SrDetection: A Self-Referential Framework for Data Leakage Detection in Code Large Language Models
Pith reviewed 2026-06-30 06:18 UTC · model grok-4.3
The pith
SrDetection identifies data leakage in Code LLMs by contrasting model performance on original samples against semantically equivalent variants.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
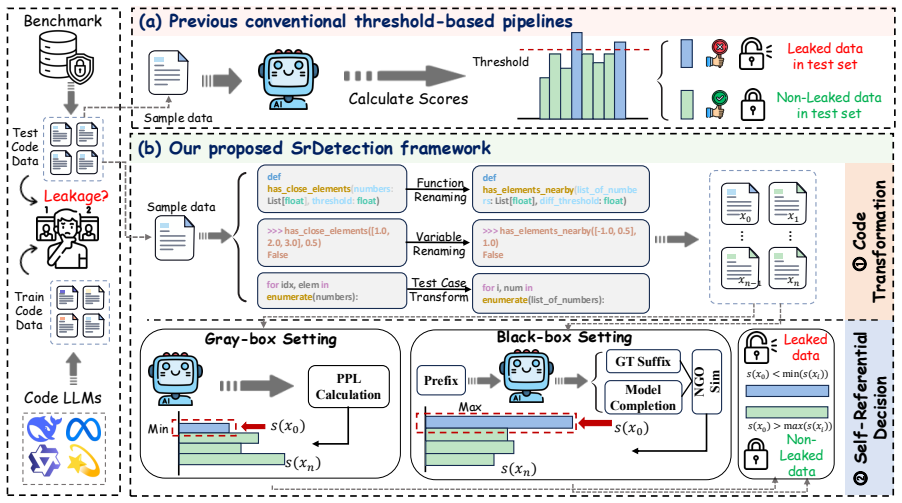
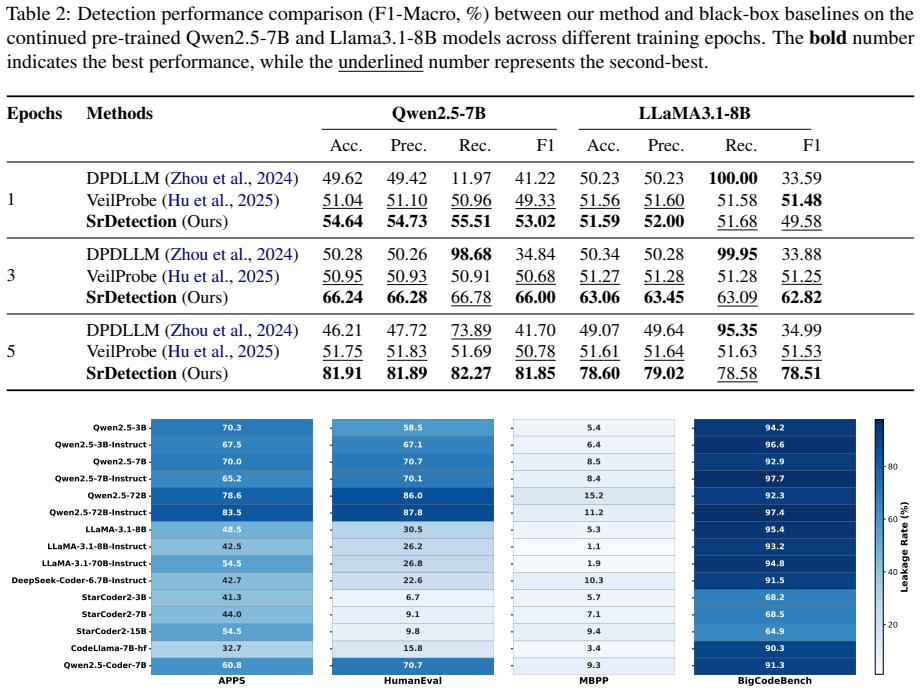
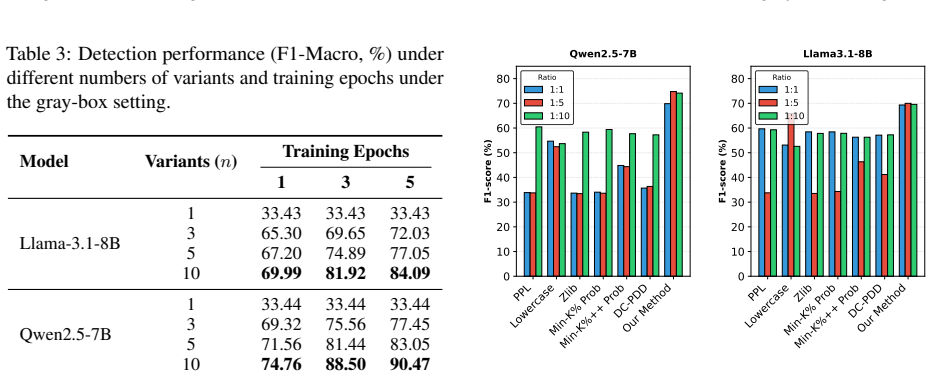
SrDetection generates semantically equivalent variants of benchmark samples and detects leakage by contrasting the model's behavior on the original versus its variants, flagging cases where the original is disproportionately easier for the model. This unified framework applies to both gray-box and black-box settings and demonstrates robust, threshold-independent detection, with average F1 improvements of 21.52 points in gray-box and 14.46 in black-box over baselines.
What carries the argument
The self-referential contrast mechanism that compares model performance on original benchmark samples to that on their semantically equivalent variants.
If this is right
- Enables more accurate evaluation of Code LLMs by identifying leaked data without proprietary information.
- Provides consistent detection across different models and training stages.
- Reveals specific leakage patterns in popular benchmarks through application to 15 models.
- Operates effectively in both gray-box and black-box access scenarios.
Where Pith is reading between the lines
- This approach could be adapted to detect leakage in non-code domains like natural language benchmarks.
- It suggests that future benchmarks might incorporate variant generation to make leakage harder to exploit.
- The threshold-independent property may reduce the need for per-model tuning in evaluation pipelines.
Load-bearing premise
That performance gaps between originals and their variants reliably signal leakage rather than other model behaviors or coincidental differences.
What would settle it
Observing that models perform equally well on both originals and variants even when leakage is known to have occurred, or large gaps appearing on non-leaked data.
