Fast LLM-Based Semantic Filtering: From a Unified Framework to an Adaptive Two-Phase Method
Pith reviewed 2026-06-27 19:03 UTC · model grok-4.3
The pith
Adaptive two-phase cascade of clustering then confidence-trained proxy cuts LLM calls 1.6-2.0x at 90% accuracy target
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
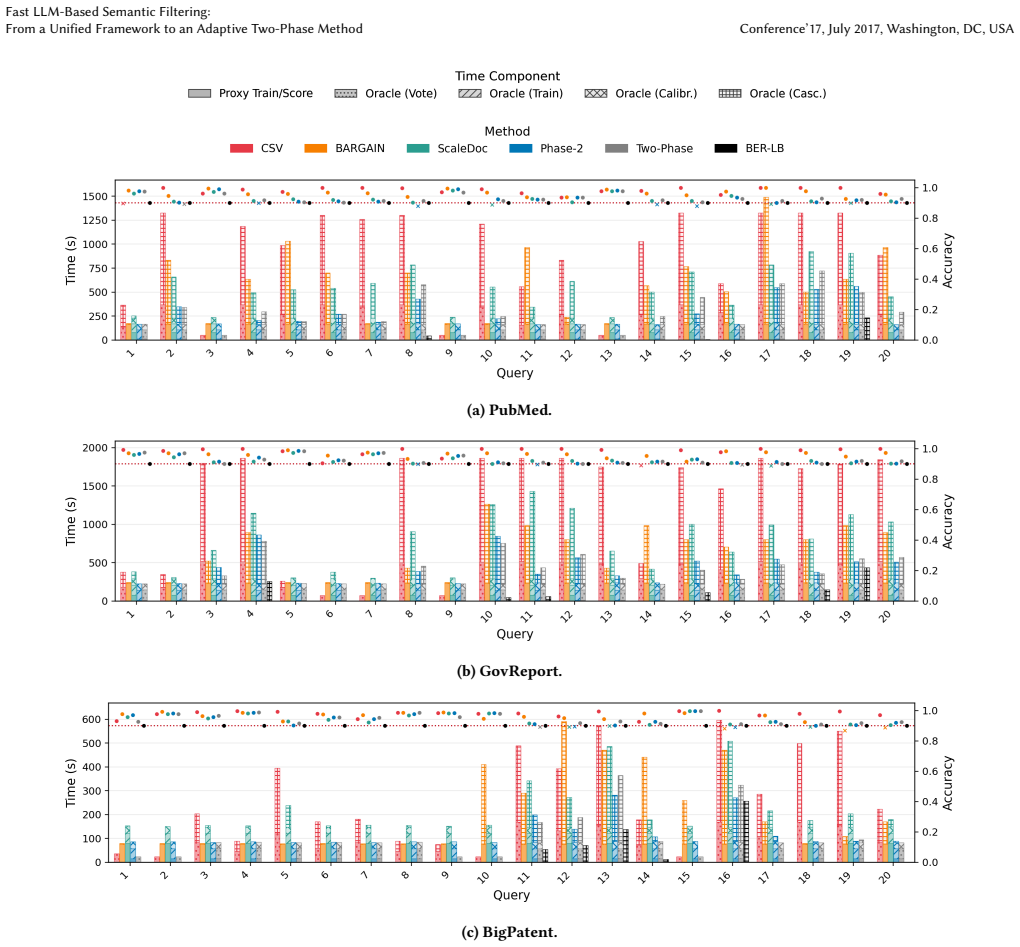
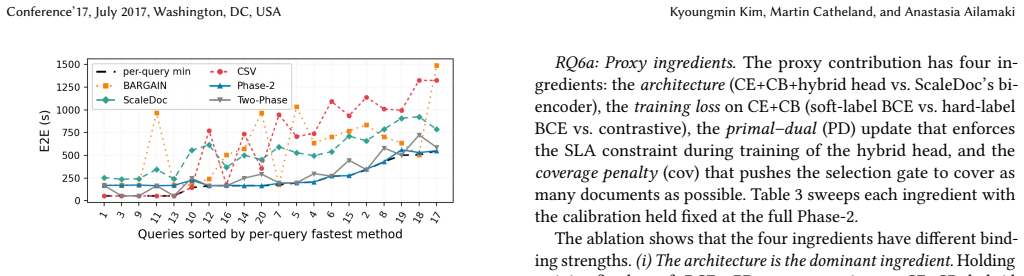
The central claim is that composing clustering and an online proxy in two phases, training the proxy on the oracle's continuous per-document confidence scores as soft labels, replacing bi-encoders with hybrid token-aware models, and calibrating safety margins only on sparse samples produces a cascade that meets a 90% accuracy target on 95% of queries while using 1.6-2.0x fewer oracle calls than the best prior method on each of three 10K-document corpora. The oracle confidence scores are used for the first time as a query difficulty compass, a lower bound on minimum oracle calls any proxy-based cascade can achieve, and the proxy's soft training label.
