From Holistic Evaluation to Structured Criteria: Rubrics Across the Evolving LLM Landscape
Pith reviewed 2026-07-02 22:38 UTC · model grok-4.3
The pith
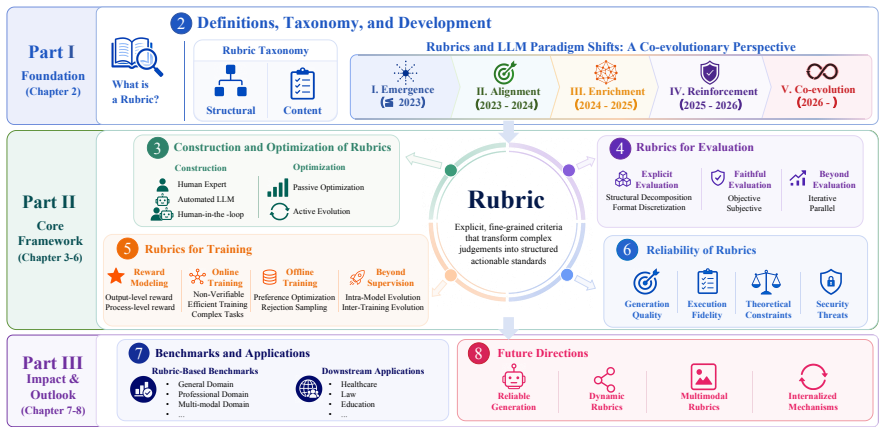
Rubrics turn complex LLM quality judgments into explicit, decomposable criteria that recur across evaluation, training, and self-improvement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
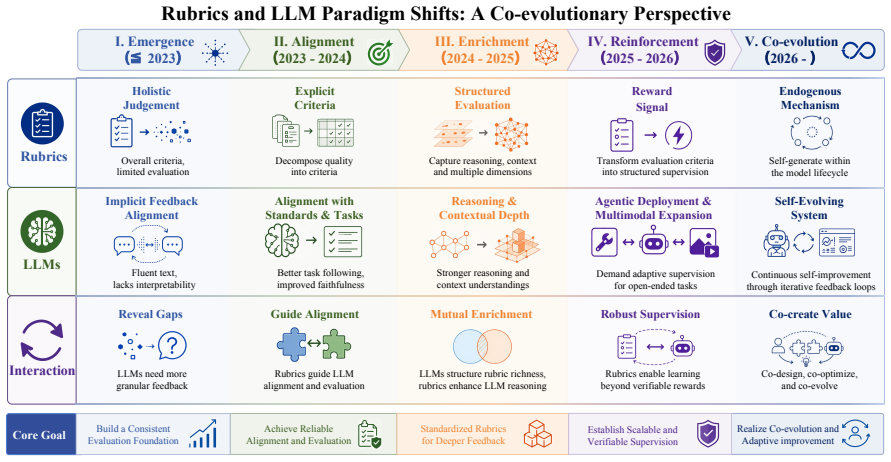
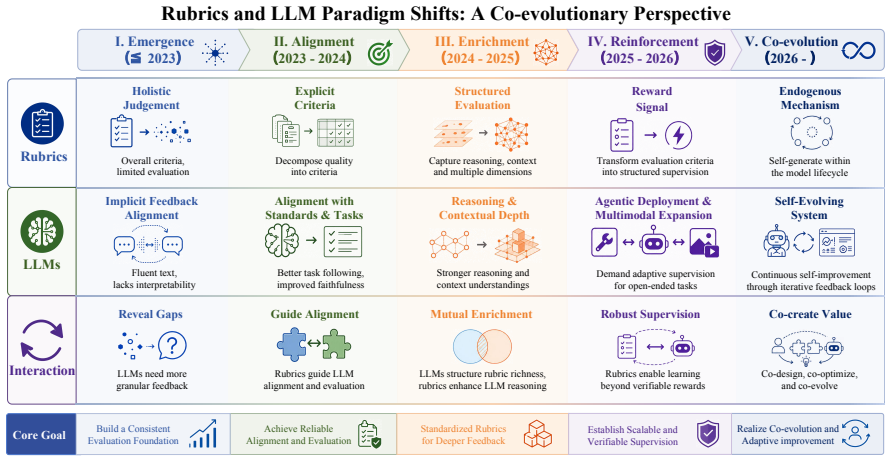
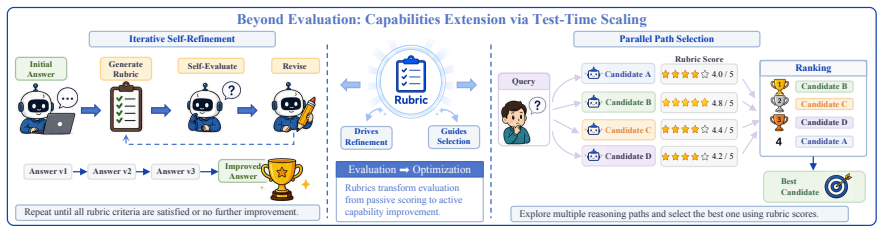
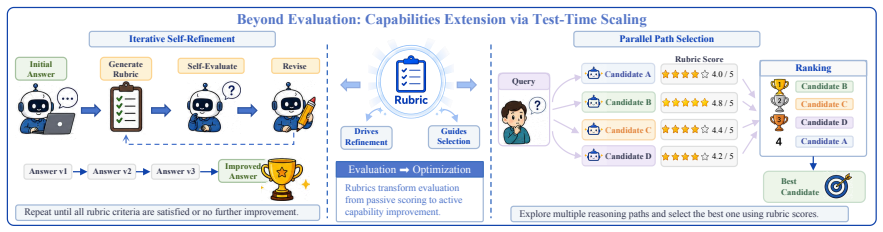
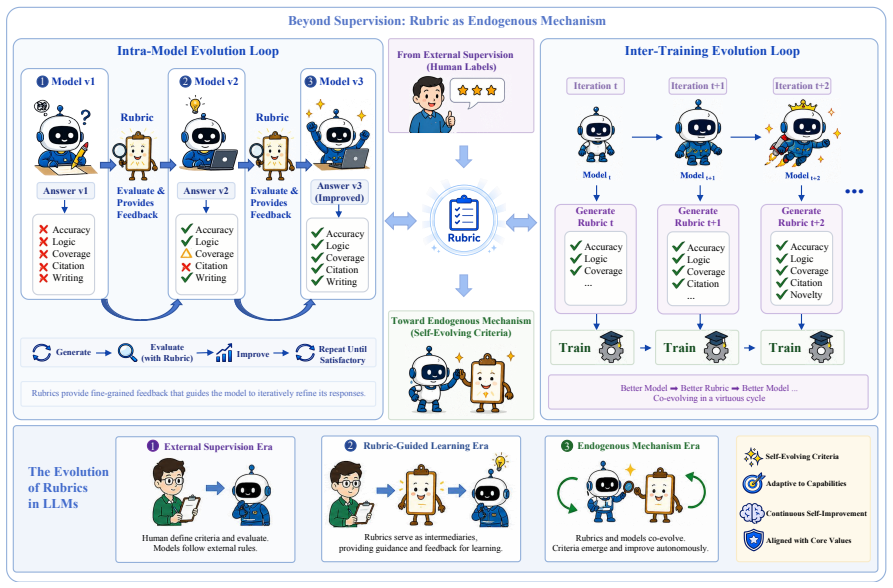
