Geometry of Human Perceptual Domains Emerges Transiently in LLM Representations
Pith reviewed 2026-06-29 12:28 UTC · model grok-4.3
The pith
LLM residual streams develop human-like perceptual geometry in middle layers that later attenuates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
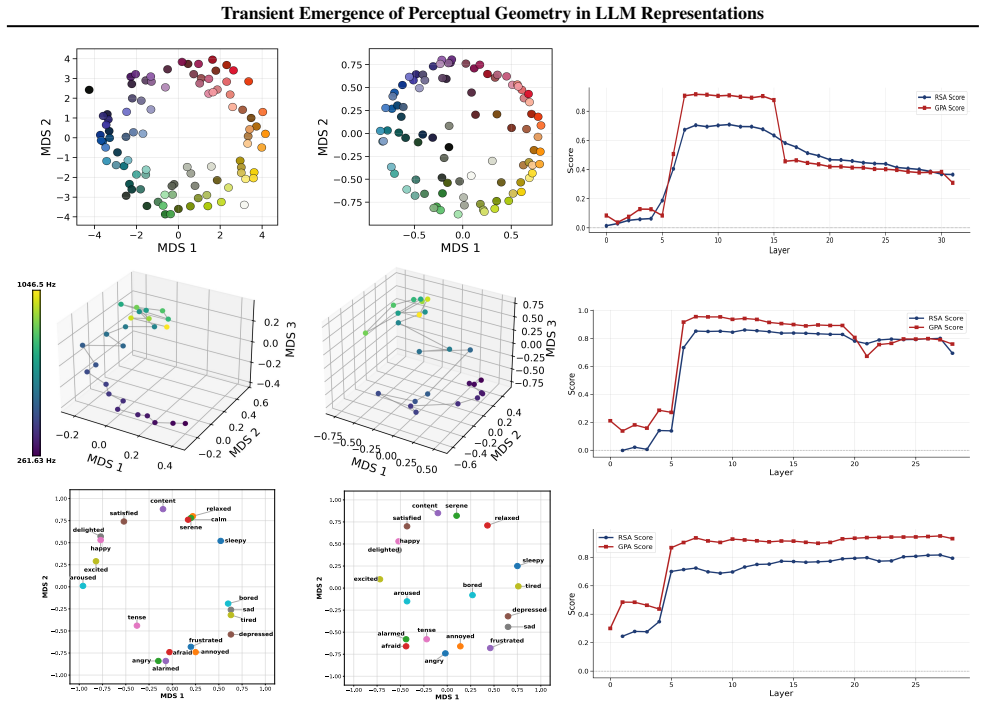
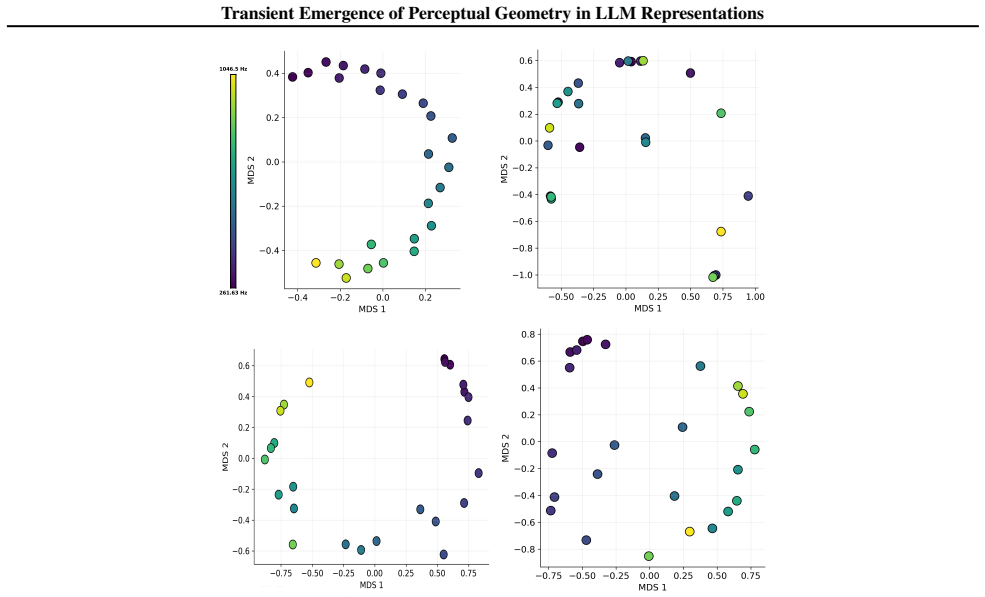
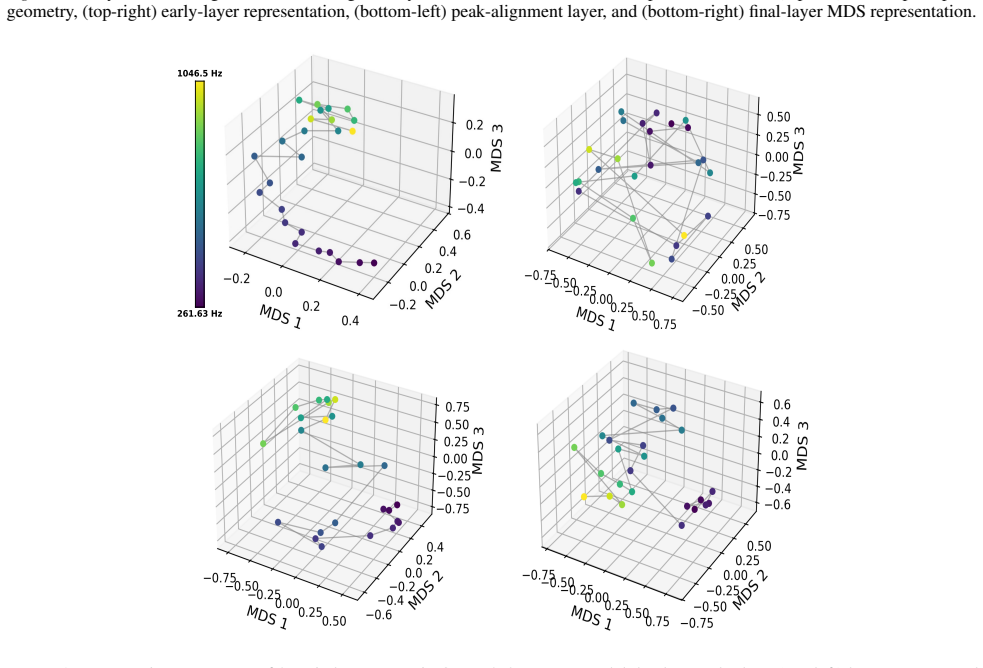
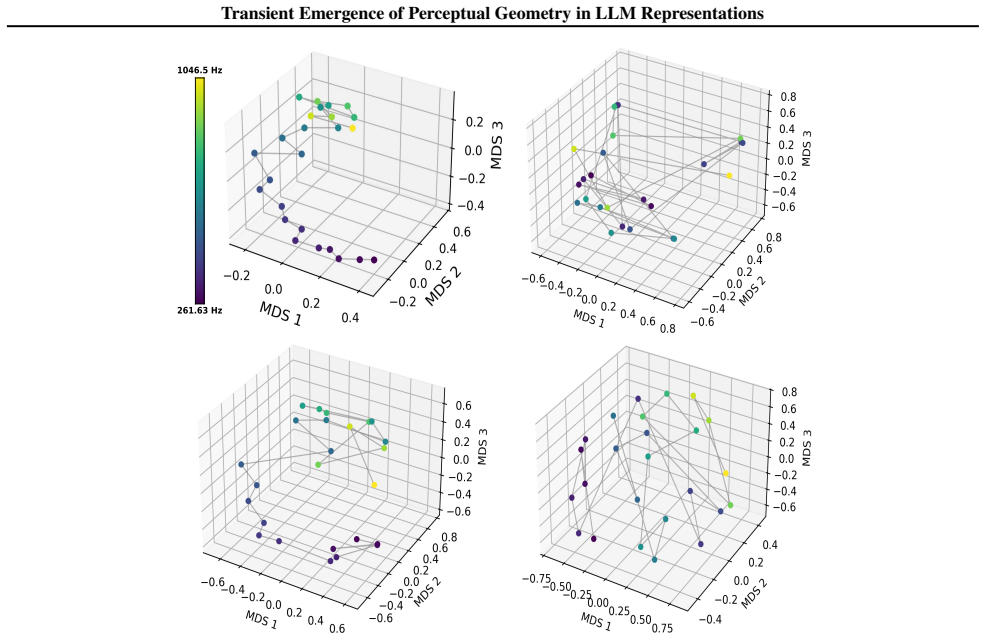
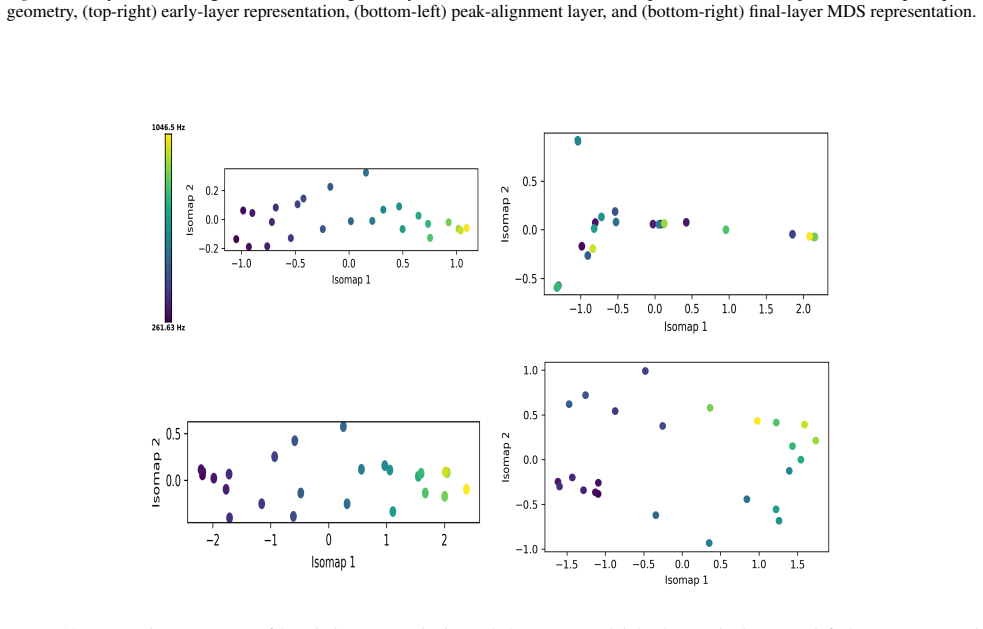
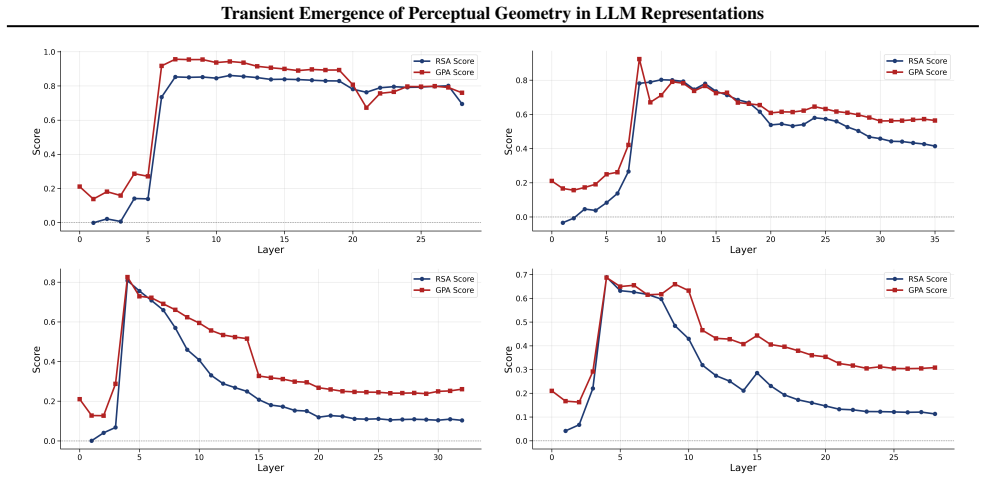
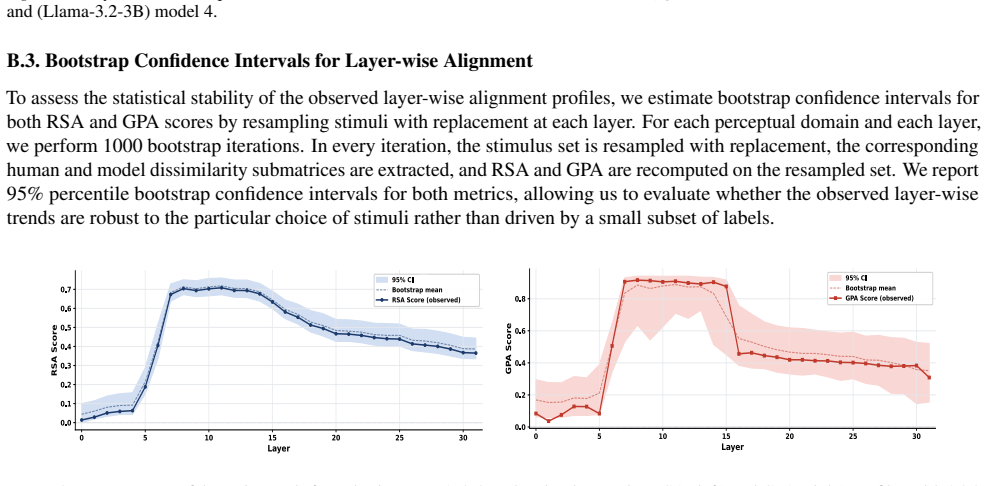
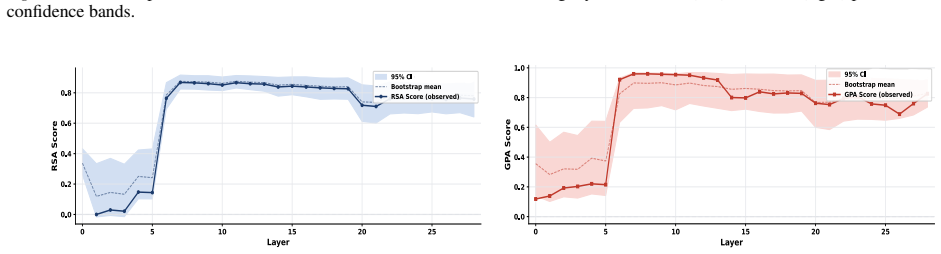
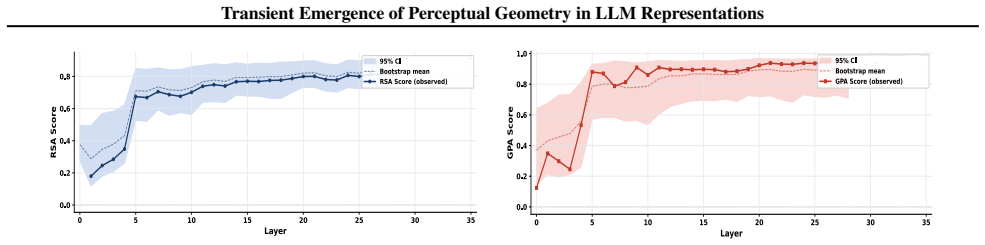
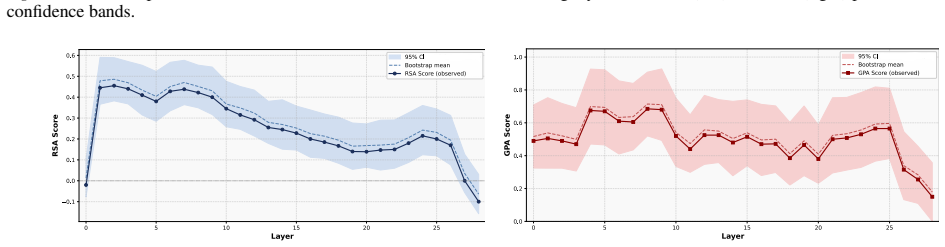
The paper claims that geometric structure corresponding to perceptual modalities emerges transiently in the residual streams of transformer LLMs: it is weak or diffuse in early layers, becomes progressively organised in intermediate layers, and is attenuated in later layers, with both the structure itself and its alignment to human baselines showing domain- and model-specific trajectories across depth.