What carries the argument
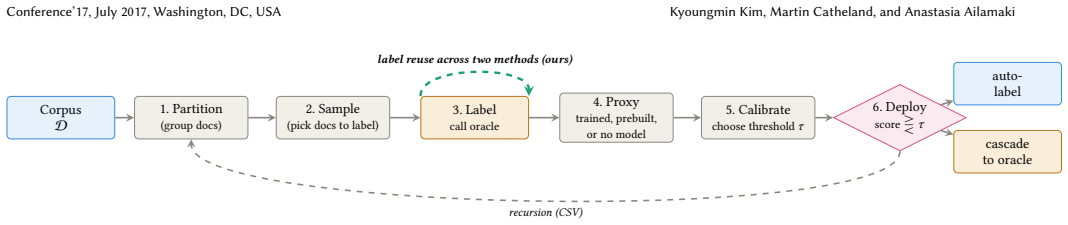
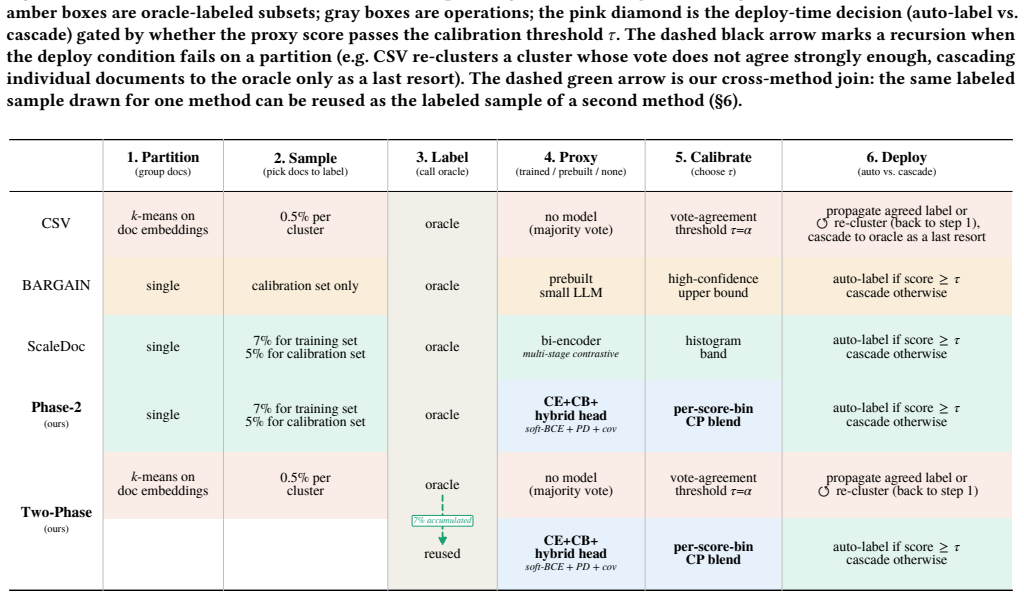
The adaptive two-phase cascade that applies model-free clustering first and invokes the online proxy only when clustering alone cannot guarantee the accuracy target, with oracle calls shared across phases and the proxy trained on soft labels from the oracle's per-document confidence.
