Identifying Latent Concepts and Structures for Generalized Category Discovery
Pith reviewed 2026-07-02 14:39 UTC · model grok-4.3
The pith
Compositional Primitive Fields decompose images into reusable parts so novel categories appear as new patterns over a shared vocabulary.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
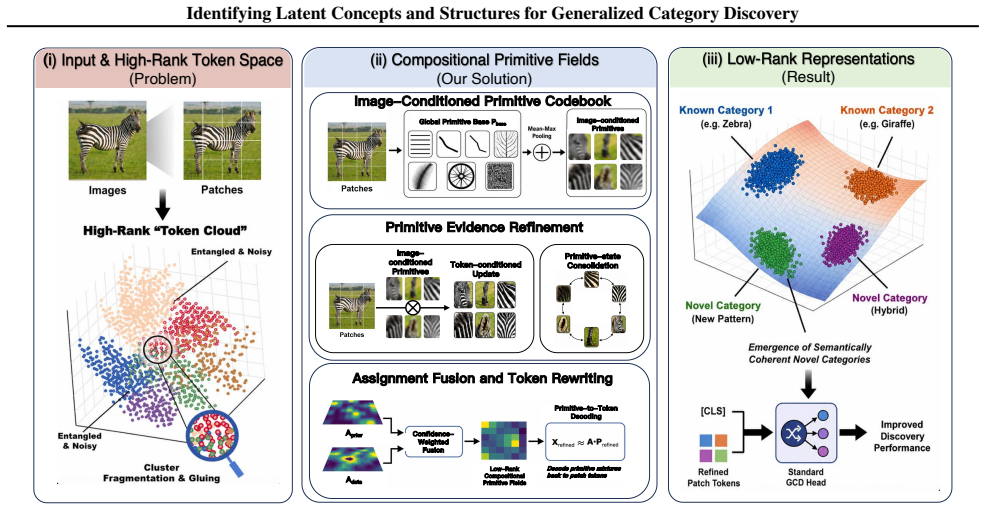
The central claim is that all categories can be expressed as compositions and spatial arrangements of a finite set of learnable visual primitives. CPF-GCD instantiates this geometric constraint by inserting a spatial field mechanism between the backbone and the head that rewrites noisy patch tokens through low-rank primitive mixtures, decomposing each image into reusable atomic parts and their layouts. Novel categories then emerge naturally as new activation patterns over the shared vocabulary, moving the representation focus from partitioning global embeddings to constructing a structured and separable primitive field.
What carries the argument
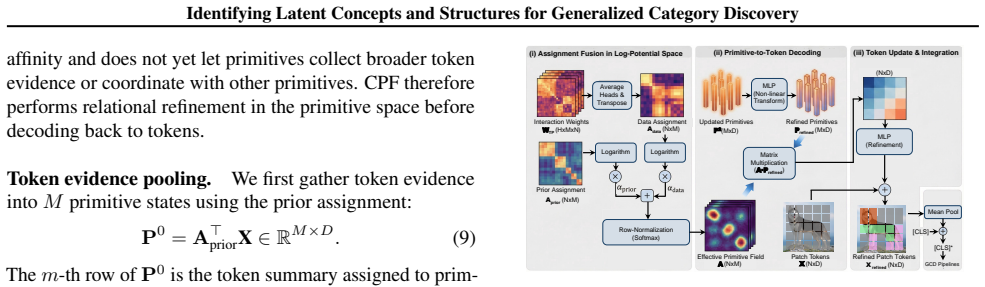
Compositional Primitive Fields (CPF), a spatial field mechanism inserted between backbone and head that rewrites patch tokens via low-rank primitive mixtures to explicitly model the spatial distribution of reusable visual primitives.
If this is right
- Novel categories emerge as new activation patterns over the shared primitive vocabulary without requiring a separate clustering stage.
- The module acts as a generic plug-and-play addition that raises performance across diverse existing GCD methods.
- Representation learning shifts from partitioning global embeddings to constructing explicit spatial layouts of primitives.
