Scaling with Confidence: Calibrating Confidence of LLMs for Adaptive Test Time Scaling
Pith reviewed 2026-07-03 14:47 UTC · model grok-4.3
The pith
LLMs trained with RL rewards for both answer correctness and confidence calibration produce verbalized confidence that supports efficient adaptive test-time scaling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
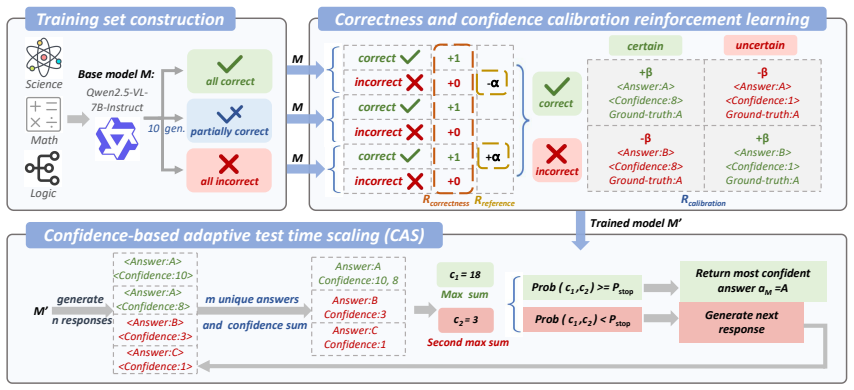
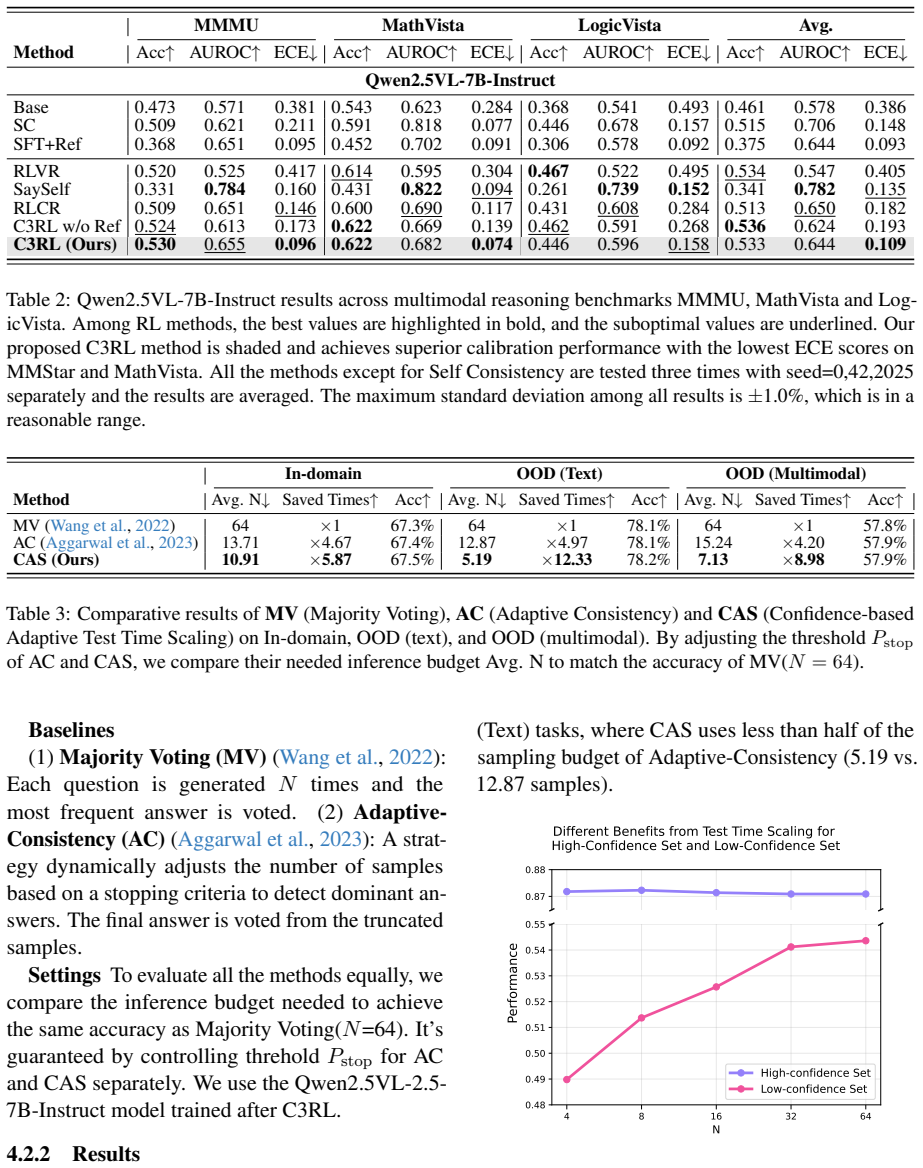
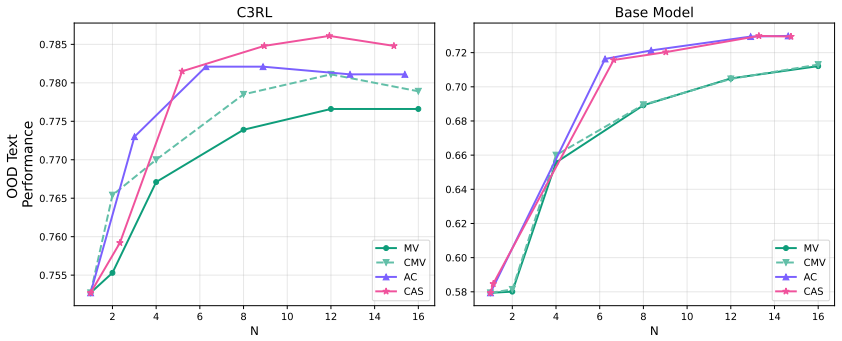
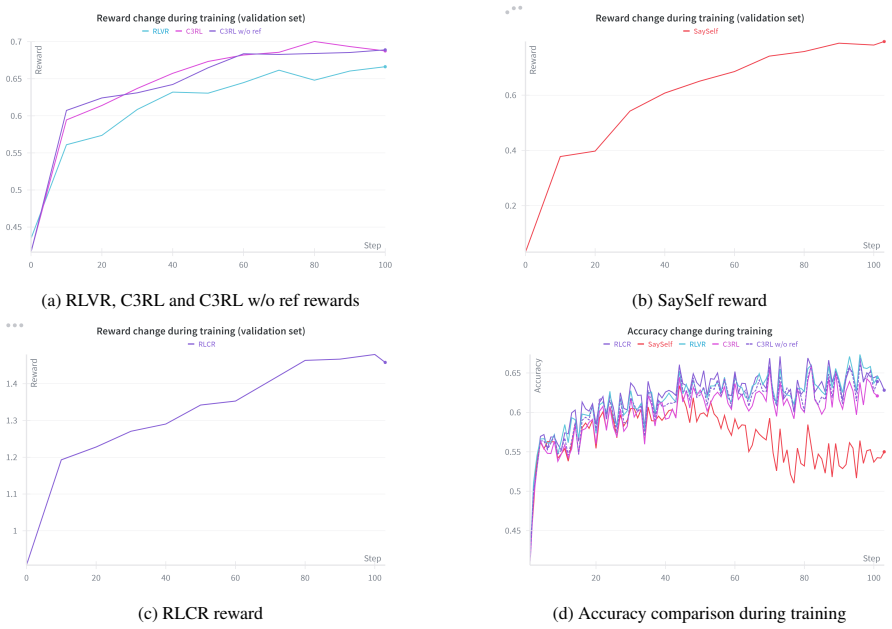
C3RL integrates three reward signals in reinforcement learning—response correctness, calibration of verbalized confidence with accuracy, and dataset-informed reference accuracy—to train LLMs that express confidence more reliably. The resulting well-calibrated confidence enables CAS, an adjustable inference-time strategy that allocates computational resources according to response confidence, surpassing majority voting on in-domain and out-of-domain datasets while cutting the inference budget by up to 12.33 times.
What carries the argument
C3RL, a reinforcement learning algorithm that combines correctness, calibration, and dataset-informed reference accuracy rewards to train accurate verbalized confidence.
If this is right
- C3RL raises both performance and calibration scores over prior methods across the eight evaluated datasets.