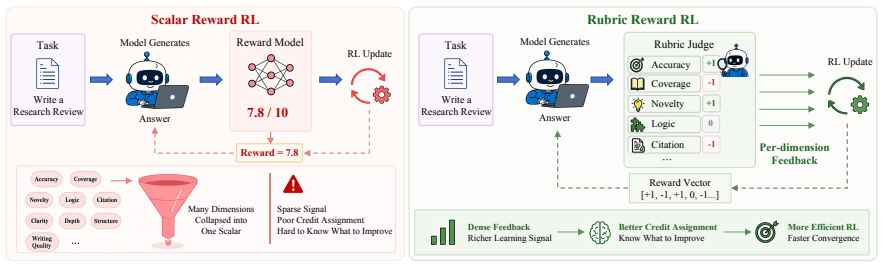
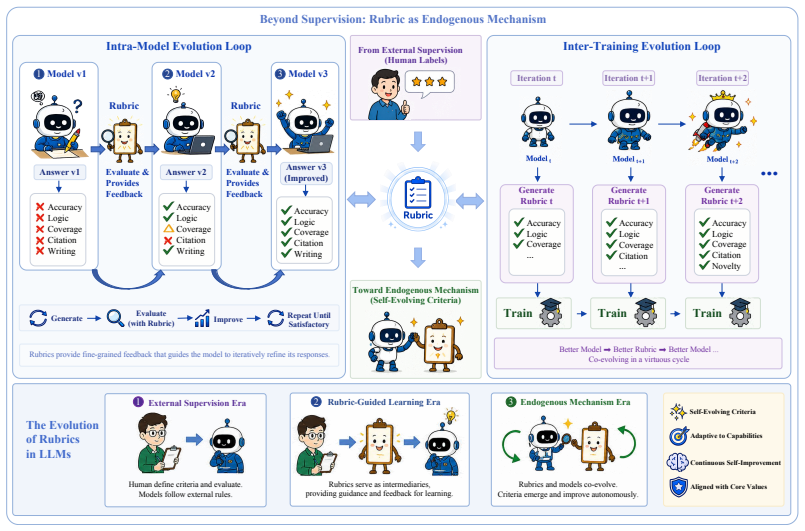
Rubrics manifest at three progressively deeper levels: at the evaluative level they decompose holistic judgments into verifiable dimensions; at the training level they serve as dense feedback signals providing process-level guidance where scalar rewards fall short; at the intrinsic level they emerge dynamically from model behaviors, driving self-improvement. Their recurrence across evaluation, reinforcement learning, and safety alignment is presented as a systematic response to successive LLM paradigm shifts rather than coincidence.
