The Serialized Bridge: Understanding and Recovering LLM Serving Performance under Blackwell GPU Confidential Computing
Pith reviewed 2026-06-26 06:37 UTC · model grok-4.3
The pith
The confidential VM-GPU bridge serializes host-device transfers and causes 13-27% LLM serving throughput loss under TDX plus GPU-CC.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
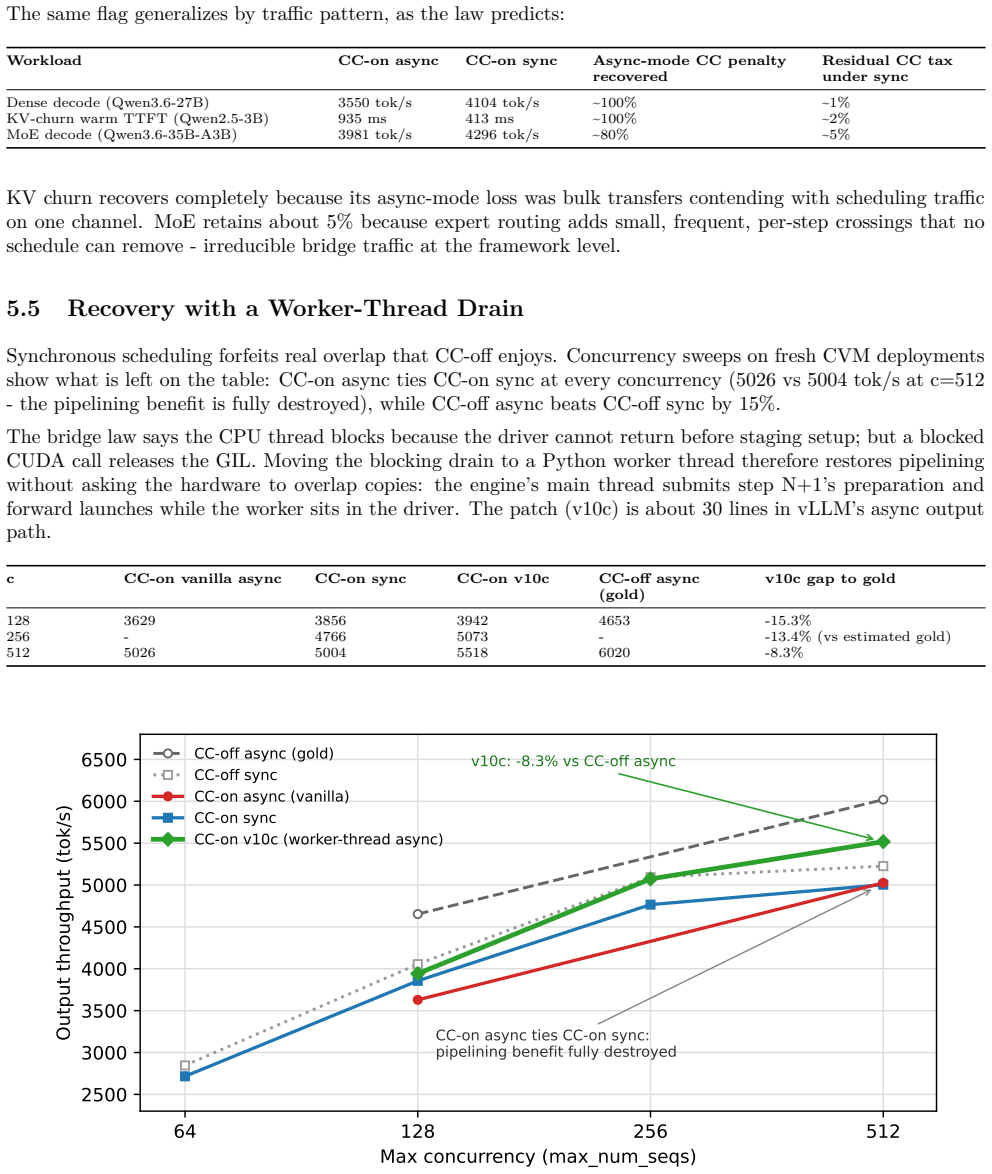
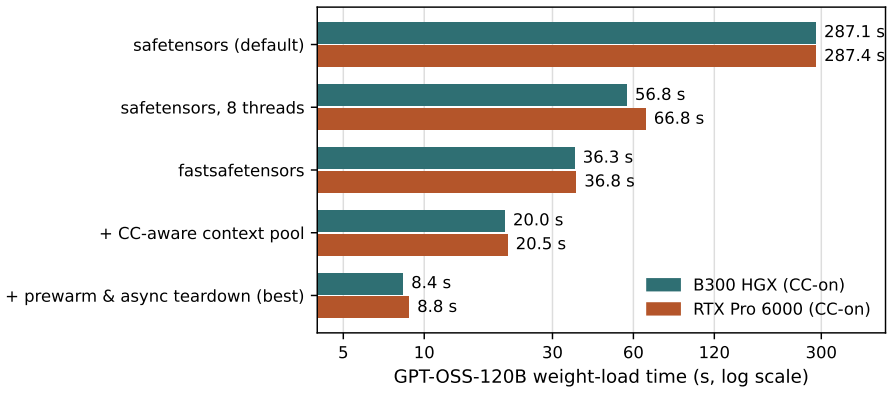
The dominant cause of the performance gap is the confidential VM-GPU bridge, which turns host/device movement into a serialized, high-setup-cost channel that violates assumptions of modern inference runtimes. On RTX Pro 6000 and B300 HGX platforms, secure copies do not gain CUDA-stream concurrency within a context, asynchronous transfers block at the runtime boundary, and small crossings pay a fixed toll. This produces the measured 13-27% throughput loss in vLLM dense decode, a +131% KV-restore penalty, and a 34x model-load slowdown. A scheduling flag recovers 57% of the gap and a worker-thread drain recovers up to 92% in high-concurrency runs. Blackwell also qualifies confidential multi-GPU
What carries the argument
The confidential VM-GPU bridge, which enforces secure but serialized and high-setup-cost host/device data movement instead of the cheap concurrent DMA expected by inference runtimes.
If this is right
- A simple scheduling flag recovers 57% of the throughput gap in vLLM dense decode.
