Bag of Dims: Training-Free Mechanistic Interpretability via Dimension-Level Sign Patterns
Pith reviewed 2026-06-27 10:29 UTC · model grok-4.3
The pith
Transformer hidden states encode semantic features directly via per-dimension sign patterns with no rotation or training required.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
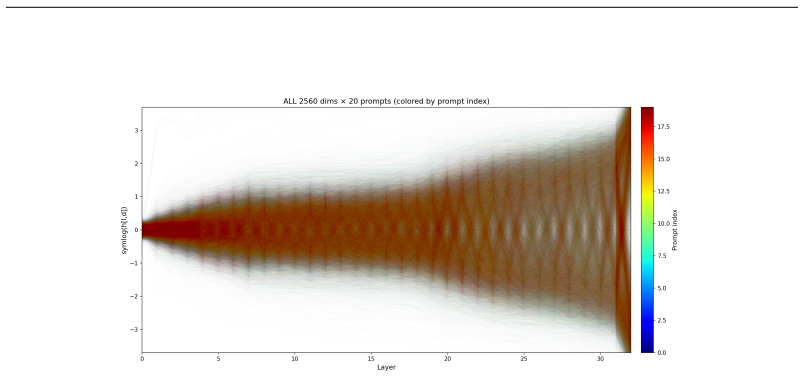
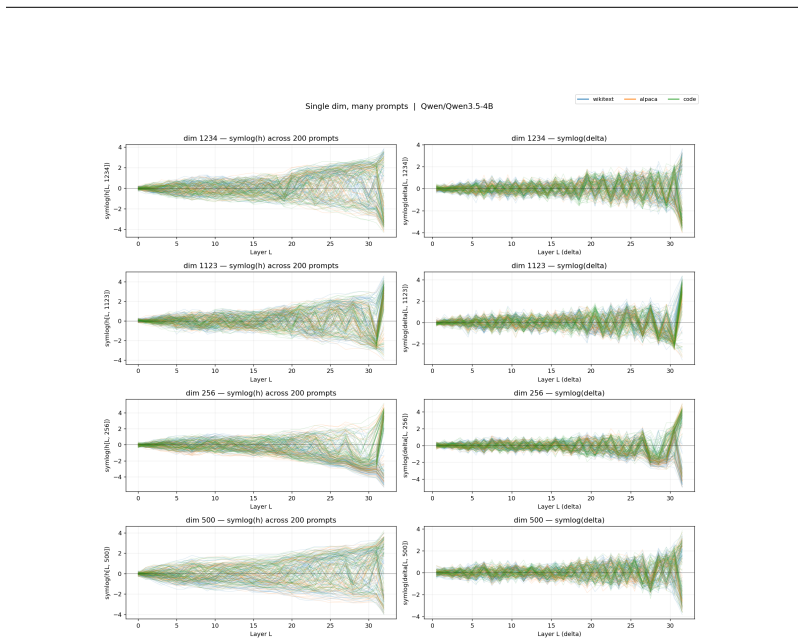
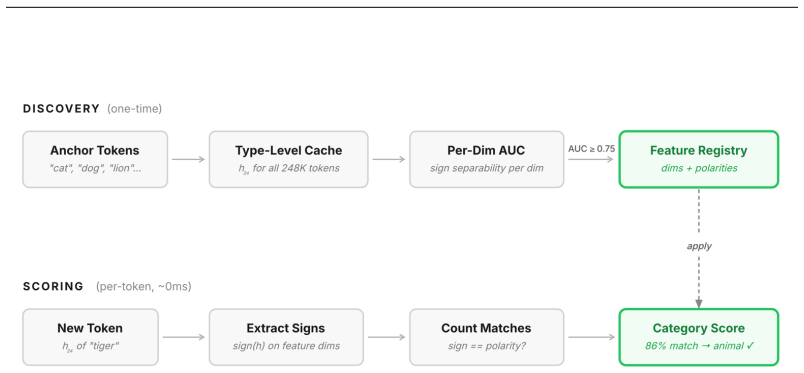
We show the standard basis of transformer hidden states already provides a training-free, architecture-general feature basis. Individual dimensions encode semantic content via their signs (+/-1) and confidence via their magnitudes, acting as independent binary registers; a feature is a subset of dimensions with a consistent sign pattern, read by counting sign agreements with no learned rotation. Signs alone carry predictive content: unit-magnitude sign patterns preserve 60-93% top-5 next-token accuracy through the LM head, and decoder-free Hamming scoring reaches 80-90% top-4096. From a single-token cache, we detect 175 categories at AUC 0.97-0.99 by sign agreement. These features are causal
What carries the argument
The Bag of Dims framework, where each hidden-state dimension functions as an independent binary register whose sign defines membership in feature patterns that are read by simple agreement counting.
