Training-Free Rate-Distortion-Perception Traversal With Diffusion
Pith reviewed 2026-05-25 07:13 UTC · model grok-4.3
The pith
Pre-trained diffusion models enable training-free traversal across the full rate-distortion-perception surface.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The proposed diffusion decoder is optimal for the distortion-perception tradeoff under AWGN observations, and the overall framework with the RCC module achieves the optimal RDP function in the Gaussian case. The approach is training-free and uses pre-trained diffusion models to adaptively compress while balancing bitrate, fidelity, and perceptual quality.
What carries the argument
The reverse channel coding (RCC) module paired with a score-scaled probability flow ODE decoder derived from pre-trained diffusion models.
If this is right
- Any point on the RDP surface becomes reachable by tuning the RCC rate and the ODE scaling parameter.
- The same pre-trained diffusion model works for multiple operating points without retraining.
- The framework supplies both a practical method and a proof of optimality for the Gaussian-AWGN setting.
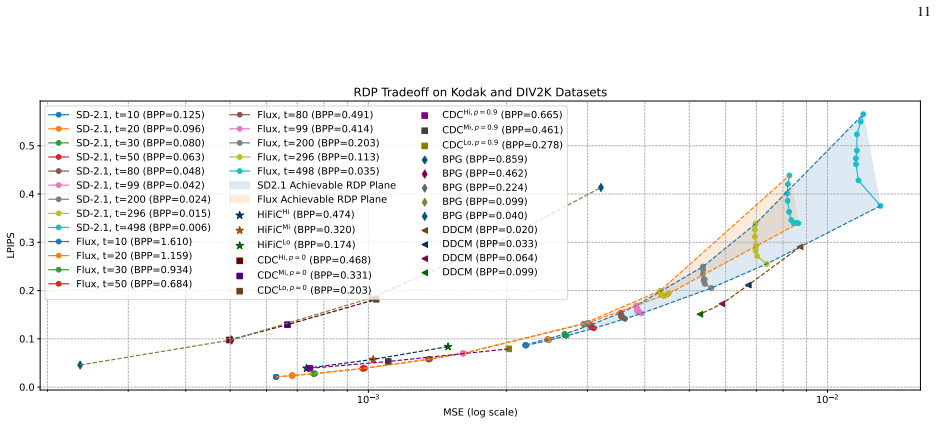
- Empirical tests on multiple datasets confirm that the method can navigate the ternary tradeoff.
Where Pith is reading between the lines
- The same construction might be tested on non-Gaussian sources to measure how far the optimality extends beyond the proved case.
- If the diffusion model already approximates the data distribution well, the method could eliminate the need to train separate compressors for different perception levels.
- Practical performance under non-AWGN channels remains open and could be checked with controlled experiments.
Load-bearing premise
Pre-trained diffusion models are assumed to be sufficiently expressive and well-calibrated to serve as near-optimal decoders once the score-scaled ODE and RCC components are added.
What would settle it
A direct computation that shows the achieved RDP curve falls short of the known optimal RDP function for Gaussian sources observed through AWGN would disprove the optimality claim.
Figures
















read the original abstract
The rate-distortion-perception (RDP) tradeoff characterizes the fundamental limits of lossy compression by jointly considering bitrate, reconstruction fidelity, and perceptual quality. While recent neural compression methods have improved perceptual performance, they typically operate at fixed points on the RDP surface, requiring retraining to target different tradeoffs. In this work, we propose a training-free framework that leverages pre-trained diffusion models to traverse the entire RDP surface. Our approach integrates a reverse channel coding (RCC) module with a novel score-scaled probability flow ODE decoder. We theoretically prove that the proposed diffusion decoder is optimal for the distortion-perception tradeoff under AWGN observations and that the overall framework with the RCC module achieves the optimal RDP function in the Gaussian case. Empirical results across multiple datasets demonstrate the framework's flexibility and effectiveness in navigating the ternary RDP tradeoff using pre-trained diffusion models. Our results establish a practical and theoretically grounded approach to adaptive, perception-aware compression.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a training-free framework for traversing the rate-distortion-perception (RDP) surface in lossy compression. It integrates a reverse channel coding (RCC) module with a novel score-scaled probability flow ODE decoder built on pre-trained diffusion models. The central claims are that this decoder is optimal for the distortion-perception tradeoff under AWGN observations and that the full RCC-augmented framework attains the optimal RDP function when the source is Gaussian, with supporting empirical results on multiple datasets.
