VLA-FAIL: Efficient Task Failure Detection for Finetuned Vision-Language-Action Models
Pith reviewed 2026-06-26 14:55 UTC · model grok-4.3
The pith
VLA-FAIL combines last-layer feature deviations with action chunk consistency to detect failures in finetuned vision-language-action models without any failure examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
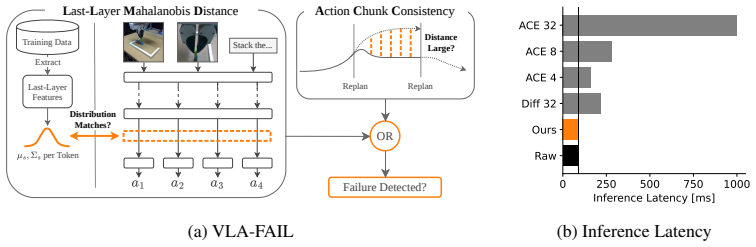
VLA-FAIL detects task failures by running last-layer Mahalanobis distance on token features to identify distribution shifts and action chunk consistency on temporally overlapping plans to identify planning breakdowns. Their combination yields reliable early detection across tasks while adding minimal compute and avoiding any need for failure rollouts or repeated action sampling.
What carries the argument
The joint use of last-layer Mahalanobis distance on token features and consistency checks between consecutive action chunks under receding-horizon control.
If this is right
- Failure detection becomes feasible at runtime for any finetuned VLA without collecting negative examples.
- Detection latency can be traded against precision using the AUCPDT metric without needing to tune thresholds in advance.
- The method applies across manipulation tasks that use receding-horizon action chunking.
- Compute cost stays low enough for on-robot deployment compared with sampling-based alternatives.
Where Pith is reading between the lines
- The same two signals could be tested on other sequence predictors that generate overlapping output chunks.
- Calibration of the Mahalanobis covariance on a small held-out set might further reduce false positives without retraining the VLA.
- Integrating the consistency check directly into the policy's planning loop could allow the model to replan automatically on detection.
Load-bearing premise
Token-wise deviations from training features and inconsistencies between action chunks are sufficient indicators of actual task failure in out-of-distribution states.
What would settle it
A recorded rollout in which the VLA visibly fails at its assigned task yet both last-layer Mahalanobis distance and action chunk consistency remain below their detection thresholds throughout.
Figures





read the original abstract
Vision-language-action models (VLAs) achieve state-of-the-art performance on many robotic manipulation tasks, yet they can still behave unpredictably in out-of-distribution scenarios. Runtime failure detection is therefore essential for the safe real-world deployment of VLAs. However, existing task failure detectors require computationally expensive action sampling, are based on architectural assumptions that limit their applicability to VLAs, or need access to failure rollouts. We propose VLA-FAIL, a lightweight and broadly applicable failure detection framework for VLAs that combines two novel failure detectors with minimal overhead, without requiring failure data. The first, last-layer Mahalanobis distance (LLMD), detects out-of-distribution states by measuring token-wise deviations in last-layer features relative to the training data. The second, action chunk consistency (ACC), exploits