If this is right
- Sign patterns alone suffice for high-accuracy category detection from a single forward pass per token with no context or labels.
- Flipping the signs of a detected feature during the forward pass suppresses the associated concept in a magnitude-matched, concept-specific way.
- The same sign-based structure appears in self-supervised vision, supervised vision, and audio models, indicating it arises from transformer training in general.
- Pairwise mutual information between dimensions stays below 0.006 bits, confirming they function as independent registers.
- A trained probe on top of the sign patterns adds only marginal AUC improvement and converges to axis-aligned weights.
Where Pith is reading between the lines
- Cataloging the meaning of each individual dimension could replace basis-search methods as the default first step when analyzing a new model.
- The cross-modal consistency suggests that future work could test whether similar sign structures appear in non-transformer architectures after standard training.
- If dimensions remain independent, interventions on one feature are unlikely to require explicit decorrelation steps.
- The one-pass nature of the method could enable rapid auditing of deployed models without additional optimization.
Load-bearing premise
That the sign patterns associated with a given semantic feature remain stable enough across inputs for agreement counting to reliably identify the feature, and that sign flips affect primarily the intended concept.
What would settle it
Finding that sign patterns for the same semantic category vary substantially across different input examples, or that targeted sign flips suppress unrelated concepts at comparable rates.
Figures


read the original abstract
We show the standard basis of transformer hidden states already provides a training-free, architecture-general feature basis. Individual dimensions encode semantic content via their signs (+/-1) and confidence via their magnitudes, acting as independent binary registers; a feature is a subset of dimensions with a consistent sign pattern, read by counting sign agreements with no learned rotation. We validate this Bag of Dims framework across seven models spanning language (Qwen 3.5-4B, Gemma 3-4B, Mistral 7B, Qwen3-32B), vision (DINOv2, ViT-Base), and audio (AST). Signs alone carry predictive content: unit-magnitude sign patterns preserve 60-93% top-5 next-token accuracy through the LM head, and decoder-free Hamming scoring reaches 80-90% top-4096. From a single-token cache (one forward pass per token, no context, no labels), we detect 175 categories at AUC 0.97-0.99 by sign agreement; a trained probe adds only +0.018 AUC and converges to axis-aligned weights. These features are causally operative: they survive the K/V attention projections, trace to the FFN neuron coalitions that write them (random-weight controls never reproduce this), and flipping a feature's signs during the live forward pass suppresses its concept across four language models, magnitude-matched and concept-specific. Dimensions stay independent throughout (pairwise mutual information below 0.006 bits). The structure is not specific to language: the same per-dimension signs appear in self-supervised vision (DINOv2, 9/12 ImageNet superclasses), supervised vision (ViT-Base, 11/12), and audio (AST, 50/50 ESC-50 categories), so it reflects transformer training in general, not the language-modeling objective. The standard basis already suffices for feature reading at one forward pass, no optimization, no GPU-days. The open problem shifts from finding the right rotation to cataloging what each dimension encodes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the standard basis of transformer hidden states already constitutes a training-free, architecture-general feature basis. Individual dimensions act as independent binary registers, encoding semantic content via their signs (+/-1) and confidence via magnitudes; a feature is a subset of dimensions sharing a consistent sign pattern, readable by simple sign-agreement counts with no learned rotation or optimization. This 'Bag of Dims' approach is validated across seven models (language: Qwen, Gemma, Mistral; vision: DINOv2, ViT; audio: AST), showing 60-93% next-token accuracy retention from unit-magnitude signs, 80-90% top-4096 via Hamming scoring, 0.97-0.99 AUC category detection from single-token caches, near-identical performance to trained probes, low pairwise mutual information (<0.006 bits), and successful causal interventions via sign flips that suppress targeted concepts.