Figures

read the original abstract
Evaluating code large language models (Code LLMs) requires reliable detection of data leakage, where benchmark performance is artificially inflated by exposure to benchmark data during pre-training. Existing approaches either assume access to proprietary training corpora, rely on brittle heuristics such as timestamp filtering, or use external reference sets with manually tuned, non-generalizable thresholds. To address these limitations, we introduce \textbf{SrDetection}, a unified \textbf{s}elf-\textbf{r}eferential leakage detection framework for both gray-box (access to model logits) and black-box (access to model outputs) settings. SrDetection generates semantically equivalent variants of a benchmark sample and detects leakage by contrasting the model's behavior on the original versus its variants, flagging cases where the original is disproportionately easier for the model. We further design a controlled leakage detection testbed and evaluate SrDetection in this environment. Across different models and training stages, SrDetection improves average F1 by 21.52 points in the gray-box setting and 14.46 points in the black-box setting over strong baselines, demonstrating robust, threshold-independent leakage detection. Finally, a gray-box study of 15 widely used Code LLMs on four popular benchmarks reveals benchmark-specific leakage patterns beyond prior overlap-based analyses\footnote{\footnotesize Source code and data are available at https://github.com/SMinL/SrDetectionCode
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SrDetection, a self-referential framework for detecting data leakage in Code LLMs. In both gray-box (logits) and black-box (outputs) settings, it generates semantically equivalent variants of benchmark samples and flags leakage when the model performs disproportionately better on the original than on the variants. The authors design a controlled leakage testbed, report average F1 gains of 21.52 (gray-box) and 14.46 (black-box) over baselines across models and training stages, and apply the method to 15 Code LLMs on four benchmarks, revealing benchmark-specific leakage patterns. Source code and data are released.
