Weight-Space Geometry of Offline Reasoning Training
Pith reviewed 2026-06-26 10:24 UTC · model grok-4.3
The pith
DPO produces weight deltas in a near-orthogonal subspace to other offline losses, crosses a mode-connectivity barrier, and reaches the highest accuracy on GSM8K and AIME26.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
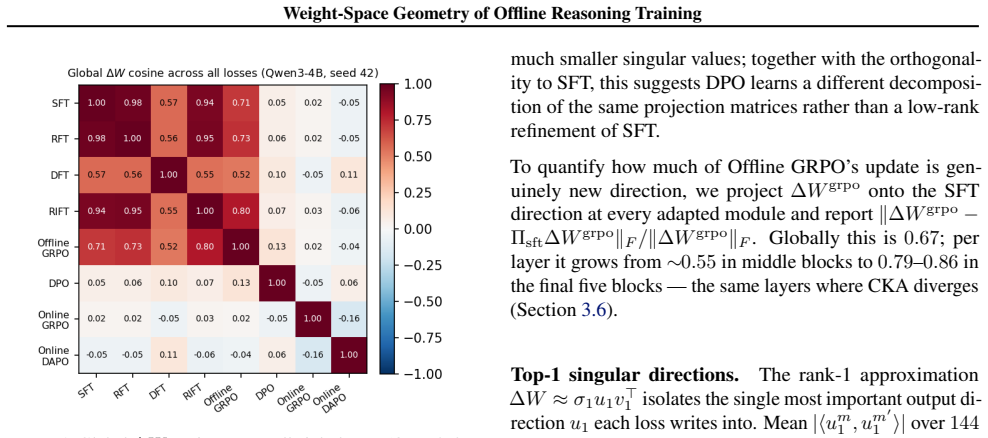
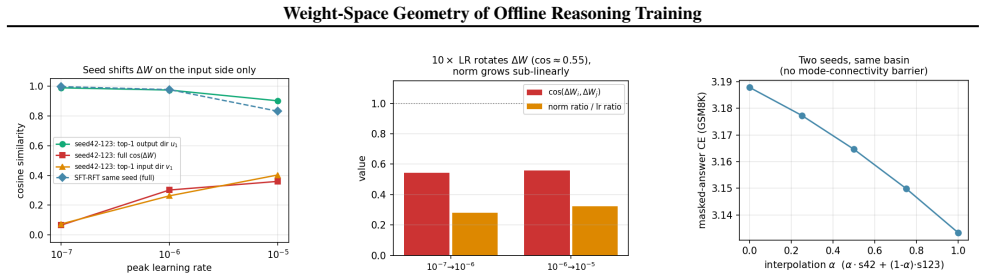
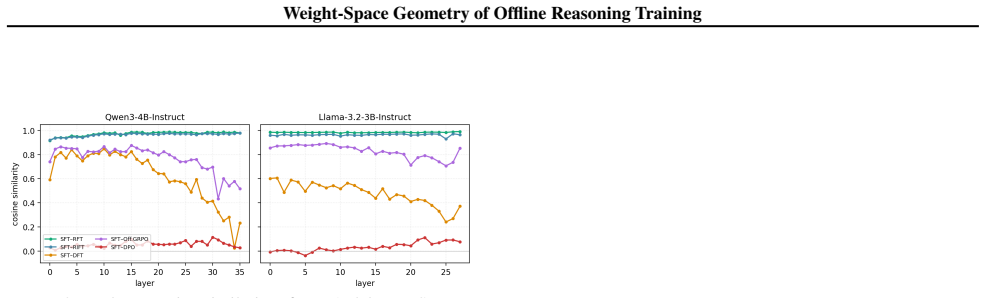
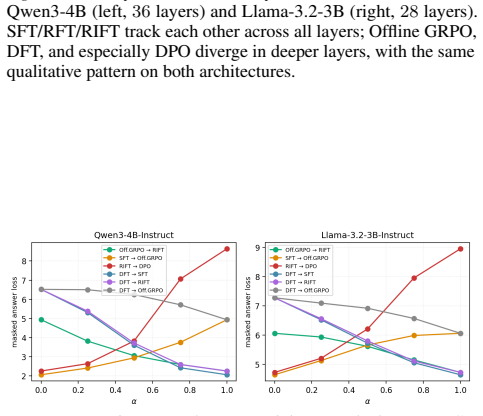
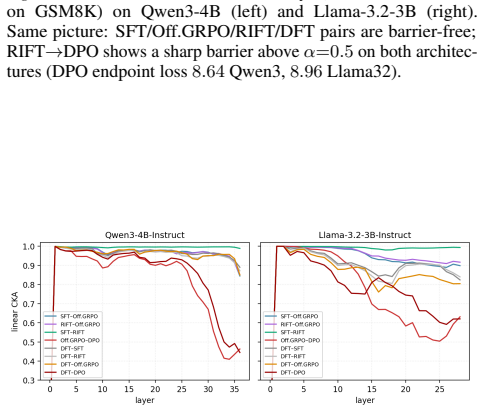
DPO sits in a near-orthogonal subspace, shows a mode-connectivity barrier, and collapses late-layer CKA to ~0.46 while reaching the highest accuracy (93.5 percent on GSM8K, 30.0 percent on AIME26); SFT, RFT, and RIFT remain nearly colinear with cosine similarity at least 0.97 and comparable accuracy, whereas Offline GRPO introduces a substantial orthogonal component yet stays inside the SFT loss basin.
