Bringing Agentic Search to Earth Observation Data Discovery
Pith reviewed 2026-07-03 06:41 UTC · model grok-4.3
The pith
Agentic search combining neural scoring, BM25 fusion, and zero-shot LLM reranking improves Earth observation data retrieval by over 5x.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
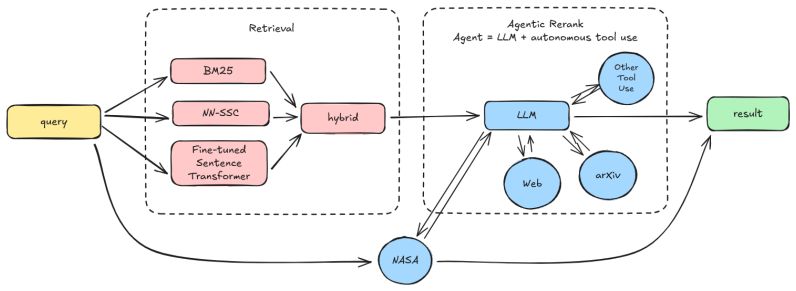
The central claim is that the latent value of knowledge graphs for geoscience data discovery can be substantially amplified through agentic search. From the NASA Earth Observation Knowledge Graph the authors derive NASA-EO-Bench, an open benchmark of 47k query-dataset pairs including 21k task-based queries. A neural scorer fine-tuned on this benchmark beats cosine and BM25 baselines; score fusion with BM25 raises R@10 and MRR by over 5x; and a zero-shot agentic reranking stage lifts MRR by 28 percent on a stratified N=200 subset.
What carries the argument
The hybrid retrieval pipeline that fuses a fine-tuned neural scorer with BM25 and then applies zero-shot LLM agentic reranking on top of the NASA Earth Observation Knowledge Graph.
If this is right
- The deployed public service can directly help domain experts locate matching datasets and tools from natural language research questions.
- Synthetic query pairs generated from the knowledge graph enable effective supervised training for retrieval in this domain.
- LLM reasoning in the reranking stage adds measurable value beyond what supervised methods alone achieve.
- The performance gains are observed on both the full benchmark and a stratified subset of task-based queries.
Where Pith is reading between the lines
- The same hybrid supervised-plus-zero-shot pattern could be tested on knowledge graphs from other scientific fields that face similar discovery problems.
- Real-world usage logs from the public service could serve as a natural next test set to check how well synthetic queries generalize.
- The observed complementarity suggests that future systems may routinely combine trained scorers with lightweight agentic stages rather than relying on either approach alone.
Load-bearing premise
The NASA EO-KG faithfully captures all relevant dataset-tool relationships and the 47k synthetic query pairs are representative of real user information needs.
What would settle it
Running the full pipeline on a collection of actual user queries collected from geoscience researchers and measuring whether the reported gains in Recall@10 and MRR still appear.
Figures
read the original abstract
NASA and its data centers hold thousands of geoscience datasets and tools like Worldview, Giovanni, the Science Discovery Engine, and Harmony. Finding the right one is hard even for domain experts. We present an agentic search system, deployed as a public service for the geoscience community, that takes a natural-language research query and returns the matching datasets and tools. We demonstrate that, in the era of large language models, the latent value of knowledge graphs (KGs) can be substantially amplified through agentic search. From the NASA Earth Observation Knowledge Graph (NASA EO-KG) we derive NASA-EO-Bench, an open benchmark of 47k query-dataset pairs (21k task-based queries). A neural scorer fine-tuned on NASA-EO-Bench beats cosine and BM25 baselines. Further combining it with BM25 via score fusion raises both Recall@10 (R@10) and MRR by over 5x. On top of this supervised pipeline, we add a zero-shot agentic reranking stage that, without any additional training, lifts MRR by 28% on a stratified N=200 subset, showing that LLM reasoning is complementary to supervised retrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an agentic search system for NASA Earth Observation datasets and tools. From the NASA EO-KG it derives the open NASA-EO-Bench benchmark of 47k synthetic query-dataset pairs (including 21k task-based queries). A neural scorer fine-tuned on the benchmark, when combined with BM25 via score fusion, raises R@10 and MRR by over 5x relative to cosine and BM25 baselines. A zero-shot agentic reranking stage then lifts MRR by an additional 28% on a stratified N=200 subset, with the overall system deployed as a public service.
Significance. If the reported gains prove robust, the work illustrates how KGs can be leveraged at scale through LLM-based agentic reranking for a deployed retrieval service in geoscience. The release of NASA-EO-Bench as an open benchmark is a concrete positive contribution that could support further research on EO data discovery.
major comments (2)
- [Abstract] Abstract: All quantitative claims (5x lift from neural+BM25 fusion; 28% MRR gain from zero-shot agentic reranking) are measured exclusively on NASA-EO-Bench, which is generated from the same NASA EO-KG that supplies the retrieval index and relationships. No external validation set, human-authored query collection, or out-of-distribution test is referenced, so it is unclear whether the measured improvements transfer to real user queries whose ambiguity, multi-hop structure, or tool/dataset relationships may differ from the KG-derived distribution.