What carries the argument
Layer-wise measurement of geometric structure in residual-stream embeddings compared against human perceptual baselines across multiple domains.
Load-bearing premise
Quantitative measures of geometric structure in residual-stream embeddings can be meaningfully compared to human perceptual baselines across domains using appropriate similarity metrics.
What would settle it
Observing a model or perceptual domain in which geometric alignment with human baselines does not strengthen in intermediate layers and weaken in later layers would falsify the claimed consistent representational trajectory.
Figures



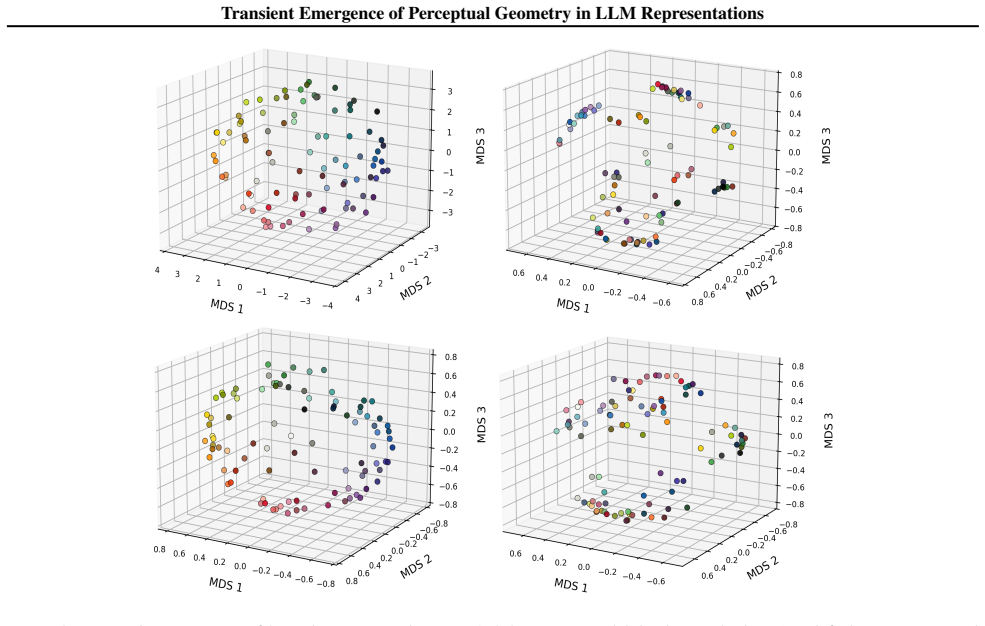
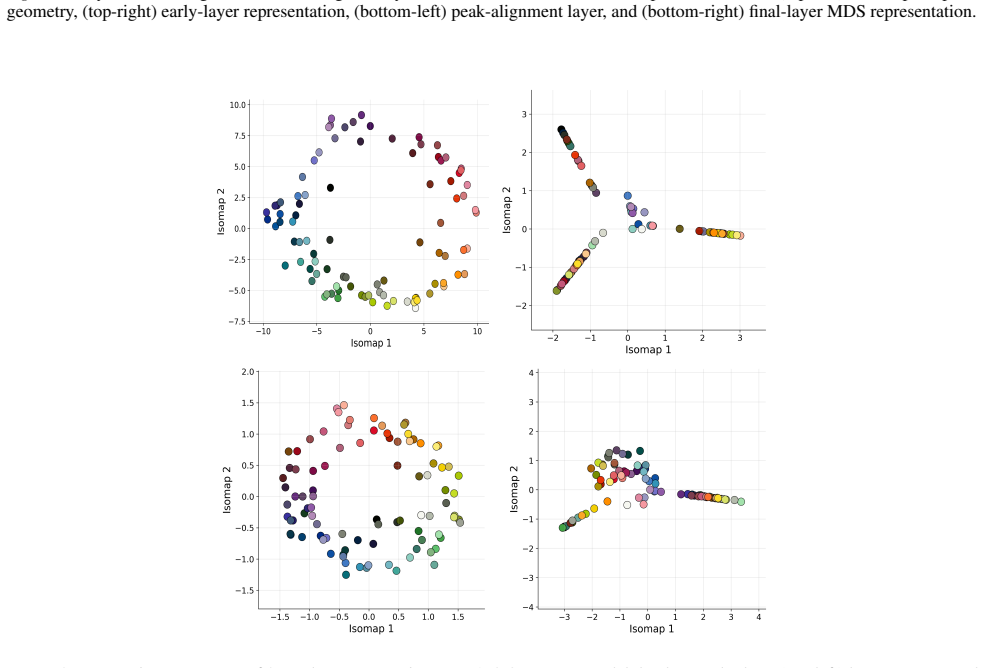
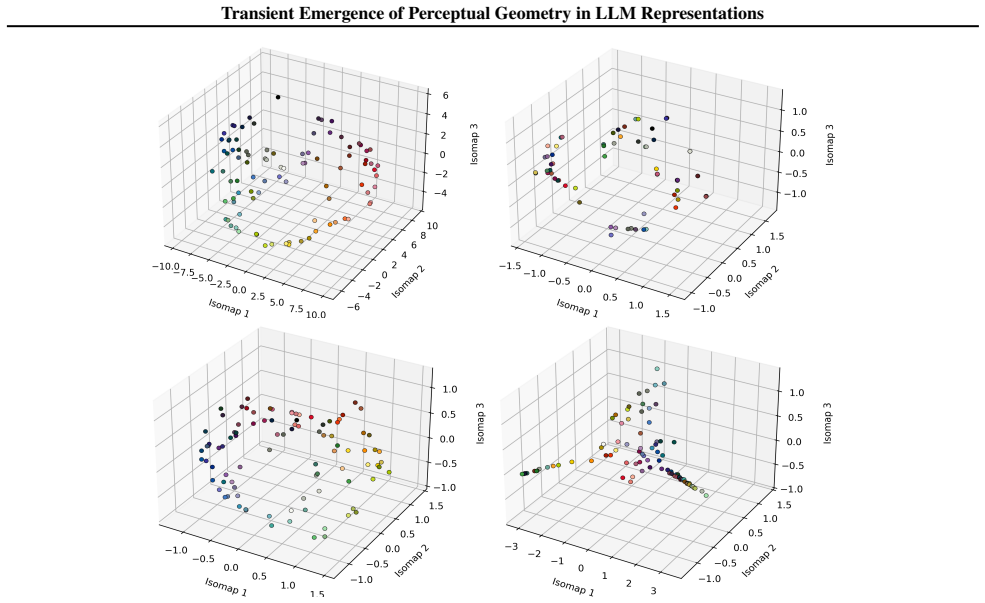
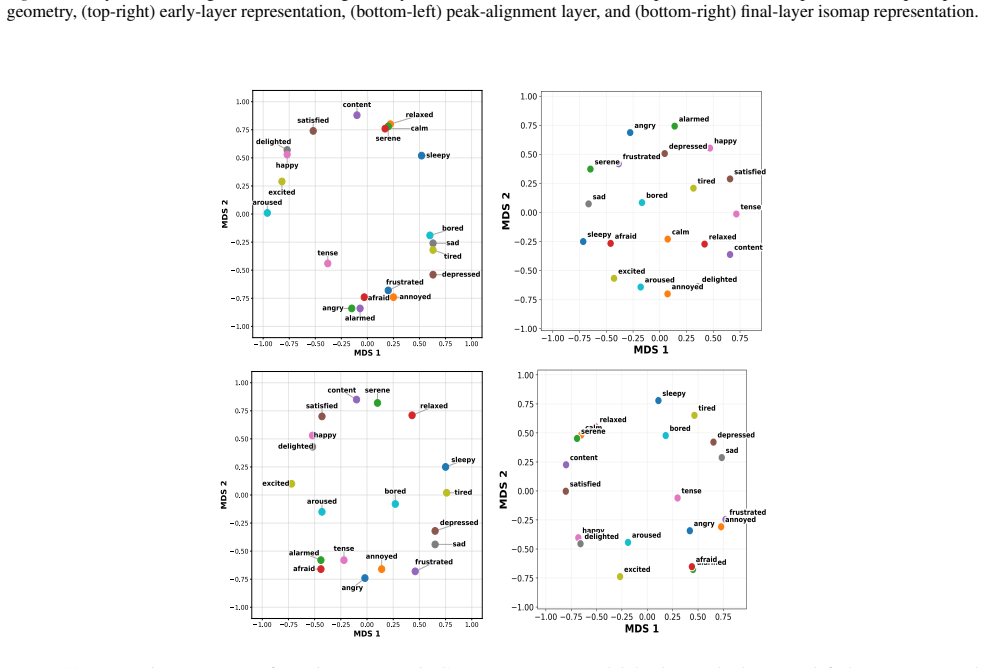
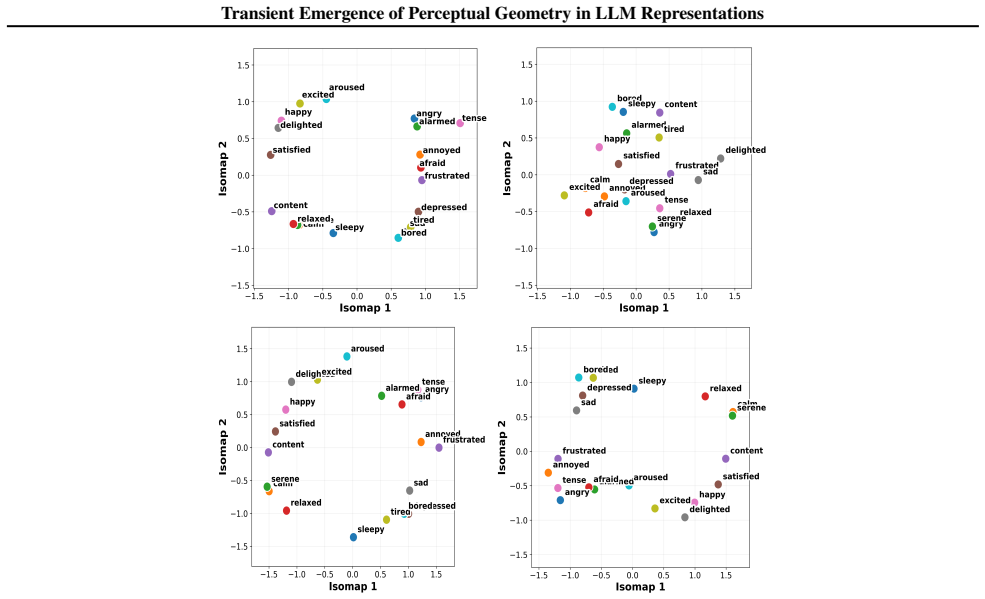
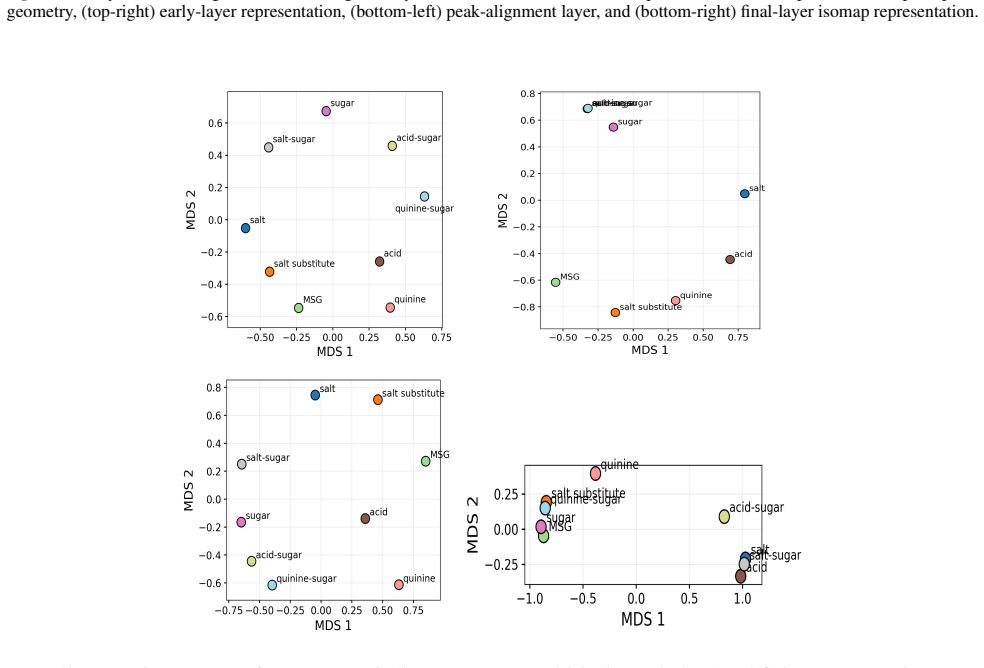
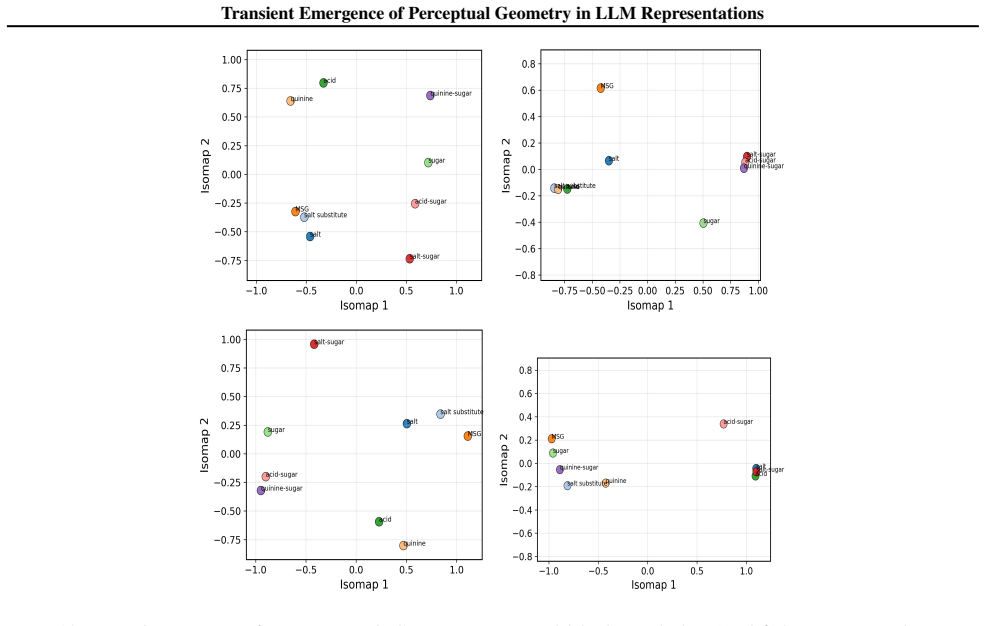
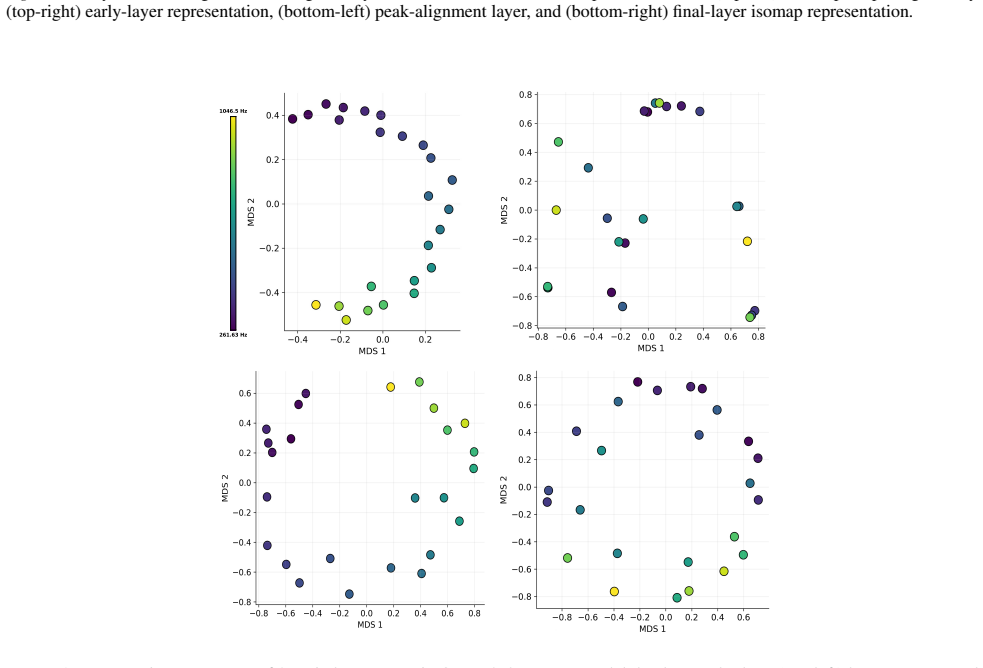