What carries the argument
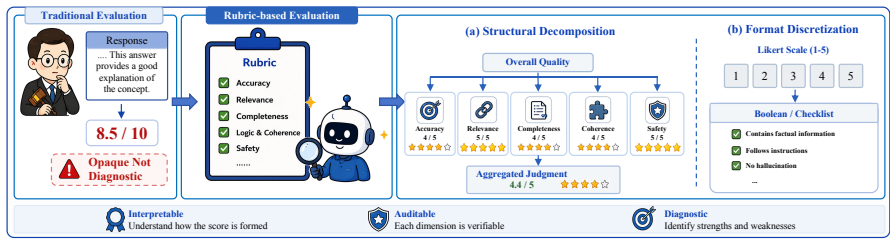
The rubric, defined as an explicit criteria set that transforms complex quality judgments into structured and actionable standards.
If this is right
- Rubrics make assessment transparent by breaking judgments into verifiable dimensions that can be checked independently.
- They supply process-level guidance during training that scalar rewards cannot provide.
- They can arise internally from model behavior to support self-improvement without external supervision.
- Their reliability can be tested separately on generation quality, execution fidelity, theoretical constraints, and security threats.
- They enable construction of benchmarks that apply consistent criteria across diverse domains.
Where Pith is reading between the lines
- If intrinsic rubrics become dominant, models could generate their own evaluation standards that diverge from initial human specifications.
- The framework suggests a path toward alignment methods that treat criteria as learnable rather than fixed external rules.
- Rubric structures may generalize to other structured feedback mechanisms in agent training beyond current LLM settings.
Load-bearing premise
The recurrence of similar rubric structures in evaluation, training, and alignment reflects one underlying systematic response to LLM changes rather than separate practical solutions.
What would settle it
