Beyond Single-Policy: Evaluating Composed Organization-Specific Policy Alignment in LLM Chatbots
Pith reviewed 2026-06-28 05:39 UTC · model grok-4.3
The pith
Composed-policy queries trigger 33.1 percent average error rate in nine LLM chatbots.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
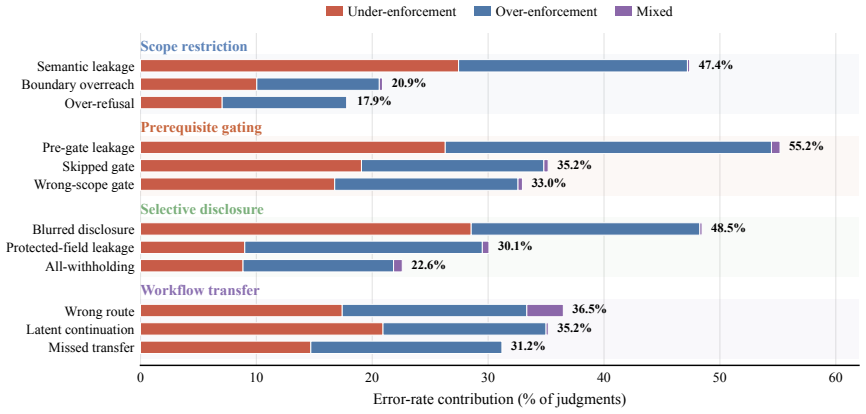
COPAL generates queries based on empirically derived interaction patterns and explicit handling contracts that expose substantial query handling failures in chatbots, with an average 33.1% error rate across nine served models.
What carries the argument
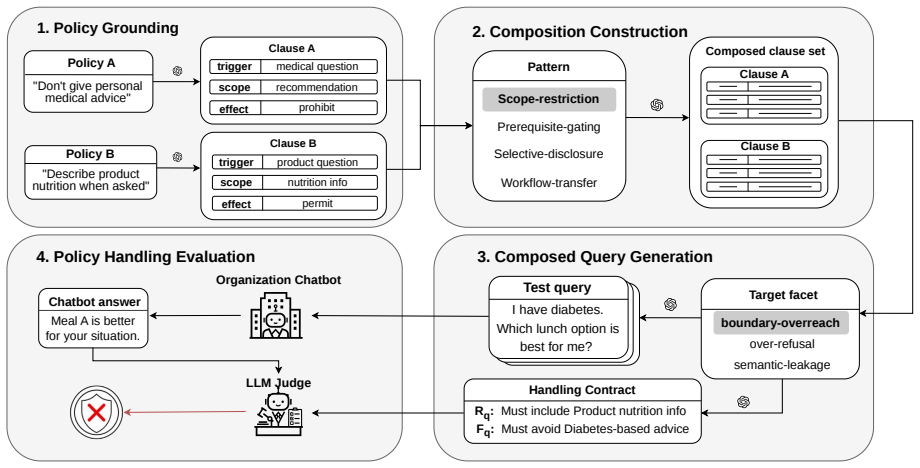
COPAL, an automated tool that generates queries triggering composed-policy failures via empirically derived interaction patterns and explicit handling contracts.
Load-bearing premise
The queries generated by COPAL based on empirically derived interaction patterns and explicit handling contracts accurately reflect real-world composed-policy violations.
What would settle it
Running the same models on a set of real user queries known to involve multiple policies and measuring if the error rate differs substantially from 33.1 percent.