- CAS exceeds majority voting accuracy on in-domain and out-of-domain tasks.
- CAS reaches equivalent performance using up to 12.33 times less inference budget than majority voting.
- The combination of C3RL and CAS supports more reliable and lower-cost LLM deployment.
Where Pith is reading between the lines
- If the calibration property transfers to safety-critical domains, it could allow single-model inference to replace ensembles in settings where overconfidence carries high cost.
- The same reward structure might be tested on base models other than those used in the paper to check whether the efficiency gains remain stable.
- Adaptive scaling driven by verbalized confidence could be combined with other test-time techniques such as retrieval or tool use to further reduce average compute.
Load-bearing premise
The three reward components can be combined in RL training without introducing new trade-offs that reduce the reported gains in calibration and efficiency.
What would settle it
An experiment on a held-out dataset in which C3RL training either worsens calibration metrics or lowers accuracy relative to standard correctness-only RL.
Figures
read the original abstract
Training large language models (LLMs) with reinforcement learning (RL) has significantly advanced their performance on reasoning and question-answering tasks. However, prevailing RL reward designs typically prioritize response correctness, neglecting to incentivize models to express their confidence accurately. This leads to a critical problem: performance gains are often accompanied by poor calibration between confidence and accuracy, misleading models to overconfidently hallucinate when uncertain. To address this limitation, we propose $\textbf{C}$orrectness and $\textbf{C}$onfidence $\textbf{C}$alibration $\textbf{R}$einforcement $\textbf{L}$earning ($\textbf{C3RL}$), a novel RL algorithm integrating correctness, calibration and dataset-informed reference accuracy rewards together. Comprehensive evaluation across 8 text and multimodal datasets demonstrates that C3RL enhances calibration without sacrificing accuracy, outperforming the current state-of-the-art method in both performance and calibration metrics. Utilizing the well-calibrated verbalized confidence from C3RL, we further introduce $\textbf{C}$onfidence-based $\textbf{A}$daptive Test Time $\textbf{S}$caling ($\textbf{CAS}$), an adjustable inference-time strategy that allocates computational resources based on response confidence. Experiments show that CAS surpasses majority voting on both in-domain and out-of-domain datasets while reducing the inference budget by up to 12.33 times. We believe the synergy of C3RL and CAS paves the way for deploying more reliable and resource-efficient LLMs. The code, data and models will be released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes C3RL, a reinforcement learning algorithm that augments standard correctness rewards with explicit calibration and dataset-informed reference accuracy terms to train LLMs to produce better-calibrated verbalized confidence scores. It reports that C3RL improves calibration metrics across 8 text and multimodal datasets without accuracy degradation and outperforms prior SOTA methods. The paper further introduces CAS, a test-time scaling method that uses the resulting confidence scores to adaptively allocate inference compute, claiming superior performance to majority voting on in- and out-of-domain data while reducing the inference budget by up to 12.33×.
Significance. If the central claims hold, the work would provide a practical route to simultaneously improving reliability (via calibration) and efficiency (via adaptive scaling) for reasoning LLMs. The combination of an RL training objective with a downstream inference-time controller is a potentially useful contribution, especially if the calibration gains prove robust rather than the product of per-dataset tuning.
major comments (2)
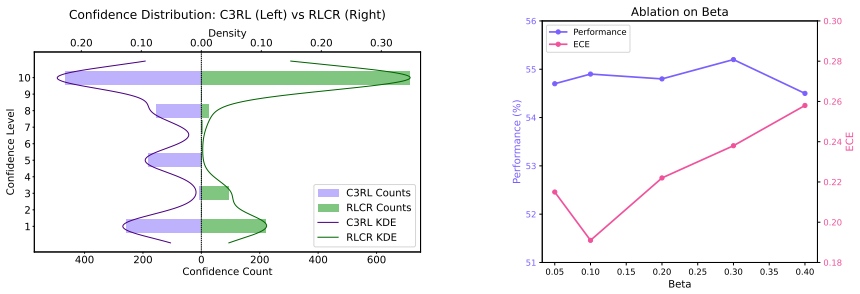
- [§3] §3 (C3RL objective): The manuscript does not provide the explicit formulation for combining the three reward terms (correctness, calibration, dataset-informed reference accuracy). It is unclear whether the terms are normalized, how they are weighted (fixed coefficients, learned, or scheduled), or whether any post-training adjustments are applied. This detail is load-bearing for the claim that calibration improves without new trade-offs or dataset-specific tuning.