Significance. If the optimality proofs are rigorously established and the assumptions on the pre-trained models hold, the result would be significant: it supplies a practical, training-free method to achieve any point on the RDP surface by leveraging existing diffusion checkpoints, thereby connecting information-theoretic limits to generative modeling without task-specific retraining.
major comments (2)
- [Abstract] Abstract: the claim that the diffusion decoder is optimal for the distortion-perception tradeoff under AWGN observations is asserted without any derivation steps, explicit assumption list, or proof sketch. Because this optimality is load-bearing for the central contribution, the manuscript must supply the full argument (including how the score-scaled PF-ODE yields the optimal posterior) rather than a high-level statement.
- Theoretical claims (Gaussian case): the assertion that the RCC-augmented framework achieves the optimal RDP function requires that the pre-trained diffusion model supplies a score function that exactly matches the source distribution under the AWGN observation model. No argument is provided showing that a generic checkpoint (typically trained on ImageNet-scale data) satisfies the required score-matching condition when the source is an arbitrary Gaussian or when the channel deviates from the training distribution; any mismatch immediately voids the optimality derivation.
minor comments (1)
- The abstract refers to 'empirical results across multiple datasets' demonstrating flexibility but does not name the datasets, the quantitative RDP metrics reported, or the baselines used for comparison.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on the theoretical claims. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the diffusion decoder is optimal for the distortion-perception tradeoff under AWGN observations is asserted without any derivation steps, explicit assumption list, or proof sketch. Because this optimality is load-bearing for the central contribution, the manuscript must supply the full argument (including how the score-scaled PF-ODE yields the optimal posterior) rather than a high-level statement.
Authors: We agree that the abstract presents the optimality claim at a high level. The full derivation, including the explicit assumptions and the steps showing how the score-scaled PF-ODE produces the optimal posterior under AWGN, appears in Section 3 of the manuscript. We will revise the abstract to incorporate a concise proof sketch and assumption list, and we will expand the introduction to preview the argument. revision: yes
-
Referee: [—] Theoretical claims (Gaussian case): the assertion that the RCC-augmented framework achieves the optimal RDP function requires that the pre-trained diffusion model supplies a score function that exactly matches the source distribution under the AWGN observation model. No argument is provided showing that a generic checkpoint (typically trained on ImageNet-scale data) satisfies the required score-matching condition when the source is an arbitrary Gaussian or when the channel deviates from the training distribution; any mismatch immediately voids the optimality derivation.
Authors: The Gaussian-case optimality result is derived under the assumption that the diffusion model supplies an exact score match to the source under the AWGN observation model; we will add an explicit statement of this assumption in the revised manuscript. We do not provide (and cannot provide) an argument that a generic ImageNet-trained checkpoint satisfies exact score matching for an arbitrary Gaussian source or mismatched channel, as this would generally not hold. The theoretical claim is therefore conditional on the score-matching condition, while the empirical results demonstrate practical RDP traversal with approximate scores from existing checkpoints. revision: partial
- We cannot supply an argument showing that generic pre-trained checkpoints satisfy the exact score-matching condition required for optimality when the source is an arbitrary Gaussian or the channel deviates from the training distribution.
Circularity Check
Theoretical optimality proof does not reduce to self-defined inputs or fitted quantities.
full rationale
The paper states a theoretical proof that the score-scaled probability flow ODE decoder is optimal for the distortion-perception tradeoff under AWGN observations and that the RCC-augmented framework attains the optimal RDP function for Gaussian sources. No equations, fitting procedures, or self-citation chains are visible that would make the optimality claim equivalent to its own inputs by construction. The result is presented as holding under explicit assumptions (AWGN channel, Gaussian source, sufficiently expressive pre-trained diffusion model) rather than being forced by redefinition or parameter fitting within the paper itself. This is the most common honest outcome for a derivation-focused theoretical claim.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The diffusion decoder is optimal for distortion-perception tradeoff under AWGN observations
- domain assumption The full framework achieves the optimal RDP function for Gaussian sources
