MMClima: A Framework for Multimodal Climate Science Data and Evaluation
Pith reviewed 2026-06-27 17:14 UTC · model grok-4.3
The pith
MMClima supplies over 104,000 expert-validated multimodal question-answer pairs spanning climate science articles, videos, and figures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
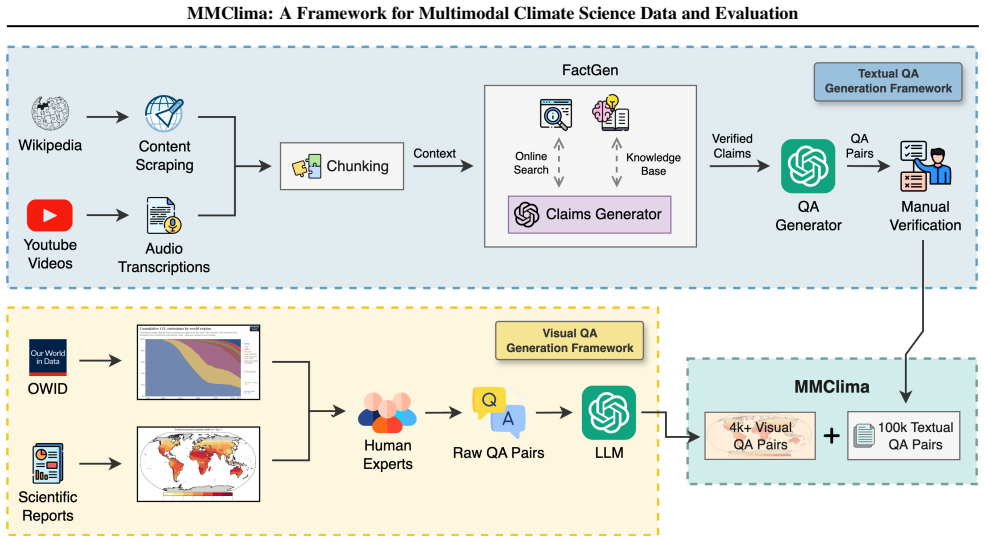
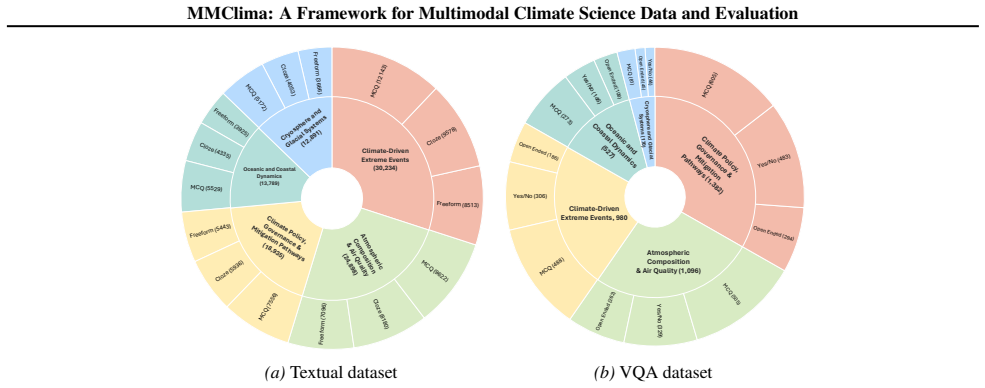
MMClima is a large-scale multimodal climate question answering framework with 104k+ expert-validated question-answer pairs spanning articles, video transcriptions, and figures across five core climate science domains, constructed via automated claim extraction and QA synthesis with human-in-the-loop validation.
What carries the argument
The MMClima dataset and its automated claim extraction plus human-in-the-loop validation pipeline that generates the multimodal QA pairs.
If this is right
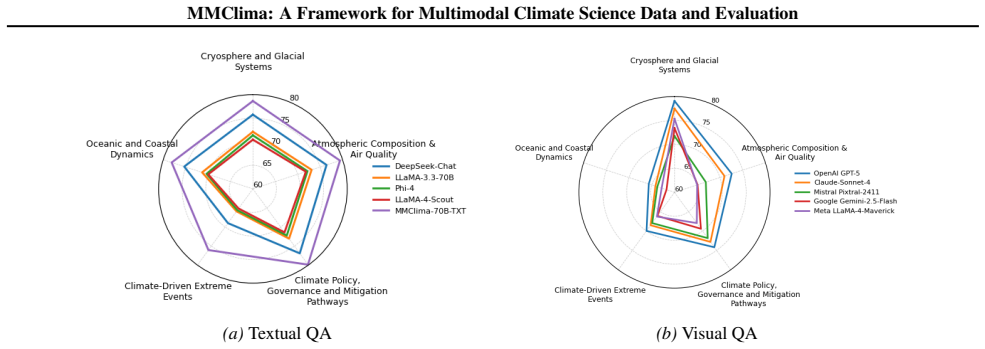
- State-of-the-art multimodal models can now be evaluated on climate tasks that require factual recall, visual interpretation, and cross-modal synthesis.