- [Abstract] Abstract: The reported results supply no error bars, confidence intervals, statistical significance tests, or full experimental protocol (train/test split details, baseline re-implementations, hyper-parameter search, or verification that the N=200 subset is representative). This absence makes it impossible to assess the reliability or reproducibility of the 5x and 28% figures.
minor comments (1)
- [Abstract] Abstract: The distinction between the full 47k pairs and the 21k task-based queries is stated but not used to qualify any of the reported metrics; clarifying which subset drives the fusion and reranking results would improve interpretability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment point by point below, with plans for revision where the concerns are valid.
read point-by-point responses
-
Referee: [Abstract] Abstract: All quantitative claims (5x lift from neural+BM25 fusion; 28% MRR gain from zero-shot agentic reranking) are measured exclusively on NASA-EO-Bench, which is generated from the same NASA EO-KG that supplies the retrieval index and relationships. No external validation set, human-authored query collection, or out-of-distribution test is referenced, so it is unclear whether the measured improvements transfer to real user queries whose ambiguity, multi-hop structure, or tool/dataset relationships may differ from the KG-derived distribution.
Authors: We acknowledge that NASA-EO-Bench is derived from the NASA EO-KG, which encodes the authoritative dataset-tool relationships. This design enables scalable generation of 47k pairs with verifiable ground truth that would otherwise require extensive human annotation. The KG reflects real NASA-curated relationships, allowing the benchmark to test recovery of those relationships from natural-language queries. However, we agree that the absence of an external or human-authored validation set is a limitation for assessing generalization to real user queries with potentially different ambiguity or multi-hop structures. In the revision we will expand the discussion and limitations sections to explicitly address this, including potential distribution shifts, and we will outline plans for future collection of a small human-authored test set. We will also update the abstract to note that all reported results are on the KG-derived benchmark. revision: partial
-
Referee: [Abstract] Abstract: The reported results supply no error bars, confidence intervals, statistical significance tests, or full experimental protocol (train/test split details, baseline re-implementations, hyper-parameter search, or verification that the N=200 subset is representative). This absence makes it impossible to assess the reliability or reproducibility of the 5x and 28% figures.
Authors: We agree that the abstract and results presentation would be strengthened by including these details. In the revised manuscript we will add error bars (via bootstrapping or multiple runs where available), confidence intervals, and statistical significance tests for the key metrics. We will also expand the experimental section with the full protocol: train/test split details, baseline re-implementation notes, hyper-parameter search procedure, and a description of how the stratified N=200 subset was constructed along with evidence of its representativeness relative to the full benchmark. revision: yes
Circularity Check
No circularity; empirical claims on newly constructed benchmark with no derivations or self-referential reductions.
full rationale
The paper contains no equations, derivations, or mathematical claims. All performance numbers (5x gains from fusion, 28% MRR lift from agentic reranking) are direct empirical measurements on NASA-EO-Bench, a benchmark explicitly derived from the NASA EO-KG. This is standard construction of a synthetic evaluation set followed by train/test reporting; it does not match any enumerated circularity pattern such as self-definitional relations, fitted inputs renamed as predictions, or load-bearing self-citations. The benchmark and system share a common data source, but that is a generalization concern, not a reduction of the reported results to their own inputs by construction. No steps qualify for flagging.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S. Bruch, S. Gai, and A. Ingber. An analysis of fusion functions for hybrid retrieval. ACM Transactions on Information Systems, 42 0 (1): 0 20:1--20:35, 2024. doi:10.1145/3596512
- [2]
-
[3]
T. Cohen, K. Roberts, A. E. Gururaj, X. Chen, S. Pournejati, G. Alter, W. R. Hersh, D. Demner-Fushman, L. Ohno-Machado, and H. Xu. A publicly available benchmark for biomedical dataset retrieval: the reference standard for the 2016 biocaddie dataset retrieval challenge. Database, 2017, Jan. 2017. ISSN 1758-0463. doi:10.1093/database/bax061. URL http://dx....
- [4]
- [5]
-
[6]
A. Jaber, W. Zhu, A. Roy, K. Jayavelu, J. Downes, S. Mohamed, C. Agonafir, L. Hawkins, and T. Zheng. Autoclimds: Climate data science agentic ai -- a knowledge graph is all you need, 2025. URL https://arxiv.org/abs/2509.21553
-
[7]
M. P. Kato, H. Ohshima, Y. Liu, and H. Chen. Overview of the NTCIR-15 data search task. In C. L. A. Clarke and N. Kando, editors, Proceedings of the 15th NTCIR Conference on Evaluation of Information Access Technologies, NTCIR 2020, Tokyo, Japan, December 8-11, 2020 . National Institute of Informatics (NII) , 2020. URL https://research.nii.ac.jp/ntcir/wor...
