Reliable to Expressive: A Curriculum for Rubric-Following Safety Judges
Pith reviewed 2026-06-27 16:59 UTC · model grok-4.3
The pith
A reliable-to-expressive curriculum trains 12B judges to apply varying safety rubrics consistently, reaching 94%+ accuracy with 0.76 cross-rubric variance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
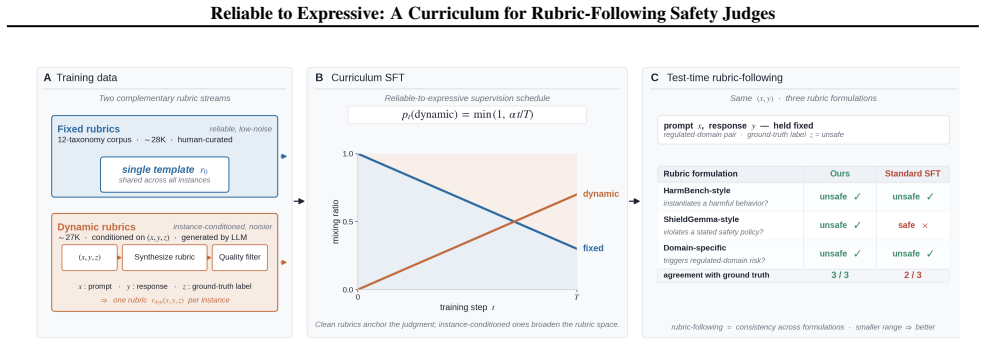
Safety judgment is a rubric-following problem: a robust judge must apply the given evaluation criteria consistently across rubric formulations rather than memorize one specific template. Instance-conditioned dynamic rubrics generated from prompt-response-label triples expose the model to criterion variability, and a reliable-to-expressive curriculum that begins with clean fixed-rubric supervision before introducing noisier dynamic-rubric data produces judges whose accuracy remains high and stable when the same instances are scored under contrasting rubric prompts.
What carries the argument
The reliable-to-expressive curriculum, which begins with clean fixed-rubric supervision and progressively introduces noisier dynamic-rubric data generated from prompt-response-label triples.
If this is right
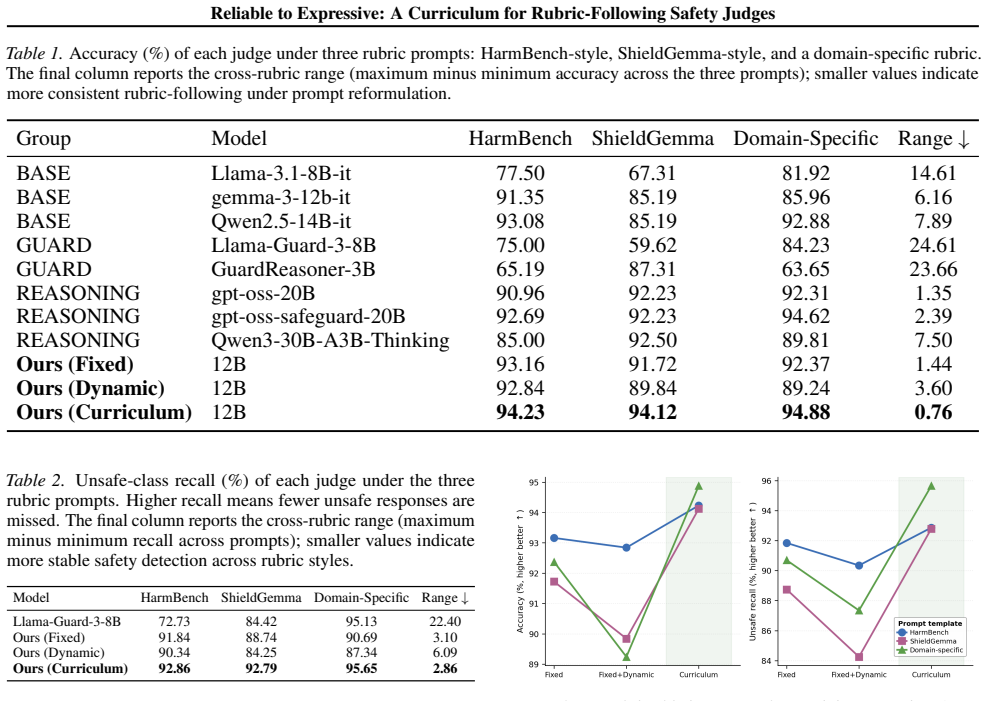
- Naive mixing of dynamic rubrics raises cross-rubric variance from 1.44 to 3.60, while the curriculum schedule reduces it to 0.76.
- The 12B curriculum judge exceeds the peak accuracy and stability of general-purpose LLMs, dedicated safety classifiers, and reasoning-oriented judges up to 30B.
- Performance remains consistent when the same human-labeled set is scored under HarmBench-style, ShieldGemma-style, and domain-specific rubrics.
- The curriculum recovers and improves on the fixed-rubric baseline where simple dynamic-rubric mixing fails.
