XFP: Quality-Targeted Adaptive Codebook Quantization with Sparse Outlier Separation for LLM Inference
Pith reviewed 2026-06-30 21:25 UTC · model grok-4.3
The pith
XFP inverts LLM quantization so the operator sets per-channel cosine similarity floors and the method automatically selects codebook size, outlier budget, and packing without calibration data or Hessian.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
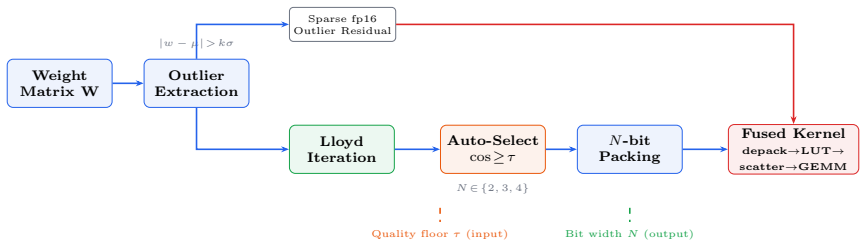
XFP decomposes each weight matrix into a sparse fp16 outlier residual and a dense sub-byte index tensor into a per-group learned codebook; codebook size, outlier budget, and packing are chosen automatically from operator-specified per-channel cosine similarity floors (strict for attention and shared experts, lazy for routed experts); two storage modes (V2 per-channel Lloyd, V2a shared library of 32 codebooks) share the same frontend and fused kernel; the H-Process iterates the floors inside an OOM boundary and a garbage-generation boundary to fit models into target memory.
What carries the argument
Per-channel cosine similarity floor (strict or lazy) that drives automatic selection of codebook size and outlier budget, together with the H-Process iteration over those floors.
If this is right
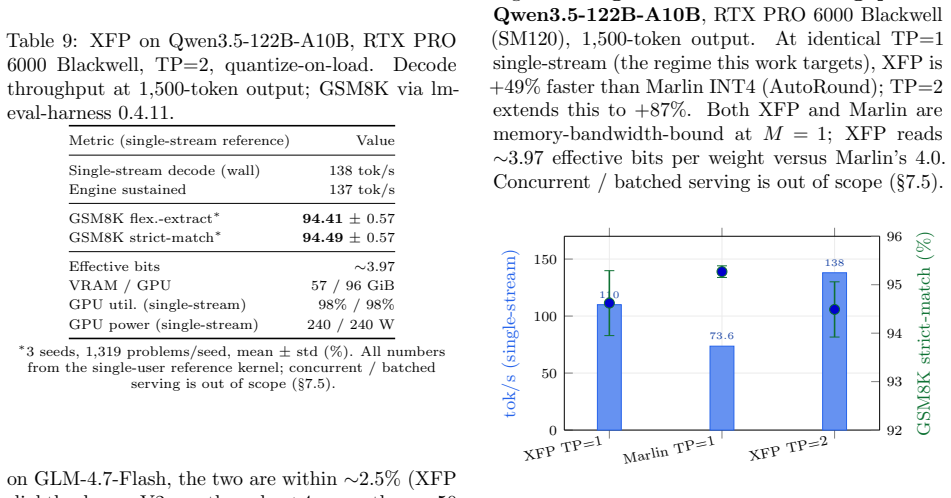
- On Qwen3.5-122B-A10B under V2 the method reaches 138 tok/s at 94.49% GSM8K and is 49% faster than Marlin INT4 at TP=1.
- On Qwen3.5-397B-A17B the H-Process fits the full expert population into 2x96 GB at approximately 3.4 effective bits while delivering 100.9 tok/s at 66.72% GSM8K.
- The same thresholds and iteration exceed INT4 with routed-expert pruning on memory, throughput, and accuracy simultaneously.
- V2 and V2a modes share one auto-select frontend and one fused decode kernel.
Where Pith is reading between the lines
- The method could allow operators to adjust quality-memory trade-offs on the fly for a given hardware envelope without re-deriving Hessians.
- If cosine similarity continues to track output quality across new model families, the same floors might serve as a portable control signal for other compression schemes.
