Single-Thread JPEG Decoder Benchmarks Mis-Evaluate ML Data Loaders
Pith reviewed 2026-05-21 09:07 UTC · model grok-4.3
The pith
Single-thread JPEG decoder benchmarks can misrank options for use in ML DataLoaders.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
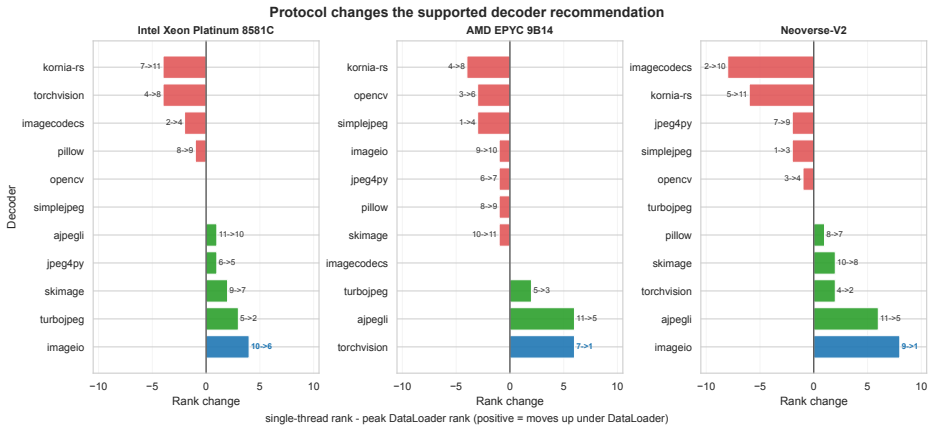
The evaluation protocol changes the supported conclusion about which JPEG decoder is fastest. On Neoverse V2, imageio ranks ninth in single-thread throughput but joins the top tier with torchvision in DataLoader tests. On Zen 4, torchvision moves from seventh in single-thread to the top DataLoader tier. On Neoverse N1, imagecodecs leads single-thread but falls to fifth at peak DataLoader throughput. For PyTorch DataLoader workloads, torchvision and simplejpeg form the strongest zero-skip tier, while OpenCV stays above 90 percent of the platform-local winner on every CPU.
What carries the argument
The side-by-side measurement of single-thread decode throughput versus PyTorch DataLoader throughput across worker counts from 0 to 8 on matched 16 vCPU instances of different CPU architectures.
If this is right
- On some platforms, decoders that appear slow in isolation become competitive or best when used with multiple DataLoader workers.
- Worker-count conclusions differ between similar CPUs such as Zen 4 and Zen 5.
- TensorFlow exhibits a large single-thread performance penalty on ARM CPUs compared with other decoders.
- OpenCV remains a robust fallback that stays within 10 percent of the local winner across all tested architectures.
- Strict native JPEG decoders reject the same rare malformed files from the ImageNet validation set.
Where Pith is reading between the lines
- Benchmarking tools for ML data pipelines should default to DataLoader-wrapped tests instead of isolated microbenchmarks.
- Similar re-rankings could appear with other image formats or video loaders in multi-worker settings.
- Production pipelines that add I/O or caching layers may shift relative decoder performance further.
- Library maintainers could provide architecture-specific decoder recommendations based on DataLoader measurements.
Load-bearing premise
The assumption that single-thread, in-memory decoding of a full dataset accurately reflects the relative performance of decoders inside actual multi-process ML training pipelines.
What would settle it
Running the DataLoader benchmark on Neoverse V2 and finding that imageio stays below the top tier while single-thread rankings remain unchanged would show the protocol does not alter conclusions.