Significance. If the detection rule proves robust, the approach offers a threshold-independent alternative to overlap-based or heuristic leakage detectors and could strengthen evaluation practices for Code LLMs. The public release of code and data supports reproducibility and is a clear strength.
major comments (2)
- [controlled leakage detection testbed (abstract and §4)] The central detection rule rests on the assumption that training exposure to an original benchmark sample does not imply exposure to its generated semantically equivalent variants, and that any performance gap is attributable to leakage rather than model-specific behaviors on code structure or tokenization. The controlled testbed description does not include an ablation that replaces the variant generator with independently verified equivalent programs (e.g., via execution-equivalence checks), leaving the F1 gains vulnerable to this confound. This assumption is load-bearing for the reported improvements.
- [evaluation results (abstract and §5)] The abstract states specific F1 improvements but provides no details on the number of runs, variance, or statistical tests supporting the 21.52 / 14.46 point gains. Without these, it is not possible to assess whether the gains are reliable or sensitive to variant-generation hyperparameters.
minor comments (2)
- [method overview] Notation for gray-box versus black-box contrast functions should be defined explicitly with equations rather than prose descriptions.
- [abstract footnote] The footnote on code availability is helpful; the repository link should also appear in the main text and reproducibility statement.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and commit to revisions that directly strengthen the evaluation of the controlled testbed and the statistical reporting of results.
read point-by-point responses
-
Referee: [controlled leakage detection testbed (abstract and §4)] The central detection rule rests on the assumption that training exposure to an original benchmark sample does not imply exposure to its generated semantically equivalent variants, and that any performance gap is attributable to leakage rather than model-specific behaviors on code structure or tokenization. The controlled testbed description does not include an ablation that replaces the variant generator with independently verified equivalent programs (e.g., via execution-equivalence checks), leaving the F1 gains vulnerable to this confound. This assumption is load-bearing for the reported improvements.
Authors: We agree that execution-based verification of equivalence would further isolate leakage effects from potential structural or tokenization artifacts. In the revised manuscript we will add an ablation that substitutes the current variant generator with programs verified for execution equivalence (via test-case agreement on both original and variant). This will be performed on a representative subset of the testbed to quantify any impact on the reported F1 scores. revision: yes
-
Referee: [evaluation results (abstract and §5)] The abstract states specific F1 improvements but provides no details on the number of runs, variance, or statistical tests supporting the 21.52 / 14.46 point gains. Without these, it is not possible to assess whether the gains are reliable or sensitive to variant-generation hyperparameters.
Authors: We acknowledge that the current manuscript lacks explicit reporting of run counts, variance, and significance testing. In the revision we will report results over multiple independent runs (with different random seeds for variant generation and model evaluation), include standard deviations or confidence intervals, and add paired statistical tests (e.g., t-tests) comparing SrDetection against baselines. We will also include a brief sensitivity analysis with respect to key variant-generation hyperparameters. revision: yes
Circularity Check
No circularity; detection rule grounded in observable contrast
full rationale
The paper defines SrDetection via generation of semantically equivalent variants followed by a contrast of model behavior (logits or outputs) on the original versus variants, flagging leakage when the original is disproportionately easier. This rule is stated directly in terms of model outputs on independently generated inputs and does not reduce to any fitted parameter, self-definition, or self-citation chain. The controlled testbed is described as an external simulation environment used for evaluation; reported F1 gains are measured against external baselines rather than being forced by construction from the same data. No equations or load-bearing steps in the abstract or described method equate the claimed result to its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code , booktitle =
Naman Jain and King Han and Alex Gu and Wen. LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code , booktitle =. 2025 , url =
2025
-
[5]