the temporal overlap induced by receding-horizon control and detects failures when consecutive action chunks become inconsistent. To capture the trade-off between detection accuracy and detection latency, we introduce AUCPDT, a threshold-independent metric that jointly evaluates precision, recall, and detection time. Through extensive real-world and simulation experiments, we demonstrate that LLMD and ACC capture complementary failure modes whose combination enables reliable and early failure detection across diverse tasks, frequently outperforming significantly more expensive baseline methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
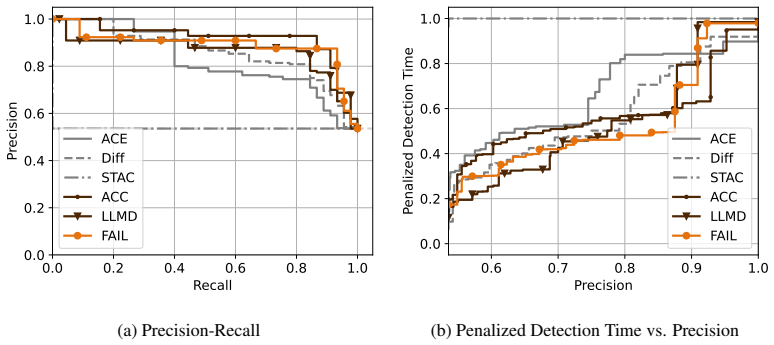
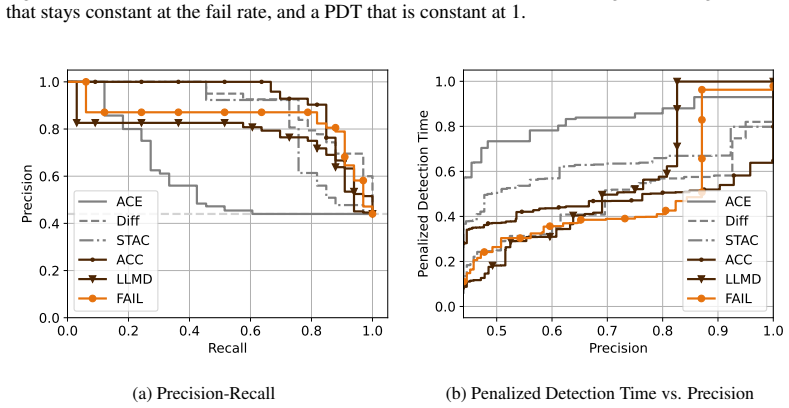
Summary. The manuscript proposes VLA-FAIL, a lightweight runtime failure detection framework for finetuned vision-language-action (VLA) models. It introduces two detectors that require no failure rollouts: last-layer Mahalanobis distance (LLMD), which measures token-wise deviations of last-layer features from a Gaussian fitted on training data, and action chunk consistency (ACC), which flags failures via inconsistencies between overlapping action chunks produced by receding-horizon control. The combination is claimed to capture complementary failure modes. The paper also defines AUCPDT, a threshold-independent metric that integrates precision, recall, and detection latency, and reports that the method outperforms more expensive baselines across diverse simulation and real-world tasks.
Significance. If the central experimental claims hold, the work supplies a practical, low-overhead safety layer for VLAs that avoids the need for failure data collection, a notable practical advantage. The AUCPDT metric is a useful contribution for comparing detectors on the accuracy-latency trade-off. The explicit complementarity argument between feature-based and temporal-consistency detectors, if substantiated, would be a clear advance over single-heuristic approaches.
major comments (3)
- [§3.1] §3.1 (LLMD definition): The detector assumes last-layer activations of successful trajectories are adequately modeled by a single multivariate Gaussian whose covariance can be reliably estimated from training tokens. No validation of this modeling choice (e.g., QQ-plots, covariance conditioning, or comparison to kernel density or mixture models) is provided, yet the central claim that LLMD reliably detects OOD states rests on it. High feature dimensionality or LoRA-style finetuning that leaves the final projection largely unchanged could invalidate the assumption.
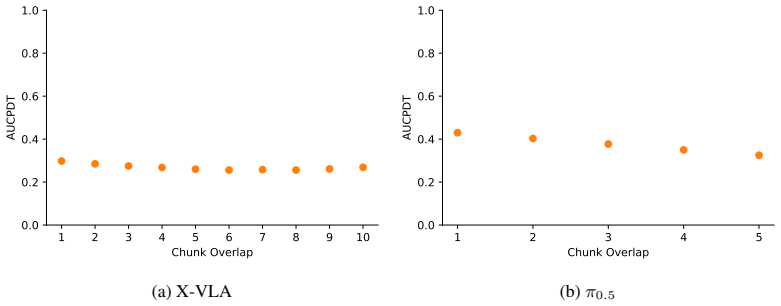
- [§3.2] §3.2 (ACC definition and §4 experiments): ACC relies on measurable inconsistency between consecutive overlapping action chunks indicating failure. The manuscript supplies no analysis or ablation on policy stochasticity, chunk length, or the choice of inconsistency metric (L2 vs. cosine). These parameters directly affect whether ACC fires on the claimed failure modes; without such analysis the claim that ACC and LLMD are jointly sufficient for reliable detection across arbitrary OOD states remains unsupported.