- Fine-tuning on the textual split produces mmclima-70b-txt, which outperforms strong open- and closed-source models on textual climate QA.
- Release of the dataset, evaluation pipeline, model weights, and data creation framework enables standardized multimodal evaluation for climate science.
- The construction method supports creation of large, validated QA resources that combine multiple data modalities.
Where Pith is reading between the lines
- The same extraction-plus-validation approach could be reused to generate benchmarks in other scientific domains that produce text, video, and figure data.
- Models that perform well on MMClima may improve downstream applications such as summarizing climate reports or answering public queries about climate data.
- Testing whether performance gains on this benchmark transfer to real policy or research workflows would clarify its practical value.
Load-bearing premise
The automated claim extraction and human-in-the-loop validation process produces QA pairs that are both factually accurate and representative of genuine climate science reasoning demands.
What would settle it
Independent domain experts reviewing a random sample of the QA pairs and identifying a substantial fraction that contain factual errors or fail to test multimodal reasoning would falsify the claim that the dataset is reliable and representative.
Figures

read the original abstract
Climate change research increasingly requires AI systems that reason across text, dynamic visual content, and scientific figures, yet existing climate QA benchmarks are small, mostly textual, and cover a narrow range of models. We introduce MMClima, a large-scale multimodal climate question answering framework with 104k+ expert-validated question-answer pairs spanning articles, video transcriptions, and figures across five core climate science domains. MMClima is constructed via automated claim extraction and QA synthesis with human-in-the-loop validation to ensure both scale and reliability. Using MMClima, we benchmark state-of-the-art multimodal language models on tasks requiring factual recall, visual interpretation, and cross-modal synthesis. We additionally fine-tune on the textual split to produce mmclima-70b-txt, a domain-adapted baseline that outperforms strong open- and closed-source models on textual QA. We release the dataset, evaluation pipeline, fine-tuned model weights, and data creation framework to support standardized multimodal evaluation for climate science.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MMClima, a large-scale multimodal climate QA framework with 104k+ expert-validated question-answer pairs spanning articles, video transcriptions, and figures across five climate science domains. The dataset is constructed via automated claim extraction and human-in-the-loop validation. The authors benchmark state-of-the-art multimodal models on factual recall, visual interpretation, and cross-modal synthesis, fine-tune a textual model (mmclima-70b-txt) claimed to outperform baselines, and release the dataset, evaluation pipeline, model weights, and data creation framework.
Significance. If the validation process is shown to produce accurate and representative pairs, MMClima would address a clear gap by supplying the first large-scale multimodal benchmark for climate science AI, where prior resources were small and text-only. The explicit release of the full dataset, pipeline, and fine-tuned weights is a concrete strength that directly supports reproducibility and standardized evaluation in the field.
major comments (2)
- [Abstract] Abstract: the claim that mmclima-70b-txt 'outperforms strong open- and closed-source models on textual QA' is presented without any quantitative results, tables, or error analysis, so the performance assertion cannot be evaluated from the given text.
- [Abstract] Abstract: the description of the 'human-in-the-loop validation' process provides no statistics on inter-annotator agreement, error rates, or sampling methodology, which is load-bearing for the central claim that the 104k+ pairs are both factually accurate and representative of genuine climate science reasoning.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We have revised the abstract to incorporate quantitative performance results and validation statistics, ensuring the central claims are supported and evaluable directly from the abstract while retaining full details in the main text.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that mmclima-70b-txt 'outperforms strong open- and closed-source models on textual QA' is presented without any quantitative results, tables, or error analysis, so the performance assertion cannot be evaluated from the given text.
Authors: We agree that the abstract should include quantitative results to allow direct evaluation of the performance claim. The main manuscript already contains the full results, tables, and error analysis in Section 5 and associated tables. We have revised the abstract to add a concise summary of the key metrics demonstrating the outperformance. revision: yes
-
Referee: [Abstract] Abstract: the description of the 'human-in-the-loop validation' process provides no statistics on inter-annotator agreement, error rates, or sampling methodology, which is load-bearing for the central claim that the 104k+ pairs are both factually accurate and representative of genuine climate science reasoning.