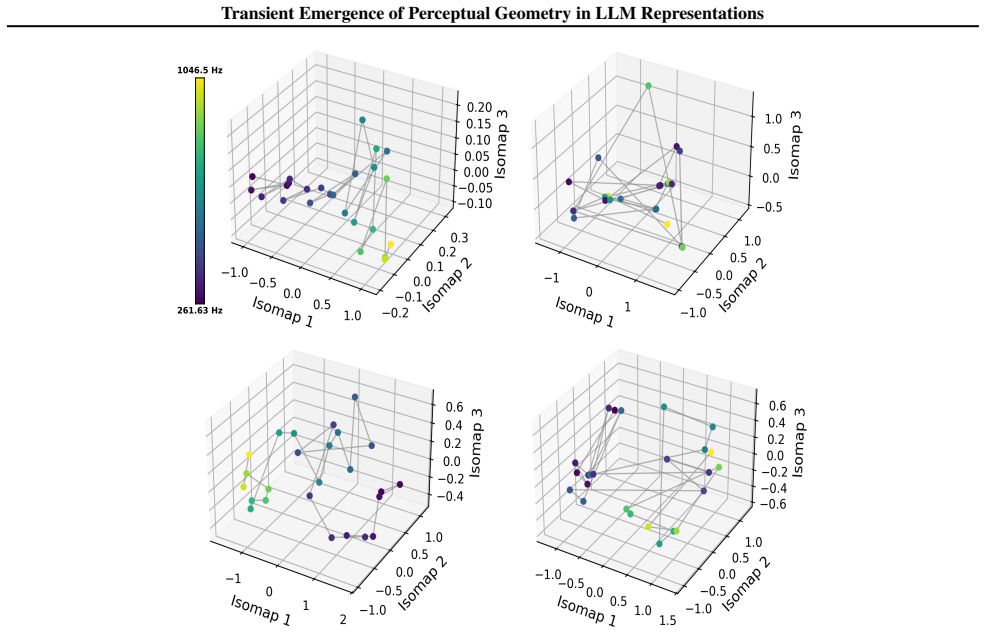
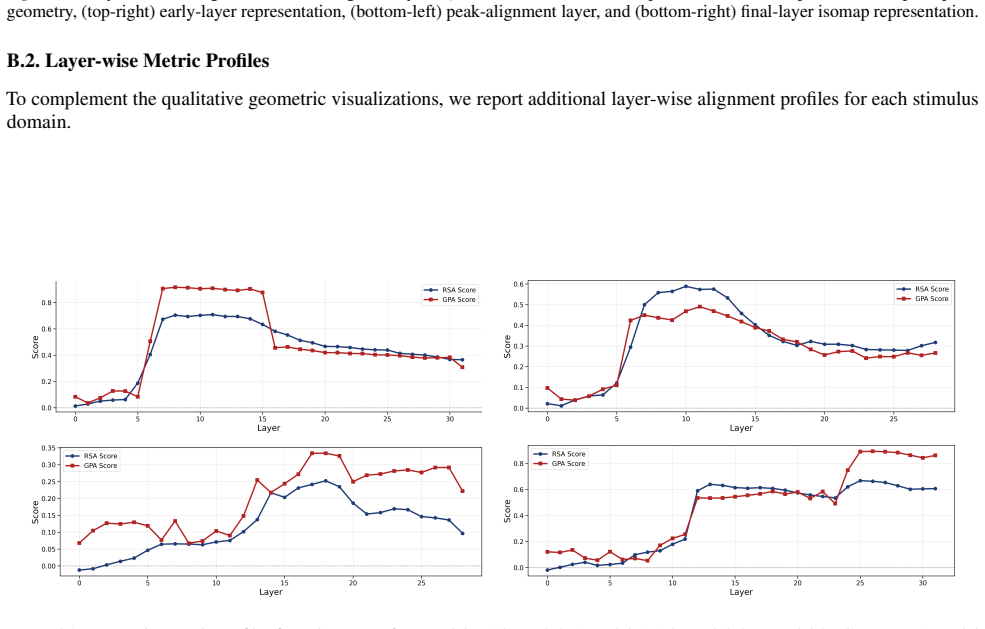
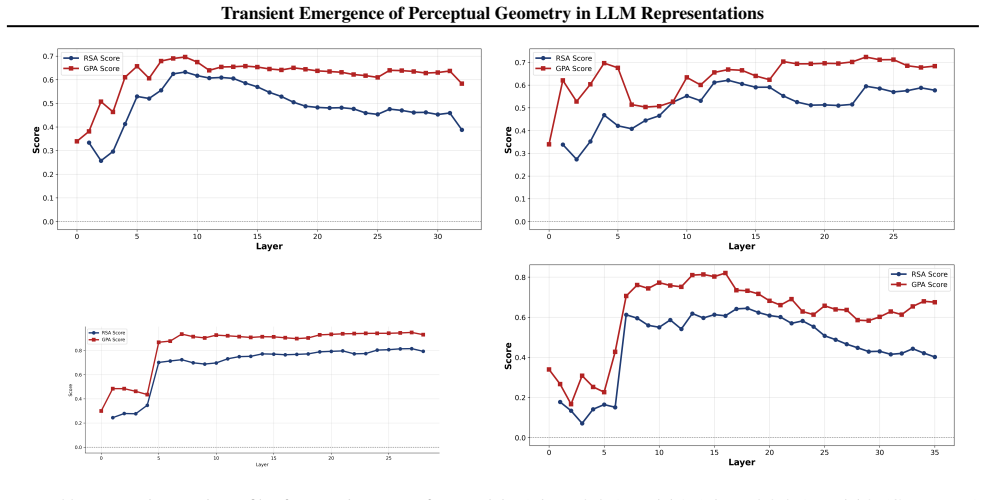
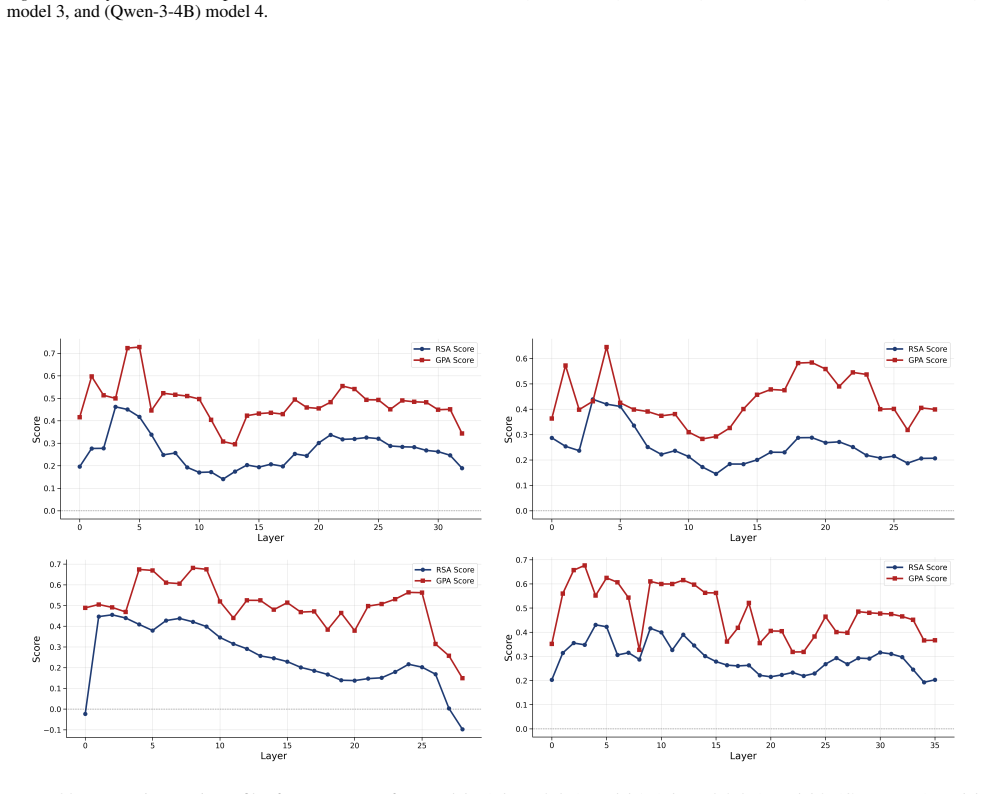
read the original abstract
While large language models (LLMs) are trained purely on textual data, prior work has shown that their internal representations can exhibit rich geometric structure in embedding space. Building on this line of work, we investigate whether such structure is similar to human perceptual organisation across different domains (e.g., color, pitch, emotion, and taste). Specifically, we study the layer-wise emergence of intrinsic geometrical structure corresponding to perceptual modalities within the residual streams of multiple open-weight transformer architectures. Our results reveal three key findings. First, we observe the emergence of layer-wise geometric structure across multiple perceptual domains, despite the absence of any direct perceptual supervision during training. Second, these perceptual domains exhibit distinct emergence profiles, with both