices/
-
[57]
Procedural knowledge improves agentic llm workflows,
V . Hsiao, M. Roberts, and L. Smith, “Procedural knowledge improves agentic llm workflows,” 2025
2025
-
[58]
C. Huanget al., “What affects the stability of tool learning? an empirical study on the robustness of tool learning frameworks,” 2024. [Online]. Available: https://arxiv.org/abs/2407.03007
-
[59]
Enhancing decision-making for llm agents via step-level q-value models,
Y . Zhaiet al., “Enhancing decision-making for llm agents via step-level q-value models,” inProceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational Advances in Artificial Intelligence. AAAI Press, 2025
2025
-
[60]
What Prompts Don't Say: Understanding and Managing Underspecification in LLM Prompts
C. Yang, Y . Shi, Q. Ma, M. X. Liu, C. K ¨astner, and T. Wu, “What prompts don’t say: Understanding and managing underspecification in llm prompts,”arXiv preprint arXiv:2505.13360, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Plan-and-solve prompting: Improving zero-shot chain- of-thought reasoning by large language models,
L. Wanget al., “Plan-and-solve prompting: Improving zero-shot chain- of-thought reasoning by large language models,” inProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), 2023, pp. 2609–2634
2023
-
[62]
Self-refine: Iterative refinement with self-feedback,
A. Madaanet al., “Self-refine: Iterative refinement with self-feedback,” Advances in neural information processing systems, vol. 36, pp. 46 534– 46 594, 2023
2023
-
[63]
Web-shepherd: Advancing prms for reinforcing web agents,
H. Chaeet al., “Web-shepherd: Advancing prms for reinforcing web agents,”Advances in Neural Information Processing Systems, vol. 38, pp. 63 314–63 356, 2026
2026
-
[64]
Reward Hacking Benchmark: Measuring Exploits in LLM Agents with Tool Use
K. Thaman, “Reward hacking benchmark: measuring exploits in llm agents with tool use,”arXiv preprint arXiv:2605.02964, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[65]
Recognizing limits: Investigating in- feasibility in large language models,
W. Zhang, Z. Xu, and H. Cai, “Recognizing limits: Investigating in- feasibility in large language models,”arXiv preprint arXiv:2408.05873, 2024
-
[66]
AgentSpec: Customizable Runtime Enforcement for Safe and Reliable LLM Agents
H. Wang, C. M. Poskitt, and J. Sun, “Agentspec: Customizable run- time enforcement for safe and reliable llm agents,”arXiv preprint arXiv:2503.18666, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Same task, more tokens: the impact of input length on the reasoning performance of large language models,
M. Levy, A. Jacoby, and Y . Goldberg, “Same task, more tokens: the impact of input length on the reasoning performance of large language models,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 15 339–15 353
2024
-
[68]
RULER: What's the Real Context Size of Your Long-Context Language Models?
C.-P. Hsiehet al., “Ruler: What’s the real context size of your long- context language models?”arXiv preprint arXiv:2404.06654, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[69]
Super-NaturalInstructions: Generalization via declar- ative instructions on 1600+ NLP tasks,
Y . Wanget al., “Super-NaturalInstructions: Generalization via declar- ative instructions on 1600+ NLP tasks,” inProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Y . Goldberg, Z. Kozareva, and Y . Zhang, Eds. Association for Computational Linguistics, Dec. 2022, pp. 5085–5109
2022
-
[70]
Towards benchmarking and improving the temporal reasoning capability of large language models,
Q. Tan, H. T. Ng, and L. Bing, “Towards benchmarking and improving the temporal reasoning capability of large language models,” inProceed- ings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 14 820–14 835
2023
-
[71]
Not what you’ve signed up for: Compromising real-world llm- integrated applications with indirect prompt injection,
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real-world llm- integrated applications with indirect prompt injection,” inProceedings of the 16th ACM workshop on artificial intelligence and security, 2023, pp. 79–90
2023
-
[72]
Tooltweak: An attack on tool selection in llm-based agents,
J. Snehet al., “Tooltweak: An attack on tool selection in llm-based agents,”arXiv preprint arXiv:2510.02554, 2025
-
[73]
From prompts to templates: A systematic prompt template analysis for real-world llmapps,
Y . Mao, J. He, and C. Chen, “From prompts to templates: A systematic prompt template analysis for real-world llmapps,” inProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering, 2025, pp. 75–86. 12
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.