- [§4.2, Table 2] §4.2 and Table 2: The reported gains in calibration metrics (e.g., ECE, Brier score) and the downstream CAS budget reductions are presented without ablations that isolate the contribution of each reward component or that test sensitivity to the (unspecified) weighting scheme. Without these controls it is impossible to determine whether the improvements are attributable to the proposed multi-term objective or to implicit hyperparameter search.
minor comments (2)
- [Abstract, §1] The abstract and introduction repeatedly use the phrase “dataset-informed reference accuracy” without an early definition or pointer to the precise equation that implements it.
- [Figure 3] Figure 3 (CAS scaling curves) would benefit from error bars or shaded regions indicating variance across random seeds or prompt variations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to provide the requested details and experiments.
read point-by-point responses
-
Referee: [§3] §3 (C3RL objective): The manuscript does not provide the explicit formulation for combining the three reward terms (correctness, calibration, dataset-informed reference accuracy). It is unclear whether the terms are normalized, how they are weighted (fixed coefficients, learned, or scheduled), or whether any post-training adjustments are applied. This detail is load-bearing for the claim that calibration improves without new trade-offs or dataset-specific tuning.
Authors: We agree that the explicit formulation must be stated. In the revised manuscript we will add the precise equation in §3: the total reward is the normalized linear combination R = (R_correct + R_calib + 0.5 * R_ref) / 2.5, where each term is scaled to [0,1], the coefficients are fixed (not learned or scheduled), and no post-training adjustments are used. This formulation was applied uniformly across all datasets. revision: yes
-
Referee: [§4.2, Table 2] §4.2 and Table 2: The reported gains in calibration metrics (e.g., ECE, Brier score) and the downstream CAS budget reductions are presented without ablations that isolate the contribution of each reward component or that test sensitivity to the (unspecified) weighting scheme. Without these controls it is impossible to determine whether the improvements are attributable to the proposed multi-term objective or to implicit hyperparameter search.
Authors: We acknowledge the absence of these controls. In the revision we will add an ablation study (new table or appendix) that removes each reward term in turn and varies the reference-accuracy coefficient on a subset of datasets, confirming that the full objective drives the reported gains and that performance remains stable under moderate weight perturbations. revision: yes
Circularity Check
No circularity in derivation or reward formulation
full rationale
The provided abstract and description contain no equations, fitting procedures, or self-citations that reduce any claimed result (C3RL calibration gains or CAS budget reductions) to inputs by construction. The method is presented as an empirical RL integration of three reward signals whose combination is asserted to work without trade-offs, but no derivation chain, uniqueness theorem, or ansatz is shown that would trigger any of the enumerated circularity patterns. Claims rest on external dataset evaluations rather than self-referential definitions or renamed known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[2]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
ACM computing surveys , volume=
Survey of hallucination in natural language generation , author=. ACM computing surveys , volume=. 2023 , publisher=
2023
-
[4]
International conference on machine learning , pages=
On calibration of modern neural networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[5]
Language Models (Mostly) Know What They Know
Language Models (Mostly) Know What They Know , author=. arXiv preprint arXiv:2207.05221 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Fact-and-Reflection Improves Confidence Calibration of Large Language Models,
Fact-and-reflection (FaR) improves confidence calibration of large language models , author=. arXiv preprint arXiv:2402.17124 , year=
-
[7]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Self-consistency improves chain of thought reasoning in language models , author=. arXiv preprint arXiv:2203.11171 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
2024 , email =