Authors: We agree that the abstract should include these validation statistics to substantiate the dataset quality claim. The main manuscript provides the complete description and statistics in Section 3.2. We have revised the abstract to briefly report the inter-annotator agreement, error rates, and sampling methodology. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents a data-construction and benchmarking effort: it describes automated claim extraction plus human-in-the-loop validation to build a multimodal QA dataset, followed by model evaluation and fine-tuning. No equations, fitted parameters, derivations, or load-bearing self-citations appear in the abstract or stated methodology. The central claim (release of 104k+ validated pairs) rests on the success of the described process rather than reducing to any input by construction. This is a standard non-derivational dataset paper; the derivation chain is empty.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
arXiv:2005.11401. Li, X., Ding, J., and Elhoseiny, M. Vrsbench: A versatile vision–language benchmark dataset for remote sensing image understanding. InAdvances in Neural Informa- tion Processing Systems, volume 37, 2024. Datasets and Benchmarks Track. arXiv:2406.12384. Liang, P., Bommasani, R., et al. Holistic evaluation of language models.Transactions o...
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[2]
10 MMClima: A Framework for Multimodal Climate Science Data and Evaluation Masry, A., Long, D
ICLR 2025 Poster. 10 MMClima: A Framework for Multimodal Climate Science Data and Evaluation Masry, A., Long, D. X., Tan, J. Q., Joty, S., and Hoque, E. ChartQA: A benchmark for question answering about charts with visual and logical reasoning. InFindings of the Association for Computational Linguistics: ACL 2022, pp. 2263–2279, Dublin, Ireland, 2022. Ass...
2025
-
[3]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
arXiv:2201.11903. Wikipedia contributors. Wikipedia, the free encyclopedia,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Zhang, T., Kishore, V ., Wu, F., Weinberger, K
Accessed 2026-01-29. Zhang, T., Kishore, V ., Wu, F., Weinberger, K. Q., and Artzi, Y . BERTScore: Evaluating text generation with BERT. In International Conference on Learning Representations,
2026
-
[5]
BERTScore: Evaluating Text Generation with BERT
arXiv:1904.09675. Zhao, Y ., Luo, X., Luo, J., Zhang, W., Xiao, Z., Ju, W., Yu, P. S., and Zhang, M. Multifaceted evaluation of audio- visual capability for MLLMs: Effectiveness, efficiency, generalizability and robustness. InFindings of the As- sociation for Computational Linguistics: EMNLP 2025, pp. 1026–1041, Suzhou, China, 2025. Association for Comput...
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[6]
arXiv:2306.05685. Zhu, H. and Tiwari, P. Climate change from large language models, 2023. arXiv:2312.11985. 11 MMClima: A Framework for Multimodal Climate Science Data and Evaluation A. Appendix A.1. Chunk Distribution Across Themes This section shows the number of chunks obtained from both sources, Wikipedia and YouTube transcripts. Table 5.Number of chu...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Standalone→The claim must be understandable by itself without extra context
-
[8]
Verifiable→The claim must be fact-based and checkable against reliable sources
-
[9]
Universally Accepted→The claim must be widely recognized in climate science, policy, or history
-
[10]
Atomic→Each claim must express exactly one fact
-
[11]
[Warning] Reject vague/general statements