- The absence of calibration data requirements could simplify deployment pipelines for models that change frequently or must run on air-gapped systems.
Load-bearing premise
That operator-specified per-channel cosine similarity floors plus the H-Process iteration are sufficient to guarantee sensible generation output without any calibration data or post-selection verification.
What would settle it
Apply the same cosine floors to a new model or benchmark set and check whether accuracy falls below the reported GSM8K levels or generation produces incoherent text before the stated thresholds are reached.
Figures

read the original abstract
We introduce XFP, a dynamic weight quantizer for LLM inference that inverts the conventional workflow: the operator specifies reconstruction quality floors on per-channel cosine similarity (one strict floor for attention and shared experts, one lazy floor for routed-expert MoE); XFP determines codebook size, outlier budget, and packing per layer automatically -- no Hessian, no calibration data, no manual bit-width selection. Each weight matrix is decomposed into a sparse fp16 outlier residual and a dense sub-byte index tensor into a per-group learned codebook. Two storage modes share one auto-select frontend and one fused decode kernel: V2 (per-channel Lloyd) and V2a (shared library of L=32 codebooks per layer). On Qwen3.5-122B-A10B under V2, XFP reaches 138 tok/s single-stream decode on workstation hardware (RTX PRO 6000 Blackwell, TP=2) at 94.49% GSM8K strict-match (3 seeds, n=3957), and is 49% faster than Marlin INT4 at TP=1. For models that do not fit in the target memory envelope, we present the H-Process: a quality-driven iteration over the two cosine thresholds that finds the operating point at which the model just fits while still producing sensible output. Three constraints define its search space: the operator-set thresholds, an OOM boundary at quantize-on-load, and a garbage boundary in generation (cosine similarity steers; benches verify). On Qwen3.5-397B-A17B (512 routed experts/layer), the H-Process fits the full expert population into 2x96 GB at ~3.4 effective bits and delivers 100.9 tok/s long-output decode at 66.72% GSM8K strict-match on the full 1319-problem set (single seed at submission; multi-seed evaluation in progress), exceeding INT4 with routed-expert pruning on memory, throughput, and accuracy simultaneously.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces XFP, a dynamic weight quantizer for LLM inference that inverts the conventional workflow by having the operator specify per-channel cosine similarity reconstruction quality floors (one strict for attention/shared experts, one lazy for routed experts in MoE); the method then automatically determines codebook size, outlier budget, and packing per layer with no Hessian, no calibration data, and no manual bit-width selection. Each weight matrix is decomposed into a sparse FP16 outlier residual and a dense sub-byte index tensor into a per-group learned codebook, supporting two storage modes (V2 per-channel Lloyd and V2a shared library of L=32 codebooks) that share an auto-select frontend and fused decode kernel. For models exceeding memory limits, the H-Process performs a quality-driven iteration over the two cosine thresholds subject to OOM and garbage boundaries (with 'cosine similarity steers; benches verify') to find a fitting operating point. The abstract reports concrete results on Qwen3.5-122B-A10B (138 tok/s at 94.49% GSM8K) and Qwen3.5-397B-A17B (~3.4 effective bits, 100.9 tok/s at 66.72% GSM8K), claiming simultaneous gains over INT4 with routed-expert pruning on memory, throughput, and accuracy.
Significance. If the central claims hold, the work would be significant for simplifying deployment of very large MoE models by providing an automatic, calibration-free quantization path that targets memory envelopes while preserving generation quality. The H-Process and dual storage modes with fused kernels address practical constraints for models like the 397B variant on 2x96 GB hardware, and the reported throughput/accuracy numbers suggest potential advantages over existing INT4 baselines. Strengths include the parameter-free frontend once floors are set and the explicit handling of routed experts. However, the significance depends on resolving whether cosine floors serve as a reliable proxy without hidden data dependence.
major comments (2)
- [Abstract] Abstract (H-Process paragraph): The central claim that XFP requires 'no calibration data' and operates automatically is load-bearing, yet the H-Process is described as locating the operating point via iteration where 'cosine similarity steers; benches verify' the garbage boundary. This indicates that threshold selection and validation rely on running generation benchmarks, which is a form of data-dependent post-hoc verification and directly contradicts the no-calibration assertion.