- Known and novel classes share the same finite primitive basis, enabling unsupervised emergence of new classes.
- Low-rank organization makes latent visual concepts identifiable in an otherwise high-rank token space.
Where Pith is reading between the lines
- If the learned primitives prove reusable across datasets, the approach could reduce the need for full retraining when encountering new visual domains.
- The explicit spatial modeling might extend naturally to tasks that require understanding object arrangements, such as scene graph prediction.
- Ablating the rank of the primitive mixtures on controlled synthetic data where categories are known to be non-compositional would test the boundary of the hypothesis.
- Similar low-rank decomposition ideas could be applied to other open-set problems like novel object detection or zero-shot segmentation.
Load-bearing premise
All categories, known or novel, can be expressed as compositions and spatial arrangements of a finite set of learnable visual primitives that capture reusable concepts.
What would settle it
Train the model on a standard GCD benchmark after removing the low-rank primitive mixture constraint; if novel-class discovery performance shows no consistent gain over baselines, the necessity of the compositional structure is falsified.
Figures



read the original abstract
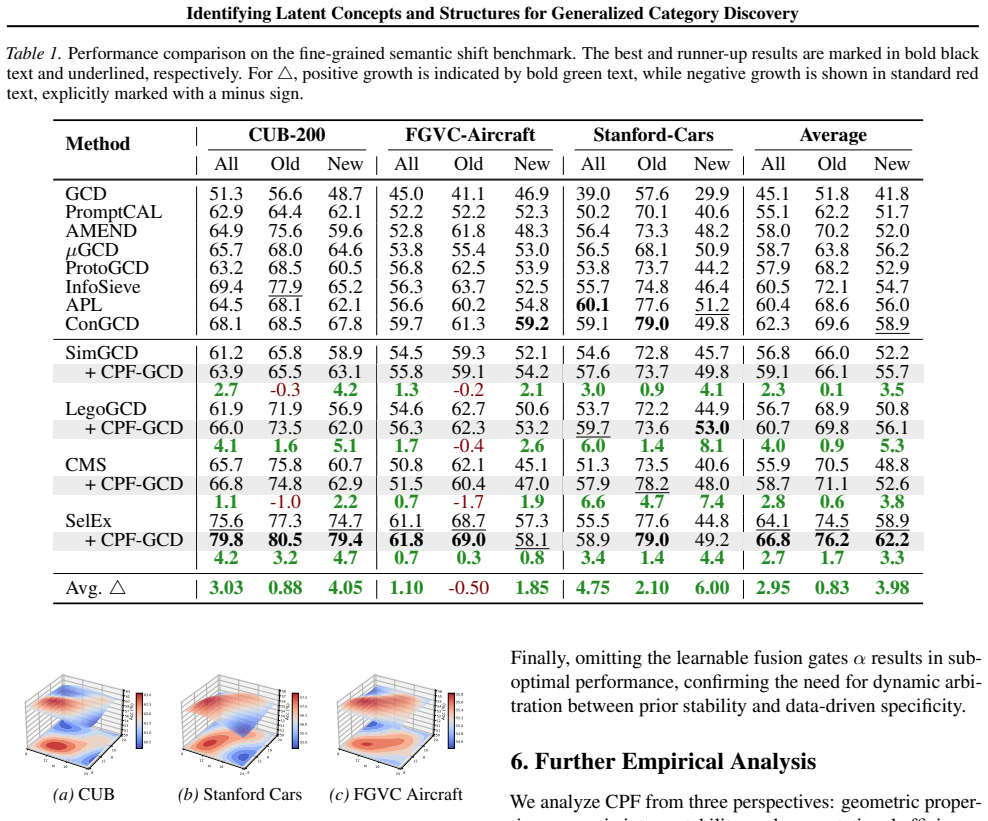
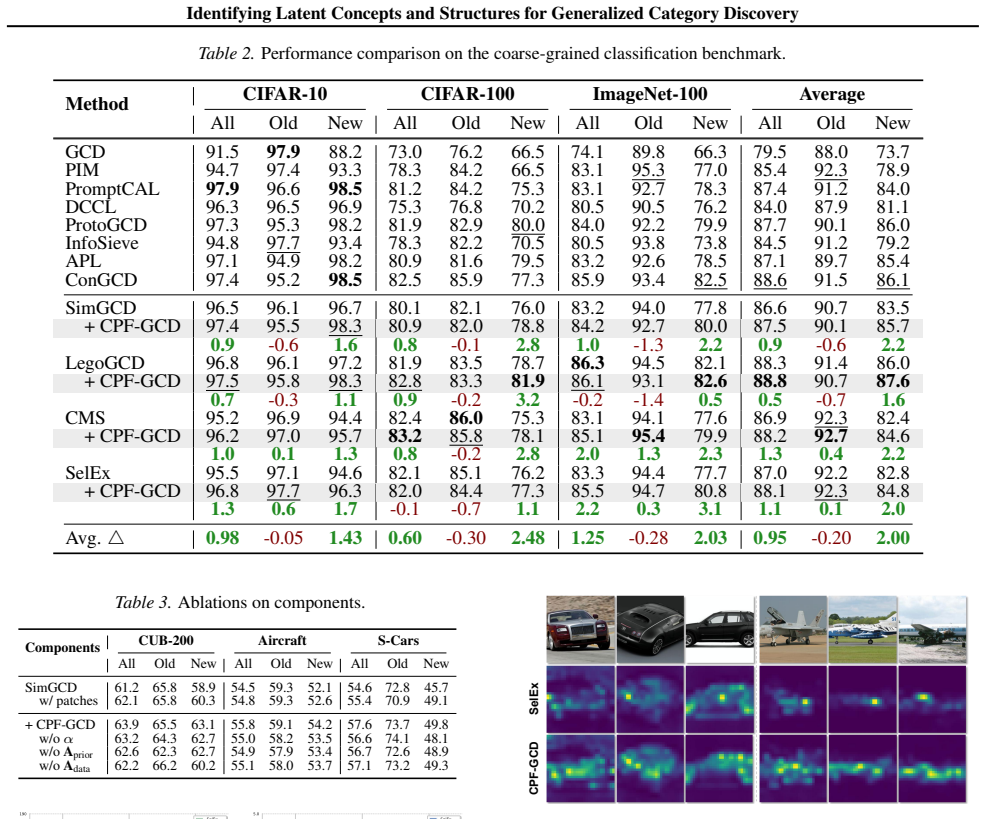
Generalized Category Discovery (GCD) aims to recognize known classes while autonomously discovering novel ones in open-world settings. However, current approaches primarily focus on designing clustering objectives, often overlooking a critical bottleneck: standard vision backbones yield high-rank, entangled token representations that are ill-suited for unsupervised discovery of latent concepts and structures. In this paper, we propose Compositional Primitive Fields (CPF-GCD), a novel representation learning framework that reshapes the feature space to make such latent structure