Where Pith is reading between the lines
- The same curriculum pattern could be tested on other instruction-following tasks that require consistent application of varying criteria.
- Specialized smaller models may suffice for evaluation roles once rubric variability is addressed through ordered training.
- Extending the method to rubrics drawn from entirely new domains would test whether the dynamic-rubric generation generalizes beyond the training distribution.
Load-bearing premise
The generated dynamic rubrics from prompt-response-label triples expose the judge to a representative sample of evaluation-criteria variability.
What would settle it
A new rubric style, never derived from the training triples, on which the curriculum judge shows accuracy variance above 1.0 or peak accuracy below the fixed-rubric baseline.
Figures

read the original abstract
Safety judges are increasingly deployed to evaluate model outputs against evolving criteria, yet recent meta-evaluation work shows they remain brittle under prompt and rubric variation, with false negative-rate swings of up to 0.24 reported for stylistic perturbations alone. We argue that safety judgment is fundamentally a rubric-following problem: a robust judge must apply the given evaluation criteria consistently across rubric formulations rather than memorize one specific template. We propose a training strategy that combines (i) instance-conditioned dynamic rubrics generated from prompt-response-label triples to expose the judge to the variability of evaluation criteria, and (ii) a reliable-to-expressive curriculum that begins with clean fixed-rubric supervision and progressively introduces noisier dynamic-rubric data. We evaluate on a single human-labeled set under three contrasting rubric prompts (HarmBench-style, ShieldGemma-style, and a domain-specific rubric). Our 12B curriculum judge achieves 94.12-94.88% accuracy across the three rubrics with a cross-rubric range of only 0.76, outperforming general-purpose LLMs, dedicated safety classifiers, and reasoning-oriented judges up to 30B in both peak accuracy and stability. An ablation shows that naively mixing dynamic rubrics into SFT increases cross rubric variance (1.44 -> 3.60); only the curriculum schedule recovers and improves on the fixed rubric baseline (variance 0.76).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that safety judgment is a rubric-following task and proposes a two-part training strategy: (i) generating instance-conditioned dynamic rubrics from prompt-response-label triples to expose the model to criterion variability, and (ii) a reliable-to-expressive curriculum that begins with clean fixed-rubric supervision before introducing noisier dynamic data. On a single human-labeled evaluation set under three fixed rubric styles (HarmBench-style, ShieldGemma-style, domain-specific), the resulting 12B model reaches 94.12–94.88% accuracy with a cross-rubric range of only 0.76, outperforming general LLMs, safety classifiers, and reasoning judges up to 30B; an ablation shows that naive mixing of dynamic rubrics increases variance while the curriculum schedule reduces it below the fixed-rubric baseline.
Significance. If the representativeness assumption holds, the work supplies a concrete, empirically validated curriculum method for improving stability of safety judges under rubric variation—an issue highlighted by prior meta-evaluations. The explicit contrast between curriculum ordering and naive mixing, together with the stability metric (cross-rubric range) and comparisons against multiple strong baselines, constitutes a useful methodological contribution. The concrete accuracy figures and ablation results are strengths that would be citable if the distributional claim is substantiated.
major comments (2)
- [Training strategy description] Training strategy description: the central claim that instance-conditioned dynamic rubrics expose the judge to representative variability of evaluation criteria is load-bearing for both the curriculum and the robustness conclusion, yet the manuscript reports no quantitative verification (lexical, structural, or semantic diversity metrics) that the generated rubrics span the same space of criterion changes that would appear in deployment; evaluation stability is measured only across three fixed test rubrics on one dataset.
- [Evaluation section] Evaluation section: the reported 0.76 cross-rubric range and outperformance claims rest on a single held-out human-labeled set; without additional datasets or an analysis of how the three test rubrics relate to the distribution of dynamic rubrics seen in training, it is unclear whether the stability generalizes beyond the specific test styles.
minor comments (2)
- The abstract and evaluation paragraphs should explicitly state the total number of examples, the exact progression schedule of the curriculum (e.g., fraction of dynamic data per stage), and the precise definition of the cross-rubric range metric.
- Figure or table presenting the ablation results should include per-rubric accuracies for all compared models, not only the final range, to allow readers to assess whether gains are uniform or driven by particular rubric styles.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where additional evidence would strengthen the claims about rubric variability and generalization. We respond point-by-point below and indicate where revisions are feasible.
read point-by-point responses
-
Referee: [Training strategy description] Training strategy description: the central claim that instance-conditioned dynamic rubrics expose the judge to representative variability of evaluation criteria is load-bearing for both the curriculum and the robustness conclusion, yet the manuscript reports no quantitative verification (lexical, structural, or semantic diversity metrics) that the generated rubrics span the same space of criterion changes that would appear in deployment; evaluation stability is measured only across three fixed test rubrics on one dataset.