Significance. If the central claims hold, the result would be significant: it reframes mechanistic interpretability by eliminating the need to search for rotations or train probes, shifting the open problem to cataloging per-dimension encodings. Strengths include the parameter-free nature, cross-modal generality (language/vision/audio), direct causal evidence via live interventions, and explicit reporting that random-weight controls fail to reproduce the patterns. The independence result and survival through K/V projections add to the mechanistic value.
major comments (2)
- [Abstract; single-token cache experiments] The claim that sign patterns define stable semantic features (Abstract) rests on consistency across inputs, yet all category detection (AUC 0.97-0.99) and accuracy results use single-token, no-context caches. No direct stability metric (e.g., fraction of matching signs between no-context and full-sequence activations for the same tokens) is reported; this is load-bearing because context-sensitive changes would undermine the 'consistent sign pattern' definition of a feature.
- [Causal intervention results] The causal claim that flipping a feature's signs 'suppresses its concept across four language models, magnitude-matched and concept-specific' requires a precise intervention protocol. The manuscript does not specify how dimensions belonging to a feature are selected for flipping, nor how effects from correlated dimensions or downstream nonlinearities are isolated; without this, the specificity of the interventions cannot be verified.
minor comments (1)
- [Abstract] The abstract states 'decoder-free Hamming scoring reaches 80-90% top-4096' but the exact scoring procedure, vocabulary size, and comparison baselines are not detailed in the provided text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of feature stability and intervention specificity. We address each major point below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract; single-token cache experiments] The claim that sign patterns define stable semantic features (Abstract) rests on consistency across inputs, yet all category detection (AUC 0.97-0.99) and accuracy results use single-token, no-context caches. No direct stability metric (e.g., fraction of matching signs between no-context and full-sequence activations for the same tokens) is reported; this is load-bearing because context-sensitive changes would undermine the 'consistent sign pattern' definition of a feature.
Authors: We agree that a direct stability metric is important for rigorously supporting the definition of features as consistent sign patterns. The single-token cache design was chosen to isolate intrinsic per-dimension encodings without contextual modulation, and the high AUCs and predictive power observed even in this minimal setting provide supporting evidence. However, we acknowledge that the manuscript does not report a quantitative comparison of sign agreement between no-context and full-sequence activations for identical tokens. In the revision we will add this analysis, computing the per-dimension and per-feature sign-matching fractions across contexts for representative tokens and categories, along with any observed variance. revision: yes
-
Referee: [Causal intervention results] The causal claim that flipping a feature's signs 'suppresses its concept across four language models, magnitude-matched and concept-specific' requires a precise intervention protocol. The manuscript does not specify how dimensions belonging to a feature are selected for flipping, nor how effects from correlated dimensions or downstream nonlinearities are isolated; without this, the specificity of the interventions cannot be verified.
Authors: We appreciate the request for a more explicit protocol. Feature dimensions are identified by selecting those with high sign-agreement scores (thresholded at the top quantile of agreement across a held-out set of concept examples); only these dimensions receive the sign flip during the live forward pass. Specificity is supported by (i) magnitude-matched random-flip controls that produce no comparable suppression and (ii) the fact that the same intervention leaves unrelated concepts unaffected. We will expand the Methods and supplementary sections with a precise, reproducible description of the selection criterion, the exact set of dimensions flipped per feature, and the control procedures, including pseudocode. revision: yes
Circularity Check
No circularity; claims rest on direct empirical sign-agreement counts and interventions.
