Regularized Reward-Punishment Reinforcement Learning
Pith reviewed 2026-06-29 04:46 UTC · model grok-4.3
The pith
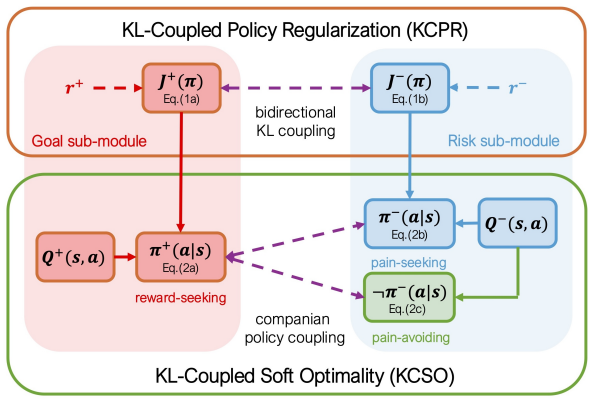
KL-Coupled Policy Regularization lets reward-seeking and punishment-avoiding policies act as dynamic priors for each other.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
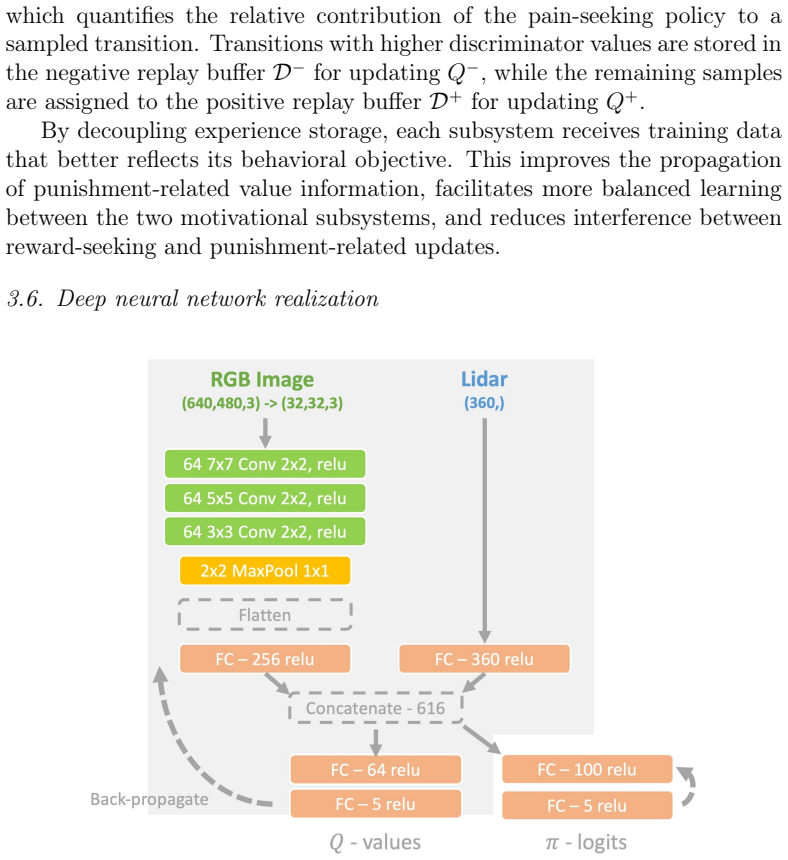
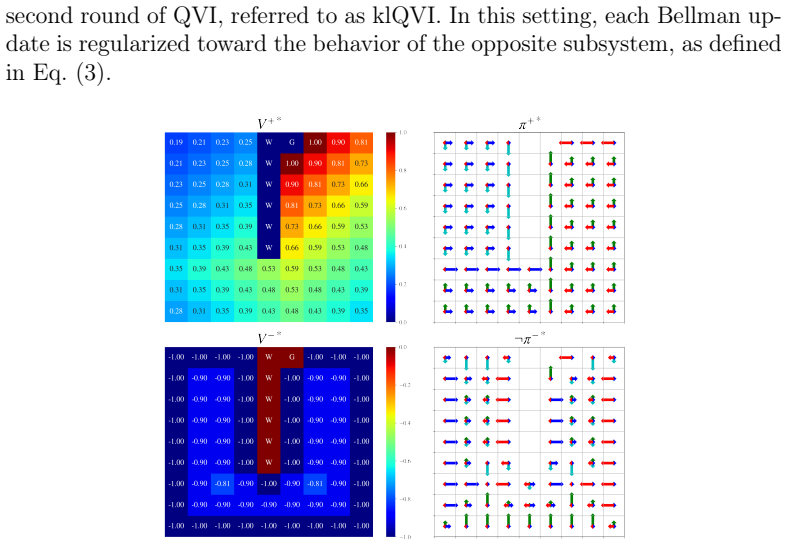