A systematic comparison showing that rubric-like criteria in evaluation, reinforcement learning from human feedback, and safety alignment arise from unrelated engineering needs with no shared structural pattern would falsify the unifying claim.
Figures

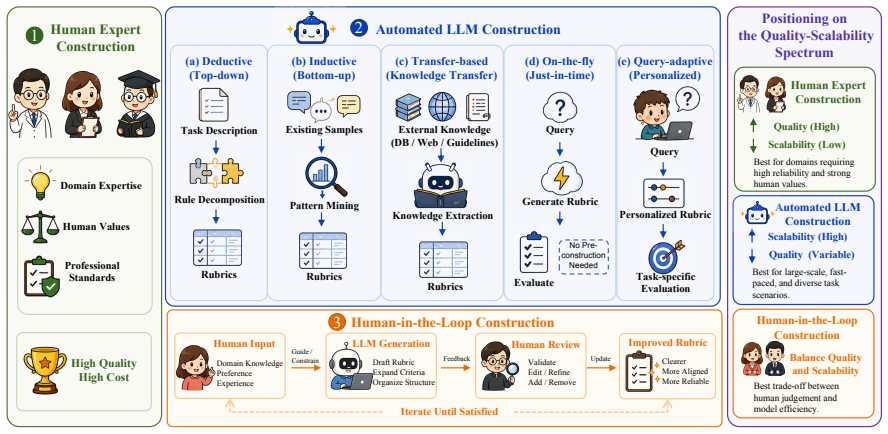
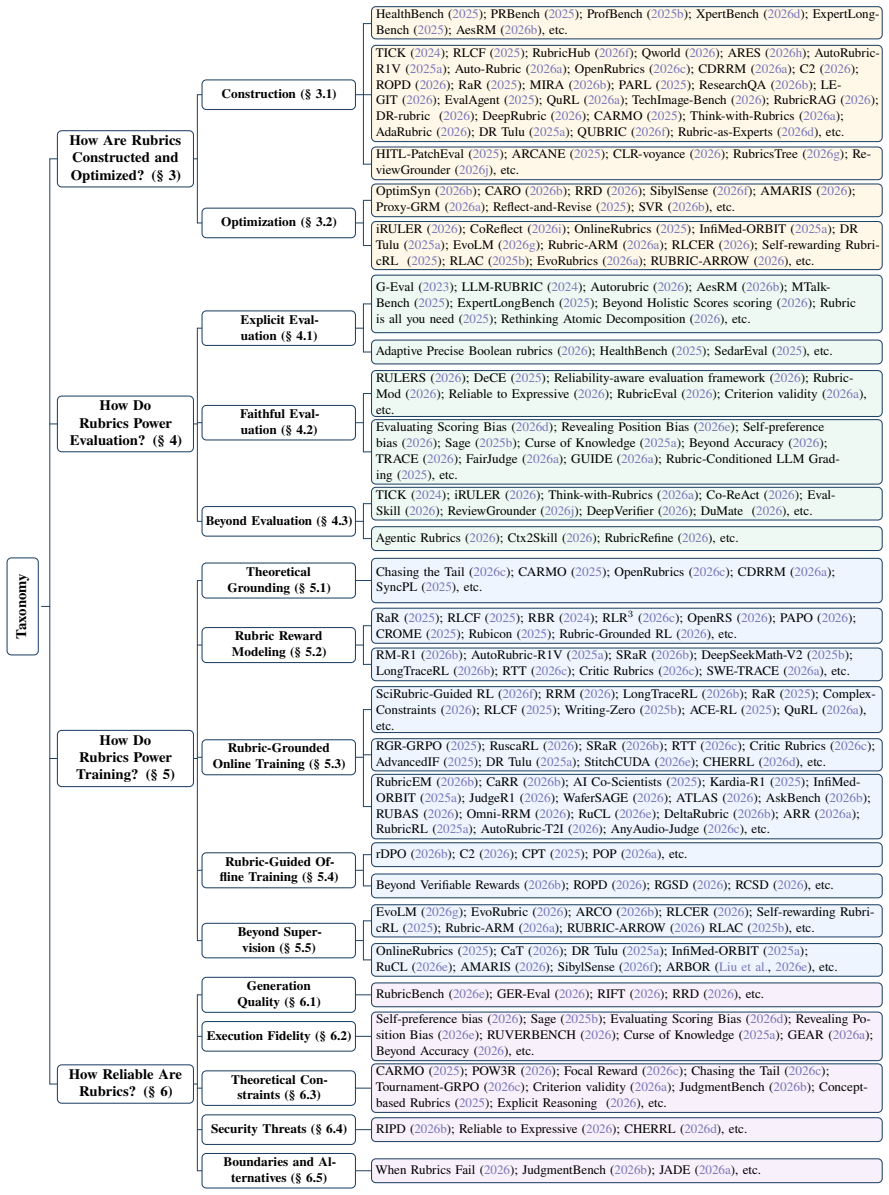
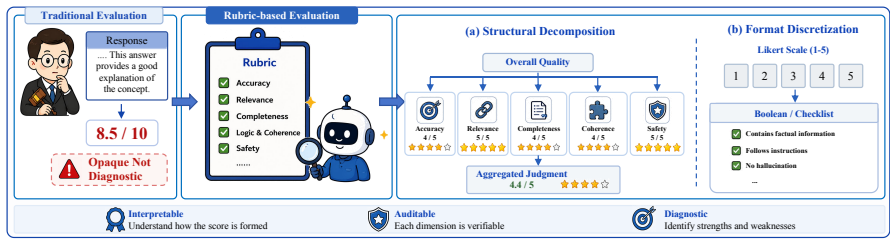
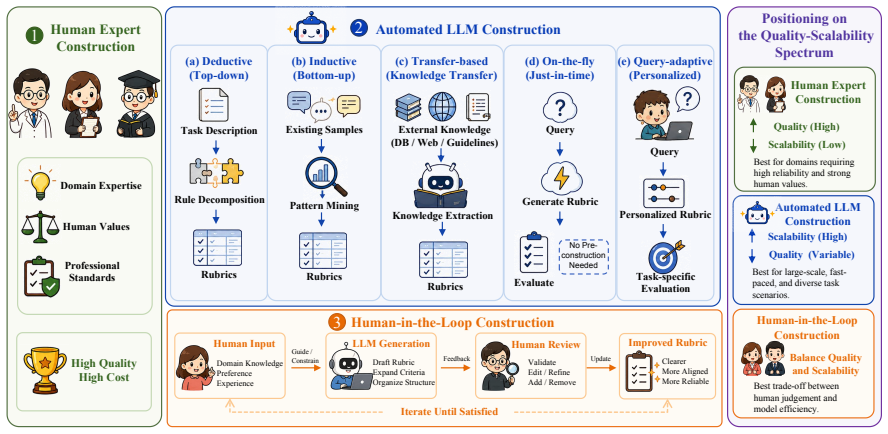
read the original abstract
As Large Language Models (LLMs) advance toward open-ended autonomous agents, the mechanisms used to evaluate and guide their behavior must evolve accordingly. This work introduces the rubric as a unifying framework capturing this evolution, characterizing rubrics as a dynamic response to successive LLM paradigm shifts that recurs across otherwise independent efforts in evaluation, reinforcement learning, and safety alignment. We define rubrics as explicit criteria sets that transform complex quality judgments into structured and actionable standards, and demonstrate that their recurrence across these research threads is not coincidental. We systematically organize existing rubric designs, examine their construction and optimization, and analyze their role across evaluation and training. Rubrics manifest at three progressively deeper levels: at the evaluative level, they decompose holistic judgments into verifiable dimensions; at the training level, they serve as dense feedback signals providing