Follow the Latent Roadmap: Navigating Revocable Decoding for Diffusion LLMs with Anchor Tokens
Pith reviewed 2026-06-27 03:50 UTC · model grok-4.3
The pith
Anchor tokens identified by temporal consistency let revocable decoding in diffusion LLMs reduce error propagation and local reinforcement without any training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
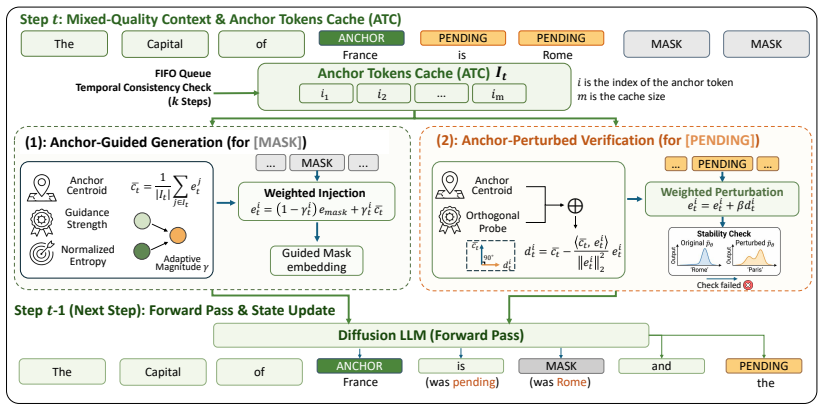
ASRD decouples decoding context into trusted Anchor Tokens identified via temporal consistency and uncertain candidates inside a dynamic Anchor Tokens Cache. Anchor-Guided Generation injects entropy-weighted anchor signals into masked positions to implicitly rectify attention toward the reliable global skeleton. Anchor-Perturbed Verification applies orthogonal perturbations to uncertain candidate tokens, destabilizing and remasking errors driven by fragile local consensus.
What carries the argument
Anchor Tokens identified via temporal consistency, together with Anchor-Guided Generation and Anchor-Perturbed Verification operating inside the embedding space via a dynamic cache.
If this is right
- Error propagation is reduced because new tokens receive attention signals from the reliable global skeleton rather than from erroneous context.
- Local error reinforcement is broken because orthogonal perturbations destabilize the mutual reinforcement that lets errors evade detection.
- The same accuracy and speed gains hold across recent remasking baselines on math and coding benchmarks.
- Inference throughput increases because fewer erroneous tokens require repeated verification steps.
Where Pith is reading between the lines
- Temporal consistency may serve as a general signal for identifying reliable context in any iterative token-generation process that builds output step by step.
- The embedding-space separation of trusted and uncertain tokens could be tested in non-diffusion autoregressive models that also use revocable or speculative decoding.
- If anchor tokens prove stable across different model scales, the approach might reduce the need for post-training alignment steps aimed at error correction.
Load-bearing premise
Tokens identified via temporal consistency function as reliably trusted anchors whose signals can implicitly rectify attention and whose perturbations can reliably destabilize local error consensus without introducing new failure modes.
What would settle it