Figures



read the original abstract
JPEG decode is routine ML infrastructure, but Python decoder choices are often justified by single-process, single-thread microbenchmarks. We audit this evaluation assumption with thirteen Python-accessible JPEG decode paths on five matched 16 vCPU Google Cloud CPUs: Intel Emerald Rapids, AMD Zen 4, AMD Zen 5, ARM Neoverse V2, and ARM Neoverse N1. ImageNet validation is the workload, not a new dataset contribution: each run decodes the full 50,000-image split from memory and reports single-thread throughput for all decoders, PyTorch \texttt{DataLoader} throughput for eligible decoders at worker counts $\{0,2,4,8\}$, and decoder skip behavior. The evaluation protocol changes the supported conclusion. On Neoverse V2, \texttt{imageio} is ninth in single-thread throughput yet lands in the top DataLoader tier with \texttt{torchvision}; on Zen 4, \texttt{torchvision} rises from seventh single-thread to the top measured DataLoader tier; on Neoverse N1, \texttt{imagecodecs} is the single-thread leader but fifth at peak DataLoader throughput. We also find that worker-count conclusions differ between Zen 4 and Zen 5, TensorFlow has a large single-thread ARM penalty, and strict native JPEG decoders/wrappers reject the same rare ImageNet JPEG. For PyTorch DataLoader workloads, \texttt{torchvision} and \texttt{simplejpeg} form the strongest measured zero-skip tier: \texttt{torchvision} has the highest mean normalized throughput, while \texttt{simplejpeg} has the highest minimum. OpenCV remains a robust general-purpose fallback above 90\% of the platform-local winner on every tested CPU. We release raw JSON, generated tables/figures, and an executable local/cloud benchmark framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript audits the assumption that single-thread microbenchmarks reliably predict JPEG decoder performance in ML data pipelines. It evaluates thirteen Python-accessible JPEG decoders on five 16-vCPU platforms (Intel Emerald Rapids, AMD Zen 4/5, ARM Neoverse V2/N1) using the full 50 000-image ImageNet validation set decoded from memory. Throughput is reported for single-thread execution and for PyTorch DataLoader at worker counts {0,2,4,8}, together with skip behavior. The central empirical result is that decoder rankings and worker-count conclusions change between the two protocols; concrete examples include imageio rising from ninth to top-tier on Neoverse V2, torchvision rising from seventh to first on Zen 4, and imagecodecs dropping from first to fifth on Neoverse N1. The authors also note platform-specific effects (TensorFlow ARM penalty, differing Zen 4 vs. Zen 5 scaling) and release raw JSON, generated tables, and an executable benchmark framework.
Significance. If the measurements hold, the work is significant for ML systems research because it supplies reproducible, multi-architecture evidence that single-thread benchmarks can support different engineering decisions than DataLoader-based evaluation. The release of raw data and code, the use of the complete ImageNet split rather than a toy subset, and the explicit comparison of zero-skip versus skip-tolerant decoders constitute concrete strengths that allow the community to verify and extend the findings. The identification of torchvision and simplejpeg as strong zero-skip options and OpenCV as a robust cross-platform fallback provides immediately actionable guidance for practitioners.
minor comments (3)
- [§3] §3 (Experimental Setup): the exact mechanism used to preload the 50 k images into memory before timing begins is described only at high level; a short paragraph or pseudocode listing the preload loop and any explicit cache-flush steps would remove ambiguity about possible OS-level caching effects.
- [Table 2] Table 2 and Figure 3: the normalization basis for the 'mean normalized throughput' column is stated in the caption but the per-platform winner used for scaling is not listed; adding a one-line footnote or an extra column with the absolute winner throughput would improve readability.
- [§5.2] §5.2 (Worker-count scaling): the observation that optimal worker count differs between Zen 4 and Zen 5 is interesting but the text does not report the raw per-worker throughput numbers that underlie the claim; including those values (or a supplementary table) would make the platform-specific conclusion easier to verify.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript, recognition of its significance for ML systems research, and recommendation for minor revision. We appreciate the emphasis on the reproducible multi-architecture evaluation, use of the full ImageNet validation set, and the actionable guidance for practitioners regarding decoder choices.