What carries the argument
Geometry of weight deltas under different losses, quantified by cosine similarity, principal angles between subspaces, linear mode connectivity, and centered kernel alignment (CKA).
If this is right
- SFT, RFT, and RIFT converge to nearly the same weight updates and downstream accuracy.
- DFT produces weight deltas that diverge in direction more than any reward-weighted method despite identical data.
- Offline GRPO adds an orthogonal direction to the SFT update while remaining inside the same loss basin.
- DPO's distinct geometry coincides with the largest accuracy gains on both GSM8K and AIME26 under the reported protocol.
Where Pith is reading between the lines
- A learning-rate-matched DPO run would clarify how much of the geometric and accuracy differences stem from the loss alone versus the optimizer scale.
- The orthogonality observed for DPO may mark a route to basins that generalize better on mathematical reasoning.
- Similar weight-space diagnostics could be applied to other domains to test whether loss-induced geometric separation predicts performance.
Load-bearing premise
The observed differences in weight-space geometry and accuracy can be attributed primarily to the choice of loss function, with the 10x smaller learning rate for DPO treated as a joint factor.
What would settle it
Re-train DPO at the same learning rate as the other five methods and test whether the near-orthogonality, mode-connectivity barrier, reduced CKA, and accuracy advantage remain.
Figures

read the original abstract
Offline reinforcement-learning losses (RFT, RIFT, DFT, Offline GRPO, DPO) are widely used to distill reasoning from large teachers into smaller students, and are typically compared on downstream accuracy alone. We ask whether they are mechanistically distinct or converge to a similar weight update. Training six methods (SFT, RFT, DFT, RIFT, Offline GRPO, DPO) on identical math rollouts from a single base model (Qwen3-4B) with attention-only LoRA, we analyze the resulting deltas via cosine similarity, principal-angle subspace analysis, linear mode connectivity, and CKA. We observe: (i) SFT, RFT, and RIFT have nearly colinear weight deltas (cosine >= 0.97, top-1 principal angle ~7 deg median over 144 modules) and comparable GSM8K accuracy (87-88%, n=1319; pairwise McNemar p >= 0.15); (ii) DFT diverges further in direction than any reward-weighted method despite using the same data; (iii) Offline GRPO adds a substantial component orthogonal to the SFT direction (~67% globally, up to ~86% in late layers) while staying in the SFT loss basin; (iv) DPO sits in a near-orthogonal subspace, shows a mode-connectivity barrier, and collapses late-layer CKA to ~0.46. DPO also reaches the highest accuracy in our protocol on both GSM8K (93.5%, McNemar p < 10^-9 vs. each other method) and AIME26 (30.0% vs. 3.3-10.0%); its training uses a 10x smaller learning rate than the others (the standard convention), so the update-norm and accuracy gaps reflect loss-function and optimizer choices jointly, and a learning-rate-matched DPO comparison is left for future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines whether six offline reasoning training methods (SFT, RFT, DFT, RIFT, Offline GRPO, DPO) applied to identical math rollouts from Qwen3-4B with attention-only LoRA produce distinct weight-space geometries. Using cosine similarity, principal-angle analysis, linear mode connectivity, and CKA on the resulting deltas, it reports that SFT/RFT/RIFT deltas are nearly collinear (cosine >=0.97, ~7 deg angles) with comparable GSM8K accuracy (~87-88%), DFT diverges more, GRPO adds an orthogonal component while remaining in the SFT basin, and DPO is near-orthogonal with a mode-connectivity barrier and late-layer CKA ~0.46, also achieving the highest accuracy (93.5% GSM8K, 30% AIME26). The abstract notes DPO used a 10x smaller learning rate (standard convention), so its update-norm and accuracy gaps reflect loss and optimizer choices jointly.
Significance. If the reported geometric distinctions hold after isolating loss effects, the work supplies concrete evidence that offline RL losses induce mechanistically different weight updates rather than converging to equivalent directions, supported by multiple metrics and McNemar-tested accuracy differences on a controlled single-base-model setup. This could guide loss selection for reasoning distillation beyond accuracy tables alone.
major comments (1)
- [Abstract] Abstract: The central observations that DPO occupies a near-orthogonal subspace, exhibits a mode-connectivity barrier, collapses late-layer CKA to ~0.46, and attains the highest accuracy are obtained under a 10x smaller learning rate than SFT/RFT/DFT/RIFT/GRPO. The text explicitly states that the resulting gaps reflect loss-function and optimizer choices jointly and leaves a learning-rate-matched comparison for future work. Without that control, the geometric distinctions cannot be attributed primarily to the DPO objective, which is load-bearing for the claim that the methods are mechanistically distinct due to loss choice.
minor comments (2)
- The manuscript should provide explicit details on data exclusion rules, exact rollout generation procedure, and complete hyperparameter tables (including LoRA rank, batch size, and optimizer settings) to support reproducibility of the reported metrics.
