Neural Network Compression by Approximate Differential Equivalence
Pith reviewed 2026-06-28 17:28 UTC · model grok-4.3
The pith
Encoding a neural network as polynomial ODEs allows lumping of approximately equivalent neurons to compress the model while preserving accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a trained neural network can be represented as a polynomial ODE system, to which Approximate Forward Differential Equivalence can be applied to lump neurons with approximately the same induced dynamics into single representatives, yielding a compressed model that retains predictive accuracy controlled by the tolerance parameter ε. Evaluations on ground-truth synthetic data and public benchmarks confirm substantial parameter reduction with accuracy preservation superior to magnitude-based pruning and Wanda.
What carries the argument
Approximate Forward Differential Equivalence applied to a polynomial ODE encoding of the neural network, with ε controlling the approximation level
If this is right
- The method provides a smooth trade-off between model size and accuracy via a single parameter.
- Neurons are selected for aggregation based on functional dynamics similarity rather than local weight importance.
- The compressed models maintain performance on both synthetic and real regression tasks.
- Comparison shows consistent advantage over magnitude pruning and Wanda at similar compression ratios.
Where Pith is reading between the lines
- If the ODE encoding generalizes beyond the tested feedforward networks, the method could apply to recurrent or other architectures.
- Combining this lumping with existing pruning might yield hybrid compression strategies.
- The dynamical view could inspire new regularization techniques during training to encourage lumpable structures.
Load-bearing premise
The input-output behavior of the trained neural network is accurately represented by the polynomial ODE system so that lumping based on differential equivalence preserves the predictions.
What would settle it
Observe whether the accuracy of the lumped network on test data deviates substantially from the original beyond what the chosen ε tolerance would predict, or if the ODE encoding itself fails to reproduce the network's outputs closely.
Figures

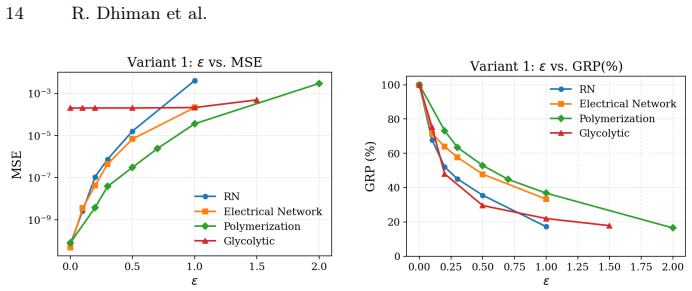
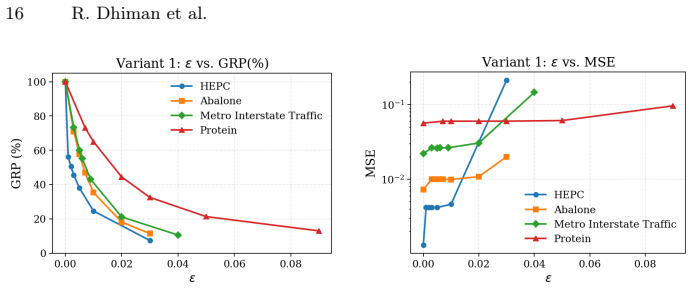
read the original abstract
Neural network compression is commonly achieved by pruning parameters based on local importance scores, e.g., magnitude-based pruning. We propose a complementary approach that compresses models by aggregating neurons with similar functional behavior rather than removing weights independently. Our method encodes a trained network as a polynomial ODE system and applies a lumping method called Approximate Forward Differential Equivalence to identify neurons with approximately matching induced dynamics. A single tolerance parameter, $\varepsilon$, controls the compression level and induces a smooth trade-off between model size and predictive accuracy. We evaluate the method on synthetic datasets derived from nonlinear dynamical systems with known ground-truth behavior and on public regression benchmarks. Across both settings, the proposed approach achieves substantial parameter reduction while preserving accuracy, and consistently compares favorably with magnitude-based pruning and Wanda at similar compression levels. These results suggest that differential equivalence-based aggregation is a principled and effective alternative to conventional weight-centric pruning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that encoding a trained neural network as a polynomial ODE system and applying Approximate Forward Differential Equivalence lumping (controlled by tolerance ε) aggregates neurons with similar dynamics, yielding substantial parameter reduction while preserving accuracy on synthetic nonlinear dynamical system data and public regression benchmarks; the method is reported to compare favorably to magnitude-based pruning and Wanda at similar compression levels.