- A worker-thread drain recovers up to 92% of the gap in qualified high-concurrency runs.
- The same bridge model accounts for the +131% KV-restore latency penalty and the 34x model-load slowdown.
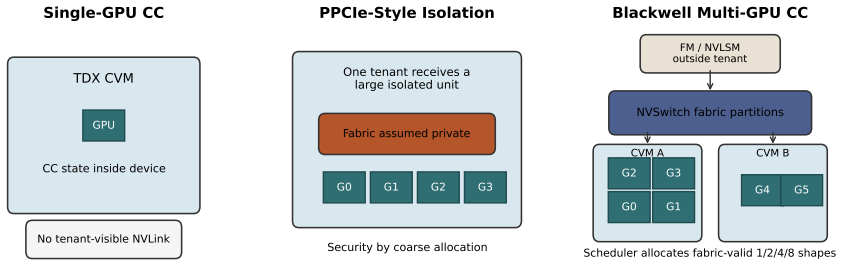
- Confidential multi-GPU NVSwitch tenants on B300 achieve 510 GB/s NVLink P2P inside a CVM with concurrent isolated tenants.
Where Pith is reading between the lines
- Inference runtimes may need explicit awareness of serialized bridges when running under confidential computing rather than assuming DMA remains cheap and concurrent.
- The same bridge behavior could appear in other TDX or SEV-SNP plus GPU-CC combinations and would be testable by repeating the small-allocation microbenchmarks.
- Closing the remaining fabric-attestation gap would be required before production confidential multi-tenant AI platforms can fully use the qualified NVSwitch tenants.
- The performance recovery techniques could be back-ported to other serving frameworks that rely on frequent small host-device crossings.
Load-bearing premise
The observed throughput and latency gaps are produced by the VM-GPU bridge itself rather than by interactions with the particular vLLM version, TDX settings, or other unmeasured system components.
What would settle it
Measure end-to-end vLLM throughput and small-copy latency on the same Blackwell hardware with GPU-CC disabled but TDX still active; if the 13-27% gap and 44x small-operation slowdown disappear, the bridge is the cause.