Circularity Check
No significant circularity
full rationale
This is a pure empirical measurement study that reports direct throughput observations from benchmark runs on the full ImageNet validation set across five CPU platforms. There are no equations, derivations, fitted parameters, predictions, ansatzes, or self-citations that could reduce any claim to its own inputs by construction. All rank changes and tier conclusions follow immediately from the measured single-thread versus DataLoader numbers at varying worker counts, with raw JSON and code released for verification. The central claim is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption ImageNet validation set from memory is a representative workload for ML JPEG decoding without introducing decoder-specific biases
- domain assumption Single-process and DataLoader measurements isolate decoder performance from other system effects
Reference graph
Works this paper leans on
-
[1]
TensorFlow.https://www.tensorflow.org, 2024
Google Brain Team. TensorFlow.https://www.tensorflow.org, 2024. Accessed 2026-05-02
work page 2024
-
[2]
Google Cloud compute engine machine families (c4 / c4d / c4a / t2a documentation)
Google Cloud. Google Cloud compute engine machine families (c4 / c4d / c4a / t2a documentation). https://cloud.google.com/compute/docs/machine-types, 2026. Accessed 2026-05-02
work page 2026
-
[3]
ajpegli: Python bindings for Google JPEGli.https://github.com/dKosarevsky/ ajpegli, 2026
Dmitry Kosarevsky. ajpegli: Python bindings for Google JPEGli.https://github.com/dKosarevsky/ ajpegli, 2026. Accessed 2026-05-20
work page 2026
-
[4]
FFCV: Accelerating training by removing data bottlenecks
Guillaume Leclerc, Andrew Ilyas, Logan Engstrom, Sung Min Park, Hadi Salman, and Aleksander Mądry. FFCV: Accelerating training by removing data bottlenecks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12011–12020, 2023
work page 2023
-
[5]
Bob McElrath and Thomas Breuel. Webdataset: a PyTorch dataset (WebDataset) designed for streaming training.https://github.com/webdataset/webdataset, 2021. Accessed 2026-05-02
work page 2021
-
[6]
NVIDIA Corporation. NVIDIA DALI: GPU-accelerated data loading and image augmentation.https: //developer.nvidia.com/dali, 2024. Accessed 2026-05-02
work page 2024
-
[7]
nvJPEG: GPU-accelerated JPEG decode
NVIDIA Corporation. nvJPEG: GPU-accelerated JPEG decode. https://developer.nvidia.com/ nvjpeg, 2024. Accessed 2026-05-02
work page 2024
-
[8]
Open source computer vision library (OpenCV).https://opencv.org, 2024
OpenCV Team. Open source computer vision library (OpenCV).https://opencv.org, 2024. Accessed 2026-05-02
work page 2024
-
[9]
Pillow: the friendly PIL fork.https://pillow.readthedocs.io/en/stable/, 2024
Pillow Developers. Pillow: the friendly PIL fork.https://pillow.readthedocs.io/en/stable/, 2024. Accessed 2026-05-02
work page 2024
-
[10]
PyTorch.https://pytorch.org, 2024
PyTorch Team. PyTorch.https://pytorch.org, 2024. Accessed 2026-05-02
work page 2024
-
[11]
Torchdata.https://github.com/pytorch/data, 2024
PyTorch Team. Torchdata.https://github.com/pytorch/data, 2024. Accessed 2026-05-02
work page 2024
-
[12]
torchvision.https://pytorch.org/vision, 2024
PyTorch Team. torchvision.https://pytorch.org/vision, 2024. Accessed 2026-05-02
work page 2024
-
[13]
Kornia: differentiable computer vision in PyTorch.https://kornia.github.io, 2024
Edgar Riba, Dmytro Mishkin, Daniel Ponsa, Ethan Rublee, and Gary Bradski. Kornia: differentiable computer vision in PyTorch.https://kornia.github.io, 2024. Accessed 2026-05-02
work page 2024
-
[14]
ImageNet Large Scale Visual Recognition Challenge,
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. Imagenet large scale visual recognition challenge.International Journal of Computer Vision, 115(3):211–252, 2015. doi: 10.1007/s11263-015-0816-y
-
[15]
libjpeg-turbo.https://libjpeg-turbo.org, 2024
The libjpeg-turbo Project. libjpeg-turbo.https://libjpeg-turbo.org, 2024. Accessed 2026-05-02. 8 A Generated evidence Every numeric table in the Markdown companion and every paper figure is generated from the platform/library JSON files underoutput/ by tools/paper_assets.py. Each result file stores platform metadata, timed throughput samples, sample stand...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.