Multi-Rollout On-Policy Distillation via Peer Successes and Failures
Pith reviewed 2026-05-14 21:25 UTC · model grok-4.3
The pith
By conditioning teacher signals on both successful and failed peer rollouts from the same prompt, multi-rollout on-policy distillation supplies denser and better-aligned supervision than single-rollout baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
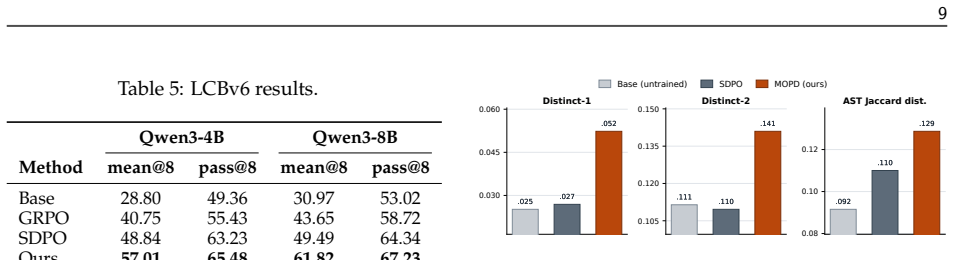
MOPD constructs teacher signals by conditioning on the student's local rollout group, employing both positive peer imitation and contrastive success-failure conditioning; the resulting mixed contexts yield teacher scores that align more closely with verifier rewards and deliver consistent gains over standard on-policy distillation baselines on competitive programming, mathematical reasoning, scientific question answering, and tool-use benchmarks.
What carries the argument
The peer-conditioned distillation framework that builds teacher targets from the student's own multi-rollout group by contrasting successful and failed trajectories for the identical prompt.
If this is right
- Distillation performance improves when the teacher sees both correct and incorrect student attempts for the same prompt rather than one attempt at a time.
- Mixed success-failure contexts increase the correlation between the teacher's token-level scores and the external verifier's binary reward.
- On-policy methods become more effective when they treat the student's trial-and-error set as a structured source of positive and negative evidence.
- The gains appear across four distinct reasoning domains, suggesting the mechanism is not tied to any single task format.
Where Pith is reading between the lines
- The same peer-conditioning idea could be applied in other on-policy RL settings where multiple trajectories are sampled per state to sharpen value estimates.
- If the peer-group construction is kept instance-adaptive, it may reduce the need for hand-crafted negative examples or additional preference data.
- The alignment result suggests that future verifier design could be guided by how well its signals match what a multi-rollout teacher already discovers.
Load-bearing premise
The student's local set of rollouts for a given prompt supplies teacher signals that are more informative and better aligned with verifier rewards without injecting new selection biases.
What would settle it
An experiment in which mixed success-failure conditioning produces no improvement in task accuracy or no increase in correlation between teacher scores and verifier rewards compared with single-rollout distillation.
Figures




read the original abstract
Large language models are often post-trained with sparse verifier rewards, which indicate whether a sampled trajectory succeeds but provide limited guidance about where reasoning succeeds or fails. On-policy distillation (OPD) offers denser token-level supervision by training on student-generated trajectories, yet existing methods typically distill each rollout independently and ignore the other attempts sampled for the same prompt. We introduce Multi-Rollout On-Policy Distillation (MOPD), a peer-conditioned distillation framework that uses the student's local rollout group to construct more informative teacher signals. MOPD conditions the teacher on both successful and failed peer rollouts: successes provide positive evidence for valid reasoning patterns, while failures provide structured negative evidence about plausible mistakes to avoid. We study two peer-context constructions: positive peer imitation and contrastive success-failure conditioning. Experiments on competitive programming, mathematical reasoning, scientific question answering, and tool-use benchmarks show that MOPD consistently improves over standard on-policy baselines. Further teacher-signal analysis shows that mixed success-failure contexts better align teacher scores with verifier rewards, indicating that the gains arise from more faithful, instance-adaptive supervision. These results indicate that effective on-policy distillation should exploit the student's multi-rollout trial-and-error behavior rather than treating rollouts as isolated samples.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Multi-Rollout On-Policy Distillation (MOPD), a peer-conditioned framework that constructs teacher signals by conditioning on both successful and failed rollouts sampled from the student's local rollout group for each prompt. It evaluates two constructions—positive peer imitation and contrastive success-failure conditioning—on competitive programming, mathematical reasoning, scientific question answering, and tool-use benchmarks, claiming consistent improvements over standard on-policy baselines. Teacher-signal analysis is reported to show that mixed success-failure contexts produce better alignment between teacher scores and external verifier rewards.