Significance. If the ODE encoding step is shown to faithfully reproduce the original network's input-output behavior, the approach would provide a principled, dynamics-based compression technique complementary to weight pruning, with the attractive feature of a single tunable parameter inducing a smooth size-accuracy trade-off. The empirical evaluation across two distinct settings and the explicit comparison to established baselines are positive elements that would strengthen the case for functional aggregation over purely local importance scoring.
major comments (3)
- [experimental evaluation] The experimental sections provide no quantitative comparison (e.g., MSE, trajectory error, or output correlation) between the original network predictions and the trajectories of the encoded polynomial ODE system on either the synthetic dynamical-system datasets or the regression benchmarks. This verification is load-bearing for the central claim that subsequent lumping preserves predictive performance rather than the encoding approximation itself.
- [method] The method description does not specify the polynomial degree, the procedure for fitting the ODE coefficients from the trained network weights, or any a-priori error bound on the encoding step; without these, it is impossible to isolate the contribution of the Approximate Forward Differential Equivalence lumping from potential artifacts of the initial encoding.
- [results] Table or figure reporting the benchmark results (regression tasks) lacks error bars, statistical significance tests, or the precise ε values and resulting compression ratios used for each method, undermining the claim of consistent favorable comparison to magnitude pruning and Wanda.
minor comments (2)
- [abstract] Notation for the tolerance parameter ε and the lumping operator should be introduced with a clear definition before its first use in the abstract and method.
- [experimental setup] The synthetic data generation procedure (how ground-truth dynamical systems are turned into regression tasks) is only sketched; a short algorithmic outline or pseudocode would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify key areas for strengthening the manuscript's rigor and clarity. We will prepare a major revision that addresses each point, with specific additions to the experimental evaluation, method description, and results presentation.
read point-by-point responses
-
Referee: [experimental evaluation] The experimental sections provide no quantitative comparison (e.g., MSE, trajectory error, or output correlation) between the original network predictions and the trajectories of the encoded polynomial ODE system on either the synthetic dynamical-system datasets or the regression benchmarks. This verification is load-bearing for the central claim that subsequent lumping preserves predictive performance rather than the encoding approximation itself.
Authors: We agree that explicit verification of the encoding step is essential to attribute performance preservation to the lumping procedure. Although the manuscript emphasizes end-to-end accuracy after lumping, we will add a dedicated subsection in the revised version reporting quantitative metrics (MSE, trajectory error, and output correlation) comparing the original network predictions to those of the encoded polynomial ODE system on both the synthetic dynamical systems and regression benchmarks. This will isolate the encoding approximation from the effects of Approximate Forward Differential Equivalence. revision: yes
-
Referee: [method] The method description does not specify the polynomial degree, the procedure for fitting the ODE coefficients from the trained network weights, or any a-priori error bound on the encoding step; without these, it is impossible to isolate the contribution of the Approximate Forward Differential Equivalence lumping from potential artifacts of the initial encoding.
Authors: The referee correctly notes the absence of these implementation details. We will expand the method section in the revision to specify the polynomial degree (quadratic terms for the networks considered), the coefficient-fitting procedure (least-squares regression over sampled input-output trajectories derived from the trained weights), and any available a-priori or empirical error bounds on the encoding. These additions will enable readers to better separate encoding effects from the lumping contribution. revision: yes
-
Referee: [results] Table or figure reporting the benchmark results (regression tasks) lacks error bars, statistical significance tests, or the precise ε values and resulting compression ratios used for each method, undermining the claim of consistent favorable comparison to magnitude pruning and Wanda.