Authors: We agree that explicit quantitative verification of rubric diversity (e.g., lexical, structural, or semantic metrics) is absent and would better support the claim that dynamic rubrics capture representative criterion variability. The generation process conditions on prompt-response-label triples to induce content-specific changes, but without computed diversity statistics this remains unverified. We will add such metrics and a comparison of rubric characteristics in revision. The three test rubrics were selected as contrasting styles to measure stability, though we acknowledge they do not exhaustively represent all deployment variations. revision: partial
-
Referee: [Evaluation section] Evaluation section: the reported 0.76 cross-rubric range and outperformance claims rest on a single held-out human-labeled set; without additional datasets or an analysis of how the three test rubrics relate to the distribution of dynamic rubrics seen in training, it is unclear whether the stability generalizes beyond the specific test styles.
Authors: We concur that reliance on a single human-labeled evaluation set limits the generalizability of the stability results. The three test rubrics were chosen to span distinct styles, but no explicit distributional comparison to the training dynamic rubrics was performed. We will revise to include such an analysis (e.g., feature-based comparison of criterion granularity and phrasing). Additional datasets would require new human annotations and are noted as a limitation for future work. revision: partial
- Evaluation on only a single human-labeled dataset without results from additional datasets to support broader generalization claims.
Circularity Check
No circularity; empirical training and held-out evaluation
full rationale
The paper presents a standard supervised fine-tuning pipeline with a curriculum schedule on generated dynamic rubrics, followed by accuracy measurement on a held-out human-labeled test set under three fixed rubric prompts. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the described derivation. Results are obtained by direct comparison to external labels rather than any internal reduction or construction from the training inputs themselves.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions of supervised fine-tuning and curriculum learning apply to safety judgment tasks
Forward citations
Cited by 2 Pith papers
-
From Holistic Evaluation to Structured Criteria: Rubrics Across the Evolving LLM Landscape
Rubrics function as explicit criteria sets that decompose judgments, supply dense training signals, and emerge from model behavior to bridge human intentions and LLM actions across evaluation, reinforcement learning, ...
-
From Holistic Evaluation to Structured Criteria: Rubrics Across the Evolving LLM Landscape
The paper frames rubrics as a recurring structured-criteria approach that decomposes holistic judgments at evaluative, training, and intrinsic levels in LLM research.
Reference graph
Works this paper leans on
-
[1]
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models
arXiv:2404.01318. Eiras, F., Petrov, A., Torr, P. H. S., Kumar, M. P., and Bibi, A. Know thy judge: On the robustness meta- evaluation of LLM safety judges. InICLR 2025 Work- shop on I Can’t Believe It’s Not Better (ICBINB),
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
arXiv:2503.04474. Gemma Team, G. D. Gemma 3 technical report.arXiv preprint arXiv:2503.19786,
-
[3]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
arXiv:1904.03626. Inan, H., Upasani, K., Chi, J., Rungta, R., Iyer, K., Mao, Y ., Tontchev, M., Hu, Q., Fuller, B., Testuggine, D., and Khabsa, M. Llama Guard: LLM-based input-output safeguard for human-AI conversations.arXiv preprint arXiv:2312.06674,
-
[5]
arXiv:2307.04657. Kim, S., Shin, J., Cho, Y ., Jang, J., Longpre, S., Lee, H., Yun, S., Shin, S., Kim, S., Thorne, J., and Seo, M. Prometheus: Inducing fine-grained evaluation capabil- ity in language models. InThe Twelfth International Conference on Learning Representations (ICLR), 2024a. arXiv:2310.08491. Kim, S., Suk, J., Longpre, S., Lin, B. Y ., Shin...
-
[6]
Mazeika, M., Phan, L., Yin, X., Zou, A., Wang, Z., Mu, N., Sakhaee, E., Li, N., Basart, S., Li, B., Forsyth, D., and Hendrycks, D
ICLR 2025 Workshop on Foundation Models in the Wild. Mazeika, M., Phan, L., Yin, X., Zou, A., Wang, Z., Mu, N., Sakhaee, E., Li, N., Basart, S., Li, B., Forsyth, D., and Hendrycks, D. HarmBench: A standardized evaluation framework for automated red teaming and robust refusal. InProceedings of the 41st International Conference on Machine Learning (ICML),
2025
-
[7]
arXiv:2402.04249. OpenAI. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Training language models to follow instructions with human feedback
arXiv:2203.02155. Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y . K., Wu, Y ., and Guo, D. DeepSeek- Math: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Xie, T., Qi, X., Zeng, Y ., Huang, Y ., Sehwag, U. M., Huang, K., He, L., Wei, B., Li, D., Sheng, Y ., Jia, R., Li, B., Li, K., Chen, D., Henderson, P., and Mittal, P. SORRY-Bench: Systematically evaluating large language model safety re- fusal behaviors.arXiv preprint arXiv:2406.14598,
-
[10]
Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
ShieldGemma: Generative AI Content Moderation Based on Gemma
Zeng, W., Liu, Y ., Mullins, R., Peran, L., Fernandez, J., Harkous, H., Narasimhan, K., Proud, D., Kumar, P., Radharapu, B., Sturman, O., and Wahltinez, O. Shield- Gemma: Generative AI content moderation based on Gemma.arXiv preprint arXiv:2407.21772,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.