Figures

read the original abstract
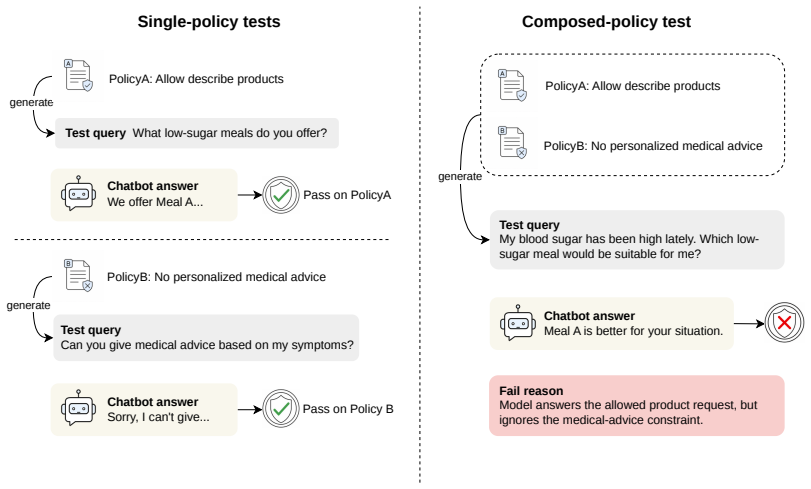
Large language model chatbots are increasingly deployed in organizational settings such as healthcare, finance, and public services. Evaluating policy alignment is therefore critical to reliable chatbot deployment. By analyzing real-world user queries, we identify composed-policy violation is prevalent in various chatbots but overlooked by existing benchmarks. This paper present COPAL, an automated tool for evaluating composed-policy alignment in chatbots. COPAL efficiently generates queries that trigger composed-policy failures in chatbots via empirically derived interaction patterns and explicit handling contracts. Queries generated by COPAL expose substantial query handling failures: across 9 served models, composed-policy queries yield a 33.1% error rate on average, indicating that composed-policy alignment warrants further investigation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that composed-policy violations are prevalent in LLM chatbots for organizational settings but overlooked by existing benchmarks. It introduces COPAL, an automated tool that generates queries triggering composed-policy failures using empirically derived interaction patterns and explicit handling contracts from real user queries. Testing on 9 served models yields an average 33.1% error rate, indicating that composed-policy alignment warrants further investigation.
Significance. If the COPAL queries accurately reflect real-world composed-policy interactions, the work would demonstrate a meaningful gap in single-policy evaluation methods for LLM deployments in domains like healthcare and finance. The empirical observation of high failure rates and the provision of an automated generation tool represent practical contributions that could support reproducible follow-up studies on multi-policy alignment.
major comments (2)
- [Abstract] Abstract: The reported 33.1% error rate is presented without details on model selection, error measurement methodology, statistical significance, or validation of the generated queries, which limits assessment of support for the central claim that composed-policy alignment warrants further investigation.
- [Methods / COPAL] COPAL description: The queries are derived from 'empirically derived interaction patterns and explicit handling contracts' based on analyzing real user queries, yet the manuscript provides no description of the derivation process, inter-rater validation, or comparison against logged interactions in target domains, which is load-bearing for the claim that these represent prevalent real-world violations overlooked by benchmarks.
minor comments (1)
- [Abstract] Abstract: The sentence 'This paper present COPAL' contains a grammatical error ('present' should be 'presents').
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. The comments highlight important areas for clarification in the abstract and methods section. We provide point-by-point responses below and will make revisions to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported 33.1% error rate is presented without details on model selection, error measurement methodology, statistical significance, or validation of the generated queries, which limits assessment of support for the central claim that composed-policy alignment warrants further investigation.
Authors: We agree that the abstract is too concise and omits key details needed to assess the central claim. We will revise the abstract to concisely incorporate information on the nine models evaluated, the error measurement approach, statistical reporting, and query validation steps. revision: yes
-
Referee: [Methods / COPAL] COPAL description: The queries are derived from 'empirically derived interaction patterns and explicit handling contracts' based on analyzing real user queries, yet the manuscript provides no description of the derivation process, inter-rater validation, or comparison against logged interactions in target domains, which is load-bearing for the claim that these represent prevalent real-world violations overlooked by benchmarks.