Figures
read the original abstract
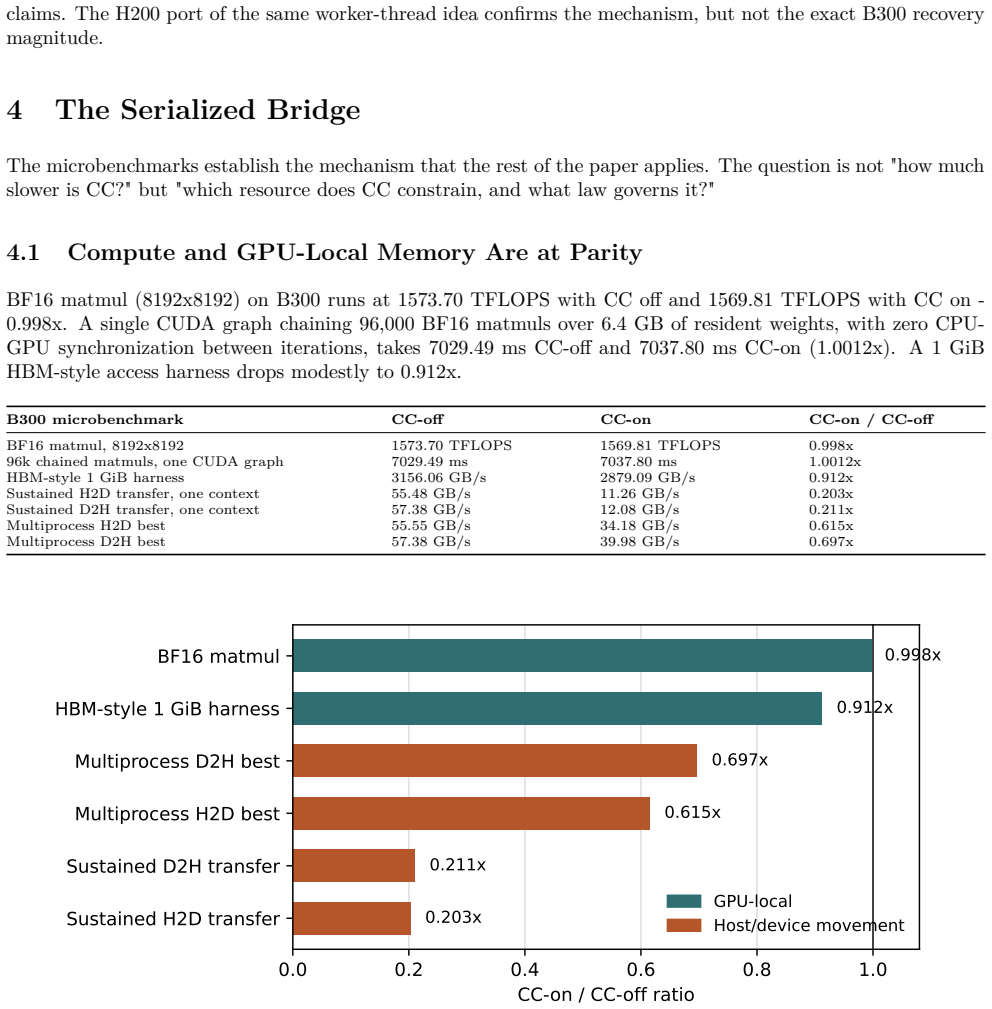
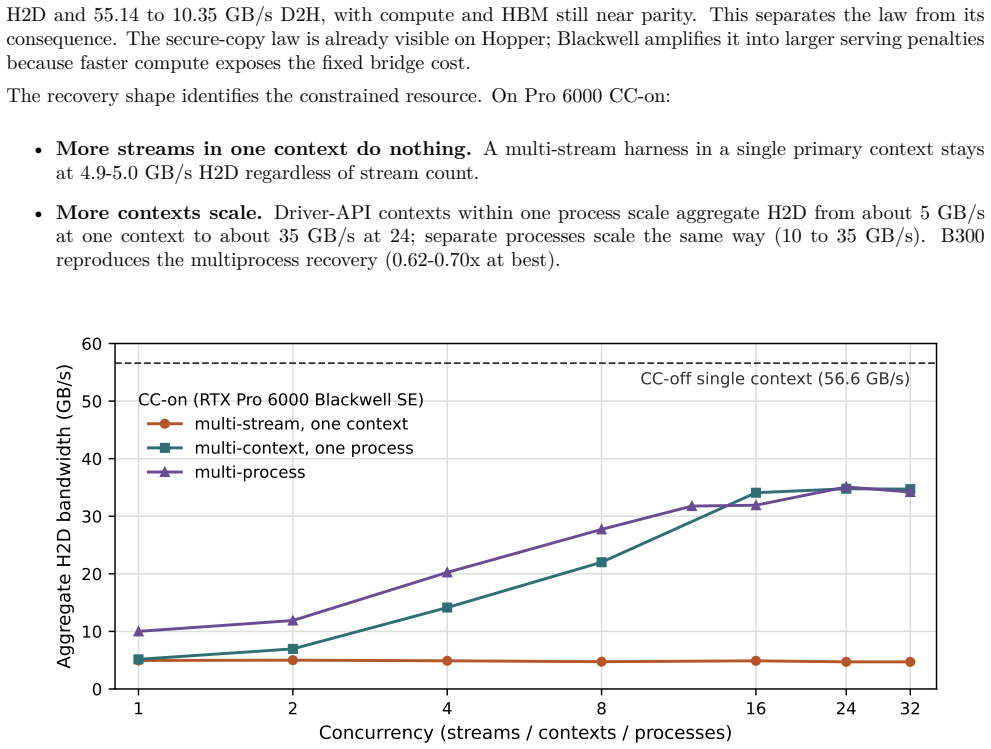
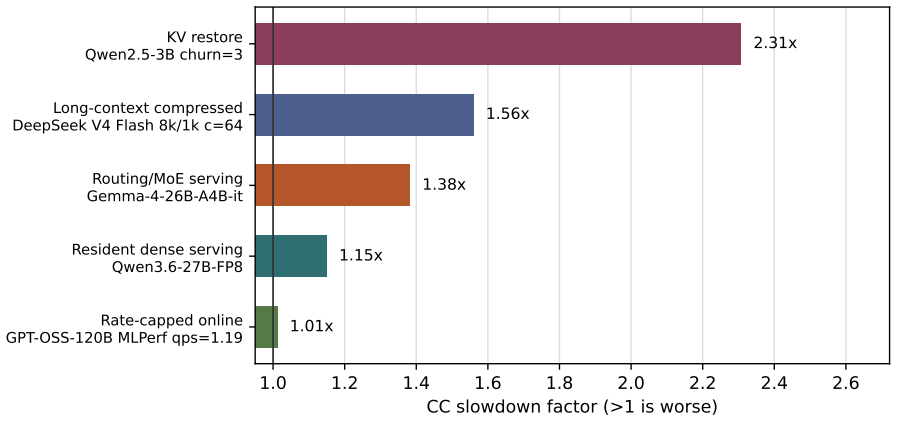
GPU Confidential Computing (GPU-CC) now preserves GPU-local performance: on NVIDIA B300, BF16 matmul runs at 0.998x of non-confidential performance. Yet LLM serving under Intel TDX plus GPU-CC still loses 13-27% of throughput, and KV-cache restore latency can more than double. This paper studies that gap on two Blackwell platforms, RTX Pro 6000 and B300 HGX, and identifies its dominant cause: the confidential VM-GPU bridge, not GPU compute. We find that GPU-CC turns host/device movement into a serialized, high-setup-cost channel. Secure copies do not gain CUDA-stream concurrency within a context, asynchronous transfers block at the runtime boundary, and small crossings pay a fixed toll. This violates the assumptions of modern inference runtimes, where DMA is expected to be cheap, concurrent, and asynchronous. In vLLM dense decode, the gap closes around 44x-slower small alloc-and-copy operations; targeted patches reject alternative explanations. A scheduling flag recovers 57% of the gap, while a worker-thread drain recovers up to 92% in qualified high-concurrency runs. The same bridge model explains a +131% KV-restore penalty and a 34x model-load slowdown. Blackwell also changes the confidential tenancy unit. We qualify confidential multi-GPU NVSwitch tenants on B300, including 510 GB/s NVLink P2P inside a CVM and concurrent isolated tenants, and identify the remaining fabric-attestation gap for production confidential AI