identifiable by enforcing a low-rank compositional organization. Our core hypothesis is that all categories, whether known or novel, can be expressed as compositions and spatial arrangements of a finite set of learnable visual primitives that capture reusable concepts. CPF instantiates this geometric constraint via a spatial field mechanism. Inserted between the backbone and the head, it rewrites noisy patch tokens through low-rank primitive mixtures, effectively decomposing images into reusable atomic parts and their spatial layouts. By explicitly modeling the spatial distribution of primitives, CPF enables novel categories to emerge naturally as new activation patterns over a shared vocabulary. This shifts the focus of representation from merely partitioning global embeddings to constructing a structured and separable primitive field. Extensive experiments demonstrate that CPF serves as a generic, plug-and-play module that consistently boosts performance across diverse GCD baselines, validating that identifying and leveraging low-rank compositional structure is a crucial inductive bias for open-world recognition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Compositional Primitive Fields (CPF-GCD) for Generalized Category Discovery (GCD). It identifies high-rank entangled token representations from standard vision backbones as a bottleneck for discovering novel categories and introduces a plug-and-play spatial field mechanism inserted between backbone and head. This module rewrites patch tokens via low-rank primitive mixtures to enforce a compositional organization, based on the hypothesis that all categories (known and novel) are compositions and spatial arrangements of a finite set of learnable visual primitives. The mechanism is claimed to allow novel categories to emerge as new activation patterns over a shared vocabulary, shifting representation learning toward structured primitive fields. Experiments are reported to show consistent performance gains across diverse GCD baselines.
