Beyond the Hard Budget: Sparsity Regularizers for More Interpretable Top-k Sparse Autoencoders
Pith reviewed 2026-06-26 04:59 UTC · model grok-4.3
The pith
Hard Top-k selection and soft sparsity penalties combine to improve monosemanticity in autoencoders.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
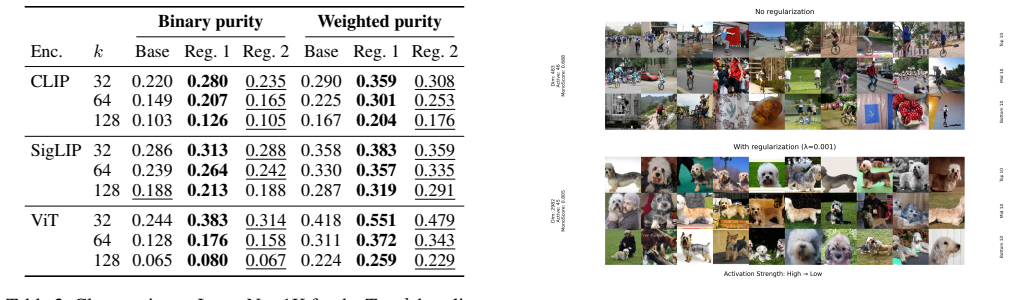
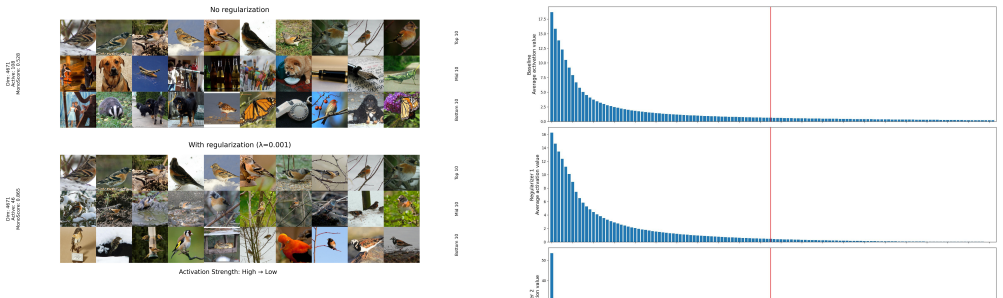
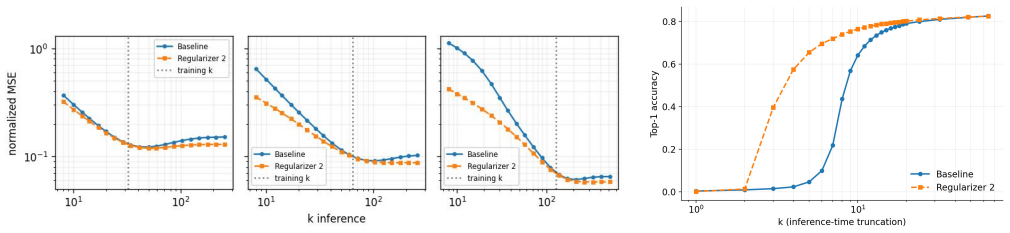
Top-k sparse autoencoders enforce sparsity by keeping only the k largest activations per input, avoiding the drawbacks of an explicit L1 penalty yet still suffering from a fixed budget k and overfitting to the training value of k. The paper introduces two compatible regularizers acting before the Top-k step: an L1 penalty on off-support units and an L1/L2-ratio penalty that concentrates the code. Both are applied only to batch-active units. The result is higher monosemanticity at unchanged reconstruction quality, with the ratio penalty also concentrating information and making reconstruction more robust to the inference-time choice of k.
What carries the argument
The two pre-Top-k sparsity regularizers—an L1 penalty on unselected units and a scale-invariant L1/L2-ratio penalty—restricted to batch-active units.
If this is right
- Monosemanticity improves consistently across two datasets, three vision models, and a range of k values.
- The L1/L2 ratio penalty concentrates information into fewer effective latents.
- Reconstruction quality becomes less dependent on the exact inference-time value of k.
- Linear probing accuracy improves especially when the probing budget is small.
Where Pith is reading between the lines
- The same hybrid approach could be tested on non-vision modalities or on other hard-sparsity architectures to check whether complementarity holds more generally.
- Because the ratio penalty reduces dependence on k, it may allow training once with a large k and then selecting smaller subsets at inference without retraining.
- The concentration effect might lower the total number of latents required to reach a target level of reconstruction or interpretability.
Load-bearing premise
Standard monosemanticity metrics reliably measure true interpretability gains and restricting the regularizers to batch-active units does not create new selection biases.
What would settle it
If the same regularizers produce no monosemanticity gain or degrade reconstruction when tested on a new vision foundation model or dataset outside the three reported, the claim of complementarity would be falsified.