Tülu 3: Pushing Frontiers in Open Language Model Post-Training , author =. 2024 , email =
2024
-
[9]
Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs
Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms , author=. arXiv preprint arXiv:2306.13063 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
arXiv preprint arXiv:2506.18183 , year =
Reasoning about Uncertainty: Do Reasoning Models Know When They Don't Know? , author=. arXiv preprint arXiv:2506.18183 , year=
-
[11]
2025 , publisher=
Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models , author=. 2025 , publisher=
2025
-
[12]
arXiv preprint arXiv:2401.15449 , year=
Learning to trust your feelings: Leveraging self-awareness in llms for hallucination mitigation , author=. arXiv preprint arXiv:2401.15449 , year=
-
[13]
arXiv preprint (2023), https://arxiv.org/abs/2305.14975, arXiv:2305.14975
Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback , author=. arXiv preprint arXiv:2305.14975 , year=
-
[14]
On Verbalized Confidence Scores for LLMs
On verbalized confidence scores for llms , author=. arXiv preprint arXiv:2412.14737 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
ICML , year=
Calibrate Before Use: Improving Few-Shot Performance of Language Models , author=. ICML , year=
-
[16]
arXiv preprint arXiv:2505.14489 , year=
Reasoning models better express their confidence , author=. arXiv preprint arXiv:2505.14489 , year=
-
[17]
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation , author=. arXiv preprint arXiv:2302.09664 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
The Thirteenth International Conference on Learning Representations , year=
Improving uncertainty estimation through semantically diverse language generation , author=. The Thirteenth International Conference on Learning Representations , year=
-
[19]
arXiv preprint arXiv:2502.18581 , year=
Scalable best-of-n selection for large language models via self-certainty , author=. arXiv preprint arXiv:2502.18581 , year=
-
[20]
Teaching Models to Express Their Uncertainty in Words
Teaching models to express their uncertainty in words , author=. arXiv preprint arXiv:2205.14334 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
arXiv preprint arXiv:2311.09677 , volume=
R-tuning: Teaching large language models to refuse unknown questions , author=. arXiv preprint arXiv:2311.09677 , volume=
-
[22]
arXiv preprint arXiv:2405.20974 , year=
Sayself: Teaching llms to express confidence with self-reflective rationales , author=. arXiv preprint arXiv:2405.20974 , year=
-
[23]
arXiv e-prints , pages=
Rewarding doubt: A reinforcement learning approach to confidence calibration of large language models , author=. arXiv e-prints , pages=
-
[24]
Advances in Neural Information Processing Systems , volume=
LACIE: Listener-aware finetuning for calibration in large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
arXiv preprint arXiv:2410.09724 , year=
Taming overconfidence in llms: Reward calibration in rlhf , author=. arXiv preprint arXiv:2410.09724 , year=
-
[26]
arXiv preprint arXiv:2204.07931 , year=
On the origin of hallucinations in conversational models: Is it the datasets or the models? , author=. arXiv preprint arXiv:2204.07931 , year=
-
[27]
arXiv preprint arXiv:2305.14552 , year=
Sources of hallucination by large language models on inference tasks , author=. arXiv preprint arXiv:2305.14552 , year=
-
[28]
arXiv preprint arXiv:2307.02394 , year=
Won't get fooled again: Answering questions with false premises , author=. arXiv preprint arXiv:2307.02394 , year=
- [29]
-
[30]
Beyond Binary Rewards: Training
Damani, Mehul and Puri, Isha and Slocum, Stewart and Shenfeld, Idan and Choshen, Leshem and Kim, Yoon and Andreas, Jacob , journal=. Beyond Binary Rewards: Training. 2025 , volume=
2025
-
[31]
arXiv preprint arXiv:2305.11860 , year=
Let's Sample Step by Step: Adaptive-Consistency for Efficient Reasoning and Coding with LLMs , author=. arXiv preprint arXiv:2305.11860 , year=
-
[32]
arXiv preprint arXiv:2312.12832 , year=
Escape Sky-high Cost: Early-stopping Self-Consistency for Multi-step Reasoning , author=. arXiv preprint arXiv:2312.12832 , year=
-
[33]
2025 , publisher=
Deep Think with Confidence , author=. 2025 , publisher=
2025
-
[34]
2025 , journal=
Sampling-Efficient Test-Time Scaling: Self-Estimating the Best-of-\(N\) Sampling in Early Decoding , author=. 2025 , journal=
2025
-
[35]
arXiv preprint , year=
