Agon: An Autonomous Large-Scale Omnidisciplinary Research System Built on Prompt Economy
Pith reviewed 2026-06-25 23:22 UTC · model grok-4.3
The pith
Agon shows prompt economy loops can scale research production across domains while a taxonomy separates machine-fixable failures from those needing human judgment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
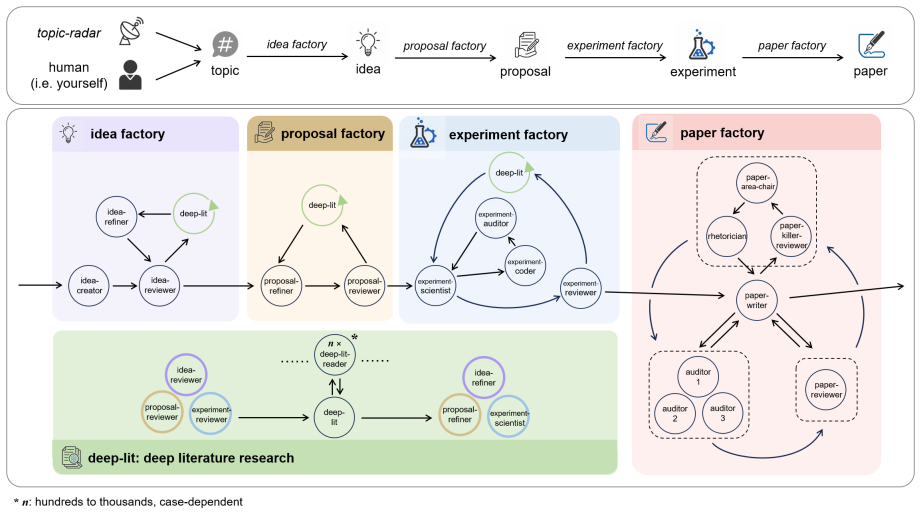
Agon is an autonomous large-scale omnidisciplinary research system built on the six principles of Prompt Economy, Future-Facing, Minimal Prompts, OmniDisciplinary, Massive Parallelism, and Zero-Code. When run for 444 iterations across domains from minimal starting topics and without any human-written experimental code, it validates what can be checked inside the workflow and exposes new classes of failure. These failures are organized into a taxonomy along severity, fixability, visibility, and capability locus that separates issues the loops can see and fix from those that require human judgment.
What carries the argument
Prompt Economy loops that autonomously generate research artifacts and validate checkable claims inside the workflow.
If this is right
- Research production can proceed at larger scales when only initial topics are supplied by humans.
- Failures in autonomous research systems can be systematically grouped to clarify the boundary between machine and human roles.
- The taxonomy provides a practical way to route tasks so that loops handle visible and fixable problems while humans address the remainder.
- Omnidisciplinary operation becomes feasible when the same loop structure applies across fields without custom code.
Where Pith is reading between the lines
- Testing the same loops on narrower domains could reveal whether the machine-human boundary shifts with field-specific checkability.
- The taxonomy might serve as a design tool for other agent systems by making explicit which capabilities must remain with humans.
- Repeated deployments could track whether the fraction of machine-fixable failures decreases as the loops accumulate experience.
Load-bearing premise
That the prompt economy loops can reliably validate checkable claims inside the workflow and that the derived failure taxonomy accurately distinguishes machine-fixable issues from those requiring human judgment, all without any human-written experimental code.
What would settle it
A run in which Agon produces a claim whose truth value is independently verifiable yet the internal loops accept an incorrect conclusion, or a failure whose classification under the taxonomy does not match independent review of its fixability.
Figures
read the original abstract
Large language models are making research production scalable, shifting the bottleneck from producing artifacts to judging claims. We present \textsc{Agon}, a research orchestrator that validates what can be checked inside the workflow and leaves the remaining judgments to human scientists. \textsc{Agon} is built on six design principles: Prompt Economy, Future-Facing, Minimal Prompts, OmniDisciplinary, Massive Parallelism, and Zero-Code. We ran \textsc{Agon} across domains for 444 iterations of Prompt Economy loops, using only small starting topics and no human-written experimental code. These deployments demonstrate scalability while exposing new classes of failure. We organize these failures into a taxonomy along severity, fixability, visibility, and capability locus. The taxonomy separates failures the loops can see and fix from those that require human judgment. Together, these results show that \textsc{Agon} is pushing research toward a new paradigm: machine scales, human steers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Agon, an autonomous research orchestrator built on six design principles (Prompt Economy, Future-Facing, Minimal Prompts, OmniDisciplinary, Massive Parallelism, Zero-Code). It reports running the system for 444 iterations across domains from small starting topics with no human-written experimental code, claims these runs demonstrate scalability while exposing failures, and organizes the failures into a taxonomy along severity, fixability, visibility, and capability locus that separates machine-fixable issues from those requiring human judgment, advancing a paradigm of machine scaling with human steering.