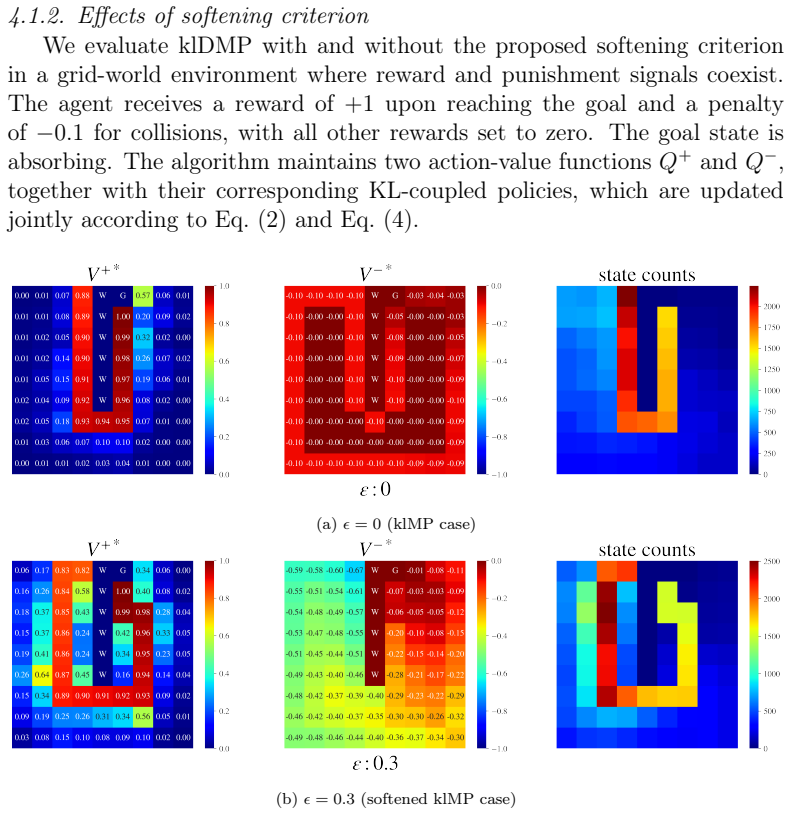
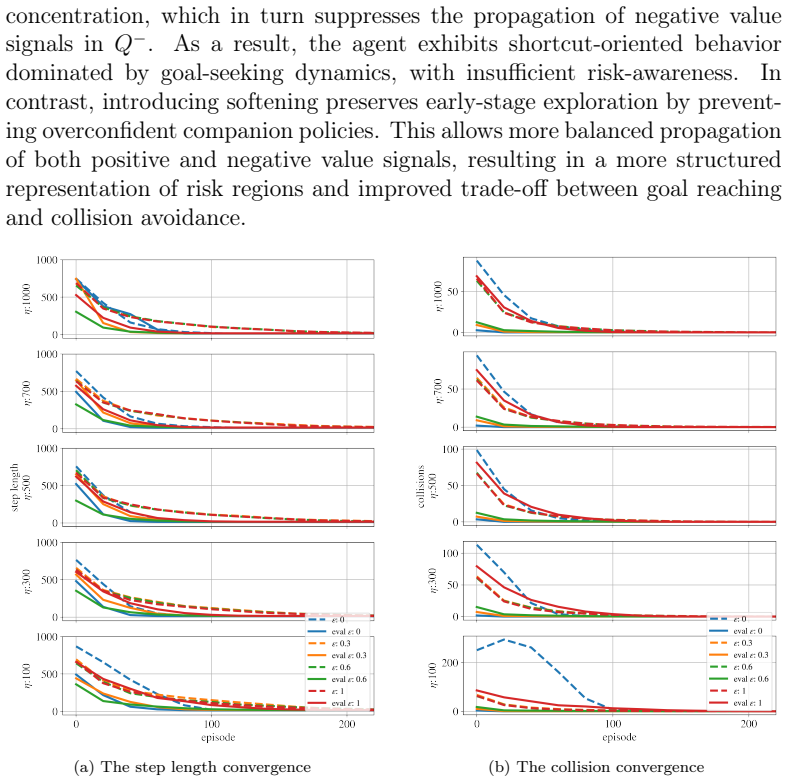
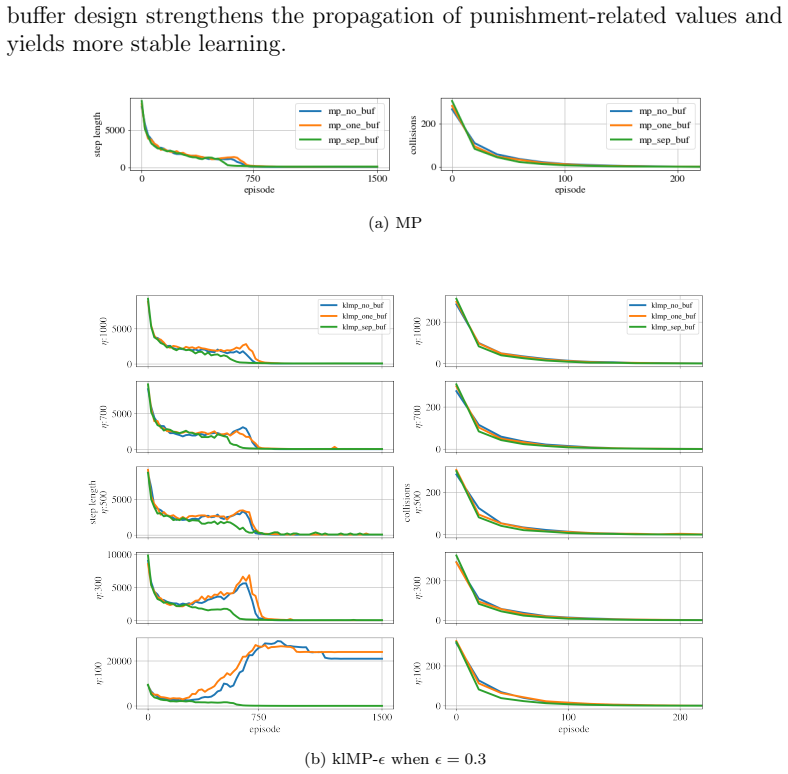
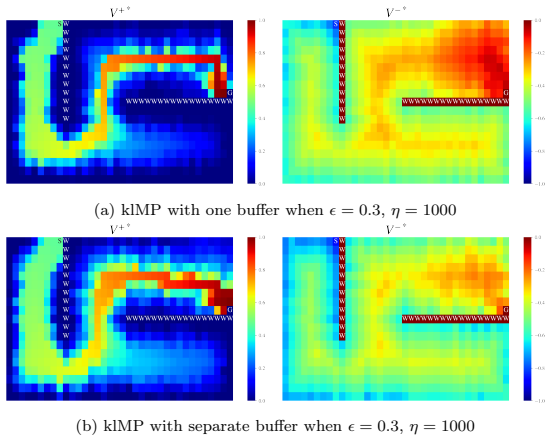
KL-Coupled Policy Regularization (KCPR) enables direct interactions between companion policies by treating each as a dynamically learned prior for the other. From KCPR the authors derive KL-Coupled Soft Optimality (KCSO), which produces coupled soft-optimal policies and KL-regularized Bellman operators. These operators let reward and punishment information jointly influence value propagation. A companion-prior softening mechanism is added for stability, and separate replay buffers are used to balance the two kinds of experience. The resulting algorithm, klDMP, is shown to improve safety and stability while retaining task performance.