An experiment on the same math and coding benchmarks in which replacing the anchor signals with random embeddings produces no accuracy gain or throughput loss would falsify the claim that the mechanisms are responsible for the reported improvements.
Figures


read the original abstract
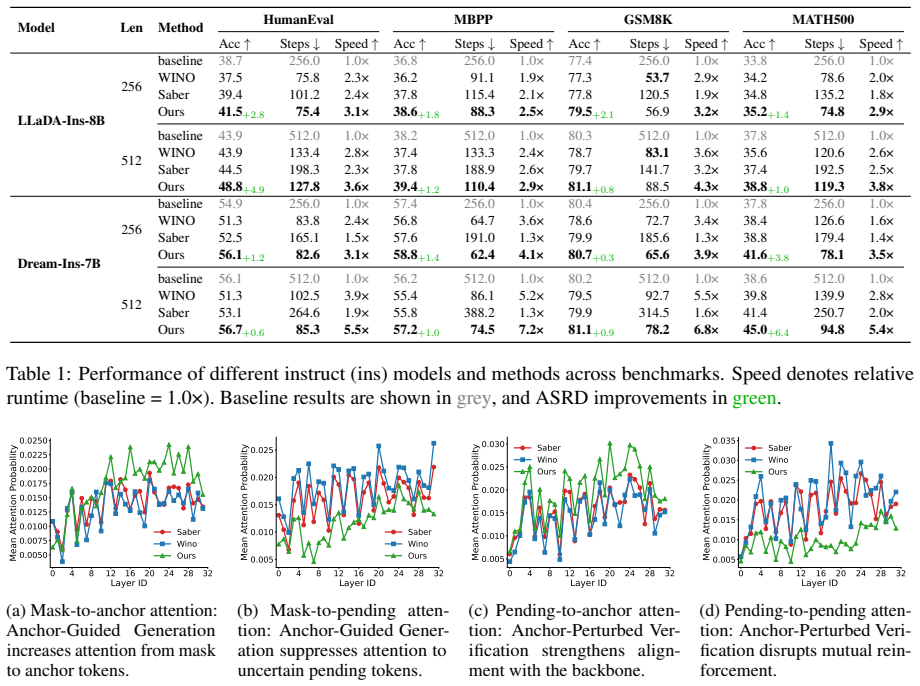
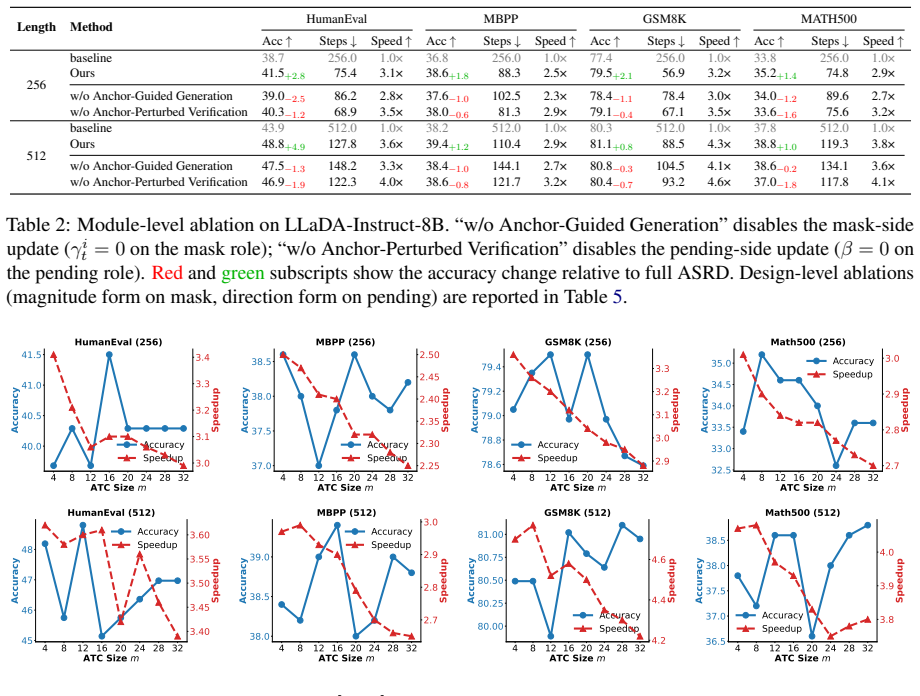
Diffusion Large Language Models (dLLMs) offer a promising avenue for parallel generation but face a trade-off between decoding speed and quality. While revocable decoding strategies attempt to mitigate errors by verifying and remasking tokens, they typically operate within a mixed-quality context. This leads to two critical failures: \textit{Error Propagation}, where new tokens absorb toxic information from erroneous context, and \textit{Local Error Reinforcement}, where errors mutually reinforce each other to evade detection. To alleviate these challenges, we propose ASRD (Anchor Supervised Revocable Decoding), a training-free framework that operates within the embedding space. ASRD explicitly decouples the decoding context into trusted \textit{Anchor Tokens}, which are identified via temporal consistency, and uncertain candidates. Leveraging a dynamic Anchor Tokens Cache, we introduce two complementary mechanisms: (1) Anchor-Guided Generation, which injects entropy-weighted anchor signals into masked positions to implicitly rectify attention toward the reliable global skeleton; and (2) Anchor-Perturbed Verification, which applies orthogonal perturbations to uncertain candidate tokens, destabilizing and remasking errors driven by fragile local consensus. Extensive experiments on math and coding benchmarks demonstrate that ASRD outperforms recent remasking baselines, achieving accuracy improvements of up to 6.4\% while accelerating inference throughput by up to 7.2$\times$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ASRD (Anchor Supervised Revocable Decoding), a training-free framework for revocable decoding in diffusion LLMs. Anchor tokens are identified via temporal consistency and cached; these are used in Anchor-Guided Generation (injecting entropy-weighted signals into masked positions to rectify attention) and Anchor-Perturbed Verification (orthogonal perturbations to destabilize local error consensus). The central claim is that this mitigates Error Propagation and Local Error Reinforcement, yielding up to 6.4% accuracy gains and 7.2× throughput on math and coding benchmarks versus recent remasking baselines.