Significance. If the empirical claims and taxonomy validation hold with supporting data, the work could represent a notable contribution to automated research systems by showing how LLM-based loops can handle internal validation at scale while deferring only select judgments. The zero-code and omnidisciplinary framing would be strengths if demonstrated with concrete outputs and reproducible traces.
major comments (3)
- [Abstract] Abstract: The central claim that 444 iterations demonstrate scalability and yield a taxonomy separating machine-fixable from human-required failures lacks any reported metrics, success rates, concrete research outputs, examples of autonomously validated claims, or traces of how failures were observed and classified.
- [Abstract] Abstract/Results: The taxonomy is asserted to distinguish failures the loops can see and fix from those requiring human judgment, but no evidence, examples, or classification procedure is supplied, rendering the distinction unevaluable and the paradigm-shift assertion unsupported.
- [Methods] Methods/Implementation: No details are provided on how Prompt Economy loops validate checkable claims inside the workflow, what the small starting topics were, or how the zero-code constraint was maintained across iterations, all of which are load-bearing for the autonomy and validation claims.
minor comments (1)
- [Abstract] The term 'Prompt Economy' is used as a foundational concept without an explicit definition or grounding in the provided text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will make targeted revisions to improve clarity, evidence, and reproducibility.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 444 iterations demonstrate scalability and yield a taxonomy separating machine-fixable from human-required failures lacks any reported metrics, success rates, concrete research outputs, examples of autonomously validated claims, or traces of how failures were observed and classified.
Authors: We agree the abstract would be strengthened by including quantitative indicators. In revision we will add summary statistics (e.g., overall iteration throughput, fraction of claims autonomously validated, and counts of each failure category) drawn from the results section, plus one or two concrete examples of validated outputs and failure traces. The main text already reports the 444 iterations and taxonomy, but these numbers and examples will be elevated to the abstract for immediate visibility. revision: yes
-
Referee: [Abstract] Abstract/Results: The taxonomy is asserted to distinguish failures the loops can see and fix from those requiring human judgment, but no evidence, examples, or classification procedure is supplied, rendering the distinction unevaluable and the paradigm-shift assertion unsupported.
Authors: The results section presents the taxonomy along the four axes (severity, fixability, visibility, capability locus) with illustrative cases. To make the machine-vs-human distinction directly evaluable we will add (1) an explicit classification procedure subsection describing how visibility and fixability were assessed in each iteration and (2) a table or set of annotated examples showing which failures were resolved inside the loop versus those escalated. This will also reinforce the paradigm claim with traceable evidence. revision: yes
-
Referee: [Methods] Methods/Implementation: No details are provided on how Prompt Economy loops validate checkable claims inside the workflow, what the small starting topics were, or how the zero-code constraint was maintained across iterations, all of which are load-bearing for the autonomy and validation claims.
Authors: We will expand the Methods section with three new subsections: (a) the internal validation protocol used by the Prompt Economy loops (including prompt templates for self-checking and cross-verification), (b) the exact list of small starting topics and domains, and (c) the engineering steps that enforce the zero-code rule (e.g., all code generation and execution handled exclusively by the LLM agents). These additions will directly support the autonomy and validation claims. revision: yes