process-level guidance where scalar rewards fall short; at the intrinsic level, they emerge dynamically from model behaviors, driving self-improvement. We further assess rubric reliability across generation quality, execution fidelity, theoretical constraints, and security threats, before surveying rubric-based benchmarks across diverse domains. By rendering assessment transparent and decomposable, rubrics translate human value expectations into machine-learnable signals, serving as the enduring bridge between human intentions and machine behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
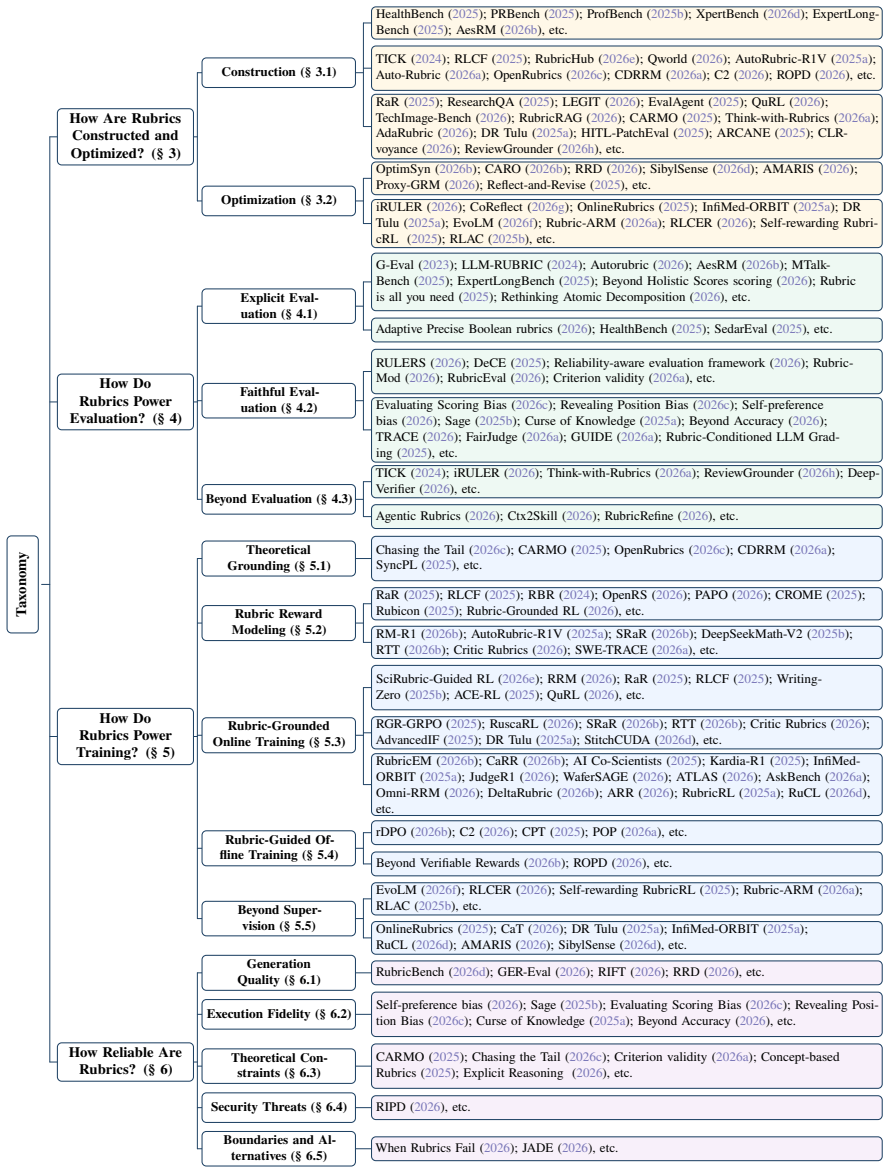
Summary. The paper introduces rubrics as a unifying framework for LLM evaluation and guidance, defining them as explicit criteria sets that transform complex quality judgments into structured and actionable standards. It claims their recurrence across evaluation, reinforcement learning, and safety alignment is a systematic (non-coincidental) response to successive LLM paradigm shifts. The work organizes existing designs, analyzes construction and optimization, and posits three progressively deeper levels: evaluative (decomposing holistic judgments), training (dense process-level feedback), and intrinsic (dynamic emergence from model behaviors for self-improvement). It further assesses reliability across quality, fidelity, constraints, and threats, then surveys rubric-based benchmarks.