Xin Zhou and Martin Weyssow and Ratnadira Widyasari and Ting Zhang and Junda He and Yunbo Lyu and Jianming Chang and Beiqi Zhang and Dan Huang and David Lo , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2502.06215 , eprinttype =. 2502.06215 , timestamp =
-
[6]
On Inter-Dataset Code Duplication and Data Leakage in Large Language Models , journal =
Jos. On Inter-Dataset Code Duplication and Data Leakage in Large Language Models , journal =
-
[7]
Benchmarkingbenchmark leakage in large language models
Ruijie Xu and Zengzhi Wang and Run. Benchmarking Benchmark Leakage in Large Language Models , journal =. 2024 , url =. doi:10.48550/ARXIV.2404.18824 , eprinttype =. 2404.18824 , timestamp =
-
[8]
The Twelfth International Conference on Learning Representations,
Weijia Shi and Anirudh Ajith and Mengzhou Xia and Yangsibo Huang and Daogao Liu and Terra Blevins and Danqi Chen and Luke Zettlemoyer , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[9]
Findings of the Association for Computational Linguistics,
Yihong Dong and Xue Jiang and Huanyu Liu and Zhi Jin and Bin Gu and Mengfei Yang and Ge Li , title =. Findings of the Association for Computational Linguistics,
-
[10]
Chunyuan Deng and Yilun Zhao and Xiangru Tang and Mark Gerstein and Arman Cohan , title =
-
[11]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing,
Weichao Zhang and Ruqing Zhang and Jiafeng Guo and Maarten de Rijke and Yixing Fan and Xueqi Cheng , title =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing,
2024
-
[12]
Shuo Yang and Wei. Rethinking Benchmark and Contamination for Language Models with Rephrased Samples , journal =. 2023 , url =. doi:10.48550/ARXIV.2311.04850 , eprinttype =. 2311.04850 , timestamp =
-
[13]
Joty and Steven C
Yue Wang and Weishi Wang and Shafiq R. Joty and Steven C. H. Hoi , title =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing,
2021
-
[14]
Yue Wang and Hung Le and Akhilesh Gotmare and Nghi D. Q. Bui and Junnan Li and Steven C. H. Hoi , title =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing,
2023
-
[15]
CodeRL: Mastering Code Generation through Pretrained Models and Deep Reinforcement Learning , booktitle =
Hung Le and Yue Wang and Akhilesh Deepak Gotmare and Silvio Savarese and Steven Chu. CodeRL: Mastering Code Generation through Pretrained Models and Deep Reinforcement Learning , booktitle =
-
[16]
Findings of the Association for Computational Linguistics:
Yekun Chai and Shuohuan Wang and Chao Pang and Yu Sun and Hao Tian and Hua Wu , title =. Findings of the Association for Computational Linguistics:
-
[17]
StarCoder: may the source be with you! , journal =
Raymond Li and Loubna Ben Allal and Yangtian Zi and Niklas Muennighoff and Denis Kocetkov and Chenghao Mou and Marc Marone and Christopher Akiki and Jia Li and Jenny Chim and Qian Liu and Evgenii Zheltonozhskii and Terry Yue Zhuo and Thomas Wang and Olivier Dehaene and Mishig Davaadorj and Joel Lamy. StarCoder: may the source be with you! , journal =
-
[18]
Code Llama: Open Foundation Models for Code
Baptiste Rozi. Code Llama: Open Foundation Models for Code , journal =. 2023 , url =. doi:10.48550/ARXIV.2308.12950 , eprinttype =. 2308.12950 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.12950 2023
-
[19]
Heri Zhao and Jeffrey Hui and Joshua Howland and Nam Nguyen and Siqi Zuo and Andrea Hu and Christopher A. Choquette. CodeGemma: Open Code Models Based on Gemma , journal =. 2024 , url =. doi:10.48550/ARXIV.2406.11409 , eprinttype =. 2406.11409 , timestamp =
-
[20]
Qwen2.5-Coder Technical Report
Binyuan Hui and Jian Yang and Zeyu Cui and Jiaxi Yang and Dayiheng Liu and Lei Zhang and Tianyu Liu and Jiajun Zhang and Bowen Yu and Kai Dang and An Yang and Rui Men and Fei Huang and Xingzhang Ren and Xuancheng Ren and Jingren Zhou and Junyang Lin , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2409.12186 , eprinttype =. 2409.12186 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2409.12186 2024
-
[21]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
Daya Guo and Qihao Zhu and Dejian Yang and Zhenda Xie and Kai Dong and Wentao Zhang and Guanting Chen and Xiao Bi and Y. Wu and Y. K. Li and Fuli Luo and Yingfei Xiong and Wenfeng Liang , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2401.14196 , eprinttype =. 2401.14196 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2401.14196 2024
-
[22]
The Twelfth International Conference on Learning Representations,
Niklas Muennighoff and Qian Liu and Armel Randy Zebaze and Qinkai Zheng and Binyuan Hui and Terry Yue Zhuo and Swayam Singh and Xiangru Tang and Leandro von Werra and Shayne Longpre , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[23]
Long Ouyang and Jeffrey Wu and Xu Jiang and Diogo Almeida and Carroll L. Wainwright and Pamela Mishkin and Chong Zhang and Sandhini Agarwal and Katarina Slama and Alex Ray and John Schulman and Jacob Hilton and Fraser Kelton and Luke Miller and Maddie Simens and Amanda Askell and Peter Welinder and Paul F. Christiano and Jan Leike and Ryan Lowe , title =....