platforms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that the 13-27% throughput loss and doubled KV-cache restore latency in LLM serving under Intel TDX + Blackwell GPU-CC (on RTX Pro 6000 and B300 HGX) is caused by the serialized, high-setup-cost confidential VM-GPU bridge for host/device transfers rather than by GPU compute itself (which achieves 0.998x matmul parity). It supports this via micro-benchmarks on secure copies, identification of violated runtime assumptions (no stream concurrency, blocking async transfers, fixed toll on small crossings), targeted vLLM patches that isolate the effect around 44x-slower small alloc/copy operations, and two mitigations (scheduling flag recovering 57%, worker-thread drain recovering up to 92% in high-concurrency cases). The same model explains the +131% KV-restore penalty and 34x model-load slowdown; the work also qualifies confidential multi-GPU NVSwitch tenancy including 510 GB/s P2P inside a CVM.
Significance. If the empirical isolation holds, the result is significant for systems supporting confidential AI inference: it pinpoints a bridge-level bottleneck that violates modern inference runtime assumptions and supplies concrete, measurable mitigations. Credit is due for the use of targeted patches to reject alternative explanations (vLLM version, TDX config) and for qualifying new Blackwell confidential tenancy properties on production-relevant hardware.
minor comments (3)
- Abstract and §4 (micro-benchmarks) should include explicit error bars, run counts, and the exact vLLM commit/version used so that the 44x slowdown and 57% recovery numbers can be directly reproduced.