Authors: We acknowledge that the current results presentation would benefit from greater statistical detail and reproducibility information. In the revised manuscript we will update the relevant tables and figures to include error bars (standard deviation across repeated runs), report the exact ε values together with the resulting compression ratios for the proposed method and the baselines, and add statistical significance indicators for the performance comparisons where appropriate. revision: yes
Circularity Check
No circularity: derivation is self-contained against external benchmarks
full rationale
The paper encodes a trained NN as a polynomial ODE system then applies Approximate Forward Differential Equivalence lumping controlled by a single tolerance ε. No quoted step reduces a claimed prediction or uniqueness result to a fitted input, self-citation chain, or definitional tautology. All reported results are empirical comparisons against independent external baselines (magnitude pruning, Wanda) on synthetic dynamical systems and public regression benchmarks. The encoding step and lumping are presented as sequential procedures whose accuracy retention is measured directly rather than forced by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- ε
axioms (1)
- domain assumption A trained neural network can be encoded as a polynomial ODE system that captures its induced dynamics
Reference graph
Works this paper leans on
-
[1]
Journal of Logical and Algebraic Methods in Programming134, 100876 (2023)
Cardelli, L., Squillace, G., Tribastone, M., Tschaikowski, M., Vandin, A.: Formal lumping of polynomial differential equations through approximate equivalences. Journal of Logical and Algebraic Methods in Programming134, 100876 (2023)
2023
-
[2]
ACM SIGPLAN Notices51(1), 137–150 (2016)
Cardelli, L., Tribastone, M., Tschaikowski, M., Vandin, A.: Symbolic computation of differential equivalences. ACM SIGPLAN Notices51(1), 137–150 (2016)
2016
-
[3]
Cardelli, L., Tribastone, M., Tschaikowski, M., Vandin, A.: Erode: a tool for the evaluation and reduction of ordinary differential equations. In: Tools and Algo- rithms for the Construction and Analysis of Systems: 23rd International Confer- ence, TACAS 2017, Held as Part of the European Joint Conferences on Theory and Practice of Software, ETAPS 2017, U...
2017
-
[4]
Proceedings of the National Academy of Sciences 114(38), 10029–10034 (2017)
Cardelli, L., Tribastone, M., Tschaikowski, M., Vandin, A.: Maximal aggregation of polynomial dynamical systems. Proceedings of the National Academy of Sciences 114(38), 10029–10034 (2017)
2017
-
[5]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2024)
Cheng, H., Zhang, M., Shi, J.Q.: A survey on deep neural network pruning: Taxon- omy, comparison, analysis, and recommendations. IEEE Transactions on Pattern Analysis and Machine Intelligence (2024)
2024
-
[6]
PloS one 10(3), e0119821 (2015)
Daniels, B.C., Nemenman, I.: Efficient inference of parsimonious phenomenological models of cellular dynamics using s-systems and alternating regression. PloS one 10(3), e0119821 (2015)
2015
-
[7]
In: Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers)
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: Bert: Pre-training of deep bidi- rectional transformers for language understanding. In: Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). pp. 4171–4186 (2019)
2019
-
[8]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Dong, X., Huang, J., Yang, Y., Yan, S.: More is less: A more complicated network with less inference complexity. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 5840–5848 (2017)
2017
-
[9]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[10]
In: International Conference on Learning Representations (ICLR) (2019)
Frankle, J., Carbin, M.: The lottery ticket hypothesis: Finding sparse, trainable neural networks. In: International Conference on Learning Representations (ICLR) (2019)