2022
-
[24]
Hongjin Su and Shuyang Jiang and Yuhang Lai and Haoyuan Wu and Boao Shi and Che Liu and Qian Liu and Tao Yu , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2402.12317 , eprinttype =. 2402.12317 , timestamp =
-
[25]
The Twelfth International Conference on Learning Representations,
Can Xu and Qingfeng Sun and Kai Zheng and Xiubo Geng and Pu Zhao and Jiazhan Feng and Chongyang Tao and Qingwei Lin and Daxin Jiang , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[26]
Lily Zhong and Zilong Wang and Jingbo Shang , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2402.16906 , eprinttype =. 2402.16906 , timestamp =
-
[27]
PaLM: Scaling Language Modeling with Pathways , journal =
Aakanksha Chowdhery and Sharan Narang and Jacob Devlin and Maarten Bosma and Gaurav Mishra and Adam Roberts and Paul Barham and Hyung Won Chung and Charles Sutton and Sebastian Gehrmann and Parker Schuh and Kensen Shi and Sasha Tsvyashchenko and Joshua Maynez and Abhishek Rao and Parker Barnes and Yi Tay and Noam Shazeer and Vinodkumar Prabhakaran and Emi...
-
[28]
Reza Shokri and Marco Stronati and Congzheng Song and Vitaly Shmatikov , title =. 2017
2017
-
[29]
White-box vs Black-box: Bayes Optimal Strategies for Membership Inference , booktitle =
Alexandre Sablayrolles and Matthijs Douze and Cordelia Schmid and Yann Ollivier and Herv. White-box vs Black-box: Bayes Optimal Strategies for Membership Inference , booktitle =
-
[30]
Proceedings of the 25th
Congzheng Song and Vitaly Shmatikov , title =. Proceedings of the 25th
-
[31]
Extracting Training Data from Large Language Models , booktitle =
Nicholas Carlini and Florian Tram. Extracting Training Data from Large Language Models , booktitle =
-
[32]
The Thirteenth International Conference on Learning Representations , year=
Min-K\ author=. The Thirteenth International Conference on Learning Representations , year=
-
[33]
The Twelfth International Conference on Learning Representations,
Manley Roberts and Himanshu Thakur and Christine Herlihy and Colin White and Samuel Dooley , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[34]
DPDLLM : A Black-box Framework for Detecting Pre-training Data from Large Language Models
Zhou, Baohang and Wang, Zezhong and Wang, Lingzhi and Wang, Hongru and Zhang, Ying and Song, Kehui and Sui, Xuhui and Wong, Kam-Fai. DPDLLM : A Black-box Framework for Detecting Pre-training Data from Large Language Models. Findings of the Association for Computational Linguistics: ACL 2024. 2024
2024
-
[35]
Hu, Ruihan and Shang, Yu-Ming and Peng, Jiankun and Luo, Wei and Wang, Yazhe and Zhang, Xi , title =. 2025 , isbn =. doi:10.24963/ijcai.2025/44 , booktitle =
-
[36]
Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, virtual , year =
Dan Hendrycks and Steven Basart and Saurav Kadavath and Mantas Mazeika and Akul Arora and Ethan Guo and Collin Burns and Samir Puranik and Horace He and Dawn Song and Jacob Steinhardt , title =. Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, virtual , year =
2021
-
[37]
Llama Team , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2407.21783 , eprinttype =. 2407.21783 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[38]
An Yang and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoran Wei and Huan Lin and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Yang and Jiaxi Yang and Jingren Zhou and Junyang Lin and Kai Dang and Keming Lu and Keqin Bao and Kexin Yang and Le Yu and Mei Li and Mi...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115 2024