2020
-
[8]
N. Kolyada, M. Potthast, and B. Stein. A Test Collection for Dataset Retrieval, pages 372--380. Springer Nature Switzerland, 2025. ISBN 9783031887147. doi:10.1007/978-3-031-88714-7_36. URL http://dx.doi.org/10.1007/978-3-031-88714-7_36
-
[9]
Lewis, E
P. Lewis, E. Perez, A. Piktus, et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems, volume 33, pages 9459--9474, 2020
2020
-
[10]
Z. Li, S. Yan, J. Cao, M. Zhang, A. Wei, J. Yoo, and Y. Hong. HydroAgent : Closing the gap between frontier LLMs and human experts in hydrologic model calibration via simulator-grounded RL , 2026. URL https://arxiv.org/abs/2605.17792
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
T. Lin, Q. Chen, G. Cheng, A. Soylu, B. Ell, R. Zhao, Q. Shi, X. Wang, Y. Gu, and E. Kharlamov. Acordar: A test collection for ad hoc content-based (rdf) dataset retrieval. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR '22, pages 2981--2991. ACM, July 2022. doi:10.1145/3477495.353...
-
[12]
N. F. Liu, K. Lin, J. K. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang. Lost in the middle: How language models use long contexts, 2023. URL https://arxiv.org/abs/2307.03172
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [13]
-
[14]
Z. Liu and Y. Wen. Accelerating earth science to action. Bulletin of the American Meteorological Society, 106 0 (10), 2025. doi:10.1175/BAMS-D-24-0226.1
- [15]
-
[16]
nasa-impact/nasa-smd-ibm-st-v2 : Domain-adapted sentence transformer for nasa scientific text
nasa-smd-ibm-st-v2. nasa-impact/nasa-smd-ibm-st-v2 : Domain-adapted sentence transformer for nasa scientific text. https://huggingface.co/nasa-impact/nasa-smd-ibm-st-v2, 2024. Accessed: 2026
2024
-
[17]
D. Pantiukhin, B. Shapkin, I. Kuznetsov, A. A. Jost, and N. Koldunov. Accelerating earth science discovery via multi-agent llm systems, 2025. URL https://arxiv.org/abs/2503.05854
-
[18]
D. Pantiukhin, I. Kuznetsov, B. Shapkin, A. Jost, T. Jung, and N. Koldunov. A hierarchical multi-agent system for autonomous discovery in geoscientific data archives, 2026. URL https://arxiv.org/abs/2602.21351
-
[19]
RankZephyr: Effective and Robust Zero-Shot Listwise Reranking is a Breeze!
R. Pradeep, S. Sharifymoghaddam, and J. Lin. Rankzephyr: Effective and robust zero-shot listwise reranking is a breeze!, 2023. URL https://arxiv.org/abs/2312.02724
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
X. Ren, Y. Sun, and H. Liang. Correcting mean bias in text embeddings: A refined renormalization with training-free improvements on MMTEB , 2025. URL https://arxiv.org/abs/2511.11041
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [21]
-
[22]
S. E. Robertson, S. Walker, S. Jones, M. M. Hancock-Beaulieu, and M. Gatford. Okapi at TREC -3. In TREC, 1995
1995
-
[23]
Toolformer: Language Models Can Teach Themselves to Use Tools
T. Schick, J. Dwivedi-Yu, R. Dessì, R. Răileanu, M. Lomelí, L. Zettlemoyer, N. Cancedda, and T. Scialom. Toolformer: Language models can teach themselves to use tools, 2023. URL https://arxiv.org/abs/2302.04761
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Schluntz and B
E. Schluntz and B. Zhang. Building effective agents. https://www.anthropic.com/engineering/building-effective-agents, 2024. Anthropic Engineering Blog, December 2024
2024
- [25]
- [26]
-
[27]
Y. Sun, X. Ren, C. Yi, J. Guo, K. Zhang, J. Du, and H. Yang. Agon: An autonomous large-scale omnidisciplinary research system built on prompt economy, 2026 a . URL https://arxiv.org/abs/2606.24177
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [28]
- [29]
-
[30]
A Reference Architecture for Agentic Hybrid Retrieval in Dataset Search
R. Terrenzi, P. M. Konrad, T. L. Adam, and S. Ayvaz. A reference architecture for agentic hybrid retrieval in dataset search, 2026. URL https://arxiv.org/abs/2604.16394
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
S. Yan, M. Chen, Z. Li, Y. Wen, et al. AI agent for hydrologic modeling: Definition, development and application, 2026. URL https://essopenarchive.org/doi/full/10.22541/essoar.176894821.13120988/v1
- [32]
-
[33]
S. Yao, J. Zhao, D. Yu, et al. ReAct : Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [34]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.