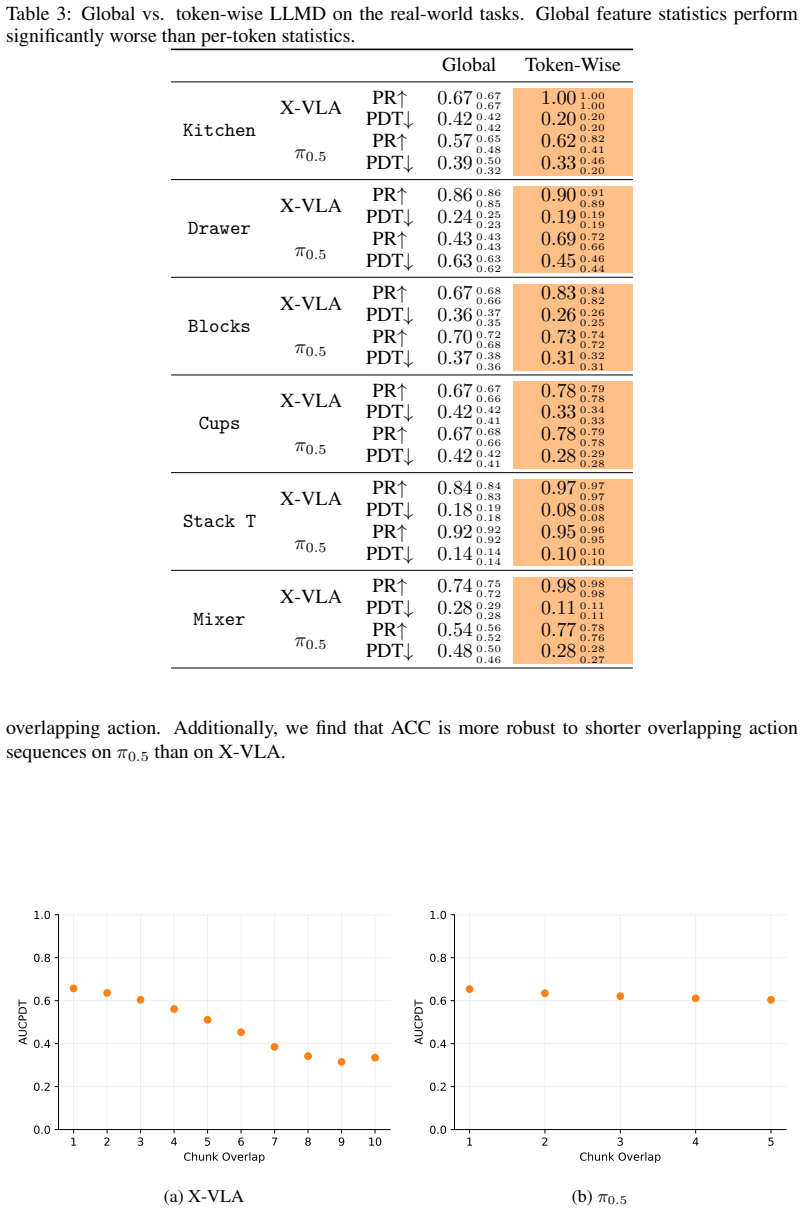
- [§4] §4 (experimental results and Table 2/3): The abstract and results assert that the LLMD+ACC combination “frequently outperforming significantly more expensive baseline methods” across diverse tasks. However, the paper does not demonstrate that the chosen baselines also operate without failure rollouts or that the reported AUCPDT gains are robust to post-hoc threshold selection. This comparison is load-bearing for the superiority claim.
minor comments (3)
- [§3.1] Notation for the Mahalanobis distance in §3.1 is introduced without an explicit equation number; adding Eq. (X) would improve traceability.
- [Figures] Figure captions for the real-world experiment plots should explicitly state the number of trials per task and whether error bars reflect standard deviation or standard error.
- [Related Work] The related-work section omits recent action-chunking papers that also exploit receding-horizon overlap; adding 2–3 citations would strengthen context.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.1] §3.1 (LLMD definition): The detector assumes last-layer activations of successful trajectories are adequately modeled by a single multivariate Gaussian whose covariance can be reliably estimated from training tokens. No validation of this modeling choice (e.g., QQ-plots, covariance conditioning, or comparison to kernel density or mixture models) is provided, yet the central claim that LLMD reliably detects OOD states rests on it. High feature dimensionality or LoRA-style finetuning that leaves the final projection largely unchanged could invalidate the assumption.
Authors: We agree that additional validation of the Gaussian assumption would improve the manuscript. The single-Gaussian Mahalanobis distance is a standard choice in the OOD detection literature, but we will add covariance conditioning diagnostics and representative QQ-plots for the last-layer token features in the revised version. We will also include a short discussion noting that LLMD is applied token-wise (mitigating some dimensionality concerns) and that empirical results hold across both full fine-tuning and LoRA-based VLAs; however, we acknowledge that cases where the final projection remains unchanged could reduce sensitivity and will flag this as a limitation. revision: yes
-
Referee: [§3.2] §3.2 (ACC definition and §4 experiments): ACC relies on measurable inconsistency between consecutive overlapping action chunks indicating failure. The manuscript supplies no analysis or ablation on policy stochasticity, chunk length, or the choice of inconsistency metric (L2 vs. cosine). These parameters directly affect whether ACC fires on the claimed failure modes; without such analysis the claim that ACC and LLMD are jointly sufficient for reliable detection across arbitrary OOD states remains unsupported.