Significance. If the non-coincidence claim and three-level taxonomy can be grounded in a predictive mechanism rather than post-hoc classification, the framework could help unify disparate threads in LLM assessment and alignment research. It would highlight how structured criteria serve as bridges between human values and machine behavior, potentially informing future benchmark and training design. The current presentation, however, risks reducing to a broad re-labeling exercise without independent evidence or falsifiable predictions.
major comments (3)
- [Abstract] Abstract, sentence beginning 'We define rubrics as...': The definition is broad enough to retroactively classify many pre-existing evaluation rubrics, reward-model components, and alignment checklists. This renders the central assertion that recurrence 'is not coincidental' but reflects a 'systematic response to successive LLM paradigm shifts' dependent on definitional scope rather than an independent derivation, external benchmark, or mechanism that predicts which techniques will or will not qualify as rubrics.
- [Abstract] Abstract, paragraph on three levels: The taxonomy (evaluative, training, intrinsic) is asserted without reference to specific derivations, empirical checks, or falsifiable predictions. The claim that rubrics 'emerge dynamically from model behaviors, driving self-improvement' at the intrinsic level requires substantiation showing it is forced by paradigm shifts rather than a re-description of existing self-improvement or process-supervision techniques.
- [Abstract] Abstract, sentence 'we demonstrate that their recurrence... is not coincidental': No mechanism, cross-period analysis, or external validation is referenced to establish that the pattern is systematic rather than an artifact of the chosen label. Without this, the non-coincidence claim rests on the breadth of the definition and cannot be load-bearing for the framework's novelty.
minor comments (1)
- The manuscript would benefit from explicit comparison to prior taxonomies in LLM evaluation (e.g., those distinguishing scalar vs. process rewards) to clarify what the rubric lens adds beyond re-organization.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where the abstract's claims require additional grounding and clarification. We respond to each major comment below, indicating planned revisions to the manuscript where they strengthen the presentation without altering the core contribution of organizing rubric designs across LLM research threads.
read point-by-point responses
-
Referee: [Abstract] Abstract, sentence beginning 'We define rubrics as...': The definition is broad enough to retroactively classify many pre-existing evaluation rubrics, reward-model components, and alignment checklists. This renders the central assertion that recurrence 'is not coincidental' but reflects a 'systematic response to successive LLM paradigm shifts' dependent on definitional scope rather than an independent derivation, external benchmark, or mechanism that predicts which techniques will or will not qualify as rubrics.
Authors: The definition is deliberately scoped to the structural property of decomposing complex judgments into explicit, actionable criteria sets, which we use to surface parallels across evaluation, RL, and alignment literature. The manuscript supports the non-coincidental recurrence via a chronological mapping in Sections 2–4 showing how each paradigm shift (from classification to open-ended generation to agentic behavior) exposed limitations of scalar or holistic methods, prompting structured alternatives. To mitigate the retroactive classification concern, we will revise the abstract to foreground the organizing role of the framework and add a new subsection in the introduction with explicit inclusion/exclusion criteria and counterexamples of non-rubric techniques. revision: partial
-
Referee: [Abstract] Abstract, paragraph on three levels: The taxonomy (evaluative, training, intrinsic) is asserted without reference to specific derivations, empirical checks, or falsifiable predictions. The claim that rubrics 'emerge dynamically from model behaviors, driving self-improvement' at the intrinsic level requires substantiation showing it is forced by paradigm shifts rather than a re-description of existing self-improvement or process-supervision techniques.
Authors: The three-level taxonomy is derived from a literature synthesis that groups works by the depth at which criteria interact with model internals or training dynamics; each level is anchored to representative papers cited in the main text. For the intrinsic level, we reference recent self-critique and self-generated reward work as evidence of dynamic emergence. We agree the abstract overstates the 'forced by paradigm shifts' aspect. In revision we will add explicit citations and a derivation table in Section 3, while softening the abstract language to 'we identify three progressively deeper levels observed in the literature' and note the observational rather than predictive nature of the taxonomy. revision: yes
-
Referee: [Abstract] Abstract, sentence 'we demonstrate that their recurrence... is not coincidental': No mechanism, cross-period analysis, or external validation is referenced to establish that the pattern is systematic rather than an artifact of the chosen label. Without this, the non-coincidence claim rests on the breadth of the definition and cannot be load-bearing for the framework's novelty.