Load-bearing premise
The oracle LLM's per-document confidence scores supply unbiased soft labels for proxy training and a reliable lower bound on minimum oracle calls even after the adaptive phase switch.
What would settle it
Measuring whether accuracy falls below the target on queries where the initial clustering step fails to separate positive and negative documents would show if the subsequent proxy phase preserves the guarantee without extra oracle cost.
Figures





read the original abstract
Evaluating a natural-language yes/no predicate over a document corpus under an accuracy target - the semantic filter - is a cornerstone of LLM-based data processing. Calling the LLM on every document (the oracle) is prohibitive, so cascades pair the oracle with a fast proxy. As deployed today, they leave four limitations on the table. (1) Each cascade family - model-free clustering, prebuilt small-LLM proxies, online-trained proxies - commits to a single representation and pipeline, and wins on only a narrow query regime. (2) The strongest online proxy invests in a custom training scheme on a bi-encoder over dense embeddings, missing the token-level evidence richer predicates require. (3) The proxy is trained against binary yes/no labels, wasting the LLM's per-document confidence at the boundary documents it most needs to learn. (4) Existing calibrations add a uniform safety margin, conflating genuine proxy uncertainty with small-sample noise and inflating cascade cost. We address these by (1) composing families adaptively - model-free clustering first, online proxy only when needed, with oracle calls shared across phases; (2) replacing the cosine bi-encoder with a hybrid of off-the-shelf token-aware models; (3) training the proxy with the oracle's per-document confidence as a soft label; and (4) a calibration that adds the safety margin only where the labeled sample is sparse. We are also the first to use the oracle's per-document confidence for three purposes: a query-level difficulty compass, a lower bound on the minimum oracle calls any proxy-based cascade can make, and the proxy's soft training label. At a 90% accuracy target on three 10K-document corpora, our methods are 1.6-2.0x faster than the best prior method per corpus and meet the target on 95% of queries; the BER-derived lower bound indicates a further ~4-20x of headroom for future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a unified framework for semantic filtering (evaluating natural-language yes/no predicates over document corpora under an accuracy target) and proposes an adaptive two-phase method that begins with model-free clustering, invokes an online-trained proxy only when needed, and shares oracle LLM calls across phases. It replaces cosine bi-encoder proxies with hybrid token-aware models, trains the proxy using the oracle's per-document confidence as soft labels, and introduces a calibration that applies safety margins only on sparse samples. The oracle confidence is also used as a query difficulty compass and as the basis for a BER lower bound on minimum oracle calls. On three 10K-document corpora at a 90% accuracy target the method achieves 1.6-2.0x speedups over the best prior per-corpus baseline while meeting the target on 95% of queries, with the BER bound indicating 4-20x additional headroom.
Significance. If the empirical speedups, accuracy rates, and the claim that the adaptive composition preserves the BER lower bound all hold, the work would meaningfully improve the practicality of LLM-based semantic queries in database systems by moving beyond single-family cascades and by extracting more signal from oracle confidence scores. The lower-bound construction, if rigorously established, would also supply a useful benchmark for future proxy-cascade research.
major comments (2)
- [Abstract and §3] Abstract and §3 (method): the claim that the adaptive two-phase construction (clustering first, then online proxy) inherits the BER lower bound on oracle calls is not demonstrated. No argument or proof sketch shows that the composition avoids new failure modes precisely on queries where the initial clustering sample is uninformative; if such queries exist, both the reported 1.6-2.0x speedup and the 4-20x headroom can be invalidated while the nominal accuracy target is still met on the remaining queries.