Significance. If the empirical gains hold and the compositional premise is validated, the work supplies a new geometric inductive bias for open-world recognition that moves beyond clustering objectives to explicit modeling of reusable atomic parts and layouts. This could improve identifiability of latent structures in GCD settings by leveraging shared primitives across known and novel classes.
major comments (2)
- [Abstract] Abstract: The central claim that the low-rank compositional constraint enables novel categories to emerge as new activation patterns rests on the untested premise that 'all categories, whether known or novel, can be expressed as compositions and spatial arrangements of a finite set of learnable visual primitives.' No derivation, sufficiency bound, or ablation testing this vocabulary coverage for novel classes is supplied, making the identifiability guarantee conditional on an assumption that may fail for subsets of novel data.
- [Abstract] Abstract / method description: The spatial field mechanism is presented as instantiating an 'externally imposed geometric prior' rather than a quantity derived from data or self-referential equations; without explicit equations showing how the low-rank mixtures are optimized or how they differ from standard low-rank approximations, it is unclear whether the rewriting step actually decomposes representations in the claimed manner or simply adds a regularizer.
minor comments (2)
- [Abstract] The abstract states that 'extensive experiments demonstrate' consistent boosts but supplies no quantitative results, dataset names, or baseline comparisons; these details should be summarized with effect sizes even in the abstract.
- [Abstract] Notation for the 'spatial field mechanism' and 'primitive mixtures' is introduced without defining symbols or relating them to standard attention or factorization operators, which reduces clarity for readers familiar with compositional models.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on the abstract and method description. We address each point below, clarifying the framing of our hypothesis and committing to revisions that improve transparency without overstating theoretical guarantees.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the low-rank compositional constraint enables novel categories to emerge as new activation patterns rests on the untested premise that 'all categories, whether known or novel, can be expressed as compositions and spatial arrangements of a finite set of learnable visual primitives.' No derivation, sufficiency bound, or ablation testing this vocabulary coverage for novel classes is supplied, making the identifiability guarantee conditional on an assumption that may fail for subsets of novel data.
Authors: The manuscript explicitly presents the statement as a 'core hypothesis' rather than a derived theorem or identifiability guarantee. We do not supply a formal sufficiency bound because the contribution centers on an empirical inductive bias whose value is demonstrated through consistent gains across GCD baselines. While direct ablations isolating vocabulary coverage for held-out novel classes are absent, the plug-and-play improvements on multiple datasets provide supporting evidence that the shared primitives are reusable in practice. We will revise the abstract to foreground the hypothetical framing, add a dedicated limitations paragraph, and include an experiment subsection visualizing learned primitives and their activation patterns on novel classes. revision: partial
-
Referee: [Abstract] Abstract / method description: The spatial field mechanism is presented as instantiating an 'externally imposed geometric prior' rather than a quantity derived from data or self-referential equations; without explicit equations showing how the low-rank mixtures are optimized or how they differ from standard low-rank approximations, it is unclear whether the rewriting step actually decomposes representations in the claimed manner or simply adds a regularizer.