Authors: The demonstration rests on the cross-period organization presented in the body, which traces parallel adoption of rubric structures timed to capability jumps (e.g., from outcome supervision to process supervision). This constitutes the cross-period analysis. We accept that the manuscript offers no independent predictive mechanism or external validation beyond the literature synthesis. Accordingly, we will revise the abstract to replace 'we demonstrate that their recurrence... is not coincidental' with the more measured phrasing 'we argue, based on a systematic organization of the literature, that their recurrence reflects a response to paradigm shifts' and relocate stronger interpretive language to the discussion. revision: yes
- The referee correctly notes the absence of a predictive mechanism or falsifiable predictions that would establish the framework as more than post-hoc classification; the manuscript is a survey and organizing lens and does not introduce or test such a mechanism.
Circularity Check
Broad definition of rubrics renders recurrence claim tautological
specific steps
-
self definitional
[abstract]
"We define rubrics as explicit criteria sets that transform complex quality judgments into structured and actionable standards, and demonstrate that their recurrence across these research threads is not coincidental. We systematically organize existing rubric designs..."
The definition is broad enough to encompass pre-existing evaluation rubrics, reward components, and alignment checklists. The 'demonstration' of systematic recurrence therefore consists of re-labeling those artifacts under the new term, making the non-coincidental claim true by the scope of the definition rather than by any independent derivation or falsifiable prediction.
full rationale
The paper's core assertion—that rubric recurrence across evaluation, RL, and safety is a systematic response to paradigm shifts rather than coincidental—rests on a definition general enough to retroactively classify diverse existing techniques as rubrics. The abstract states the definition and then claims to 'demonstrate' non-coincidence by organizing those techniques, without an independent mechanism, external benchmark, or predictive criterion that would falsify the classification. This matches self-definitional circularity: the unifying framework is constructed from the patterns it purports to explain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rubrics are explicit criteria sets that transform complex quality judgments into structured and actionable standards.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2501.15595. Z. Fan, R. Chen, T. Hu, R. Peng, Z. Huang, H. Xu, Y. Chen, J. Wu, J. Zhao, and Z. Liu. Optimsyn: Influence-guided rubrics optimization for synthetic data generation, 2026b. URLhttps://arxiv. org/abs/2604.00536. J. Fang, Z. Hong, M. Zheng, M. Song, G. Li, H. Jiang, D. Zhang, H. Guo, X. Wang, and T.-S. Chua. Rubric-based...
-
[2]
URLhttps://arxiv.org/abs/2603.23522. S. Goel, R. Hazra, D. Jayalath, T. Willi, P. Jain, W. F. Shen, I. Leontiadis, F. Barbieri, Y. Bachrach, J. Geiping, and C. Whitehouse. Training ai co-scientists using rubric rewards, 2025. URL https://arxiv.org/abs/2512.23707. S. Gu, J. Chen, S. Zhou, A. Cohan, and R. Ying. Rethinking reward supervision: Rubric-conditi...
-
[3]
URLhttps://arxiv.org/abs/2604.13618. S. Kim, J. Shin, Y. Cho, J. Jang, S. Longpre, H. Lee, S. Yun, S. Shin, S. Kim, J. Thorne, and M. Seo. Prometheus: Inducing fine-grained evaluation capability in language models, 2024. URL https://arxiv.org/abs/2310.08491. M. Kinniment, L. J. K. Sato, H. Du, B. Goodrich, M. Hasin, L. Chan, L. H. Miles, T. R. Lin, H. Wij...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
URLhttps://arxiv.org/abs/2602.00846. N. Lambert, V. Pyatkin, J. Morrison, L. Miranda, B. Y. Lin, K. Chandu, N. Dziri, S. Kumar, T. Zick, Y. Choi, N. A. Smith, and H. Hajishirzi. Rewardbench: Evaluating reward models for language modeling, 2024. URLhttps://arxiv.org/abs/2403.13787. J. Lee, K.-W. On, S. Han, A. Cohan, and J. Hockenmaier. Evaluating legal re...