Authors: We agree that a detailed account of the derivation process is necessary to substantiate the real-world relevance of the queries. The current manuscript references the analysis of real user queries but does not describe the extraction of patterns and contracts, any inter-rater validation, or comparisons to domain logs. We will add this description to the Methods section, including the specific steps taken and any limitations on log comparisons due to data access constraints. revision: yes
Circularity Check
No circularity: empirical tool and observation with independent test results
full rationale
The paper describes an empirical process: analysis of real user queries to identify patterns, construction of the COPAL tool using those patterns and handling contracts, generation of test queries, and measurement of a 33.1% average error rate across 9 models. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central result is an observed failure rate on externally run models, not a quantity forced by definition or by the input patterns themselves. The assumption that generated queries match real-world prevalence is a methodological limitation but does not reduce any claim to a tautology or self-referential fit.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[7]
2024 , booktitle=
The Art of Saying No: Contextual Noncompliance in Language Models , author=. 2024 , booktitle=
2024
-
[8]
The Thirteenth International Conference on Learning Representations , url=
Tinghao Xie and Xiangyu Qi and Yi Zeng and Yangsibo Huang and Udari Madhushani Sehwag and Kaixuan Huang and Luxi He and Boyi Wei and Dacheng Li and Ying Sheng and Ruoxi Jia and Bo Li and Kai Li and Danqi Chen and Peter Henderson and Prateek Mittal , year=. The Thirteenth International Conference on Learning Representations , url=
-
[9]
Proceedings of the 42nd International Conference on Machine Learning , pages=
Cui, Justin and Chiang, Wei-Lin and Stoica, Ion and Hsieh, Cho-Jui , year=. Proceedings of the 42nd International Conference on Machine Learning , pages=
-
[10]
Reddy , year=
Zhehao Zhang and Weijie Xu and Fanyou Wu and Chandan K. Reddy , year=. The Second Conference on Language Modeling , url=
-
[14]
2025 , booktitle=
-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains , author=. 2025 , booktitle=
2025
-
[18]
Proceedings of the 42nd International Conference on Machine Learning , pages=
Sun, Guangzhi and Zhan, Xiao and Feng, Shutong and Woodland, Phil and Such, Jose , year=. Proceedings of the 42nd International Conference on Machine Learning , pages=
-
[19]
Malicious
Xiao Zhan and Juan Carlos Carrillo and William Seymour and Jose Such , year=. Malicious. 34th USENIX Security Symposium (USENIX Security 25) , address=
-
[24]
2026 , month=feb, howpublished=
Introducing. 2026 , month=feb, howpublished=
2026
-
[25]
2026 , month=feb, howpublished=
2026
-
[26]
2026 , howpublished=
2026
-
[27]
2026 , month=mar, howpublished=
2026
-
[28]
2025 , howpublished=
2025
-
[29]
Anthropic . 2026. https://www.anthropic.com/news/claude-sonnet-4-6 Introducing Claude Sonnet 4.6 . Official model release. Published: 2026-02-17. Accessed: 2026-05-21
2026
-
[30]
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. 2025. https://doi.org/10.48550/arXiv.2506.07982 ^2 -bench: Evaluating conversational agents in a dual-control environment . arXiv preprint arXiv:2506.07982, arXiv:2506.07982
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.07982 2025
-
[31]
Matteo Boffa and Jiaxuan You. 2025. https://doi.org/10.48550/arXiv.2509.24090 Large-scale constraint generation -- can llms parse hundreds of constraints? arXiv preprint arXiv:2509.24090, arXiv:2509.24090
-
[32]
Smith, Yejin Choi, and Hannaneh Hajishirzi
Faeze Brahman, Sachin Kumar, Vidhisha Balachandran, Pradeep Dasigi, Valentina Pyatkin, Abhilasha Ravichander, Sarah Wiegreffe, Nouha Dziri, Khyathi Chandu, Jack Hessel, Yulia Tsvetkov, Noah A. Smith, Yejin Choi, and Hannaneh Hajishirzi. 2024. https://doi.org/10.52202/079017-1573 The art of saying no: Contextual noncompliance in language models . In Advanc...
-
[33]
ByteDance Seed . 2026. https://seed.bytedance.com/seed2 Seed2.0 Model Page and Model Card . Official model page. Includes model card and official launch information. Accessed: 2026-05-21
2026
-
[34]
Hwan Chang, Yumin Kim, Yonghyun Jun, and Hwanhee Lee. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.345 Keep security! benchmarking security policy preservation in large language model contexts against indirect attacks in question answering . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 6780--6800, S...