Authors: The abstract is intentionally concise; the method section supplies the explicit formulation in which the low-rank primitive mixtures are optimized jointly with the GCD loss, rendering the fields data-driven. The spatial structure distinguishes the mechanism from generic low-rank factorization by tying each primitive to a learnable spatial field. We will revise the abstract to reference the end-to-end optimization and ensure the key equations are cross-referenced from the introduction, making the distinction from standard regularizers explicit. revision: yes
Circularity Check
No circularity; core hypothesis stated as explicit modeling assumption with no self-referential reduction.
full rationale
The paper's derivation begins with an explicit core hypothesis (all categories as compositions of a finite set of learnable primitives) presented as the foundational premise, then introduces CPF as a plug-and-play module to enforce the resulting low-rank constraint. No equations or steps reduce a claimed prediction or identifiability result back to fitted parameters or prior outputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, and the mechanism is described as an imposed inductive bias rather than a derived necessity. The central claim therefore remains an assumption plus an architectural choice, not a closed loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption All categories, whether known or novel, can be expressed as compositions and spatial arrangements of a finite set of learnable visual primitives that capture reusable concepts.
invented entities (2)
-
Compositional Primitive Fields (CPF)
no independent evidence
-
spatial field mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
ACM TKDD , @@volume=
A survey on explainable anomaly detection , author=. ACM TKDD , @@volume=. 2023 , publisher=
2023
-
[2]
IJCV , @@volume=
Generalized out-of-distribution detection: A survey , author=. IJCV , @@volume=. 2024 , publisher=
2024
-
[3]
2020 , @publisher=
Recent advances in open set recognition: A survey , author=. 2020 , @publisher=
2020
-
[4]
NeurIPS , @@volume=
No representation rules them all in category discovery , author=. NeurIPS , @@volume=
-
[5]
CVPR , @@pages=
Openmix: Reviving known knowledge for discovering novel visual categories in an open world , author=. CVPR , @@pages=
-
[6]
ECCV , @pages=
Class-incremental novel class discovery , author=. ECCV , @pages=. 2022 , @organization=
2022
-
[7]
CVPR , @pages=
Novel class discovery in semantic segmentation , author=. CVPR , @pages=
-
[8]
ICCV , @@@pages=
Learning to discover novel visual categories via deep transfer clustering , author=. ICCV , @@@pages=
-
[9]
IEEE TPAMI , @volume=
Autonovel: Automatically discovering and learning novel visual categories , author=. IEEE TPAMI , @volume=. 2021 , publisher=
2021
-
[10]
Generalized category discovery , author=
-
[11]
ICCV , @pages=
Learning semi-supervised gaussian mixture models for generalized category discovery , author=. ICCV , @pages=
-
[12]
CVPR , @pages=
Contrastive Mean-Shift Learning for Generalized Category Discovery , author=. CVPR , @pages=
-
[13]
ICCV , @pages=
Parametric information maximization for generalized category discovery , author=. ICCV , @pages=
-
[14]
ICLR , year=
SPTNet: An efficient alternative framework for generalized category discovery with spatial prompt tuning , author=. ICLR , year=
-
[15]
CVPR , @pages=
Solving the catastrophic forgetting problem in generalized category discovery , author=. CVPR , @pages=
-
[16]
CVPR , @pages=
On-the-fly category discovery , author=. CVPR , @pages=
-
[17]
CVPR , @@pages=
Neighborhood contrastive learning for novel class discovery , author=. CVPR , @@pages=
-
[18]
ICCV , @@pages=
A unified objective for novel class discovery , author=. ICCV , @@pages=
-
[19]
NeurIPS , @@volume=
Novel visual category discovery with dual ranking statistics and mutual knowledge distillation , author=. NeurIPS , @@volume=
-
[20]
International Conference on Learning Representations , @publisher =
Kaidi Cao and Maria Brbic and Jure Leskovec , title =. International Conference on Learning Representations , @publisher =
-
[21]
ICML , @pages=
A simple framework for contrastive learning of visual representations , author=. ICML , @pages=. 2020 , @organization=
2020
-
[22]
Junnan Li and Pan Zhou and Caiming Xiong and Steven C. H. Hoi , title =. ICLR , year =
-
[23]
NeurIPS , @volume=
Fixmatch: Simplifying semi-supervised learning with consistency and confidence , author=. NeurIPS , @volume=