geometric structure and its alignment with human baselines following domain- and model-specific trajectories across depth. Third, this emergence follows a consistent representational trajectory: geometry is weak or diffuse in early layers, becomes progressively organised in intermediate layers, and is attenuated in later layers, suggesting that perceptual geometry arises transiently as part of the model's internal transformation pipeline. This provides new insight into how and where human-like perceptual geometry arises in LLMs, offering a principled pathway for mechanistic analysis of internal representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines layer-wise emergence of geometric structure in the residual streams of multiple open-weight transformer LLMs, focusing on whether this structure corresponds to human perceptual organization across domains such as color, pitch, emotion, and taste. It reports three main findings: (1) geometric structure emerges despite purely textual training, (2) domains show distinct emergence profiles with model-specific trajectories in both intrinsic geometry and alignment to human baselines, and (3) the structure is weak early, peaks in intermediate layers, and attenuates later, indicating transient emergence within the model's transformation pipeline.
Significance. If the quantitative alignments hold under rigorous controls, the work supplies a concrete, layer-resolved map of how perceptual-like geometry arises in LLMs. This supplies a falsifiable, depth-dependent signature that can be used for mechanistic interpretability and for testing whether such geometry is an incidental byproduct of next-token prediction or a functional intermediate representation.
major comments (3)
- [§4] §4 (Results on human alignment): the central claim that measured geometries align with human perceptual baselines requires explicit specification of the human similarity matrices or perceptual datasets employed for each domain and the precise comparison procedure (e.g., Mantel test, Procrustes, or nearest-neighbor overlap). Without these details or controls for textual co-occurrence statistics, the reported trajectories could be driven by linguistic rather than perceptual structure.