What carries the argument
KL-Coupled Policy Regularization (KCPR), the mechanism that treats each policy as a dynamically learned prior for its companion so that reward and punishment information jointly shape value propagation through KL-regularized operators.
If this is right
- Reward and punishment signals jointly affect value propagation via the coupled KL-regularized Bellman operators.
- The companion-prior softening mechanism improves learning stability.
- Separate replay buffers for reward and punishment experience help balance the two objectives.
- Policy-level coordination provides an effective mechanism for integrating multiple behavioral objectives in reinforcement learning.
- The approach maintains competitive task performance while increasing safety in grid-world and robotic navigation domains.
Where Pith is reading between the lines
- The same prior-coupling idea could be applied to other pairs of conflicting objectives, such as speed versus energy use, without requiring new objective-specific machinery.
- Dynamic priors might reduce the need for hand-tuned weighting parameters between objectives by letting the policies negotiate influence through the regularization term.
- If the softening mechanism proves robust, it could be tested in environments where one objective must dominate only after the other has reached a threshold.
- The framework might extend naturally to settings with more than two companion policies by chaining the prior relations.
Load-bearing premise
Treating each policy as a dynamically learned prior for the other produces stable joint value propagation and safety gains without introducing new instabilities.
What would settle it
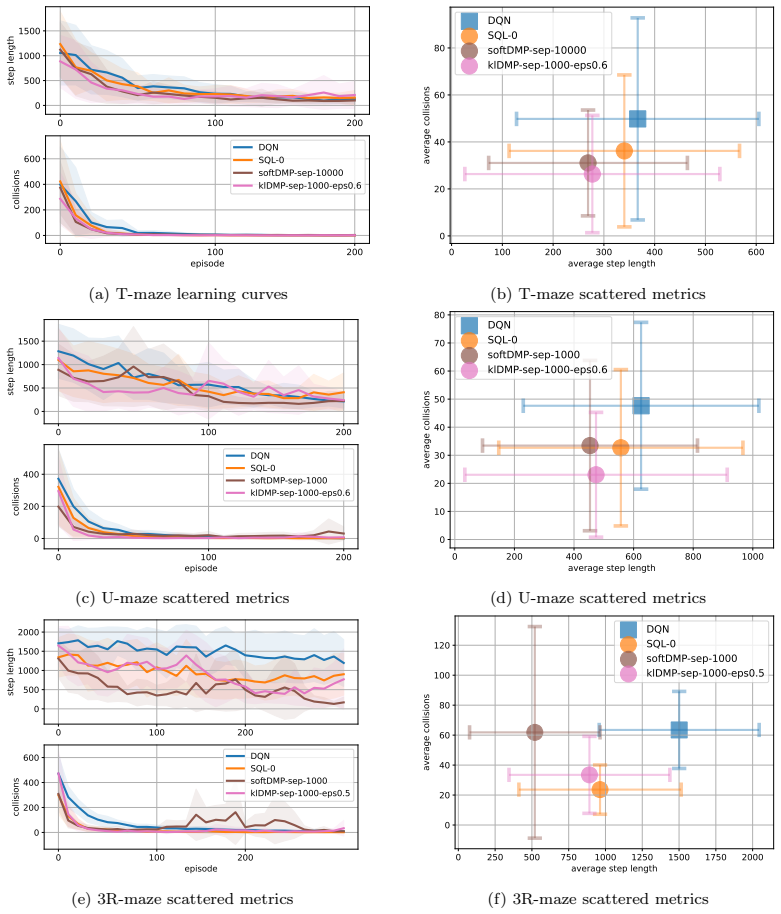
In the Gazebo robotic navigation tasks, if klDMP shows no improvement in safety metrics or exhibits more unstable learning curves than the independent baselines DQN, SQL, and softDMP, the central claim would be falsified.