-
[24]
NeurIPS , @volume=
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results , author=. NeurIPS , @volume=
-
[25]
NeurIPS , @volume=
Mixmatch: A holistic approach to semi-supervised learning , author=. NeurIPS , @volume=
-
[26]
CVPR , @volume=
Learning with constrained and unlabelled data , author=. CVPR , @volume=. 2005 , @organization=
2005
-
[27]
, title =
Basu, Sugato and Banerjee, Arindam and Mooney, Raymond J. , title =. ICML , @pages =. 2002 , @isbn =
2002
-
[28]
Proceedings of the national academy of sciences , @@volume=
Maps of random walks on complex networks reveal community structure , author=. Proceedings of the national academy of sciences , @@volume=. 2008 , @publisher=
2008
-
[29]
ICCV , @pages=
Emerging properties in self-supervised vision transformers , author=. ICCV , @pages=
-
[30]
IEEE TBD , @@volume=
Billion-scale similarity search with gpus , author=. IEEE TBD , @@volume=. 2019 , @publisher=
2019
-
[31]
The European Physical Journal Special Topics , @@volume=
The map equation , author=. The European Physical Journal Special Topics , @@volume=. 2009 , @publisher=
2009
-
[32]
5th Berkeley Symp
Classification and analysis of multivariate observations , author=. 5th Berkeley Symp. Math. Statist. Probability , @@pages=
-
[33]
IEEE TKDE , @volume=
A survey on deep semi-supervised learning , author=. IEEE TKDE , @volume=. 2022 , publisher=
2022
-
[34]
ACM computing surveys (csur) , @@volume=
Generalizing from a few examples: A survey on few-shot learning , author=. ACM computing surveys (csur) , @@volume=. 2020 , @publisher=
2020
-
[35]
CVPR , @pages=
On learning contrastive representations for learning with noisy labels , author=. CVPR , @pages=
-
[36]
IJCV , @pages=
Slimmable networks for contrastive self-supervised learning , author=. IJCV , @pages=. 2024 , publisher=
2024
-
[37]
CVPR , @pages=
T2vlad: global-local sequence alignment for text-video retrieval , author=. CVPR , @pages=
-
[38]
BMVC , @@pages =
Jiabo Huang and Shaogang Gong , title =. BMVC , @@pages =. 2022 , @url =
2022
-
[39]
Neural networks , @@volume=
On the momentum term in gradient descent learning algorithms , author=. Neural networks , @@volume=. 1999 , @publisher=
1999
-
[40]
IEEE TPAMI , year=
Knowledge distillation and student-teacher learning for visual intelligence: A review and new outlooks , author=. IEEE TPAMI , year=
-
[41]
2009 IEEE conference on computer vision and pattern recognition , @pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , @pages=. 2009 , organization=
2009
-
[42]
CVPRW , @pages=
3d object representations for fine-grained categorization , author=. CVPRW , @pages=
-
[43]
Fine-Grained Visual Classification of Aircraft
Fine-grained visual classification of aircraft , author=. arXiv preprint arXiv:1306.5151 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
2012 IEEE conference on computer vision and pattern recognition , @pages=
Cats and dogs , author=. 2012 IEEE conference on computer vision and pattern recognition , @pages=. 2012 , organization=
2012
-
[45]
CVPR , @pages=
The inaturalist species classification and detection dataset , author=. CVPR , @pages=
-
[46]
The Herbarium Challenge 2019 Dataset
The herbarium challenge 2019 dataset , author=. arXiv preprint arXiv:1906.05372 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[47]
2011 , publisher=
The caltech-ucsd birds-200-2011 dataset , author=. 2011 , publisher=
2011
-
[48]
2009 , publisher=
Learning multiple layers of features from tiny images , author=. 2009 , publisher=
2009
-
[49]
ICLR2022 , publisher =
Sagar Vaze and Kai Han and Andrea Vedaldi and Andrew Zisserman , title =. ICLR2022 , publisher =
-
[50]
CVPR , @pages=
Federated generalized category discovery , author=. CVPR , @pages=
-
[51]
NeurIPS , year=
Prototypical Hash Encoding for On-the-Fly Fine-Grained Category Discovery , author=. NeurIPS , year=
-
[52]
CVPR , @pages=
Novel class discovery for ultra-fine-grained visual categorization , author=. CVPR , @pages=
-
[53]
arXiv preprint arXiv:2305.10420 , year=
Clip-gcd: Simple language guided generalized category discovery , author=. arXiv preprint arXiv:2305.10420 , year=
-
[54]
CVPR , year=
GET: Unlocking the Multi-modal Potential of CLIP for Generalized Category Discovery , author=. CVPR , year=
-
[55]
arXiv preprint arXiv:2409.11624 , year=
Multimodal Generalized Category Discovery , author=. arXiv preprint arXiv:2409.11624 , year=
-
[56]
ECCV , @pages=