Significance. If the anchor-reliability assumption holds, the work supplies a practical, training-free route to balancing speed and quality in parallel dLLM decoding by exploiting temporal consistency for trusted signals in embedding space. The absence of any training requirement and the explicit decoupling of trusted versus uncertain tokens are concrete strengths that could influence follow-on work on revocable decoding.
major comments (3)
- [Abstract] Abstract: the headline claims of 6.4% accuracy improvement and 7.2× throughput are stated without reference to the exact baselines, number of runs, variance, or controls; because these numbers are the sole quantitative support for the central claim, the experimental section must supply the missing details and ablations before the result can be evaluated.
- [Method (Anchor identification)] Method description of temporal consistency and Anchor Tokens: the load-bearing premise that temporally consistent tokens are reliably correct (so that their signals rectify attention and their perturbations break error consensus) receives no direct measurement of anchor precision against ground truth and no failure-case analysis; nothing in the provided text rules out the possibility that persistent errors are cached as anchors and thereby reinforced.
- [Experiments] Experiments section: no ablation isolates performance when anchor selection is forced to include known errors or when consistency is replaced by random selection; such a control is required to test whether the reported gains survive the scenario the skeptic note identifies.
minor comments (2)
- [Abstract] Abstract: the phrase 'entropy-weighted anchor signals' is introduced without even a one-line definition or reference to the weighting formula; a parenthetical would aid readability.
- [Method] Notation: the dynamic Anchor Tokens Cache is described at a high level; the update rule and eviction policy should be stated explicitly in the method section.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which help strengthen the presentation of our work on ASRD. We address each major comment below, agreeing where revisions are needed and providing clarifications.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claims of 6.4% accuracy improvement and 7.2× throughput are stated without reference to the exact baselines, number of runs, variance, or controls; because these numbers are the sole quantitative support for the central claim, the experimental section must supply the missing details and ablations before the result can be evaluated.
Authors: We agree with this observation. The abstract will be revised to specify that the 6.4% accuracy gain is the maximum improvement over the best-performing recent remasking baseline across the evaluated math and coding benchmarks (MATH, GSM8K, HumanEval, MBPP), and the 7.2× throughput is the peak speedup under the same parallel decoding setup. The experiments section reports results averaged over multiple runs with variance; we will add explicit references in the abstract and ensure all tables include standard deviations. This revision will be made. revision: yes
-
Referee: [Method (Anchor identification)] Method description of temporal consistency and Anchor Tokens: the load-bearing premise that temporally consistent tokens are reliably correct (so that their signals rectify attention and their perturbations break error consensus) receives no direct measurement of anchor precision against ground truth and no failure-case analysis; nothing in the provided text rules out the possibility that persistent errors are cached as anchors and thereby reinforced.
Authors: This is a valid concern regarding the core assumption. The manuscript does not include direct precision measurements in the submitted version. To address this, we will add in the revised manuscript a quantitative analysis of anchor token accuracy against ground truth on the math benchmarks, along with a discussion of potential failure cases where persistent errors might be selected as anchors and how the Anchor-Perturbed Verification mitigates reinforcement. We believe this will substantiate the premise. revision: yes
-
Referee: [Experiments] Experiments section: no ablation isolates performance when anchor selection is forced to include known errors or when consistency is replaced by random selection; such a control is required to test whether the reported gains survive the scenario the skeptic note identifies.
Authors: We acknowledge the need for these control experiments to isolate the contribution of the temporal consistency mechanism. In the revision, we will include two new ablations: (1) forcing anchor selection to include a percentage of known erroneous tokens and measuring the impact on final accuracy, and (2) replacing consistency-based selection with random selection of the same number of anchors. These will demonstrate that the gains are attributable to the reliable anchor identification rather than the mechanisms alone. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes ASRD, a training-free method that identifies anchor tokens via temporal consistency and applies two mechanisms (Anchor-Guided Generation and Anchor-Perturbed Verification) in embedding space. Performance claims rest on empirical results from math and coding benchmarks rather than any equations, fitted parameters presented as predictions, or load-bearing self-citations. No derivation step reduces by construction to its own inputs; the central claims remain externally falsifiable via benchmark accuracy and throughput measurements.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Temporal consistency across decoding steps identifies trusted anchor tokens that can serve as a reliable global skeleton.
invented entities (1)
-
Anchor Tokens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Evaluating large language models trained on code.Preprint, arXiv:2107.03374. Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.Preprint, arXiv:2110.14168. Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in neural information processing systems, 35:16344–16359. Yihong Dong, Zhaoyu Ma, Xue Jiang, Zhiyuan Fan, Jiaru Qian, Yongmi...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
The llama 3 herd of models.Preprint, arXiv:2407.21783. Zhengfu He, Tianxiang Sun, Qiong Tang, Kuanning Wang, Xuan-Jing Huang, and Xipeng Qiu. 2023. Dif- fusionbert: Improving generative masked language models with diffusion models. InProceedings of the 61st annual meeting of the association for compu- tational linguistics (volume 1: Long papers), pages 45...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Accelerating diffusion llms via adaptive paral- lel decoding.arXiv preprint arXiv:2506.00413. Wonjun Kang, Kevin Galim, Seunghyuk Oh, Minjae Lee, Yuchen Zeng, Shuibai Zhang, Coleman Hooper, Yuezhou Hu, Hyung Il Koo, Nam Ik Cho, and 1 oth- ers. 2025. Parallelbench: Understanding the trade- offs of parallel decoding in diffusion llms.arXiv preprint arXiv:25...