Figures

read the original abstract
We propose KL-Coupled Policy Regularization (KCPR), a policy coordination framework for Reward-Punishment Reinforcement Learning (RPRL). Based on KCPR, we derive KL-Coupled Soft Optimality (KCSO) and develop its deep realization, klDMP. Unlike existing RPRL approaches that optimize reward-seeking and punishment-related policies largely independently, KCPR enables direct interactions between companion policies by treating each as a dynamically learned prior for the other. KCSO yields coupled soft-optimal policies and KL-regularized Bellman operators, allowing reward and punishment information to jointly influence value propagation. To improve learning stability, we introduce a companion-prior softening mechanism and evaluate separate replay-buffer designs for balancing reward- and punishment-related experience. Experiments in grid-world and Gazebo robotic navigation tasks demonstrate that klDMP improves safety and learning stability while maintaining competitive task performance compared with DQN, SQL and softDMP. These results suggest that policy-level coordination provides an effective mechanism for integrating multiple behavioral objectives and may serve as a useful design principle for reinforcement learning systems with interacting motivational processes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes KL-Coupled Policy Regularization (KCPR) as a coordination framework for Reward-Punishment Reinforcement Learning (RPRL). It derives KL-Coupled Soft Optimality (KCSO) producing coupled soft-optimal policies and KL-regularized Bellman operators that allow joint reward-punishment influence on value propagation. The deep implementation klDMP incorporates a companion-prior softening mechanism and separate replay buffers; experiments in grid-world and Gazebo navigation tasks report gains in safety and stability over DQN, SQL, and softDMP.
Significance. If the derivations hold and the reported gains are robust, the approach could supply a useful design principle for RL systems that must integrate multiple motivational processes, particularly in safety-critical settings. The explicit softening mechanism directly targets the stability concern raised by treating companion policies as dynamic priors.
major comments (1)
- [Abstract] Abstract: the central claims that KCSO yields 'coupled soft-optimal policies and KL-regularized Bellman operators' and that reward/punishment information 'jointly influence value propagation' are asserted without any equations, derivation steps, or proof sketches. This gap prevents verification of the load-bearing theoretical contribution.
minor comments (1)
- The baselines include 'softDMP'; a brief definition or citation would clarify its relation to the proposed klDMP.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for highlighting the need for clearer linkage between the abstract and the theoretical contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims that KCSO yields 'coupled soft-optimal policies and KL-regularized Bellman operators' and that reward/punishment information 'jointly influence value propagation' are asserted without any equations, derivation steps, or proof sketches. This gap prevents verification of the load-bearing theoretical contribution.
Authors: We agree that the abstract presents these claims at a summary level without equations or derivation steps. The full derivations of KCSO, the coupled soft-optimal policies, and the KL-regularized Bellman operators (including the joint influence on value propagation) appear in Sections 3.2–3.3 of the manuscript, with the relevant operators and proof outlines. To address the concern, we will revise the abstract to include a concise reference to the key theoretical elements (e.g., 'as derived via the KL-regularized Bellman operators under KCPR'). revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description present KCPR as a proposed coordination framework that treats companion policies as dynamic priors, derives KCSO with coupled soft-optimal policies and KL-regularized operators, and introduces a companion-prior softening mechanism for stability. No equations, self-citations, or derivation steps are shown that reduce any claimed prediction or optimality result to a fitted input by construction, rename a known result, or rely on load-bearing self-citation chains. Experiments in grid-world and robotic tasks are cited as independent support, making the central claims self-contained against external benchmarks rather than internally forced.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Seymour, N