- [§3.2] §3.2 (Metric definitions): the intrinsic geometric measures (whatever distance or manifold statistics are applied to residual-stream embeddings of domain words) are not shown to be robust to alternative choices of stimuli or to control domains lacking perceptual structure; this leaves open whether the reported transient peak is specific to perceptual domains or an artifact of word-selection or embedding-norm effects.
- [Figure 3] Figure 3 / Table 2 (trajectory plots): the domain- and model-specific emergence profiles are presented without statistical tests for the intermediate-layer peak or for the attenuation in later layers; if the peak is within the noise envelope of early/late layers for some domains, the “transient” characterization is not yet load-bearing.
minor comments (2)
- [Abstract] The abstract states “despite the absence of any direct perceptual supervision,” but the manuscript should cite the exact training corpora and confirm that no perceptual or multimodal data were present.
- [§3] Notation for residual-stream indices and layer numbering should be standardized across figures and text to avoid ambiguity when comparing models of different depths.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify opportunities to improve clarity, robustness, and statistical support. We address each major point below, indicating revisions that will be incorporated.
read point-by-point responses
-
Referee: §4 (Results on human alignment): the central claim that measured geometries align with human perceptual baselines requires explicit specification of the human similarity matrices or perceptual datasets employed for each domain and the precise comparison procedure (e.g., Mantel test, Procrustes, or nearest-neighbor overlap). Without these details or controls for textual co-occurrence statistics, the reported trajectories could be driven by linguistic rather than perceptual structure.