2019
-
[11]
In: International Conference on Machine Learning
Frantar, E., Alistarh, D.: Sparsegpt: Massive language models can be accurately pruned in one-shot. In: International Conference on Machine Learning. pp. 10323– 10337. PMLR (2023)
2023
-
[12]
Han, S., Mao, H., Dally, W.J.: Deep compression: Compressing deep neural net- works with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[13]
Advances in neural information processing systems28 (2015)
Han, S., Pool, J., Tran, J., Dally, W.: Learning both weights and connections for efficient neural network. Advances in neural information processing systems28 (2015)
2015
-
[14]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016) 18 R. Dhiman et al
2016
-
[15]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, Y., Liu, P., Wang, Z., Hu, Z., Yang, Y.: Filter pruning via geometric median for deep convolutional neural networks acceleration. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4340–4349 (2019)
2019
-
[16]
In: Proceedings of the IEEE international conference on computer vision
He, Y., Zhang, X., Sun, J.: Channel pruning for accelerating very deep neural networks. In: Proceedings of the IEEE international conference on computer vision. pp. 1389–1397 (2017)
2017
-
[17]
UCI Machine Learning Repository (2006), DOI: https://doi.org/10.24432/C58K54
Hebrail, G., Berard, A.: Individual Household Electric Power Consumption. UCI Machine Learning Repository (2006), DOI: https://doi.org/10.24432/C58K54
-
[18]
UCI Machine Learning Repository (2019), DOI: https://doi.org/10.24432/C5X60B
Hogue, J.: Metro Interstate Traffic Volume. UCI Machine Learning Repository (2019), DOI: https://doi.org/10.24432/C5X60B
-
[19]
Kemeny,J.G.,Snell,J.L.,etal.:Finitemarkovchains,vol.26.vanNostrandPrince- ton, NJ (1969)
1969
-
[20]
Adam: A Method for Stochastic Optimization
Kingma, D.P.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[21]
arXiv preprint arXiv:2010.07611 (2020)
Lee, J., Park, S., Mo, S., Ahn, S., Shin, J.: Layer-adaptive sparsity for the magnitude-based pruning. arXiv preprint arXiv:2010.07611 (2020)
-
[22]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Lin, J., Yin, H., Ping, W., Molchanov, P., Shoeybi, M., Han, S.: Vila: On pre- training for visual language models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 26689–26699 (2024)
2024
-
[23]
In: International Conference on Machine Learning
Liu, L., Zhang, S., Kuang, Z., Zhou, A., Xue, J.H., Wang, X., Chen, Y., Yang, W., Liao, Q., Zhang, W.: Group fisher pruning for practical network compression. In: International Conference on Machine Learning. pp. 7021–7032. PMLR (2021)
2021
-
[24]
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Liu, Y., Zhang, K., Li, Y., Yan, Z., Gao, C., Chen, R., Yuan, Z., Huang, Y., Sun, H., Gao, J., et al.: Sora: A review on background, technology, limitations, and opportunities of large vision models. arXiv preprint arXiv:2402.17177 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
In: Proceedings of the IEEE international conference on computer vision
Luo, J.H., Wu, J., Lin, W.: Thinet: A filter level pruning method for deep neural network compression. In: Proceedings of the IEEE international conference on computer vision. pp. 5058–5066 (2017)
2017
-
[26]
In: Computer Vision–ECCV 2020: 16th European Confer- ence, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIII 16
Ma, X., Niu, W., Zhang, T., Liu, S., Lin, S., Li, H., Wen, W., Chen, X., Tang, J., Ma, K., et al.: An image enhancing pattern-based sparsity for real-time infer- ence on mobile devices. In: Computer Vision–ECCV 2020: 16th European Confer- ence, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIII 16. pp. 629–645. Springer (2020)
2020
-
[27]
Advances in neural information processing systems36, 21702–21720 (2023)
Ma, X., Fang, G., Wang, X.: Llm-pruner: On the structural pruning of large lan- guage models. Advances in neural information processing systems36, 21702–21720 (2023)