Authors: We accept that the current manuscript lacks ablations on these design choices. In the revision we will add experiments that vary chunk length, compare L2 versus cosine inconsistency, and report how detection performance changes. All evaluated policies use deterministic decoding at inference time; we will state this explicitly and briefly discuss expected behavior under temperature sampling. These additions will better support the complementarity argument between LLMD and ACC. revision: yes
-
Referee: [§4] §4 (experimental results and Table 2/3): The abstract and results assert that the LLMD+ACC combination “frequently outperforming significantly more expensive baseline methods” across diverse tasks. However, the paper does not demonstrate that the chosen baselines also operate without failure rollouts or that the reported AUCPDT gains are robust to post-hoc threshold selection. This comparison is load-bearing for the superiority claim.
Authors: We will revise the text and tables to explicitly document the training-data requirements of each baseline, confirming that the main comparators (ensemble and sampling-based detectors) can be run without failure rollouts. Because AUCPDT integrates over all thresholds and incorporates latency, it is designed to be insensitive to any single threshold choice; we will highlight this property more clearly and add a short sensitivity check in the supplement. With these clarifications the reported gains remain valid under the stated experimental conditions. revision: partial
Circularity Check
No circularity; detectors defined from standard statistical ideas and evaluated empirically
full rationale
The paper defines LLMD as token-wise Mahalanobis distance on last-layer features fitted to training data (standard OOD technique) and ACC as inconsistency check on overlapping action chunks from receding-horizon control (standard temporal consistency idea). Neither reduces by construction to target data quantities or self-citations. No equations, uniqueness theorems, or ansatzes are smuggled in; performance claims rest on real-world and simulation experiments rather than derivations equivalent to inputs. The central claim of complementarity is an empirical observation, not a forced result.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Last-layer token features of a finetuned VLA follow a distribution that can be summarized by mean and covariance for Mahalanobis distance computation
- domain assumption Consecutive action chunks produced by receding-horizon control should be temporally consistent when the model is succeeding
Reference graph
Works this paper leans on
-
[1]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π 0: A vision-language-action flow model for general robot control, 2026. URLhttps://arxiv. o...
Pith/arXiv arXiv 2026
-
[2]
Black, N
Physical Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner...
2025
-
[3]
Bjorck, N
NVIDIA, J. Bjorck, N. C. Fernando Castañeda, X. Da, R. Ding, L. J. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z. Xu, S. Ye, Z. Yu, A....
2025
-
[4]
J. Lee, J. Duan, H. Fang, Y . Deng, S. Liu, B. Li, B. Fang, J. Zhang, Y . R. Wang, S. Lee, W. Han, W. Pumacay, A. Wu, R. Hendrix, K. Farley, E. VanderBilt, A. Farhadi, D. Fox, and R. Krishna. Molmoact: Action reasoning models that can reason in space, 2025. URLhttps: //arxiv.org/abs/2508.07917
Pith/arXiv arXiv 2025
-
[5]
H. Fang, J. Duan, D. Clay, S. Wang, S. Liu, W. Huang, X. Fan, W.-C. Tsai, S. Chen, Y . R. Wang, S. Xing, J. Cho, J. S. Park, A. Eftekhar, P. Sushko, K. Farley, A. Wadhwa, C. Harrison, W. Han, Y .-C. Lee, E. VanderBilt, R. Hendrix, S. Ellawela, L. Ngoo, J. Chai, Z. Ren, A. Farhadi, D. Fox, and R. Krishna. Molmoact2: Action reasoning models for real-world d...