-
[5]
URLhttps://arxiv.org/abs/2606.09165. L. Lin, J. Liu, T. Yang, L. Cai, Y. Xu, L. Wei, S. Xie, and G. Zhang. Jade: Expert-grounded dynamic evaluationforopen-endedprofessionaltasks,2026a. URL https://arxiv.org/abs/2602.06486. N. Lin, J. Zhang, L. Hou, and J. Li. Longtracerl: Learning long-context reasoning from search agent trajectories with rubric rewards, ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
ComplexConstraints and Beyond: Expert Rubrics for RLVR
URLhttps://arxiv.org/abs/2606.09118. W.Mei,Z.Gu,Z.Bai,Y.Cai,L.Zhang,Z.Ding,B.Chen,Y.Gao,Y.Wu,Y.Hu,J.Liang,andD.Yang. Deep research as rubric for reinforcement learning, 2026. URLhttps://arxiv.org/abs/2606. 01091. A.Mittal,R.Shar,Z.Wu,S.Agarwal,T.Wu,C.Donahue,A.Talwalkar,W.Chi,andV.Chen.Comparing developer and llm biases in code evaluation, 2026. URLhttps:...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
URLhttp://dx.doi.org/10.1145/3702652.3744220
doi: 10.1145/3702652.3744220. URLhttp://dx.doi.org/10.1145/3702652.3744220. Y. Peng, Y. Qi, H. Peng, H. Xia, G. He, X. Shi, R. Xuan, S. Lu, Y. Liu, Z. Hu, Y. Liu, L. Hou, B. Xu, and J. Li. Can llm-as-a-judge reliably verify rubrics in agentic scenarios?, 2026. URL https://arxiv.org/abs/2606.29920. J.Pombal,R.Rei,andA.F.T.Martins. Self-preferencebiasinrubr...
-
[8]
URLhttps://arxiv.org/abs/2601.04171. D. Rao and C. Callison-Burch. Autorubric: Unifying rubric-based llm evaluation, 2026. URL https://arxiv.org/abs/2603.00077. M. Rezaei, R. Vacareanu, Z. Wang, C. Wang, B. Liu, Y. He, and A. F. Akyürek. Online rubrics elicitation from pairwise comparisons, 2025. URLhttps://arxiv.org/abs/2510.07284. M. Rezaei, A. Mahmoud,...
-
[9]
URLhttps://arxiv.org/abs/2506.01241. K. Sanders, N. Weir, S. Chaudhary, K. Bostrom, and H. Rangwala. Generating data-driven reasoning rubricsfordomain-adaptiverewardmodeling,2026. URL https://arxiv.org/abs/2602.06795. A. Shah, A. Hines, A. Downs, D. Bajet, P. Mui, F. Araujo, L. Offutt, A. Rutledge, and E. Jimenez. Case-specificrubricsforclinicalaievaluati...
-
[10]
URLhttps://arxiv.org/abs/2604.27660. A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025. C.Siro, P.Aliannejadi, andM.Aliannejadi. Learningtojudge: Llmsdesigningandapplyingevaluation rubrics, 2026. URLhttps://arxiv.org/abs/260...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
URLhttps://arxiv.org/abs/2506.16507. G. Starace, O. Jaffe, D. Sherburn, J. Aung, J. S. Chan, L. Maksin, R. Dias, E. Mays, B. Kinsella, W. Thompson, J. Heidecke, A. Glaese, and T. Patwardhan. Paperbench: Evaluating ai’s ability to replicate ai research, 2025. URLhttps://arxiv.org/abs/2504.01848. W. Su, X. Chen, Y. Wu, Q. Ai, and Y. Liu. Enhancing judgment ...
-
[12]
URLhttps://arxiv.org/abs/2605.29310. Z. Ye, Y. Yue, H. Wang, X. Han, J. Jiang, C. Wei, L. Fan, J. Liang, S. Zhang, J. Li, C. Guo, J. Wang, P. Wei, and J. Gu. Self-rewarding rubric-based reinforcement learning for open-ended reasoning,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
URLhttps://arxiv.org/abs/2509.25534. A. Yehudai, L. Eden, A. Li, G. Uziel, Y. Zhao, R. Bar-Haim, A. Cohan, and M. Shmueli-Scheuer. Survey on evaluation of llm-based agents, 2026. URLhttps://arxiv.org/abs/2503.16416. L. S. Yifei, A. Chang, C. Malaviya, and M. Yatskar. Researchqa: Evaluating scholarly question answering at scale across 75 fields with survey...
-
[14]
URLhttps://arxiv.org/abs/2512.01282. 53 Y. Yuan, Q. Mang, J. Chen, H. Wan, X. Liu, J. Xu, J. tse Huang, W. Wang, W. Jiao, and P. He. Curing miracle steps in llm mathematical reasoning with rubric rewards, 2026. URLhttps: //arxiv.org/abs/2510.07774. X. Yue, L. Wu, D. Zhang, Y. Shen, and W. Lu. Beyond rubrics: Exploration-guided evaluation skills for reward...
-
[15]
URLhttps://arxiv.org/abs/2306.05685. Y. Zheng, H. Luo, Z. Lin, W. Liu, and L. A. Tuan. Benchbench: Benchmarking automated benchmark generation, 2026. URLhttps://arxiv.org/abs/2603.20807. J. Zhong, H. Zhang, C. Southern, J. Yang, T. Wang, K. Jung, S. Zhang, D. Yarats, J. Ho, and J. Ma. Draco: a cross-domain benchmark for deep research accuracy, completenes...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.