- [Abstract] Abstract: No correlation study, ablation, or error-propagation analysis is referenced showing that operator-specified per-channel cosine similarity floors track downstream token-level quality metrics (e.g., perplexity or GSM8K accuracy) across dense and MoE layers. Without this, the premise that the floors plus H-Process iteration suffice to guarantee 'sensible output' independently of benchmarks is unsupported, placing the automatic and calibration-free properties at risk.
minor comments (1)
- [Abstract] Abstract: The reported numbers (e.g., 100.9 tok/s, 66.72% GSM8K on 1319-problem set) would benefit from explicit statement of the exact hardware (beyond 'workstation hardware'), number of seeds, and precise INT4 baseline configuration for immediate assessment of the simultaneous gains claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract and the calibration-free claims. The points identify areas where the presentation could be tightened to better separate the core algorithm from the optional H-Process. We respond point-by-point below and will make the indicated revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract (H-Process paragraph): The central claim that XFP requires 'no calibration data' and operates automatically is load-bearing, yet the H-Process is described as locating the operating point via iteration where 'cosine similarity steers; benches verify' the garbage boundary. This indicates that threshold selection and validation rely on running generation benchmarks, which is a form of data-dependent post-hoc verification and directly contradicts the no-calibration assertion.
Authors: We agree the abstract wording risks conflating two distinct stages. The core XFP quantization procedure is strictly calibration-free: given only the operator-specified per-channel cosine floors, it automatically selects codebook size, outlier budget, and packing without any data, Hessian, or benchmark runs. The H-Process is an optional outer loop invoked solely when the model exceeds the target memory envelope; its benchmark verification step is used only to locate the garbage boundary for that specific deployment scenario. We will revise the abstract to explicitly separate the no-calibration quantization algorithm from the optional H-Process verification, and we will add a clarifying sentence in the H-Process section stating that benchmark checks are a practical safeguard rather than part of the quantization itself. revision: yes
-
Referee: [Abstract] Abstract: No correlation study, ablation, or error-propagation analysis is referenced showing that operator-specified per-channel cosine similarity floors track downstream token-level quality metrics (e.g., perplexity or GSM8K accuracy) across dense and MoE layers. Without this, the premise that the floors plus H-Process iteration suffice to guarantee 'sensible output' independently of benchmarks is unsupported, placing the automatic and calibration-free properties at risk.
Authors: We acknowledge that the manuscript does not contain a dedicated correlation or ablation study linking the cosine floors to token-level metrics. The design choice rests on cosine similarity being a standard, layer-wise reconstruction metric in vector quantization, and the reported end-to-end results on Qwen3.5 models show that the selected floors preserve competitive accuracy. To strengthen the justification, we will add a new subsection (or appendix) that reports the observed correlation between per-channel cosine similarity and downstream metrics (perplexity and task accuracy) on representative attention, shared-expert, and routed-expert layers from both dense and MoE models. This addition will provide the requested empirical grounding without altering the core claims. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents XFP as a procedural method that takes operator-specified per-channel cosine similarity floors as explicit inputs and derives codebook size, outlier budget, and packing from them via decomposition into sparse fp16 residuals and dense sub-byte index tensors. The H-Process is described as an iteration over those same operator-set thresholds to satisfy memory/OOM constraints while meeting a garbage boundary verified externally by benchmarks. No equation or step equates the derived parameters to the input floors by construction, no parameter is fitted on data and then relabeled as a prediction, and no self-citation chain or uniqueness theorem is invoked to justify the core choices. The derivation remains self-contained as an input-driven search procedure whose outputs are not definitionally identical to its inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-channel cosine similarity floors
axioms (1)
- domain assumption Cosine similarity between original and reconstructed weights is a sufficient proxy for downstream generation quality
Reference graph
Works this paper leans on
-
[1]
L. Gao, J. Tow, B. Abbasi, S. Biderman, S. Black, A. DiPofi, C. Foster, L. Golding, J. Hsu, A. Le Noac'h, H. Li, K. McDonell, N. Muennighoff, C. Ociepa, J. Phang, L. Reynolds, H. Schoelkopf, A. Skowron, L. Sutawika, E. Tang, A. Thite, B. Wang, K. Wang, and A. Zou. A framework for few-shot language model evaluation. https://github.com/EleutherAI/lm-evaluat...