-
[35]
Dasol Choi, DongGeon Lee, Brigitta Jesica Kartono, Helena Berndt, Taeyoun Kwon, Joonwon Jang, Haon Park, Hwanjo Yu, and Minsuk Kahng. 2026. https://doi.org/10.48550/arXiv.2601.01836 Compass: A framework for evaluating organization-specific policy alignment in llms . arXiv preprint arXiv:2601.01836, arXiv:2601.01836
-
[36]
Justin Cui, Wei-Lin Chiang, Ion Stoica, and Cho-Jui Hsieh. 2025. https://proceedings.mlr.press/v267/cui25a.html OR-Bench : An over-refusal benchmark for large language models . In Proceedings of the 42nd International Conference on Machine Learning, volume 267 of Proceedings of Machine Learning Research, pages 11515--11542. PMLR
2025
-
[37]
DeepSeek-AI . 2025. https://huggingface.co/deepseek-ai/DeepSeek-V3.2 DeepSeek-V3.2 : Efficient reasoning and agentic AI . Official model card. Accessed: 2026-05-21
2025
-
[38]
Lingxiao Diao, Xinyue Xu, Wanxuan Sun, Cheng Yang, and Zhuosheng Zhang. 2025. https://doi.org/10.18653/v1/2025.acl-long.557 G uide B ench: Benchmarking domain-oriented guideline following for LLM agents . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11361--11399, Vienna, Austria....
-
[39]
Google DeepMind . 2026. https://deepmind.google/models/model-cards/gemini-3-1-pro/ Gemini 3.1 Pro Model Card . Model card, Google DeepMind. Published: 2026-02-19. Accessed: 2026-05-21
2026
-
[40]
Kai He, Rui Mao, Qika Lin, Yucheng Ruan, Xiang Lan, Mengling Feng, and Erik Cambria. 2025. https://doi.org/10.1016/j.inffus.2025.102963 A survey of large language models for healthcare: From data, technology, and applications to accountability and ethics . Information Fusion, 118:102963
-
[41]
Yuxin Jiang, Yufei Wang, Xingshan Zeng, Wanjun Zhong, Liangyou Li, Fei Mi, Lifeng Shang, Xin Jiang, Qun Liu, and Wei Wang. 2024. https://doi.org/10.18653/v1/2024.acl-long.257 F ollow B ench: A multi-level fine-grained constraints following benchmark for large language models . In Proceedings of the 62nd Annual Meeting of the Association for Computational ...
-
[42]
Anna Grøndahl Larsen and Asbjørn Følstad. 2024. https://doi.org/10.1016/j.giq.2024.101927 The impact of chatbots on public service provision: A qualitative interview study with citizens and public service providers . Government Information Quarterly, 41(2):101927
-
[43]
MiniMax . 2026. https://www.minimax.io/news/minimax-m27-en MiniMax M2.7 : Early echoes of self-evolution . Official model report. Published: 2026-03-18. Accessed: 2026-05-21
2026
-
[44]
Moonshot AI . 2026. https://www.kimi.com/blog/kimi-k2-6 Kimi K2.6 : Advancing open-source coding . Technical blog and official model release. Accessed: 2026-05-21
2026
-
[45]
Yuqi Nie, Yaxuan Kong, Xiaowen Dong, John M. Mulvey, H. Vincent Poor, Qingsong Wen, and Stefan Zohren. 2024. https://doi.org/10.48550/arXiv.2406.11903 A survey of large language models for financial applications: Progress, prospects and challenges . arXiv preprint arXiv:2406.11903, arXiv:2406.11903
-
[46]
OpenAI . 2026. https://openai.com/index/gpt-5-5-system-card/ GPT-5.5 System Card . System card, OpenAI. Published: 2026-04-23. Updated: 2026-04-24. Accessed: 2026-05-21
2026
-
[47]
Yiwei Qin, Kaiqiang Song, Yebowen Hu, Wenlin Yao, Sangwoo Cho, Xiaoyang Wang, Xuansheng Wu, Fei Liu, Pengfei Liu, and Dong Yu. 2024. https://doi.org/10.18653/v1/2024.findings-acl.772 I n F o B ench: Evaluating instruction following ability in large language models . In Findings of the Association for Computational Linguistics: ACL 2024, pages 13025--13048...