Textual knowledge matters: Cross-modality co-teaching for generalized visual class discovery , author=. ECCV , @pages=. 2024 , @organization=
2024
-
[57]
arXiv preprint arXiv:2208.01898 , year=
Xcon: Learning with experts for fine-grained category discovery , author=. arXiv preprint arXiv:2208.01898 , year=
-
[58]
Advances in Neural Information Processing Systems , volume=
Learn to categorize or categorize to learn? self-coding for generalized category discovery , author=. Advances in Neural Information Processing Systems , volume=
-
[59]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Protogcd: Unified and unbiased prototype learning for generalized category discovery , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[60]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Dissecting generalized category discovery: Multiplex consensus under self-deconstruction , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[61]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Adaptive Part Learning for Fine-Grained Generalized Category Discovery: A Plug-and-Play Enhancement , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[62]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Hyperbolic category discovery , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[63]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Building a bird recognition app and large scale dataset with citizen scientists: The fine print in fine-grained dataset collection , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[64]
Naval research logistics quarterly , volume=
The Hungarian method for the assignment problem , author=. Naval research logistics quarterly , volume=. 1955 , publisher=
1955
-
[65]
arXiv preprint arXiv:2507.04051 , year=
Generate, Refine, and Encode: Leveraging Synthesized Novel Samples for On-the-Fly Fine-Grained Category Discovery , author=. arXiv preprint arXiv:2507.04051 , year=
-
[66]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Generalized category discovery , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[67]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Parametric classification for generalized category discovery: A baseline study , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[68]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Learning semi-supervised gaussian mixture models for generalized category discovery , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[69]
Advances in Neural Information Processing Systems , volume=
Savi++: Towards end-to-end object-centric learning from real-world videos , author=. Advances in Neural Information Processing Systems , volume=
-
[70]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Federated generalized category discovery , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[71]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Active generalized category discovery , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[72]
Advances in neural information processing systems , volume=
Object-centric learning with slot attention , author=. Advances in neural information processing systems , volume=
-
[73]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Shepherding slots to objects: Towards stable and robust object-centric learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[74]
Advances in Neural Information Processing Systems , volume=
Self-supervised object-centric learning for videos , author=. Advances in Neural Information Processing Systems , volume=
-
[75]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Prompt-Driven Dynamic Object-Centric Learning for Single Domain Generalization , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[76]
arXiv preprint arXiv:2209.14860 , year=
Bridging the gap to real-world object-centric learning , author=. arXiv preprint arXiv:2209.14860 , year=
-
[77]
2012 IEEE conference on computer vision and pattern recognition , pages=
Cats and dogs , author=. 2012 IEEE conference on computer vision and pattern recognition , pages=. 2012 , organization=
2012
-
[78]
2009 IEEE conference on computer vision and pattern recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
2009
-
[79]
arXiv preprint arXiv:1811.12231 , year=
ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness , author=. arXiv preprint arXiv:1811.12231 , year=
-
[80]
2021 , publisher=
Open-set recognition: A good closed-set classifier is all you need? , author=. 2021 , publisher=
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.