- Clarify the precise aggregation method for the 144-module principal-angle and CKA statistics (e.g., median vs. mean, per-layer vs. global) in the methods section.
Simulated Author's Rebuttal
We thank the referee for their careful review and for identifying this important point about confounding factors in the DPO comparison. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central observations that DPO occupies a near-orthogonal subspace, exhibits a mode-connectivity barrier, collapses late-layer CKA to ~0.46, and attains the highest accuracy are obtained under a 10x smaller learning rate than SFT/RFT/DFT/RIFT/GRPO. The text explicitly states that the resulting gaps reflect loss-function and optimizer choices jointly and leaves a learning-rate-matched comparison for future work. Without that control, the geometric distinctions cannot be attributed primarily to the DPO objective, which is load-bearing for the claim that the methods are mechanistically distinct due to loss choice.
Authors: We agree that the 10× smaller learning rate for DPO (standard convention) means the observed geometry and accuracy cannot be attributed solely to the loss function. The manuscript already states this qualification explicitly. The results nevertheless demonstrate that, when each method is run under its conventional hyperparameter protocol on identical data, the resulting weight deltas occupy distinct geometries. This is a practically relevant observation for how these methods are applied in practice. We will revise the abstract to foreground this qualification more prominently and to clarify that the reported distinctions hold under standard training settings rather than claiming isolation of the loss effect alone. revision: partial
Circularity Check
No circularity: purely empirical measurements with no derivations or self-referential reductions
full rationale
The manuscript performs direct training runs of six methods on identical data, then measures weight deltas via cosine similarity, principal angles, mode connectivity, and CKA, plus downstream accuracies with McNemar tests. No equations derive a 'prediction' from fitted parameters; no self-citations support load-bearing uniqueness claims; the LR difference for DPO is explicitly flagged as a joint factor with future matched-LR work noted. All central claims rest on observable quantities independent of the paper's own outputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- DPO learning rate =
10x smaller than other methods
Reference graph
Works this paper leans on
-
[1]
Liu, Zehua and Liu, Shuqi and Zhong, Tao and Yuan, Mingxuan , journal =
-
[2]
2025 , note =
Offline. 2025 , note =
2025
-
[3]
On the Generalization of
Wu, Yongliang and others , journal =. On the Generalization of
-
[4]
Learning to Reason under Off-Policy Guidance
Learning to Reason under Off-Policy Guidance , author =. arXiv preprint arXiv:2504.14945 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Yu, Qiying and others , journal =
-
[6]
NeurIPS Workshop on Mechanistic Interpretability , year =
Shared Parameter Subspaces in Emergently Misaligned Behavior , author =. NeurIPS Workshop on Mechanistic Interpretability , year =
-
[7]
NeurIPS Workshop on Mechanistic Interpretability , year =
Convergent Linear Representations of Emergent Misalignment , author =. NeurIPS Workshop on Mechanistic Interpretability , year =
-
[8]
NeurIPS Workshop on Mechanistic Interpretability , year =
Watch the Weights: Unsupervised monitoring and control of fine-tuned LLMs , author =. NeurIPS Workshop on Mechanistic Interpretability , year =
-
[9]
Ward and others , booktitle =. Rank-1
-
[10]
Scaling Relationship on Learning Mathematical Reasoning with Large Language Models
Scaling Relationship on Learning Mathematical Reasoning with Large Language Models , author =. arXiv preprint arXiv:2308.01825 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, Y K and Wu, Y and Guo, Daya , journal =
-
[12]
Advances in Neural Information Processing Systems , year =
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author =. Advances in Neural Information Processing Systems , year =
-
[13]
Ethayarajh, Kawin and Xu, Winnie and Muennighoff, Niklas and Jurafsky, Dan and Kiela, Douwe , booktitle =
-
[14]
A general theoretical paradigm to understand learning from human preferences
A General Theoretical Paradigm to Understand Learning from Human Preferences , author =. arXiv preprint arXiv:2310.12036 , year =
-
[15]
Meng, Yu and Xia, Mengzhou and Chen, Danqi , booktitle =
-
[16]
Xiao, Teng and others , booktitle =
-
[17]
Advances in Neural Information Processing Systems , year =
Noise Contrastive Alignment of Language Models with Explicit Rewards , author =. Advances in Neural Information Processing Systems , year =
-
[18]
International Conference on Machine Learning , year =
Linear Mode Connectivity and the Lottery Ticket Hypothesis , author =. International Conference on Machine Learning , year =
-
[19]
International Conference on Learning Representations , year =
Git Re-Basin: Merging Models Modulo Permutation Symmetries , author =. International Conference on Learning Representations , year =
-
[20]
International Conference on Machine Learning , year =
Similarity of Neural Network Representations Revisited , author =. International Conference on Machine Learning , year =
-
[21]
arXiv preprint , year =
-
[22]
Hu, Edward J and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =
-
[23]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author =. arXiv preprint arXiv:2110.14168 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Interpreting
nostalgebraist , booktitle =. Interpreting. 2020 , howpublished =
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.