Figures

read the original abstract
Sparse autoencoders (SAEs) have become a leading tool for interpreting the representations of vision foundation models, decomposing their polysemantic activations into a larger set of sparse, more monosemantic features. The Top-$k$ SAE, a now-standard variant, enforces sparsity architecturally through its activation function, retaining only the $k$ most active latents per input. Because it was designed precisely to avoid the $\ell_1$ penalty used by earlier SAEs and its known drawbacks, it has not been combined with an explicit sparsity regularizer, despite retaining limitations of its own, such as a budget $k$ that is fixed regardless of input complexity and a tendency to overfit to the training value of $k$. We introduce two sparsity regularizers compatible with the Top-$k$ architecture, both acting on the activations before the Top-$k$ selection: an $\ell_1$ penalty on the unselected (off-support) units, and a scale-invariant $\ell_1/\ell_2$-ratio penalty that concentrates the code onto fewer effective units. Both penalties are applied only to the batch-active units, those selected by the Top-$k$ operator at least once within the batch. Across two datasets, three vision foundation models, and a range of $k$, both regularizers consistently improve monosemanticity at no cost to reconstruction quality. The $\ell_1/\ell_2$ penalty further concentrates information into fewer latents, making reconstruction more robust to the inference-time choice of $k$ and improving small-budget linear probing. Our central finding is that hard architectural sparsity and soft sparsity regularization are complementary rather than mutually exclusive.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces two sparsity regularizers for Top-k sparse autoencoders—an ℓ1 penalty on off-support (unselected) activations and a scale-invariant ℓ1/ℓ2-ratio penalty—both applied exclusively to batch-active units (those selected by Top-k at least once in the batch). These are positioned as compatible with the hard Top-k architectural constraint. Across two datasets, three vision foundation models, and varying k, the regularizers are reported to improve standard monosemanticity metrics at no cost to reconstruction fidelity; the ℓ1/ℓ2 variant additionally concentrates information, improving robustness to inference-time k and small-budget linear probing. The central claim is that hard architectural sparsity and soft regularization are complementary rather than mutually exclusive.
Significance. If the reported gains are robust to the batch-active restriction and genuinely reflect improved feature interpretability rather than metric artifacts, the work would establish a practical route to combining architectural and penalty-based sparsity in SAEs. This could yield more stable and interpretable decompositions for vision models, with the added benefit of reduced sensitivity to the training k. The consistent cross-model/dataset pattern and the robustness result are concrete strengths that would be useful to the mechanistic interpretability community.
major comments (1)
- [Abstract] Abstract (and the corresponding methods description of the regularizers): the claim that the two regularizers produce genuine complementarity relies on monosemanticity gains being attributable to the penalties rather than the batch-active restriction. Because the restriction selects a dynamically determined subset before the Top-k operator and couples regularization strength to per-batch activation statistics, it risks a selection bias or feedback loop favoring already-monosemantic units. No ablation (full-unit regularization) or distributional analysis is described that would rule this out, making the central empirical claim load-bearing on an untested assumption.
minor comments (1)
- [Abstract] The abstract states that both penalties act 'before the Top-k selection' yet are restricted to batch-active units; a brief clarifying sentence on the exact computational ordering would remove ambiguity.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying this potential confound in our central claim. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (and the corresponding methods description of the regularizers): the claim that the two regularizers produce genuine complementarity relies on monosemanticity gains being attributable to the penalties rather than the batch-active restriction. Because the restriction selects a dynamically determined subset before the Top-k operator and couples regularization strength to per-batch activation statistics, it risks a selection bias or feedback loop favoring already-monosemantic units. No ablation (full-unit regularization) or distributional analysis is described that would rule this out, making the central empirical claim load-bearing on an untested assumption.
Authors: We agree that the batch-active restriction is a design choice whose isolated contribution has not been ablated, and that this leaves the attribution of monosemanticity gains to the penalties themselves partially untested. The restriction was introduced to maintain compatibility with the hard Top-k constraint: units never selected within a batch have zero gradient contribution through the Top-k operator, so penalizing them would not affect reconstruction or the architectural sparsity. Nevertheless, the referee's concern is valid. In revision we will add (i) an ablation applying the same penalties to all units (with appropriate loss scaling) and (ii) a distributional analysis of activation frequencies and monosemanticity scores for batch-active versus never-active units. These additions will allow readers to assess whether the observed gains are driven by the penalties or by the selection mechanism. revision: yes
Circularity Check
No circularity; empirical claims rest on independent experimental comparisons
full rationale
The paper proposes two new sparsity regularizers for Top-k SAEs (ℓ1 on off-support units and scale-invariant ℓ1/ℓ2 ratio, both restricted to batch-active units) and reports empirical improvements in monosemanticity metrics across datasets, models, and k values. The central complementarity claim is presented as an experimental finding, not a mathematical derivation. No equations, predictions, or first-principles results are shown that reduce by construction to fitted parameters, self-definitions, or self-citations. The work is self-contained against external benchmarks via direct ablation-style comparisons, warranting a score of 0.