- Figure captions for the throughput and KV-restore plots should state the concurrency level, batch size, and whether the scheduling flag was enabled, to avoid ambiguity when comparing the two mitigation strategies.
- The description of the worker-thread drain mitigation would benefit from a short pseudocode snippet or call-graph annotation showing where the drain is inserted relative to the CUDA stream boundary.
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of our work, including the identification of the confidential VM-GPU bridge as the root cause of the observed throughput and latency penalties. The report correctly notes our use of microbenchmarks, targeted patches, and mitigations. No major comments were raised in the report.
Circularity Check
No significant circularity: empirical measurements only
full rationale
The paper presents hardware measurements, microbenchmarks, and mitigation experiments on Blackwell platforms under TDX+GPU-CC. No equations, fitted parameters, or derivations appear in the provided text or abstract. The central claim (bridge as dominant cause) rests on direct comparisons (0.998x matmul parity, 44x slowdown on small ops, recovery via patches) rather than any self-referential reduction. Self-citations, if present, are not load-bearing for any claimed result. This matches the default expectation for measurement-driven systems papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2026 , howpublished =
2026
-
[2]
Yoshimura, Takeshi and Chiba, Tatsuhiro and Sethi, Manish and Waddington, Daniel and Sundararaman, Swaminathan , title =. 2025 , eprint =. doi:10.48550/arXiv.2505.23072 , url =
-
[3]
Mohan, Apoorve and Ye, Mengmei and Franke, Hubertus and Srivatsa, Mudhakar and Liu, Zhuoran and Gonzalez, Nelson Mimura , title =. 2024 , pages =. doi:10.1109/CLOUD62652.2024.00028 , url =
-
[4]
2024 , url =
Zhong, Yinmin and Liu, Shengyu and Chen, Junda and Hu, Jianbo and Zhu, Yibo and Liu, Xuanzhe and Jin, Xin and Zhang, Hao , title =. 2024 , url =
2024
-
[5]
Blueprint, Bootstrap, and Bridge: A Security Look at NVIDIA GPU Confidential Computing
Gu, Zhongshu and Valdez, Enriquillo and Ahmed, Salman and Stephen, Julian James and Le, Michael and Jamjoom, Hani and Zhao, Shixuan and Lin, Zhiqiang , title =. 2026 , eprint =. doi:10.48550/arXiv.2507.02770 , note =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.02770 2026
-
[6]
2018 , pages =
Volos, Stavros and Vaswani, Kapil and Bruno, Rodrigo , title =. 2018 , pages =
2018
-
[7]
Confidential Computing on NVIDIA Hopper GPUs: A Per- formance Benchmark Study, September 2024
Zhu, Jianwei and Yin, Hang and Deng, Peng and Almeida, Aline and Zhou, Shunfan , title =. 2024 , eprint =. doi:10.48550/arXiv.2409.03992 , url =
-
[8]
Mo, Fan and Tarkhani, Zahra and Haddadi, Hamed , title =. 2024 , volume =. doi:10.1145/3670007 , url =
-
[9]
2023 , howpublished =
2023
-
[10]
Mart. 2025 , eprint =. doi:10.48550/arXiv.2505.16501 , note =
-
[11]
Tan, Yifan and Tan, Cheng and Mi, Zeyu and Chen, Haibo , title =. 2025 , eprint =. doi:10.48550/arXiv.2411.03357 , note =
-
[12]
SGLang: Efficient Execution of Structured Language Model Programs
Zheng, Lianmin and Yin, Liangsheng and Xie, Zhiqiang and Sun, Chuyue and Huang, Jeff and Yu, Cody Hao and Cao, Shiyi and Kozyrakis, Christos and Stoica, Ion and Gonzalez, Joseph E. and Barrett, Clark and Sheng, Ying , title =. 2024 , eprint =. doi:10.48550/arXiv.2312.07104 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.07104 2024
-
[13]
and Witchel, Emmett , title =
Hunt, Tyler and Jia, Zhipeng and Miller, Vance and Szekely, Ariel and Hu, Yige and Rossbach, Christopher J. and Witchel, Emmett , title =. 2020 , isbn =
2020
-
[14]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph E. and Zhang, Hao and Stoica, Ion , title =. 2023 , eprint =. doi:10.48550/arXiv.2309.06180 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.06180 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.