Circularity Check
No circularity: empirical description of system runs and taxonomy
full rationale
The paper presents Agon as a system built on explicitly listed design principles including Prompt Economy, then reports running it for 444 iterations across domains with no human-written experimental code, observing failures, and organizing those failures into a taxonomy along four axes. No equations, fitted parameters, self-citations, or uniqueness theorems appear in the text. The taxonomy is described as derived directly from the observed failures in the deployments rather than presupposed or fitted to match a prior result. The central claim that the taxonomy separates machine-fixable from human-required failures follows from the reported runs without any reduction to inputs by construction. This is a standard empirical systems paper with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Prompt Economy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Mlr-bench: Evaluating ai agents on open-ended machine learning research
Hui Chen, Miao Xiong, Yujie Lu, Wei Han, Ailin Deng, Yufei He, Jiaying Wu, Yibo Li, Yue Liu, and Bryan Hooi. Mlr-bench: Evaluating ai agents on open-ended machine learning research. In Proceedings of the Thirty-Ninth Conference on Neural Information Processing Systems (NeurIPS 2025), Datasets and Benchmarks Track ,
2025
-
[2]
URL https://arxiv.org/abs/2505.19955. Ruiying Chen. Evidence-bound autonomous research (evibound): A governance framework for eliminating false claims,
-
[3]
Sy-Tuyen Ho, Minghui Liu, Huy Nghiem, and Furong Huang
URL https://arxiv.org/abs/2511.05524. Sy-Tuyen Ho, Minghui Liu, Huy Nghiem, and Furong Huang. Soundnessbench: Can your ai scientist really tell good research ideas from bad ones?,
-
[4]
Xu Huang, Junwu Chen, Yuxing Fei, Zhuohan Li, Philippe Schwaller, and Gerbrand Ceder
URL https://arxiv.org/abs/2605.30329. Xu Huang, Junwu Chen, Yuxing Fei, Zhuohan Li, Philippe Schwaller, and Gerbrand Ceder. Cas- cade: Cumulative agentic skill creation through autonomous development and evolution,
-
[5]
Fengqing Jiang, Yichen Feng, Yuetai Li, Luyao Niu, Basel Alomair, and Radha Poovendran
URL https://arxiv.org/abs/2512.23880. Fengqing Jiang, Yichen Feng, Yuetai Li, Luyao Niu, Basel Alomair, and Radha Poovendran. Bad- scientist: Can a research agent write convincing but unsound papers that fool llm reviewers? In Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL 2026),
arXiv 2026
-
[6]
Priyanka Kargupta, Ishika Agarwal, Tal August, and Jiawei Han
URL https://arxiv.org/abs/2510.18003. Priyanka Kargupta, Ishika Agarwal, Tal August, and Jiawei Han. Tree-of-debate: Multi-persona debate trees elicit critical thinking for scientific comparative analysis. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL
-
[7]
URL https://arxiv.org/abs/2502.14767. Jiaqi Liu, Shi Qiu, Mairui Li, Bingzhou Li, Haonian Ji, Siwei Han, Xinyu Ye, Peng Xia, Zihan Dong, Meng Chen, Congyu Zhang, Letian Zhang, Guiming Chen, Haoqin Tu, Xinyu Yang, Lu Feng, Xujiang Zhao, Haifeng Chen, Jiawei Zhou, Xiao Wang, Weitong Zhang, Hongtu Zhu, Yun Li, Jieru Mei, Hongliang Fei, Jiaheng Zhang, Linjie ...
-
[8]
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha
URL https://arxiv.org/abs/2605.20025. Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist: Towards fully automated open-ended scientific discovery,
-
[9]
URL https://arxiv. org/abs/2408.06292. Rui Meng, Bhavana Dalvi Mishra, Jiefeng Chen, Chun-Liang Li, Palash Goyal, Mihir Parmar, Yiwen Song, Yale Song, Rajarishi Sinha, Parthasarathy Ranganathan, Burak Gokturk, Jinsung Yoon, and Tomas Pfister. Scientistone: Towards human-level autonomous research via chain-of- evidence,
-
[10]
URL https://arxiv.org/abs/2605.26340. Alexander Novikov, Ngân Vũ, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. Alphaevolve: A ...