2024
- [2]
-
[3]
Dettmers, M
T. Dettmers, M. Lewis, Y. Belkada, and L. Zettlemoyer. LLM.int8() : 8-bit Matrix Multiplication for Transformers at Scale. In NeurIPS, 2022
2022
-
[4]
T. Dettmers, R. Svirschevski, V. Egiazarian, D. Kuznedelev, E. Frantar, S. Ashkboos, A. Borzunov, T. Hoefler, and D. Alistarh. SpQR : A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression. arXiv:2306.03078, 2023
-
[5]
Dettmers, A
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer. QLoRA : Efficient Finetuning of Quantized LLMs. In NeurIPS, 2023
2023
-
[6]
Egiazarian, A
V. Egiazarian, A. Panferov, D. Kuznedelev, E. Frantar, A. Babenko, and D. Alistarh. AQLM : Extreme Compression of Large Language Models via Additive Quantization. In ICML, 2024
2024
-
[7]
Frantar, S
E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh. GPTQ : Accurate Post-Training Quantization for Generative Pre-trained Transformers. In ICLR, 2023
2023
- [8]
-
[9]
Frantar and D
E. Frantar and D. Alistarh. Marlin : Near-Ideal 4-Bit LLM Inference on NVIDIA GPUs. GitHub, IST Austria, 2024
2024
-
[10]
B. Marie. NVFP4 : Same Accuracy with 2.3x Higher Throughput for 4-Bit LLMs. The Kaitchup -- AI on a Budget, 2025
2025
-
[11]
TensorRT Model Optimizer : Post-Training Quantization for LLMs
NVIDIA. TensorRT Model Optimizer : Post-Training Quantization for LLMs. https://github.com/NVIDIA/TensorRT-Model-Optimizer, 2024
2024
-
[12]
Gerganov et al
G. Gerganov et al. llama.cpp. https://github.com/ggerganov/llama.cpp, 2023
2023
-
[13]
Lasby et al
M. Lasby et al. REAP : Reaping Experts for Activation-Aware Pruning of MoE Models. arXiv preprint, 2024
2024
- [14]
-
[15]
W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. Yu, J. Gonzalez, H. Zhang, and I. Stoica. Efficient Memory Management for Large Language Model Serving with PagedAttention . In SOSP, 2023
2023
-
[16]
J. Lin, J. Tang, H. Tang, S. Yang, X. Dang, and S. Han. AWQ : Activation-aware Weight Quantization for LLM Compression and Acceleration. In MLSys, 2024
2024
-
[17]
S.P. Lloyd. Least Squares Quantization in PCM . IEEE Trans.\ Information Theory, 28(2):129--137, 1982
1982
-
[18]
NVFP4 Tensor Core Quantization---Blackwell Architecture Whitepaper
NVIDIA. NVFP4 Tensor Core Quantization---Blackwell Architecture Whitepaper. 2024
2024
-
[19]
OCP Microscaling ( MX ) Specification, v1.0
Open Compute Project. OCP Microscaling ( MX ) Specification, v1.0. 2023
2023
-
[20]
A. Tseng, J. Chee, Q. Sun, V. Kuleshov, and C. De Sa. QuIP\# : Even Better LLM Quantization with Hadamard Incoherence and Lattice Codebooks. arXiv:2402.04396, 2024
-
[21]
Qtip: Quantiza- tion with trellises and incoherence processing,
A. Tseng, Q. Sun, D. Yin, C. De Sa, and V. Kuleshov. QTIP : Quantization with Trellises and Incoherence Processing. arXiv:2406.11235, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.