- [§5] §5 (experiments): the headline speedups at 90% accuracy rest on the oracle confidence scores serving as unbiased soft labels for proxy training; the manuscript must supply an explicit check (e.g., calibration plots or bias metrics on held-out oracle scores) that this assumption holds across the three corpora, because any systematic bias would directly undermine both the proxy quality and the claimed speedups.
minor comments (2)
- [Abstract] Abstract: the experimental claims (speedups, accuracy rates, 95% query coverage) are stated without any mention of dataset characteristics, baseline implementations, or statistical significance tests; these details belong in the abstract or a dedicated results paragraph.
- [Abstract] Notation: the acronym BER is introduced without an explicit expansion or equation reference on first use.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): the claim that the adaptive two-phase construction (clustering first, then online proxy) inherits the BER lower bound on oracle calls is not demonstrated. No argument or proof sketch shows that the composition avoids new failure modes precisely on queries where the initial clustering sample is uninformative; if such queries exist, both the reported 1.6-2.0x speedup and the 4-20x headroom can be invalidated while the nominal accuracy target is still met on the remaining queries.
Authors: We agree that the manuscript does not contain an explicit argument or proof sketch establishing that the adaptive two-phase construction inherits the BER lower bound without new failure modes on queries where the initial clustering sample is uninformative. In the revision we will add a proof sketch in §3 showing that the composition preserves the bound: the proxy phase activates only after clustering fails to meet the accuracy target on its sample, oracle calls are shared, and the BER construction applies directly to the combined labeled set. revision: yes
-
Referee: [§5] §5 (experiments): the headline speedups at 90% accuracy rest on the oracle confidence scores serving as unbiased soft labels for proxy training; the manuscript must supply an explicit check (e.g., calibration plots or bias metrics on held-out oracle scores) that this assumption holds across the three corpora, because any systematic bias would directly undermine both the proxy quality and the claimed speedups.
Authors: We agree that an explicit check is required. The revision will add calibration plots and bias metrics (e.g., expected calibration error and mean absolute deviation) on held-out oracle confidence scores for each of the three corpora to verify that the soft-label assumption holds. revision: yes
Circularity Check
No significant circularity; empirical comparisons only
full rationale
The paper describes an adaptive two-phase semantic filtering method that composes model-free clustering with online proxy training, using oracle per-document confidence scores for training labels, difficulty assessment, and a claimed lower bound on oracle calls. All performance claims (1.6-2.0x speedups at 90% accuracy) are presented as direct empirical measurements against prior cascades on fixed 10K-document corpora, with no equations, derivations, or fitted parameters that reduce the reported quantities to inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in the provided text to justify core results. The method is self-contained via experimental validation rather than any definitional or predictive reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Angelopoulos and Stephen Bates
Anastasios N. Angelopoulos and Stephen Bates. 2021. A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification.CoRR abs/2107.07511 (2021). arXiv:2107.07511 https://arxiv.org/abs/2107.07511
Pith/arXiv arXiv 2021
-
[2]
Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen, Mir Rosenberg, Xia Song, Alina Stoica, Saurabh Tiwary, and Tong Wang. 2016. MS MARCO: A Human Generated Machine Reading Comprehension Dataset.CoRR abs/1611.09268 (2016)
Pith/arXiv arXiv 2016
-
[3]
Stephen Bates, Anastasios Angelopoulos, Lihua Lei, Jitendra Malik, and Michael I. Jordan. 2021. Distribution-free, Risk-controlling Prediction Sets.J. ACM68, 6 (2021), 43:1–43:34. doi:10.1145/3478535
-
[4]
Bertsekas
Dimitri P. Bertsekas. 1999.Nonlinear Programming(2nd ed.). Athena Scientific, Belmont, MA
1999
-
[5]
Tolga Bolukbasi, Joseph Wang, Ofer Dekel, and Venkatesh Saligrama. 2017. Adap- tive Neural Networks for Efficient Inference. InProceedings of the 34th Inter- national Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017 (Proceedings of Machine Learning Research). PMLR, 527–536. http://proceedings.mlr.press/v70/bolukbasi17a.html
2017
-
[6]
2004.Convex Optimization
Stephen Boyd and Lieven Vandenberghe. 2004.Convex Optimization. Cambridge University Press
2004
-
[7]
Brown, T
Lawrence D. Brown, T. Tony Cai, and Anirban DasGupta. 2001. Interval Estima- tion for a Binomial Proportion.Statist. Sci.16, 2 (2001), 101–133
2001
-
[8]
Lingjiao Chen, Matei Zaharia, and James Zou. 2024. FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance.Trans. Mach. Learn. Res.2024 (2024). https://openreview.net/forum?id=cSimKw5p6R
2024
-
[9]
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey E. Hinton. 2020. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the 37th International Conference on Machine Learning (ICML)
2020
-
[10]
Yeounoh Chung, Rushabh Desai, Jian He, Yu Xiao, Thibaud Hottelier, Yves- Laurent Kom Samo, Pushkar Kadilkar, Xianshun Chen, Sam Idicula, Fatma Özcan, Alon Halevy, and Yannis Papakonstantinou. 2026. 100x Cost & Latency Reduction: Performance Analysis of AI Query Approximation using Lightweight Proxy Models.CoRRabs/2603.15970 (2026). arXiv:2603.15970 https:...
Pith/arXiv arXiv 2026
-
[11]
C. J. Clopper and E. S. Pearson. 1934. The Use of Confidence or Fiducial Limits Illustrated in the Case of the Binomial.Biometrika26, 4 (1934), 404–413. doi:10. 2307/2331986
1934
-
[12]
Gupta, Serena Wang, Taman Narayan, Seungil You, and Karthik Sridharan
Andrew Cotter, Heinrich Jiang, Maya R. Gupta, Serena Wang, Taman Narayan, Seungil You, and Karthik Sridharan. 2019. Optimization with Non-Differentiable Constraints with Applications to Fairness, Recall, Churn, and Other Goals.Journal of Machine Learning Research20 (2019), 1–59
2019
-
[13]
Voorhees
Nick Craswell, Bhaskar Mitra, Emine Yilmaz, Daniel Campos, and Ellen M. Voorhees. 2020. Overview of the TREC 2019 Deep Learning Track. InThe Twenty- Eighth Text REtrieval Conference (TREC) Proceedings
2020
-
[14]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Associa- tion for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, ...
-
[15]
1990.Introduction to Statistical Pattern Recognition(2 ed.)
Keinosuke Fukunaga. 1990.Introduction to Statistical Pattern Recognition(2 ed.). Academic Press. doi:10.1016/C2009-0-27872-X
-
[16]
Tianyu Gao, Xingcheng Yao, and Danqi Chen. 2021. SimCSE: Simple Contrastive Learning of Sentence Embeddings. InProceedings of the 2021 Conference on Em- pirical Methods in Natural Language Processing (EMNLP). Conference’17, July 2017, Washington, DC, USA Kyoungmin Kim, Martin Catheland, and Anastasia Ailamaki
2021
-
[17]
Yonatan Geifman and Ran El-Yaniv. 2017. Selective Classification for Deep Neural Networks. InAdvances in Neural Information Processing Systems (NeurIPS) 30. arXiv:1705.08500 https://proceedings.neurips.cc/paper_files/paper/2017/hash/ 4a8423d5e91fda00bb7e46540e2b0cf1-Abstract.html
Pith/arXiv arXiv 2017
-
[18]
Isaac Gibbs and Emmanuel J. Candès. 2021. Adaptive Conformal Inference Under Distribution Shift. InAdvances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual. 1660–1672. https://proceedings.neurips.cc/ paper/2021/hash/0d441de75945e5acbc865406fc9a2559-Abs...