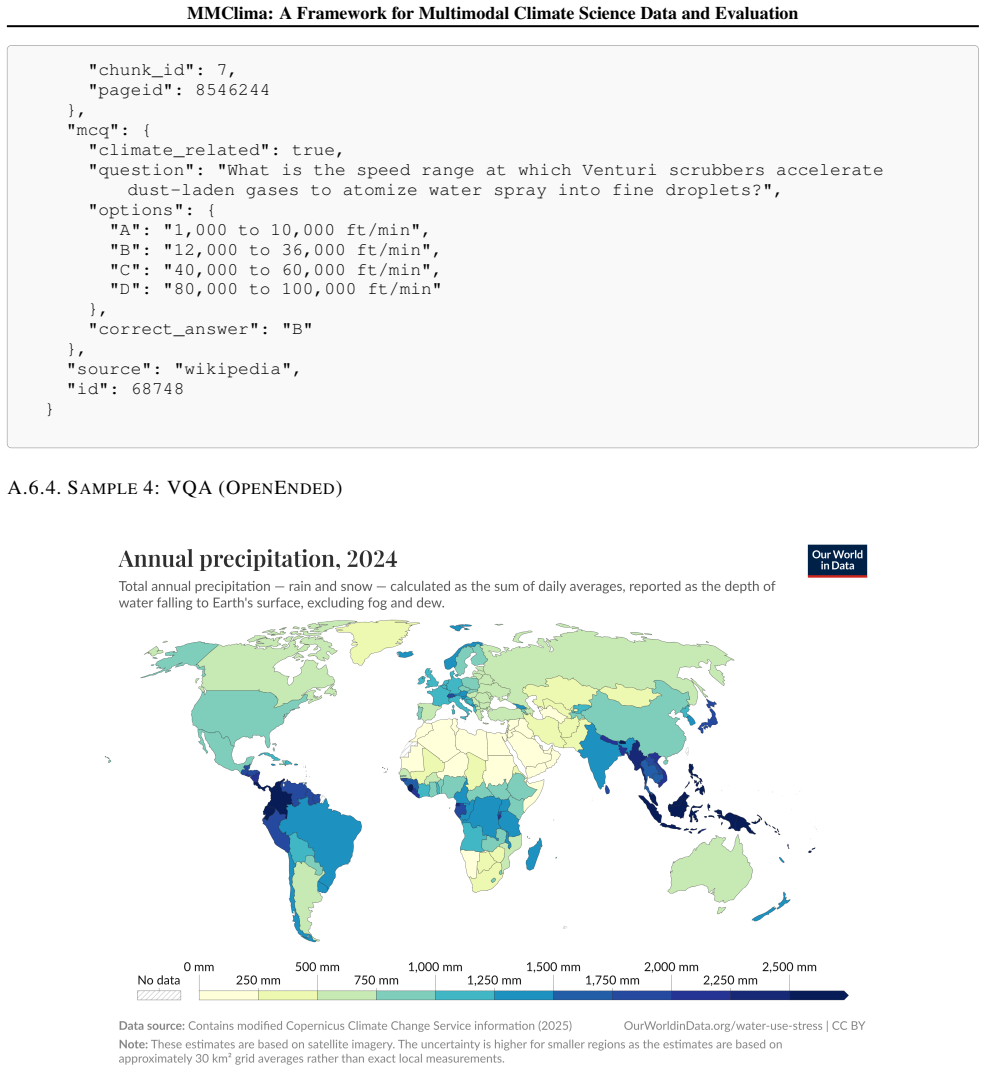
Concrete→Prefer entities, events, dates, laws, or measurements. [Warning] Reject vague/general statements. Categories: factual, conceptual, causal, policy, statistical. Output each claim as JSON with: claim, category, explanation, title, url, theme, chunk id, pageid. Extract only a few high-quality, universally accepted claims per chunk. --- Title: chunk[...
-
[13]
- The question must be complete by itself (not vague or partial)
Regardless of this flag: - Create one clear *standalone question * derived directly from the claim. - The question must be complete by itself (not vague or partial). - Provide a *short, precise answer * also derived directly from the claim. - The answer must be a short but complete sentence, factual, and to the point
-
[14]
whitelabel
Add a new field "whitelabel", which is an array of *keywords that answer the question in short way *. - Examples: ["Yes"], ["No"], ["1997"], ["CO2"], ["1 meter"], ["Paris Agreement"]. - Use the most important short tokens that answer the question. Return JSON only in this format (no commentary, no markdown fences): {{ "climate related": true/false, "quest...
1997
-
[16]
Regardless of this flag, *always create one exam-style multiple-choice question (MCQ)* based on the claim
-
[17]
- The question must test knowledge of the claim
MCQ Requirements: - Question for MCQ must be complete and unambiguous. - The question must test knowledge of the claim. - Provide exactly 4 answer options labeled A, B, C, D. - Only ONE option must be correct. - Wrong answers must be plausible but clearly incorrect. - The correct answer must be directly supported by the claim
-
[18]
climate related
Return JSON only in this exact format (no explanation, no commentary, no markdown fences): {{ "climate related": true/false, "question": "...", "options":{{ "A": "...", "B": "...", "C": "...", "D": "..." }}, "correct answer": "A/B/C/D" 15 MMClima: A Framework for Multimodal Climate Science Data and Evaluation }} Claim: "{claim text}" Context: Title = "{ti...
-
[19]
climate related
Determine if the claim is *about climate science, climate change, environment, sustainability, or related topics *. - If yes→set "climate related": true. - If no→set "climate related": false
-
[20]
1997", "Paris Agreement
Regardless of this flag: - Create a *cloze question * (fill-in-the-blank statement) derived directly from the claim. - Replace the most important factual value in the claim with a blank: " ". - The cloze must be complete and understandable by itself (not vague or partial). - Provide the correct *answer* that fills the blank. - The answer must be a short b...
1997
-
[21]
The same locked subset is used for all models
Deterministic proportional sampling.Within each stratum, sample 10% without replacement using a fixed random seed; concatenate strata to form the subset. The same locked subset is used for all models. 3.Calibration phase (using already-run models).Starting from the reviewer’s suggestion (20%), we swept candidate rates {20%,15%,10%,5%} . For each rate, and...
-
[22]
Free BERT
Evaluation phase.We then evaluated new higher-tier closed models strictly on the locked 10% subset with identical prompts and evaluation scripts. Table 11.Results on the locked 10% calibrated subset following the reviewer’s proposed strategy. “Free BERT” refers to BERTScore (F1) on free-form answers. Model MCQ Acc Cloze Weighted Free BERT google gemini-2....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.