2023
-
[28]
Advances in Neural Information Processing Systems33, 17629–17640 (2020)
Meng, F., Cheng, H., Li, K., Luo, H., Guo, X., Lu, G., Sun, X.: Pruning filter in filter. Advances in Neural Information Processing Systems33, 17629–17640 (2020)
2020
-
[29]
UCI Machine Learning Repository (1994), DOI: https://doi.org/10.24432/C55C7W
Nash, W., Sellers, T., Talbot, S., Cawthorn, A., Ford, W.: Abalone. UCI Machine Learning Repository (1994), DOI: https://doi.org/10.24432/C55C7W
-
[30]
Ad- vances in Neural Information Processing Systems33, 2925–2934 (2020)
Orseau, L., Hutter, M., Rivasplata, O.: Logarithmic pruning is all you need. Ad- vances in Neural Information Processing Systems33, 2925–2934 (2020)
2020
-
[31]
Multistep Neural Networks for Data-driven Discovery of Nonlinear Dynamical Systems
Raissi, M., Perdikaris, P., Karniadakis, G.E.: Multistep neural networks for data- driven discovery of nonlinear dynamical systems. arXiv preprint arXiv:1801.01236 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[32]
UCI Machine Learning Repository
Rana, P.: Physicochemical Properties of Protein Tertiary Structure. UCI Machine Learning Repository (2013), DOI: https://doi.org/10.24432/C5QW3H
-
[33]
In: International conference of the Italian association for artificial intelligence
Ressi,D.,Romanello,R.,Piazza,C.,Rossi,S.:Neuralnetworksreductionvialump- ing. In: International conference of the Italian association for artificial intelligence. pp. 75–90. Springer (2022) Neural Network Compression by Approximate Differential Equivalence 19
2022
-
[34]
Neural Networks178, 106411 (2024)
Ressi, D., Romanello, R., Rossi, S., Piazza, C.: Compressing neural networks via formal methods. Neural Networks178, 106411 (2024)
2024
-
[35]
IEEE Transactions on Very Large Scale Integration (VLSI) Systems15(2), 135–148 (2007)
Rosenfeld, J., Friedman, E.G.: Design methodology for global resonant - tree clock distribution networks. IEEE Transactions on Very Large Scale Integration (VLSI) Systems15(2), 135–148 (2007)
2007
-
[36]
Advances in neural information processing systems33, 20378–20389 (2020)
Sanh, V., Wolf, T., Rush, A.: Movement pruning: Adaptive sparsity by fine-tuning. Advances in neural information processing systems33, 20378–20389 (2020)
2020
-
[37]
In: Proc
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: Proc. Int. Conf. Learn. Representations. pp. 1–14 (2015)
2015
-
[39]
A Simple and Effective Pruning Approach for Large Language Models
Sun, M., Liu, Z., Bair, A., Kolter, J.Z.: A simple and effective pruning approach for large language models. arXiv preprint arXiv:2306.11695 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Advances in neural information processing systems33, 6377–6389 (2020)
Tanaka,H.,Kunin,D.,Yamins,D.L.,Ganguli,S.:Pruningneuralnetworkswithout any data by iteratively conserving synaptic flow. Advances in neural information processing systems33, 6377–6389 (2020)
2020
-
[41]
arXiv preprint arXiv:2012.09243 (2020)
Wang, H., Qin, C., Zhang, Y., Fu, Y.: Neural pruning via growing regularization. arXiv preprint arXiv:2012.09243 (2020)
-
[42]
Multimedia Systems30(3), 122 (2024)
Xiong, L., Chen, Q., Huang, J., Huang, X., Huang, P., Wei, S.: Students and teachers learning together: a robust training strategy for neural network pruning. Multimedia Systems30(3), 122 (2024)
2024
-
[43]
Advances in neural information processing systems32(2019)
You, Z., Yan, K., Ye, J., Ma, M., Wang, P.: Gate decorator: Global filter pruning method for accelerating deep convolutional neural networks. Advances in neural information processing systems32(2019)
2019
-
[44]
Advances in Neural Information Processing Systems 34, 2695–2706 (2021)
Zhang, Y., Wang, H., Qin, C., Fu, Y.: Aligned structured sparsity learning for effi- cient image super-resolution. Advances in Neural Information Processing Systems 34, 2695–2706 (2021)
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.