2021
-
[19]
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the Knowledge in a Neural Network.CoRRabs/1503.02531 (2015). https://arxiv.org/abs/1503.02531
Pith/arXiv arXiv 2015
- [20]
-
[21]
Daniel Kang, Edward Gan, Peter Bailis, Tatsunori Hashimoto, and Matei Zaharia
-
[22]
InProceedings of the VLDB Endowment, Vol
Approximate Selection with Guarantees using Proxies. InProceedings of the VLDB Endowment, Vol. 13. 1990–2003. doi:10.14778/3407790.3407811
-
[23]
Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen tau Yih. 2020. Dense Passage Retrieval for Open- Domain Question Answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)
2020
-
[24]
Omar Khattab and Matei Zaharia. 2020. ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, SIGIR 2020, Virtual Event, China, July 25-30, 2020. ACM, 39–48. doi:10. 1145/3397271.3401075
arXiv 2020
-
[25]
Ferdi Kossmann, Ziniu Wu, Alex Turk, Nesime Tatbul, Lei Cao, and Samuel Madden. 2026. KEN: An Execution Engine for Unstructured Database Systems. Proc. VLDB Endow.19, 5 (2026), 902–916. doi:10.14778/3796195.3796204
-
[26]
Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. 2025. NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net. https://openreview.net/forum?id=lgsyLSsDRe
2025
-
[27]
2021.Pretrained Transformers for Text Ranking: BERT and Beyond
Jimmy Lin, Rodrigo Nogueira, and Andrew Yates. 2021.Pretrained Transformers for Text Ranking: BERT and Beyond. Morgan & Claypool Publishers
2021
-
[28]
Chunwei Liu et al . 2024. Palimpzest: Optimizing AI-Powered Analytics with Semantic Operators. InConference on Innovative Data Systems Research (CIDR)
2024
-
[29]
Shichen Liu, Fei Xiao, Wenwu Ou, and Luo Si. 2017. Cascade Ranking for Opera- tional E-commerce Search. InProceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, August 13 - 17, 2017. ACM, 1557–1565. doi:10.1145/3097983.3098011
-
[30]
Yao Lu, Aakanksha Chowdhery, Srikanth Kandula, and Surajit Chaudhuri. 2018. Accelerating Machine Learning Inference with Probabilistic Predicates. InPro- ceedings of the 2018 International Conference on Management of Data, SIG- MOD Conference 2018, Houston, TX, USA, June 10-15, 2018. ACM, 1493–1508. doi:10.1145/3183713.3183751
-
[31]
Qiuyang Mang, Yufan Xiang, Hangrui Zhou, Runyuan He, Jiaxiang Yu, Hanchen Li, Aditya Parameswaran, and Alvin Cheung. 2026. PLOP: Cost-Based Placement of Semantic Operators in Hybrid Query Plans.CoRRabs/2604.09944 (2026). arXiv:2604.09944 https://arxiv.org/abs/2604.09944
Pith/arXiv arXiv 2026
-
[32]
Niklas Muennighoff, Nouamane Tazi, Loïc Magne, and Nils Reimers. 2023. MTEB: Massive Text Embedding Benchmark. InProceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics (EACL)
2023
-
[33]
Rodrigo Nogueira and Kyunghyun Cho. 2019. Passage Re-ranking with BERT. CoRRabs/1901.04085 (2019). arXiv:1901.04085 http://arxiv.org/abs/1901.04085
Pith/arXiv arXiv 2019
-
[34]
Northcutt, Lu Jiang, and Isaac L
Curtis G. Northcutt, Lu Jiang, and Isaac L. Chuang. 2021. Confident Learning: Estimating Uncertainty in Dataset Labels.J. Artif. Intell. Res.70 (2021), 1373–1411. doi:10.1613/JAIR.1.12125
-
[35]
Liana Patel et al . 2024. LOTUS: Enabling Semantic Queries with LLMs over Tables. InProceedings of the VLDB Endowment
2024
-
[36]