-
[5]
dLLM-Cache: Accelerating Diffusion Large Language Models with Adaptive Caching
Let’s verify step by step. InThe Twelfth Inter- national Conference on Learning Representations. Zhiyuan Liu, Yicun Yang, Yaojie Zhang, Junjie Chen, Chang Zou, Qingyuan Wei, Shaobo Wang, and Lin- feng Zhang. 2025. dllm-cache: Accelerating diffu- sion large language models with adaptive caching. Preprint, arXiv:2506.06295. Aaron Lou, Chenlin Meng, and Stef...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Discrete diffusion modeling by estimating the ratios of the data distribution.arXiv preprint arXiv:2310.16834. Xinyin Ma, Runpeng Yu, Gongfan Fang, and Xinchao Wang. 2025. dkv-cache: The cache for diffusion language models.arXiv preprint arXiv:2505.15781. Rabeeh Karimi Mahabadi, Hamish Ivison, Jaesung Tae, James Henderson, Iz Beltagy, Matthew E Peters, an...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Get to the point: Summarization with pointer- generator networks. InProceedings of the 55th An- nual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1073– 1083, Vancouver, Canada. Association for Computa- tional Linguistics. Yuerong Song, Xiaoran Liu, Ruixiao Li, Zhigeng Liu, Zengfeng Huang, Qipeng Guo, Ziwei He, an...
-
[8]
Dream 7B: Diffusion Large Language Models
Dream 7b: Diffusion large language models. arXiv preprint arXiv:2508.15487. Siyan Zhao, Devaansh Gupta, Qinqing Zheng, and Aditya Grover. 2025. d1: Scaling reasoning in diffu- sion large language models via reinforcement learn- ing.arXiv preprint arXiv:2504.12216. Fengqi Zhu, Rongzhen Wang, Shen Nie, Xiaolu Zhang, Chunwei Wu, Jun Hu, Jun Zhou, Jianfei Che...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
We posit the following assumptions regarding the model’s behavior and the decoding environment:
Let w∈V be an incorrect candidate token (w̸=x i 0). We posit the following assumptions regarding the model’s behavior and the decoding environment:
-
[10]
That is, there exists a positivesemantic margin∆ sem: p∗(xi 0)−p ∗(w) = ∆sem >0,(1) where p∗(·) denotes the intrinsic, denoised probability of a token
Semantic Capability:We assume the model is semantically capable, meaning that in a noise-free (ideal) context, the intrinsic confi- dence for the ground truth xi 0 is strictly higher than that for the incorrect candidatew. That is, there exists a positivesemantic margin∆ sem: p∗(xi 0)−p ∗(w) = ∆sem >0,(1) where p∗(·) denotes the intrinsic, denoised probab...
-
[11]
Noise:The observed probability pθ(xi 0 =v|x s) at any step s is the sum of the intrinsic prior p∗(v) and a stochastic noise term ϵs,v
i.i.d. Noise:The observed probability pθ(xi 0 =v|x s) at any step s is the sum of the intrinsic prior p∗(v) and a stochastic noise term ϵs,v. We further assume that the differ- ential noise ηs ≜ϵ s,xi 0 −ϵ s,w is symmetric around 0 and i.i.d. across decoding steps s (this holds, e.g., when ϵs,xi 0 ⊥ϵ s,w with each marginally symmetric, or when the noise v...
-
[12]
Rearranging the inequality yields: ηs < p ∗(w)−p ∗(xi
+ϵ s,xi 0 .(3) We define thedifferential noiseat step s as ηs ≜ ϵs,xi 0 −ϵ s,w. Rearranging the inequality yields: ηs < p ∗(w)−p ∗(xi
-
[13]
False Positive
=−∆ sem. This means that the error occurs only when the differential noise ηs is sufficiently negative to overcome the 14 Threshold scheduleτ(WINO, ASRD) Dataset Method τ=0.6τ=0.7τ=0.8τ=0.9 Acc Speed Acc Speed Acc Speed Acc Speed MATH500 WINO 33.0 2.9×33.6 2.3×34.2 2.0×34.8 1.5× ASRD33.2 3.3×35.2 2.9×35.6 2.2×36.0 1.7× MBPP WINO 36.2 2.9×36.2 1.9×36.8 1.6...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.