invented entities (1)
-
score-scaled probability flow ODE decoder
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We theoretically prove that the proposed diffusion decoder is optimal for the distortion-perception tradeoff under AWGN observations and that the overall framework with the RCC module achieves the optimal RDP function in the Gaussian case.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_high_calibrated_iff unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
score-scaled probability flow ODE decoder
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Rethinking lossy compression: The rate-distortion-perception tradeoff,
Y . Blau and T. Michaeli, “Rethinking lossy compression: The rate-distortion-perception tradeoff,” inProceedings of the 36th International Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research, K. Chaudhuri and R. Salakhutdinov, Eds., vol. 97. PMLR, 09–15 Jun 2019, pp. 675–685
work page 2019
-
[2]
X. Niu, B. Bai, N. Guo, W. Zhang, and W. Han, “Rate–distortion–perception trade-off in information theory, generative models, and intelligent communications,”Entropy, vol. 27, no. 4, 2025. [Online]. Available: https://www.mdpi.com/1099-4300/27/4/373
work page 2025
-
[3]
V . M. Panaretos and Y . Zemel,An Invitation to Statistics in Wasserstein Space. Springer Cham, 2020
work page 2020
-
[4]
A coding theorem for the rate-distortion-perception function,
L. Theis and A. B. Wagner, “A coding theorem for the rate-distortion-perception function,” inNeural Compression Workshop at International Conference on Learning Representations (ICLR), 2021
work page 2021
-
[5]
On the rate-distortion-perception function,
J. Chen, L. Yu, J. Wang, W. Shi, Y . Ge, and W. Tong, “On the rate-distortion-perception function,”IEEE Journal on Selected Areas in Information Theory, vol. 3, no. 4, pp. 664–673, 2022
work page 2022
-
[6]
Z. Yan, F. Wen, R. Ying, C. Ma, and P. Liu, “On perceptual lossy compression: The cost of perceptual reconstruction and an optimal training framework,” inProceedings of the International Conference on Machine Learning (ICML), 2021
work page 2021
-
[7]
Rate-distortion-perception tradeoff based on the conditional-distribution perception measure,
S. Salehkalaibar, J. Chen, A. Khisti, and W. Yu, “Rate-distortion-perception tradeoff based on the conditional-distribution perception measure,”IEEE Transactions on Information Theory, vol. 70, no. 12, pp. 8432–8454, 2024
work page 2024
-
[8]
The rate-distortion-perception trade-off: the role of private randomness,
Y . Hamdi, A. B. Wagner, and D. Gündüz, “The rate-distortion-perception trade-off: the role of private randomness,” in2024 IEEE International Symposium on Information Theory (ISIT), 2024, pp. 1083–1088
work page 2024
-
[9]
Universal rate-distortion-perception representations for lossy compression,
G. Zhang, J. Qian, J. Chen, and A. Khisti, “Universal rate-distortion-perception representations for lossy compression,” inAdvances in Neural Information Processing Systems (NeurIPS), M. Ranzato, A. Beygelzimer, Y . Dauphin, P. Liang, and J. W. Vaughan, Eds., vol. 34. Curran Associates, Inc., 2021, pp. 11 517–11 529
work page 2021
-
[10]
High-fidelity generative image compression,
F. Mentzer, G. D. Toderici, M. Tschannen, and E. Agustsson, “High-fidelity generative image compression,”Advances in Neural Information Processing Systems (NeurIPS), vol. 33, 2020
work page 2020
-
[11]
Lossy image compression with conditional diffusion models,
R. Yang and S. Mandt, “Lossy image compression with conditional diffusion models,” inThirty-seventh Conference on Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[12]
Lossy compression with gaussian diffusion,
L. Theis, T. Salimans, M. D. Hoffman, and F. Mentzer, “Lossy compression with gaussian diffusion,”arXiv preprint, 2022, [Online]. Available: https://arxiv.org/abs/2206.08889
-
[13]
Lossy compression with pretrained diffusion models,
J. V onderfecht and F. Liu, “Lossy compression with pretrained diffusion models,” inThe Thirteenth International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[14]
PSC: Posterior sampling-based compression,
N. Elata, T. Michaeli, and M. Elad, “PSC: Posterior sampling-based compression,”arXiv preprint, 2025, [Online]. Available: https://arxiv.org/abs/2407.09896
-
[15]
Progressive compression with universally quantized diffusion models,
Y . Yang, J. Will, and S. Mandt, “Progressive compression with universally quantized diffusion models,” inThe Thirteenth International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[16]
Compressed image generation with denoising diffusion codebook models,
G. Ohayon, H. Manor, T. Michaeli, and M. Elad, “Compressed image generation with denoising diffusion codebook models,” inForty-second International Conference on Machine Learning (ICML), 2025. [Online]. Available: https://openreview.net/forum?id=cQHwUckohW
work page 2025
-
[17]
Channel simulation: Theory and applications to lossy compression and differential privacy,
C. T. Li, “Channel simulation: Theory and applications to lossy compression and differential privacy,”Found. Trends Commun. Inf. Theory, vol. 21, no. 6, pp. 847–1106, Dec. 2024
work page 2024
-
[18]