-
[11]
39 Razeen A Rasheed, Somnath Banerjee, Animesh Mukherjee, and Rima Hazra
URL https://arxiv.org/abs/2506.13131. 39 Razeen A Rasheed, Somnath Banerjee, Animesh Mukherjee, and Rima Hazra. From fluent to verifiable: Claim-level auditability for deep research agents,
-
[12]
Xingyu Ren, Youran Sun, Chugang Yi, Kejia Zhang, Jiaxuan Guo, Jianda Du, and Haizhao Yang
URL https://arxiv.org/ abs/2602.13855. Xingyu Ren, Youran Sun, Chugang Yi, Kejia Zhang, Jiaxuan Guo, Jianda Du, and Haizhao Yang. What’s missing in autonomous research? a systematization of systems, benchmarks, and verifica- tion,
-
[13]
Preprint available on ResearchGate
URL https://www.researchgate.net/publication/406952713. Preprint available on ResearchGate. Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Michael Moor, Zicheng Liu, and Emad Barsoum. Agent laboratory: Using llm agents as research assistants,
-
[14]
URL https://arxiv.org/abs/2501.04227. Guijin Son, Jiwoo Hong, Honglu Fan, Heejeong Nam, Hyunwoo Ko, Seungwon Lim, Jinyeop Song, Jinha Choi, Gonçalo Paulo, Youngjae Yu, and Stella Biderman. When ai co-scientists fail: Spot- a benchmark for automated verification of scientific research,
-
[15]
URL https://arxiv.org/ abs/2505.11855. Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, Johannes Heidecke, Amelia Glaese, and Tejal Patwardhan. Paperbench: Evaluating ai’s ability to replicate ai research,
-
[16]
Youran Sun, Xingyu Ren, Kejia Zhang, Xinpeng Liu, and Jiaxuan Guo
URL https://arxiv.org/abs/2504.01848. Youran Sun, Xingyu Ren, Kejia Zhang, Xinpeng Liu, and Jiaxuan Guo. Perspectivegap: A benchmark for multi-agent orchestration prompting,
-
[17]
URL https://arxiv.org/abs/2505.18705. Nitya Thakkar, Mert Yuksekgonul, Jake Silberg, Animesh Garg, Nanyun Peng, Fei Sha, Rose Yu, Carl Vondrick, and James Zou. Can llm feedback enhance review quality? a randomized study of 20k reviews at iclr 2025,
arXiv 2025
-
[18]
Chengcheng Wang, Qinhua Xie, Wei He, Jianyuan Guo, Shiqi Wang, and Chang Xu
URL https://arxiv.org/abs/2504.09737. Chengcheng Wang, Qinhua Xie, Wei He, Jianyuan Guo, Shiqi Wang, and Chang Xu. Sibyl- autoresearch: Autonomous research needs self-evolving trial-and-error harnesses, not paper gen- erators, 2026a. URL https://arxiv.org/abs/2605.22343. Yuanli Wang, Yaoyao Qian, Yue Zhang, Hanhan Zhou, Jindan Huang, Tianfu Fu, Qiuyang Ma...
-
[19]
URL https://arxiv.org/abs/2411.00816. Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search,
-
[20]
Ruofeng Yang, Yongcan Li, and Shuai Li
URL https://arxiv.org/abs/2504.08066. Ruofeng Yang, Yongcan Li, and Shuai Li. Aris: Autonomous research via adversarial multi-agent collaboration,
-
[21]
URL https://arxiv.org/abs/2605.03042. 40 Jiakang Yuan, Xiangchao Yan, Shiyang Feng, Bo Zhang, Tao Chen, Botian Shi, Wanli Ouyang, Yu Qiao, Lei Bai, and Bowen Zhou. Dolphin: Moving towards closed-loop auto-research through thinking, practice, and feedback,
-
[22]
URL https://arxiv.org/abs/2501.03916. Bo Zhang, Shiyang Feng, Xiangchao Yan, Jiakang Yuan, Runmin Ma, Yusong Hu, Zhiyin Yu, Xiaohan He, Songtao Huang, Shaowei Hou, Zheng Nie, Zhilong Wang, Jinyao Liu, Tianshuo Peng, Peng Ye, Dongzhan Zhou, Shufei Zhang, Xiaosong Wang, Yilan Zhang, Meng Li, Zhongying Tu, Xiangyu Yue, Wangli Ouyang, Bowen Zhou, and Lei Bai....
-
[23]
URL https: //arxiv.org/abs/2505.16938. Jiazheng Zhang, Ziche Fu, Zhiheng Xi, Wenqing Jing, Mingxu Chai, Wei He, Guoqiang Zhang, Chenghao Fan, Chenxin An, Wenxiang Chen, Zhicheng Liu, Haojie Pan, Dingwei Zhu, Tao Gui, Qi Zhang, and Xuanjing Huang. Agentv-rl: Scaling reward modeling with agentic verifier. In Proceedings of the 64th Annual Meeting of the Ass...
arXiv 2026
-
[24]
Bing Zhou, Xiao Huang, Huan Ning, Qiusheng Wu, Diya Li, and Ziyi Zhang
URL https://arxiv.org/abs/2604.16004. Bing Zhou, Xiao Huang, Huan Ning, Qiusheng Wu, Diya Li, and Ziyi Zhang. Nora: A harness- engineered autonomous research agent for end-to-end spatial data science,
-
[25]
URL https: //arxiv.org/abs/2605.02092. Xinyu Zhu, Yuzhu Cai, Zexi Liu, Bingyang Zheng, Cheng Wang, Rui Ye, Yuzhi Zhang, Linfeng Zhang, Weinan E, Siheng Chen, and Yanfeng Wang. Toward ultra-long-horizon agentic science: Cognitive accumulation for machine learning engineering,
-
[26]
URL https://arxiv.org/abs/ 2601.10402. 41
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.