Significance. If the empirical gains and alignment results hold under rigorous controls, the work indicates that exploiting intra-prompt multi-rollout diversity can yield more informative, instance-adaptive supervision in on-policy distillation for LLMs trained with sparse verifier rewards, without requiring additional external data.
major comments (3)
- [Experiments] Experiments section: The central claim of 'consistent improvements' over on-policy baselines is load-bearing, yet the abstract and summary provide no quantitative deltas, ablation results (e.g., positive-only vs. contrastive), or statistical significance tests; this leaves the magnitude and reliability of the reported gains unassessable.
- [Method] Method and Analysis sections: The assumption that local rollout groups supply sufficiently independent positive/negative evidence is untested; because all trajectories are drawn from the current student policy, they are likely to share systematic errors, and no rollout-similarity metrics, diversity controls, or cross-prompt negative-example baselines are described to rule out circular reinforcement of policy biases.
- [Analysis] Teacher-signal analysis: The claim that mixed success-failure contexts 'better align teacher scores with verifier rewards' requires concrete metrics (e.g., correlation coefficients or alignment scores per construction); without these numbers or controls for rollout correlation, the interpretation that gains arise from 'more faithful' supervision remains qualitative.
minor comments (2)
- [Abstract] Abstract: Specify the number of rollouts per prompt and the precise on-policy baselines (e.g., standard OPD, PPO variants) used for comparison.
- [Method] Notation: Define the exact conditioning mechanism for contrastive success-failure (e.g., how failures are formatted as negative evidence) with a short illustrative example.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We provide point-by-point responses to the major comments below and will update the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The central claim of 'consistent improvements' over on-policy baselines is load-bearing, yet the abstract and summary provide no quantitative deltas, ablation results (e.g., positive-only vs. contrastive), or statistical significance tests; this leaves the magnitude and reliability of the reported gains unassessable.
Authors: The manuscript's experimental results section includes tables with performance numbers on all benchmarks, showing improvements over baselines and ablations for the two peer-context constructions. To make these more prominent and address the concern directly, we will add the quantitative deltas, specific ablation comparisons, and statistical significance tests (including p-values) to the abstract, introduction, and a new subsection on statistical analysis in the revised manuscript. revision: yes
-
Referee: [Method] Method and Analysis sections: The assumption that local rollout groups supply sufficiently independent positive/negative evidence is untested; because all trajectories are drawn from the current student policy, they are likely to share systematic errors, and no rollout-similarity metrics, diversity controls, or cross-prompt negative-example baselines are described to rule out circular reinforcement of policy biases.
Authors: We agree that this is an important point to verify. Although the success and failure labels provide a natural distinction, we will add experiments reporting rollout similarity metrics (e.g., average pairwise BLEU scores or embedding cosine similarities within rollout groups) and diversity statistics. We will also include a control experiment using cross-prompt negative examples to rule out bias reinforcement and demonstrate the benefit of intra-prompt peer failures. revision: yes
-
Referee: [Analysis] Teacher-signal analysis: The claim that mixed success-failure contexts 'better align teacher scores with verifier rewards' requires concrete metrics (e.g., correlation coefficients or alignment scores per construction); without these numbers or controls for rollout correlation, the interpretation that gains arise from 'more faithful' supervision remains qualitative.
Authors: We will revise the teacher-signal analysis to include concrete quantitative metrics. Specifically, we will report correlation coefficients (Pearson and Spearman) between teacher-assigned scores and verifier rewards for positive-only, failure-only, and mixed constructions. We will also add controls accounting for rollout correlations and present per-construction alignment scores to substantiate the claim with numerical evidence. revision: yes
Circularity Check
No significant circularity; empirical method with external benchmark validation
full rationale
The paper defines MOPD as a framework that constructs teacher signals from the student's own multi-rollout group for each prompt, then reports empirical gains on independent benchmarks (competitive programming, math reasoning, scientific QA, tool-use) against standard on-policy baselines. No equations, derivations, or fitted parameters are shown that reduce the claimed improvements or alignment metrics to quantities defined by the method inputs by construction. Teacher-signal analysis compares against external verifier rewards rather than self-referential quantities. No self-citations are invoked as load-bearing uniqueness theorems, and the method does not rename known results or smuggle ansatzes. The derivation chain is self-contained as an empirical proposal with measurable external outcomes.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption On-policy distillation offers denser token-level supervision than sparse verifier rewards
- domain assumption Conditioning the teacher on both successful and failed peer rollouts produces more informative signals
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.