Strong functional representation lemma and applications to coding theorems,
C. T. Li and A. E. Gamal, “Strong functional representation lemma and applications to coding theorems,”IEEE Transaction on Information Theory, vol. 64, no. 11, pp. 6967–6978, nov 2018
work page 2018
-
[19]
Score-based generative modeling through stochastic differential equations,
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differential equations,” inInternational Conference on Learning Representations (ICLR), 2021
work page 2021
-
[20]
Reverse-time diffusion equation models,
B. D. Anderson, “Reverse-time diffusion equation models,”Stochastic Processes and their Applications, vol. 12, no. 3, pp. 313–326, 1982
work page 1982
-
[21]
A connection between score matching and denoising autoencoders,
P. Vincent, “A connection between score matching and denoising autoencoders,”Neural Computation, vol. 23, no. 7, pp. 1661–1674, 2011
work page 2011
-
[22]
Interacting particle solutions of fokker-planck equations through gradient-log-density estimation,
D. Maoutsa, S. Reich, and M. Opper, “Interacting particle solutions of fokker-planck equations through gradient-log-density estimation,” Entropy, vol. 22, no. 8, 2020
work page 2020
-
[23]
S. Särkkä and A. Solin,Applied Stochastic Differential Equations, ser. Institute of Mathematical Statistics Textbooks. Cambridge University Press, 2019. 40
work page 2019
-
[24]
High Perceptual Quality Image Denoising with a Posterior Sampling CGAN ,
G. Ohayon, T. Adrai, G. Vaksman, M. Elad, and P. Milanfar, “ High Perceptual Quality Image Denoising with a Posterior Sampling CGAN ,” in2021 IEEE/CVF International Conference on Computer Vision (ICCV) Workshops. Los Alamitos, CA, USA: IEEE Computer Society, Oct. 2021, pp. 1805–1813
work page 2021
-
[25]
A theory of the distortion-perception tradeoff in wasserstein space,
D. Freirich, T. Michaeli, and R. Meir, “A theory of the distortion-perception tradeoff in wasserstein space,” inAdvances in Neural Information Processing Systems (NeurIPS), A. Beygelzimer, Y . Dauphin, P. Liang, and J. W. Vaughan, Eds., 2021
work page 2021
-
[26]
Traversing distortion-perception tradeoff using a single score-based generative model,
Y . Wang, S. Bi, Y .-J. A. Zhang, and X. Yuan, “Traversing distortion-perception tradeoff using a single score-based generative model,” in Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), June 2025, pp. 2377–2386
work page 2025
-
[27]
The perception-distortion tradeoff,
Y . Blau and T. Michaeli, “The perception-distortion tradeoff,” in2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 6228–6237
work page 2018
-
[28]
Score-based reverse mean propagation for solving inverse problems,
Z. Xue, P. Cai, X. Yuan, and X. Gao, “Score-based reverse mean propagation for solving inverse problems,”IEEE Transactions on Signal Processing, vol. 73, pp. 3947–3962, 2025
work page 2025
-
[29]
Rate-distortion-perception tradeoff for gaussian vector sources,
J. Qian, S. Salehkalaibar, J. Chen, A. Khisti, W. Yu, W. Shi, Y . Ge, and W. Tong, “Rate-distortion-perception tradeoff for gaussian vector sources,”IEEE Journal on Selected Areas in Information Theory, vol. 6, pp. 1–17, 2025
work page 2025
-
[30]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inProceedings of the 34th International Conference on Neural Information Processing Systems (NeurIPS), 2020
work page 2020
-
[31]
Ntire 2017 challenge on single image super-resolution: Dataset and study,
E. Agustsson and R. Timofte, “Ntire 2017 challenge on single image super-resolution: Dataset and study,” in2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2017, pp. 1122–1131
work page 2017
-
[32]
High-Resolution Image Synthesis with Latent Diffusion Models ,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “ High-Resolution Image Synthesis with Latent Diffusion Models ,” in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Los Alamitos, CA, USA: IEEE Computer Society, Jun. 2022, pp. 10 674–10 685
work page 2022
-
[33]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Black-Forest-Labs, S. Batifol, A. Blattmann, F. Boesel, S. Consul, C. Diagne, T. Dockhorn, J. English, Z. English, P. Esser, S. Kulal, K. Lacey, Y . Levi, C. Li, D. Lorenz, J. Müller, D. Podell, R. Rombach, H. Saini, A. Sauer, and L. Smith, “Flux.1 kontext: Flow matching for in-context image generation and editing in latent space,”arXiv preprint, 2025, [O...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
The rate-distortion-perception tradeoff: The role of common randomness,
A. B. Wagner, “The rate-distortion-perception tradeoff: The role of common randomness,”arXiv preprint, 2022, [Online]. Available: https://arxiv.org/abs/2202.04147
-
[35]
C. M. Bishop,Pattern Recognition and Machine Learning. Springer New York, 2006
work page 2006
-
[36]
An empirical bayes approach to statistics,
H. E. Robbins, “An empirical bayes approach to statistics,” inProceedings of Third Berkeley Symposium on Mathematical Statistics and Probability, January 1956, pp. 157–163
work page 1956
-
[37]
S. Friedberg, A. Insel, and L. Spence,Linear Algebra, ser. Featured Titles for Linear Algebra (Advanced) Series. Pearson Education, 2003
work page 2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.