B. Seymour, N. Daw, P. Dayan, T. Singer, R. Dolan, Differential encod- ing of losses and gains in the human striatum, Journal of Neuroscience 27 (2007) 4826–31
2007
-
[2]
Seymour, N
B. Seymour, N. Daw, J. P. Roiser, P. Dayan, R. Dolan, Serotonin selectively modulates reward value in human decision-making, Journal of Neuroscience 32 (2012) 5833–42. 26
2012
-
[3]
Eldar, T
E. Eldar, T. U. Hauser, P. Dayan, R. J. Dolan, Striatal structure and function predict individual biases in learning to avoid pain, Proceedings of the National Academy of Sciences of the United States of America 113 (2016) 4812–7
2016
-
[4]
Elfwing, B
S. Elfwing, B. Seymour, Parallel reward and punishment control in humans and robots: safe reinforcement learning using the maxpain al- gorithm, in: Proc. of the 7th Joint IEEE International Conference on Development and Learning and on Epigenetic Robotics, 2017, pp. 140–7
2017
-
[5]
J. Wang, S. Elfwing, E. Uchibe, Deep reinforcement learning by par- allelizing reward and punishment using the maxpain architecture, in: Proc. of the 8th Joint IEEE International Conference on Development and Learning and on Epigenetic Robotics, IEEE, 2018
2018
-
[6]
J. Wang, S. Elfwing, E. Uchibe, Modular deep reinforcement learning from reward and punishment for robot navigation, Neural Networks 135 (2021) 115–26
2021
-
[7]
J. Wang, E. Uchibe, Reward-punishment reinforcement learning with maximum entropy, in: 2024 International Joint Conference on Neural Networks (IJCNN), IEEE, 2024, pp. 1–7
2024
-
[8]
M. G. Azar, V. Gómez, H. J. Kappen, Dynamic policy programming, Journal of Machine Learning Research 13 (2012) 3207–45
2012
-
[9]
R. Fox, A. Pakman, N. Tishby, Taming the noise in reinforcement learn- ing via soft updates, in: Proc. of the 32nd Conference on Uncertainty in Artificial Intelligence, 2016
2016
-
[10]
Haarnoja, H
T. Haarnoja, H. Tang, P. Abbeel, S. Levine, Reinforcement learning with deep energy-based policies, in: Proc. of the 34th International Conference on Machine Learning, 2017, pp. 1352–61
2017
-
[11]
Haarnoja, A
T. Haarnoja, A. Zhou, P. Abbeel, S. Levine, Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor, in: Proc. of the 35th International Conference on Machine Learning, 2018, pp. 1861–70. 27
2018
-
[12]
Peters, K
J. Peters, K. Mulling, Y. Altun, Relative entropy policy search, in: Pro- ceedings of the AAAI Conference on Artificial Intelligence, volume 24, 2010, pp. 1607–1612
2010
-
[13]
Schulman, S
J. Schulman, S. Levine, P. Abbeel, M. Jordan, P. Moritz, Trust region policy optimization, in: International conference on machine learning, PMLR, 2015, pp. 1889–1897
2015
-
[14]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, O. Klimov, Proximal policy optimization algorithms, arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[15]
On the Opportunities and Risks of Foundation Models
R. Bommasani, On the opportunities and risks of foundation models, arXiv preprint arXiv:2108.07258 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y. Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsu, et al., Rt-1: Robotics transformer for real-world control at scale, arXiv preprint arXiv:2212.06817 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al., Rt-2: Vision-language-action models trans- fer web knowledge to robotic control, in: Conference on Robot Learning, PMLR, 2023, pp. 2165–2183
2023
-
[18]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.,pi_0: A vision-language-action flow model for general robot control, arXiv preprint arXiv:2410.24164 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Karlsson, Learning to solve multiple goals, Ph.D