Gabriel Pereyra, George Tucker, Jan Chorowski, Łukasz Kaiser, and Geoffrey E. Hinton. 2017. Regularizing Neural Networks by Penalizing Confident Output Distributions. InWorkshop Track of the 5th International Conference on Learning Representations (ICLR)
2017
-
[37]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP)
2019
-
[38]
Keshav Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, and Matei Zaharia. 2022. ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT)
2022
-
[39]
Shreya Shankar, Tristan Chambers, Tarak Shah, Aditya G. Parameswaran, and Eugene Wu. 2025. DocETL: Agentic Query Rewriting and Evaluation for Complex Document Processing.Proc. VLDB Endow.18 (2025). arXiv:2410.12189 doi:10. 14778/3746405.3746426
arXiv 2025
-
[40]
Panagiotis Sioulas, Viktor Sanca, Ioannis Mytilinis, and Anastasia Ailamaki. 2021. Accelerating Complex Analytics using Speculation. InConference on Innova- tive Data Systems Research (CIDR). https://www.cidrdb.org/cidr2021/papers/ cidr2021_paper03.pdf
2021
-
[41]
Llama Team. 2024. The Llama 3 Herd of Models.CoRRabs/2407.21783 (2024). arXiv:2407.21783 doi:10.48550/ARXIV.2407.21783
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[42]
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. 2021. BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models. InProceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks
2021
-
[43]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lam- ple. 2023. LLaMA: Open and Efficient Foundation Language Models.CoRR abs/2302.13971 (2023)
Pith/arXiv arXiv 2023
-
[44]
2005.Algorithmic Learning in a Random World
Vladimir Vovk, Alex Gammerman, and Glenn Shafer. 2005.Algorithmic Learning in a Random World. Springer. doi:10.1007/b106715
-
[45]
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. 2022. Text Embeddings by Weakly-Supervised Contrastive Pre-training.CoRRabs/2212.03533 (2022)
Pith/arXiv arXiv 2022
-
[46]
Xiang Wei, Xingyu Cui, Ning Cheng, Xiaobin Wang, Xin Zhang, Shen Huang, Pengjun Xie, Jinan Xu, Yufeng Chen, Meishan Zhang, Yong Jiang, and Wenjuan Han. 2023. Zero-Shot Information Extraction via Chatting with ChatGPT.CoRR abs/2302.10205 (2023). arXiv:2302.10205 doi:10.48550/ARXIV.2302.10205
-
[47]
Edwin B. Wilson. 1927. Probable Inference, the Law of Succession, and Statistical Inference.J. Amer. Statist. Assoc.22, 158 (1927), 209–212
1927
-
[48]
Margaux Zaffran, Olivier Féron, Yannig Goude, Julie Josse, and Aymeric Dieuleveut. 2022. Adaptive Conformal Predictions for Time Series. InInter- national Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA (Proceedings of Machine Learning Research). PMLR, 25834–25866. https://proceedings.mlr.press/v162/zaffran22a.html
2022
-
[49]
Sepanta Zeighami, Shreya Shankar, and Aditya Parameswaran. 2025. BAR- GAIN: Budget-Aware Risk-Adaptive Guarantees for Accuracy-Improved LLM Cascades over Documents.Proceedings of the ACM SIGMOD International Con- ference on Management of Data(2025). https://arxiv.org/abs/2509.02896 Preprint arXiv:2509.02896
arXiv 2025
-
[50]
Hengrui Zhang, Yulong Hui, Yihao Liu, and Huanchen Zhang. 2025. Scale- Doc: Scaling LLM-based Predicates over Large Document Collections.CoRR abs/2509.12610 (2025). arXiv:2509.12610 doi:10.48550/ARXIV.2509.12610
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.12610 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.