Pith/arXiv arXiv 2026
-
[6]
M. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[7]
Q. Gu, Y . Ju, S. Sun, I. Gilitschenski, H. Nishimura, M. Itkina, and F. Shkurti. SAFE: Multitask failure detection for vision-language-action models. InThe Thirty-ninth Annual Conference 9 on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum? id=XPyAukgsFf
2025
-
[8]
K. Menda, K. Driggs-Campbell, and M. J. Kochenderfer. Ensembledagger: A bayesian ap- proach to safe imitation learning. In2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), page 5041–5048. IEEE Press, 2019. doi:10.1109/IROS40897. 2019.8968287. URLhttps://doi.org/10.1109/IROS40897.2019.8968287
-
[9]
S.-W. Lee, X. Kang, and Y .-L. Kuo. Diff-dagger: Uncertainty estimation with diffusion policy for robotic manipulation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 4845–4852. IEEE, 2025
2025
-
[10]
Brunke, M
L. Brunke, M. Greeff, A. W. Hall, Z. Yuan, S. Zhou, J. Panerati, and A. P. Schoellig. Safe learn- ing in robotics: From learning-based control to safe reinforcement learning.Annual Review of Control, Robotics, and Autonomous Systems, 5(1):411–444, 2022
2022
-
[11]
Zheng, J
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y . Feng, Y . Zheng, J. Zou, Y . Chen, J. Zeng, T. Wang, Y .-Q. Zhang, J. Liu, and X. Zhan. X-VLA: Soft-prompted transformer as scal- able cross-embodiment vision-language-action model. InThe Fourteenth International Con- ference on Learning Representations, 2026. URLhttps://openreview.net/forum?id= kt51kZH4aG
2026
-
[12]
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei, J. Fu, J. Gong, and X. Qiu. Libero-plus: In-depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626, 2025
Pith/arXiv arXiv 2025
-
[13]
Römer, A
R. Römer, A. Kobras, L. Worbis, and A. P. Schoellig. Failure prediction at runtime for genera- tive robot policies. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[14]
S. Zhou, B. Zhu, J. Yang, X. Zhao, J. Chen, and Y .-G. Jiang. Rc-nf: Robot-conditioned normalizing flow for real-time anomaly detection in robotic manipulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 43050–43060, June 2026
2026
-
[15]
C. Ma, G. Yang, K. Lu, S. Xu, B. Byrne, N. Trigoni, and A. Markham. Cyclevla: Proactive self-correcting vision-language-action models via subtask backtracking and minimum bayes risk decoding.arXiv preprint arXiv:2601.02295, 2026
arXiv 2026
-
[16]
Z. Lin, J. Duan, H. Fang, D. Fox, R. Krishna, C. Tan, and B. Wen. Failsafe: Reasoning and recovery from failures in vision-language-action models, 2025. URLhttps://arxiv.org/ abs/2510.01642
arXiv 2025
-
[17]
C. Agia, R. Sinha, J. Yang, Z. Cao, R. Antonova, M. Pavone, and J. Bohg. Unpacking failure modes of generative policies: Runtime monitoring of consistency and progress. InProceedings of The 8th Conference on Robot Learning, volume 270 ofProceedings of Machine Learning Research, pages 689–723. PMLR, 2025
2025
-
[18]
C. Xu, T. K. Nguyen, E. Dixon, C. Rodriguez, P. Miller, R. Lee, P. Shah, R. A. Ambrus, H. Nishimura, and M. Itkina. Can we detect failures without failure data? uncertainty-aware runtime failure detection for imitation learning policies. InRobot Evaluation for the Real World, 2025. URLhttps://openreview.net/forum?id=A2iUXYdWZD
2025
-
[19]
Rolland, F
Q. Rolland, F. Mayran de Chamisso, and J.-B. Mouret. Failure identification in imitation learning via statistical and semantic filtering. InIEEE International Conference on Robotics and Automation (ICRA), 2026. 10
2026
-
[20]
G. Zheng, S. Seenivasan, M. Johnson-Roberson, and W. Zhi. Rewind-il: Online failure de- tection and state respawning for imitation learning, 2026. URLhttps://arxiv.org/abs/ 2604.16683
Pith/arXiv arXiv 2026
-
[21]
H. Tan, S. Chen, Y . Xu, Z. Wang, Y . Ji, C. Chi, Y . Lyu, Z. Zhao, X. Chen, P. Co, et al. Robo- dopamine: General process reward modeling for high-precision robotic manipulation.arXiv preprint arXiv:2512.23703, 2025
arXiv 2025
-
[22]
Liang, Y