J. Karlsson, Learning to solve multiple goals, Ph.D. thesis, University of Rochester, 1997
1997
-
[20]
M. Humphrys, Action selection methods using reinforcement learning, in: From Animals to Animats 4: Proceedings of the Fourth International Conference on Simulation of Adaptive Behavior, 1996, pp. 135–144
1996
-
[21]
Sprague, D
N. Sprague, D. Ballard, Multiple-goal reinforcement learning with mod- ular sarsa(0), in: Proc. of the 18th International Joint Conference on Artificial Intelligence, 2003, pp. 1445–1447. 28
2003
-
[22]
van Seijen, M
H. van Seijen, M. Fatemi, J. Romoff, R. Laroche, T. Barnes, J. Tsang, Hybrid reward architecture for reinforcement learning, in: Advances in Neural Information Processing Systems 30, 2017
2017
-
[23]
Z. Lin, D. Yang, L. Zhao, T. Qin, G. Yang, T.-Y. Liu, Rd2: Reward de- composition with representation decomposition, in: Advances in Neural Information Processing Systems 33, 2020
2020
-
[24]
Okada, H
H. Okada, H. Yamakawa, T. Omori, Two dimensional evaluation re- inforcement learning, in: International Conference on Artificial Neural Networks, Springer, 2001, pp. 370–377
2001
-
[25]
R. Lowe, T. Ziemke, Exploring the relationship of reward and punish- ment in reinforcement learning, in: Proc. of the 2013 IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning (AD- PRL), IEEE, 2013, pp. 140–147
2013
-
[26]
Kobayashi, T
T. Kobayashi, T. Aotani, J. R. Guadarrama-Olvera, E. Dean-Leon, G. Cheng, Reward-punishment actor-critic algorithm applying to robotic non-grasping manipulation, in: 2019 Joint IEEE 9th In- ternational Conference on Development and Learning and Epigenetic Robotics (ICDL-EpiRob), IEEE, 2019, pp. 37–42
2019
-
[27]
B. Lin, G. A. Cecchi, D. Bouneffouf, J. Reinen, I. Rish, A story of two streams: Reinforcement learning models from human behavior and neuropsychiatry, in: Proc. of the 19th International Conference on Au- tonomous Agents and Multi-Agent Systems, 2020, pp. 744–752
2020
-
[28]
Liebenow, R
B. Liebenow, R. Jones, E. DiMarco, J. D. Trattner, J. Humphries, L. P. Sands, K. P. Spry, C. K. Johnson, E. B. Farkas, A. Jiang, et al., Computational reinforcement learning, reward (and punishment), and dopamine in psychiatric disorders, Frontiers in Psychiatry 13 (2022) 886297
2022
-
[29]
Kullback, R
S. Kullback, R. A. Leibler, On information and sufficiency, The Annals of Mathematical Statistics 22 (1951) 79–86
1951
-
[30]
Asadi, M
K. Asadi, M. L. Littman, An alternative softmax operator for rein- forcement learning, in: Proc. of the 34th International Conference on Machine Learning, 2017. 29
2017
-
[31]
A. A. Rusu, S. G. Colmenarejo, C. Gulcehre, G. Desjardins, J. Kirk- patrick, R. Pascanu, V. Mnih, K. Kavukcuoglu, R. Hadsell, Policy dis- tillation, arXiv preprint arXiv:1511.06295 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[32]
Actor-Mimic: Deep Multitask and Transfer Reinforcement Learning
E. Parisotto, J. L. Ba, R. Salakhutdinov, Actor-mimic: Deep multitask and transfer reinforcement learning, arXiv preprint arXiv:1511.06342 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[33]
Y. Teh, V. Bapst, W. M. Czarnecki, J. Quan, J. Kirkpatrick, R. Hadsell, N. Heess, R. Pascanu, Distral: Robust multitask reinforcement learning, Advances in Neural Information Processing Systems 30 (2017)
2017
-
[34]
Van Seijen, H
H. Van Seijen, H. Van Hasselt, S. Whiteson, M. Wiering, A theoretical and empirical analysis of expected sarsa, in: Proc. of the IEEE Sympo- sium on Adaptive Dynamic Programming and Reinforcement Learning, IEEE, 2009, pp. 177–184
2009
-
[35]
V. Mnih, A. P. Badia, M. Mirza, A. Graves, T. Lillicrap, T. Harley, D. Silver, K. Kavukcuoglu, Asynchronous methods for deep reinforce- ment learning, in: International conference on machine learning, PmLR, 2016, pp. 1928–1937
2016
-
[36]
Garcia, F
J. Garcia, F. Fernandez, A comprehensive survey on safe reinforcement learning, Journal of Machine Learning Research 16 (2015) 1437–1480
2015
- [37]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.