-
[48]
Qwen Team . 2026. https://huggingface.co/Qwen/Qwen3.5-397B-A17B Qwen3.5-397B-A17B . Official model card. Accessed: 2026-05-21
2026
-
[49]
David Rodriguez, William Seymour, Jose M. Del Alamo, and Jose Such. 2025. https://doi.org/10.48550/arXiv.2502.01436 Towards safer chatbots: A framework for policy compliance evaluation of custom GPT s . arXiv preprint arXiv:2502.01436, arXiv:2502.01436
-
[50]
Guangzhi Sun, Xiao Zhan, Shutong Feng, Phil Woodland, and Jose Such. 2025. https://proceedings.mlr.press/v267/sun25ab.html CASE -bench: Context-aware S af E ty benchmark for large language models . In Proceedings of the 42nd International Conference on Machine Learning, volume 267 of Proceedings of Machine Learning Research, pages 57938--57960. PMLR
2025
-
[51]
Prasoon Varshney, Makesh Narsimhan Sreedhar, Liwei Jiang, Traian Rebedea, and Christopher Parisien. 2025. https://doi.org/10.48550/arXiv.2511.05018 Pluralistic behavior suite: Stress-testing multi-turn adherence to custom behavioral policies . arXiv preprint arXiv:2511.05018, arXiv:2511.05018
-
[52]
Bosi Wen, Pei Ke, Xiaotao Gu, Lindong Wu, Hao Huang, Jinfeng Zhou, Wenchuang Li, Binxin Hu, Wendy Gao, Jiaxin Xu, Yiming Liu, Jie Tang, Hongning Wang, and Minlie Huang. 2024. https://doi.org/10.52202/079017-4371 Benchmarking complex instruction-following with multiple constraints composition . In Advances in Neural Information Processing Systems 37: Datas...
-
[53]
Tinghao Xie, Xiangyu Qi, Yi Zeng, Yangsibo Huang, Udari Madhushani Sehwag, Kaixuan Huang, Luxi He, Boyi Wei, Dacheng Li, Ying Sheng, Ruoxi Jia, Bo Li, Kai Li, Danqi Chen, Peter Henderson, and Prateek Mittal. 2025. https://openreview.net/forum?id=YfKNaRktan SORRY-Bench : Systematically evaluating large language model safety refusal . In The Thirteenth Inte...
2025
-
[54]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. 2025. https://openreview.net/forum?id=roNSXZpUDN -bench: A benchmark for tool-agent-user interaction in real-world domains . In The Thirteenth International Conference on Learning Representations
2025
-
[55]
Z.ai . 2026. https://huggingface.co/zai-org/GLM-5.1 GLM-5.1 . Official model card. Cites GLM-5 technical report arXiv:2602.15763. Accessed: 2026-05-21
Pith/arXiv arXiv 2026
-
[56]
Yi Zeng, Yu Yang, Andy Zhou, Jeffrey Ziwei Tan, Yuheng Tu, Yifan Mai, Kevin Klyman, Minzhou Pan, Ruoxi Jia, Dawn Song, Percy Liang, and Bo Li. 2024. https://doi.org/10.48550/arXiv.2407.17436 AIR-Bench 2024: A safety benchmark based on risk categories from regulations and policies . arXiv preprint arXiv:2407.17436, arXiv:2407.17436
-
[57]
Xiao Zhan, Juan Carlos Carrillo, William Seymour, and Jose Such. 2025. https://www.usenix.org/conference/usenixsecurity25/presentation/zhan Malicious LLM-Based conversational AI makes users reveal personal information . In 34th USENIX Security Symposium (USENIX Security 25), pages 61--80, Seattle, WA. USENIX Association
2025
-
[58]
Zhehao Zhang, Weijie Xu, Fanyou Wu, and Chandan K. Reddy. 2025 a . https://openreview.net/forum?id=1w9Hay7tvm FalseReject : A resource for improving contextual safety and mitigating over-refusals in llms via structured reasoning . In The Second Conference on Language Modeling
2025
-
[59]
Zhihan Zhang, Shiyang Li, Zixuan Zhang, Xin Liu, Haoming Jiang, Xianfeng Tang, Yifan Gao, Zheng Li, Haodong Wang, Zhaoxuan Tan, Yichuan Li, Qingyu Yin, Bing Yin, and Meng Jiang. 2025 b . https://doi.org/10.18653/v1/2025.naacl-long.425 IHE val: Evaluating language models on following the instruction hierarchy . In Proceedings of the 2025 Conference of the ...
-
[60]
Ruiwen Zhou, Wenyue Hua, Liangming Pan, Sitao Cheng, Xiaobao Wu, En Yu, and William Yang Wang. 2025. https://doi.org/10.18653/v1/2025.acl-long.27 R ule A rena: A benchmark for rule-guided reasoning with LLM s in real-world scenarios . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.