Authors: We agree that full specification of the human baselines, comparison procedures, and linguistic controls is required for interpretability. The revised manuscript will add an explicit methods subsection listing the exact perceptual datasets (color similarities from established psychophysical matrices, pitch from musical interval studies, emotion from valence-arousal norms, taste from gustatory similarity ratings), the alignment metric (Procrustes superposition with permutation-based significance testing), and new controls that subtract co-occurrence statistics derived from the pretraining corpus. These additions will directly address whether the observed alignments exceed what linguistic statistics alone would predict. revision: yes
-
Referee: §3.2 (Metric definitions): the intrinsic geometric measures (whatever distance or manifold statistics are applied to residual-stream embeddings of domain words) are not shown to be robust to alternative choices of stimuli or to control domains lacking perceptual structure; this leaves open whether the reported transient peak is specific to perceptual domains or an artifact of word-selection or embedding-norm effects.
Authors: We accept that additional robustness demonstrations are needed. The revision will include (i) results with alternative stimulus sets drawn from independent lexical resources for each domain, (ii) parallel analyses on matched control domains lacking perceptual structure (e.g., abstract nouns matched for frequency and length), and (iii) recomputation after L2-normalization of embeddings to isolate geometry from norm effects. These controls will be reported alongside the original measures to test specificity of the transient peak. revision: yes
-
Referee: Figure 3 / Table 2 (trajectory plots): the domain- and model-specific emergence profiles are presented without statistical tests for the intermediate-layer peak or for the attenuation in later layers; if the peak is within the noise envelope of early/late layers for some domains, the “transient” characterization is not yet load-bearing.
Authors: We concur that formal statistical assessment of the peaks and attenuation is necessary. The revised figures and tables will incorporate bootstrap-derived confidence intervals around each layer’s geometric measure, together with permutation tests comparing the intermediate-layer value against the distribution of early- and late-layer values. These tests will be performed per domain and model, allowing readers to evaluate whether the transient pattern is statistically supported or falls within noise. revision: yes
Circularity Check
No circularity; claims rest on independent empirical measurements.
full rationale
The abstract and provided text describe empirical observations of layer-wise geometric structure in residual-stream embeddings across perceptual domains, with alignment to human baselines reported as a measured outcome rather than a definitional or fitted input. No equations, parameter-fitting procedures, self-citations, or uniqueness theorems are visible that would reduce any prediction to its own inputs by construction. The derivation chain consists of direct analysis of model internals against external human data, with no self-definitional steps or renamings of known results presented as novel derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2109.06129 , year=
URL https://arxiv.org/abs/ 2109.06129. Alain, G. and Bengio, Y . Understanding intermediate layers using linear classifier probes,
-
[2]
Understanding intermediate layers using linear classifier probes
URL https:// arxiv.org/abs/1610.01644. Bradley, M. M. and Lang, P. J. Affective norms for english words (anew): Instruction manual and affective ratings. Technical report. URL https://pdodds.w3.uvm.edu/teaching/ courses/2009-08UVM-300/docs/others/ everything/bradley1999a.pdf. Choi, B. J. and Weber, M. Latent structure of affective representations in large...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[3]
Latent Structure of Affective Representations in Large Language Models
URL https://arxiv.org/abs/2604.07382. Dar, G., Geva, M., Gupta, A., and Berant, J. Analyzing transformers in embedding space,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
URL https: //arxiv.org/abs/2209.02535. Engels, J., Michaud, E. J., Liao, I., Gurnee, W., and Tegmark, M. Not all language model features are one- dimensionally linear,
-
[5]
Michaud, Isaac Liao, Wes Gurnee, and Max Tegmark
URL https://arxiv. org/abs/2405.14860. Gurnee, W. and Tegmark, M. Language models represent space and time,
-
[6]
arXiv preprint arXiv:2310.02207 , year=
URL https://arxiv.org/ abs/2310.02207. Gurnee, W., Ameisen, E., Kauvar, I., Tarng, J., Pearce, A., Olah, C., and Batson, J. When models manipulate manifolds: The geometry of a counting task,
- [7]
-
[8]
URL https: //arxiv.org/abs/2602.15029. Kruskal, J. B. Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis.Psychometrika, 29(1):1–27, Mar
-
[9]
Marjieh, R., Sucholutsky, I., van Rijn, P., Jacoby, N., and Griffiths, T
URL https: //arxiv.org/abs/2502.10871. Marjieh, R., Sucholutsky, I., van Rijn, P., Jacoby, N., and Griffiths, T. L. Large language models predict human sensory judgments across six modalities,
-
[10]
Modell, A., Rubin-Delanchy, P., and Whiteley, N
URL https://arxiv.org/abs/2302.01308. Modell, A., Rubin-Delanchy, P., and Whiteley, N. The ori- gins of representation manifolds in large language mod- els,
-
[11]
URL https://www.researchgate.net/ publication/235361517_A_circumplex_ model_of_affect
doi: 10.1037/h0077714. URL https://www.researchgate.net/ publication/235361517_A_circumplex_ model_of_affect. Singh, C., Inala, J. P., Galley, M., Caruana, R., and Gao, J. Rethinking interpretability in the era of large lan- guage models,
-
[12]
URL https://arxiv.org/ abs/2402.01761. Skean, O., Arefin, M. R., LeCun, Y ., and Shwartz-Ziv, R. Does representation matter? exploring intermedi- ate layers in large language models,
-
[13]
URL https: //arxiv.org/abs/2412.09563. Skean, O., Arefin, M. R., Zhao, D., Patel, N., Naghiyev, J., LeCun, Y ., and Shwartz-Ziv, R. Layer by layer: Uncov- ering hidden representations in language models,
-
[14]
Layer by Layer: Uncovering Hidden Representations in Language Models
URLhttps://arxiv.org/abs/2502.02013. Sun, L., Yan, L., Lu, X., Lee, A., Zhang, J., and Shao, J. Valence-arousal subspace in llms: Circular emo- tion geometry and multi-behavioral control,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Valence-Arousal Subspace in LLMs: Circular Emotion Geometry and Multi-Behavioral Control
URL https://arxiv.org/abs/2604.03147. Taniguchi, T., Oizumi, M., Saji, N., Horii, T., and Tsuchiya, N. Constructive approach to bidirectional influence be- tween qualia structure and language emergence,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
The description of the color given as#HEXCODE
URLhttps://arxiv.org/abs/2409.09413. 5 Transient Emergence of Perceptual Geometry in LLM Representations A. Appendix A.1. Prompts Used We use a set of minimal, structured prompts to extract representations corresponding to each domain. The list of prompts used across modalities is provided below: Color:“The description of the color given as#HEXCODE” Emoti...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.