-
[39]
Smith and Luke Zettlemoyer , title =
Hila Gonen and Srini Iyer and Terra Blevins and Noah A. Smith and Luke Zettlemoyer , title =. Findings of the Association for Computational Linguistics:
-
[40]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
The pile: An 800gb dataset of diverse text for language modeling , author=. arXiv preprint arXiv:2101.00027 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Program Synthesis with Large Language Models
Jacob Austin and Augustus Odena and Maxwell I. Nye and Maarten Bosma and Henryk Michalewski and David Dohan and Ellen Jiang and Carrie J. Cai and Michael Terry and Quoc V. Le and Charles Sutton , title =. CoRR , volume =. 2021 , url =. 2108.07732 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[42]
Evaluating Large Language Models Trained on Code
Mark Chen and Jerry Tworek and Heewoo Jun and Qiming Yuan and Henrique Pond. Evaluating Large Language Models Trained on Code , journal =. 2021 , url =. 2107.03374 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[43]
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions , booktitle =
Terry Yue Zhuo and Minh Chien Vu and Jenny Chim and Han Hu and Wenhao Yu and Ratnadira Widyasari and Imam Nur Bani Yusuf and Haolan Zhan and Junda He and Indraneil Paul and Simon Brunner and Chen Gong and James Hoang and Armel Randy Zebaze and Xiaoheng Hong and Wen. BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instruc...
-
[44]
ACM Trans
Jiang, Juyong and Wang, Fan and Shen, Jiasi and Kim, Sungju and Kim, Sunghun , title =. ACM Trans. Softw. Eng. Methodol. , month = jul, keywords =. 2025 , publisher =
2025
-
[45]
A Survey on LLM-based Code Generation for Low-Resource and Domain-Specific Programming Languages. arXiv e-prints , keywords =. doi:10.48550/arXiv.2410.03981 , archivePrefix =. 2410.03981 , primaryClass =
-
[46]
2022 , author=
ChatGPT: optimizing language models for dialogue. 2022 , author=. Accessed on , volume=
2022
-
[47]
2024 , url=
Introducing Meta Llama 3: The most capable openly available LLM to date , author=. 2024 , url=
2024
-
[48]
Zhou Yang and Zhipeng Zhao and Chenyu Wang and Jieke Shi and Dongsun Kim and DongGyun Han and David Lo , title =. Proceedings of the 46th. 2024 , url =. doi:10.1145/3597503.3639074 , timestamp =
-
[49]
On Leakage of Code Generation Evaluation Datasets , booktitle =
Alexandre Matton and Tom Sherborne and Dennis Aumiller and Elena Tommasone and Milad Alizadeh and Jingyi He and Raymond Ma and Maxime Voisin and Ellen Gilsenan. On Leakage of Code Generation Evaluation Datasets , booktitle =
-
[50]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics,
Martin Riddell and Ansong Ni and Arman Cohan , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics,
-
[51]
Xinyi Hou and Yanjie Zhao and Yue Liu and Zhou Yang and Kailong Wang and Li Li and Xiapu Luo and David Lo and John Grundy and Haoyu Wang , title =
-
[52]
Proceedings of the 46th
Hao Yu and Bo Shen and Dezhi Ran and Jiaxin Zhang and Qi Zhang and Yuchi Ma and Guangtai Liang and Ying Li and Qianxiang Wang and Tao Xie , title =. Proceedings of the 46th
-
[53]
Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen
Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen. LoRA: Low-Rank Adaptation of Large Language Models , booktitle =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.