full rationale
The paper defines features via consistent sign patterns across dimensions and validates them through direct measurements (sign-agreement AUC, next-token accuracy preservation with unit-magnitude signs, live sign-flip interventions, and mutual information) without any fitted parameters, self-referential predictions, or load-bearing self-citations. The central method (counting sign agreements from single-token caches) is applied to raw activations and compared against a trained probe baseline, but the primary results do not reduce to the inputs by construction. No uniqueness theorems, ansatzes via citation, or renamings of known results are invoked in a circular manner.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Pairwise mutual information between dimensions remains below 0.006 bits, allowing sign patterns to be treated as independent registers
- domain assumption Sign patterns for a given semantic feature remain consistent across different tokens and contexts
Reference graph
Works this paper leans on
-
[1]
Transactions on Machine Learning Research , year=
Oquab, Maxime and Darcet, Timoth. Transactions on Machine Learning Research , year=
-
[2]
Understanding intermediate layers using linear classifier probes
Understanding intermediate layers using linear classifier probes , author=. arXiv preprint arXiv:1610.01644 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Network dissection: Quantifying interpretability of deep visual representations , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[4]
Computational Linguistics , volume=
Probing classifiers: Promises, shortcomings, and advances , author=. Computational Linguistics , volume=
-
[5]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Eliciting latent predictions from transformers with the tuned lens , author=. arXiv preprint arXiv:2303.08112 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Transformer Circuits Thread, Anthropic , year=
Towards monosemanticity: Decomposing language models with dictionary learning , author=. Transformer Circuits Thread, Anthropic , year=
-
[7]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Sparse autoencoders find highly interpretable features in language models , author=. arXiv preprint arXiv:2309.08600 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Transformer Circuits Thread, Anthropic , year=
Toy models of superposition , author=. Transformer Circuits Thread, Anthropic , year=
-
[9]
arXiv preprint arXiv:2501.17727 , year=
Sparse autoencoders can interpret randomly initialized transformers , author=. arXiv preprint arXiv:2501.17727 , year=
-
[10]
Interpreting
nostalgebraist , year=. Interpreting
-
[11]
Scaling monosemanticity: Extracting interpretable features from
Templeton, Adly and Conerly, Tom and Marcus, Jonathan and Lindsey, Jack and Bricken, Trenton and Chen, Brian and Pearce, Adam and Citro, Craig and Ameisen, Emmanuel and Jones, Andy and Cunningham, Hoagy and Turner, Nicholas L and McDougall, Callum and MacDiarmid, Monte and Freeman, C Daniel and Sumers, Theodore R and Rees, Edward and Batson, Joshua and Je...
-
[12]
Representation engineering: A top-down approach to
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and Pan, Alexander and Yin, Xuwang and Mazeika, Mantas and Dombrowski, Ann-Kathrin and Goel, Shashwat and Li, Nathaniel and Byun, Michael J and Wang, Zifan and Mallen, Alex and Basart, Steven and Koyber, Sanmi and Song, Dawn and Fredrikson, Matt and Kolter, J Zi...
-
[13]
International Conference on Learning Representations (ICLR) , year=
An image is worth 16x16 words: Transformers for image recognition at scale , author=. International Conference on Learning Representations (ICLR) , year=
-
[14]
Gong, Yuan and Chung, Yu-An and Glass, James , booktitle=
-
[15]
, booktitle=
Piczak, Karol J. , booktitle=
-
[16]
Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (
Kim, Been and Wattenberg, Martin and Gilmer, Justin and Cai, Carrie and Wexler, James and Vi. Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (. International Conference on Machine Learning (ICML) , year=
-
[17]
Fong, Ruth and Vedaldi, Andrea , booktitle=
-
[18]
Feature Visualization , author=. Distill , year=. doi:10.23915/distill.00007 , note=
-
[19]
Steering
Joseph, Sonia and Suresh, Praneet and Goldfarb, Ethan and Hufe, Lorenz and Gandelsman, Yossi and Graham, Robert and Bzdok, Danilo and Samek, Wojciech and Richards, Blake Aaron , booktitle=. Steering. 2025 , note=
2025
-
[20]
NeurIPS 2025 Workshop on Mechanistic Interpretability , year=
Learning Interpretable Features in Audio Latent Spaces via Sparse Autoencoders , author=. NeurIPS 2025 Workshop on Mechanistic Interpretability , year=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.