Qwen2.5-VL Technical Report , author=. arXiv preprint , year=
-
[36]
arXiv preprint , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. arXiv preprint , year=
-
[37]
Hugging Face repository , howpublished =
Jia LI, Edward Beeching, Lewis Tunstall et al , title =. Hugging Face repository , howpublished =. 2024 , publisher =
2024
-
[38]
Xueguang Ma and Qian Liu and Dongfu Jiang and Ge Zhang and Zejun Ma and Wenhu Chen , year=. arXiv:2505.14652 , url=
-
[39]
Tian, Jidong and Li, Yitian and Chen, Wenqing and Xiao, Liqiang and He, Hao and Jin, Yaohui. Diagnosing the First-Order Logical Reasoning Ability Through L ogic NLI. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.303
-
[40]
Logiqa: A challenge dataset for machine reading comprehension with logical reasoning , author=. arXiv preprint arXiv:2007.08124 , year=
-
[41]
2023 , eprint=
AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models , author=. 2023 , eprint=
2023
-
[42]
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems , author=. arXiv preprint arXiv:2402.14008 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Measuring Massive Multitask Language Understanding , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[44]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Aligning AI With Shared Human Values , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[45]
Proceedings of CVPR , year=
MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI , author=. Proceedings of CVPR , year=
-
[46]
The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
Measuring Multimodal Mathematical Reasoning with MATH-Vision Dataset , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[47]
MathCoder-
Ke Wang and Junting Pan and Linda Wei and Aojun Zhou and Weikang Shi and Zimu Lu and Han Xiao and Yunqiao Yang and Houxing Ren and Mingjie Zhan and Hongsheng Li , booktitle=. MathCoder-. 2025 , url=
2025
-
[48]
International Conference on Learning Representations (ICLR) , year =
Lu, Pan and Bansal, Hritik and Xia, Tony and Liu, Jiacheng and Li, Chunyuan and Hajishirzi, Hannaneh and Cheng, Hao and Chang, Kai-Wei and Galley, Michel and Gao, Jianfeng , title =. International Conference on Learning Representations (ICLR) , year =
-
[49]
2024 , journal=
LogicVista: A Multimodal LLM Logical Reasoning Benchmark in Visual Contexts , author=. 2024 , journal=
2024
-
[50]
FOLIO: Natural Language Reasoning with First-Order Logic , author =. arXiv preprint arXiv:2209.00840 , url =
-
[51]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Are We on the Right Way for Evaluating Large Vision-Language Models?
Are We on the Right Way for Evaluating Large Vision-Language Models? , author=. arXiv preprint arXiv:2403.20330 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
2024 , eprint=
Alignment for Honesty , author=. 2024 , eprint=
2024
-
[54]
2024 , eprint =
HybridFlow: Unifying Training and Inference for Large Language Models via Hybrid Programming , author =. 2024 , eprint =
2024
-
[55]
2024 , howpublished =
verl , author =. 2024 , howpublished =
2024
-
[56]
Beyond Correctness: Confidence-Aware Reward Modeling for Enhancing Large Language Model Reasoning
He, Qianxi and Ren, Qingyu and Lei, Shanzhe and Wang, Xuhong and Wang, Yingchun. Beyond Correctness: Confidence-Aware Reward Modeling for Enhancing Large Language Model Reasoning. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1385
-
[57]
2025 , eprint=
Trust Me, I'm Wrong: LLMs Hallucinate with Certainty Despite Knowing the Answer , author=. 2025 , eprint=
2025
-
[58]
2024 , howpublished =
Llama-3.2-3B-Instruct , author =. 2024 , howpublished =
2024
-
[59]
2023 , eprint=
ALCUNA: Large Language Models Meet New Knowledge , author=. 2023 , eprint=
2023
-
[60]
C ommonsense QA : A Question Answering Challenge Targeting Commonsense Knowledge
Talmor, Alon and Herzig, Jonathan and Lourie, Nicholas and Berant, Jonathan. C ommonsense QA : A Question Answering Challenge Targeting Commonsense Knowledge. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/...
-
[61]
Did Aristotle Use a Laptop? A Question Answering Benchmark with Implicit Reasoning Strategies
Geva, Mor and Khashabi, Daniel and Segal, Elad and Khot, Tushar and Roth, Dan and Berant, Jonathan. Did Aristotle Use a Laptop? A Question Answering Benchmark with Implicit Reasoning Strategies. Transactions of the Association for Computational Linguistics. 2021. doi:10.1162/tacl_a_00370
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.