A. Liang, Y . Korkmaz, J. Zhang, M. Hwang, A. Anwar, S. Kaushik, A. Shah, A. S. Huang, L. Zettlemoyer, D. Fox, Y . Xiang, A. Li, A. Bobu, A. Gupta, S. Tu, E. Biyik, and J. Zhang. Robometer: Scaling general-purpose robotic reward models via trajectory comparisons. In Robotics: Science and Systems 2026, 2026
2026
-
[23]
T. Lee, A. Wagenmaker, K. Pertsch, P. Liang, S. Levine, and C. Finn. Roboreward: A dataset and benchmark for vision-language reward models in robotics, 2025. URLhttps: //openreview.net/forum?id=iDmt7Tzmke
2025
-
[24]
S. Ross, G. Gordon, and D. Bagnell. A reduction of imitation learning and structured predic- tion to no-regret online learning. InProceedings of the fourteenth international conference on artificial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Pro- ceedings, 2011
2011
-
[25]
K. Lee, K. Lee, H. Lee, and J. Shin. A simple unified framework for de- tecting out-of-distribution samples and adversarial attacks. In S. Bengio, H. Wal- lach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors,Ad- vances in Neural Information Processing Systems, volume 31. Curran Associates, Inc.,
-
[26]
URLhttps://proceedings.neurips.cc/paper_files/paper/2018/file/ abdeb6f575ac5c6676b747bca8d09cc2-Paper.pdf
2018
-
[27]
J. Ren, S. Fort, J. Liu, A. G. Roy, S. Padhy, and B. Lakshminarayanan. A simple fix to mahalanobis distance for improving near-ood detection, 2021. URLhttps://arxiv.org/ abs/2106.09022
arXiv 2021
-
[28]
Müller and M
M. Müller and M. Hein. Mahalanobis++: Improving OOD detection via feature normaliza- tion. InForty-second International Conference on Machine Learning, 2025. URLhttps: //openreview.net/forum?id=vutMcZl50l
2025
-
[29]
Daxberger, A
E. Daxberger, A. Kristiadi, A. Immer, R. Eschenhagen, M. Bauer, and P. Hennig. Laplace redux - effortless bayesian deep learning. In M. Ranzato, A. Beygelzimer, Y . Dauphin, P. Liang, and J. W. Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pages 20089–20103. Curran Associates, Inc., 2021. URLhttps://proceedings.neurips.cc/...
2021
-
[30]
Reuss, H
M. Reuss, H. Zhou, M. Rühle, Ö. E. Ya ˘gmurlu, F. Otto, and R. Lioutikov. FLOWER: De- mocratizing generalist robot policies with efficient vision-language-flow models. In9th An- nual Conference on Robot Learning, 2025. URLhttps://openreview.net/forum?id= JeppaebLRD
2025
-
[31]
Q. Li, Y . Deng, Y . Liang, L. Luo, L. Zhou, C. Yao, L. Zeng, Z. Feng, H. Liang, S. Xu, Y . Zhang, X. Chen, H. Chen, L. Sun, D. Chen, J. Yang, and B. Guo. Scalable vision-language-action model pretraining for robotic manipulation with real-life human activity videos.arXiv preprint arXiv:2510.21571, 2025
arXiv 2025
-
[32]
C. Xu, T. K. Nguyen, E. Dixon, C. Rodriguez, P. Miller, R. Lee, P. Shah, R. Ambrus, H. Nishimura, and M. Itkina. Can we detect failures without failure data? uncertainty-aware runtime failure detection for imitation learning policies. InRobotics: Science and Systems, 2025. 11
2025
-
[33]
L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Al- abdulmohsin, M. Tschannen, E. Bugliarello, T. Unterthiner, D. Keysers, S. Koppula, F. Liu, A. Grycner, A. Gritsenko, N. Houlsby, M. Kumar, K. Rong, J. Eisenschlos, R. Kabra, M. Bauer, M. Bošnjak, X. Chen, M. Minderer, P. V oigtlaender, I. Bica, I. Balazevic, J. Puigcerv...
Pith/arXiv arXiv 2024
-
[34]
B. Xiao, H. Wu, W. Xu, X. Dai, H. Hu, Y . Lu, M. Zeng, C. Liu, and L. Yuan. Florence- 2: Advancing a unified representation for a variety of vision tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4818–4829, 2024
2024
-
[35]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning. volume 36, pages 44776–44791, 2023
2023
-
[36]
Jülich Supercomputing Centre. JUWELS Cluster and Booster: Exascale Pathfinder with Mod- ular Supercomputing Architecture at Juelich Supercomputing Centre.Journal of large-scale research facilities, 7(A183), 2021. doi:10.17815/jlsrf-7-183. URLhttp://dx.doi.org/ 10.17815/jlsrf-7-183. 12 A Penalized Detection Time Here, we provide further details on the AUCP...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.