Axiom & Free-Parameter Ledger
free parameters (2)
- regularization coefficients
- k
axioms (1)
- domain assumption Monosemanticity metrics accurately reflect interpretability
Reference graph
Works this paper leans on
-
[1]
Adaptive Sparse Allocation with Mutual Choice and Feature Choice Sparse Autoencoders. arXiv:2411.02124. Bricken, T.; Templeton, A.; Batson, J.; Chen, B.; Jermyn, A.; Conerly, T.; Turner, N.; Anil, C.; Denison, C.; Askell, A.; Lasenby, R.; Wu, Y.; Kravec, S.; Schiefer, N.; Maxwell, T.; Joseph, N.; Hatfield-Dodds, Z.; Tamkin, A.; Nguyen, K.; McLean, B.; Bur...
-
[2]
https://transformer-circuits.pub/ 2023/monosemantic-features
Towards Monosemanticity: Decom- posing Language Models with Dictionary Learning.Trans- former Circuits Thread. https://transformer-circuits.pub/ 2023/monosemantic-features. Bussmann, B.; Leask, P.; and Nanda, N
2023
-
[3]
BatchTopK Sparse Autoencoders. arXiv:2412.06410. Bussmann, B.; Nabeshima, N.; Karvonen, A.; and Nanda, N
-
[4]
Learning Multi-Level Features with Matryoshka Sparse Autoencoders. arXiv:2503.17547. Cunningham, H.; Ewart, A.; Riggs, L.; Huben, R.; and Sharkey, L
-
[5]
Sparse Autoencoders Find Highly Inter- pretable Features in Language Models. arXiv:2309.08600. Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; Uszkoreit, J.; and Houlsby, N
-
[6]
InInternationalConferenceonLearn- ing Representations (ICLR)
An Image Is Worth 16x16 Words: Transformers for Image RecognitionatScale. InInternationalConferenceonLearn- ing Representations (ICLR). Elhage, N.; Hume, T.; Olsson, C.; Schiefer, N.; Henighan, T.; Kravec, S.; Hatfield-Dodds, Z.; Lasenby, R.; Drain, D.; Chen, C.; Grosse, R.; McCandlish, S.; Kaplan, J.; Amodei, D.;Wattenberg,M.;andOlah,C.2022.ToyModelsofSu...
Pith/arXiv arXiv 2022
-
[7]
Stable and Steer- able Sparse Autoencoders with Weight Regularization. arXiv:2603.04198. Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; Duerig, T.; and Ferrari, V
-
[8]
Makhzani, A.; and Frey, B
The Open ImagesDatasetV4:UnifiedImageClassification,ObjectDe- tection,andVisualRelationshipDetectionatScale.Interna- tional Journal of Computer Vision, 128(7): 1956–1981. Makhzani, A.; and Frey, B
1956
-
[9]
k-Sparse Autoencoders. arXiv:1312.5663. Olson, M. L.; Hinck, M.; Ratzlaff, N.; Li, C.; Howard, P.; Lal,V.;andTseng,S.-Y.2025. ProbingtheRepresentational Power of Sparse Autoencoders in Vision Models. ICCV Workshops 2025, arXiv:2508.11277. Pach, M.; Karthik, S.; Bouniot, Q.; Belongie, S.; and Akata, Z.2025.SparseAutoencodersLearnMonosemanticFeatures in Vis...
Pith/arXiv arXiv 2025
-
[10]
InInternational Conference on Machine Learning (ICML), 8748–8763
Learning Trans- ferable Visual Models from Natural Language Supervision. InInternational Conference on Machine Learning (ICML), 8748–8763. Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; Berg,A.C.;andFei-Fei,L.2015. ImageNetLargeScaleVi- sual Recognition Challenge.International Journ...
2015
-
[11]
VERIFY FULL AU- THOR LIST, arXiv:2605.06610
SoftSAE: Dynamic Top-K Selection for Adaptive Sparse Autoencoders. VERIFY FULL AU- THOR LIST, arXiv:2605.06610. Stevens, S.; Chao, W.-L.; Berger-Wolf, T.; and Su, Y
-
[12]
Sparse Autoencoders for Scientifically Rigorous Interpreta- tion of Vision Models. arXiv:2502.06755. Tschannen, M.; Gritsenko, A.; Wang, X.; Naeem, M. F.; Alabdulmohsin, I.; Parthasarathy, N.; Evans, T.; Beyer, L.; Xia, Y.; Mustafa, B.; Hénaff, O.; Harmsen, J.; Steiner, A.; andZhai,X.2025. SigLIP2:MultilingualVision-Language EncoderswithImprovedSemanticUn...
arXiv 2025
-
[13]
VERIFY AUTHOR LIST, arXiv:2508.17320
AdaptiveK Sparse Autoencoders: Dy- namic Sparsity Allocation for Interpretable LLM Represen- tations. VERIFY AUTHOR LIST, arXiv:2508.17320
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.