LaME: Learning to Think in Latent Space for Multimodal Embedding via Information Bottleneck
Pith reviewed 2026-06-27 07:29 UTC · model grok-4.3
The pith
Multimodal embeddings can reason effectively in latent space using a fixed set of learnable tokens as an information bottleneck instead of explicit textual CoT.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
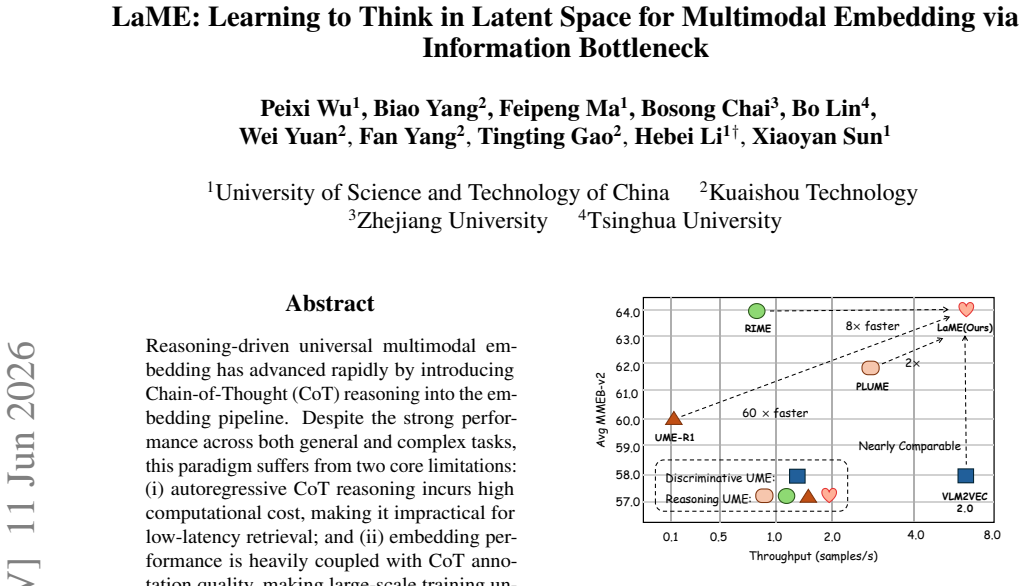
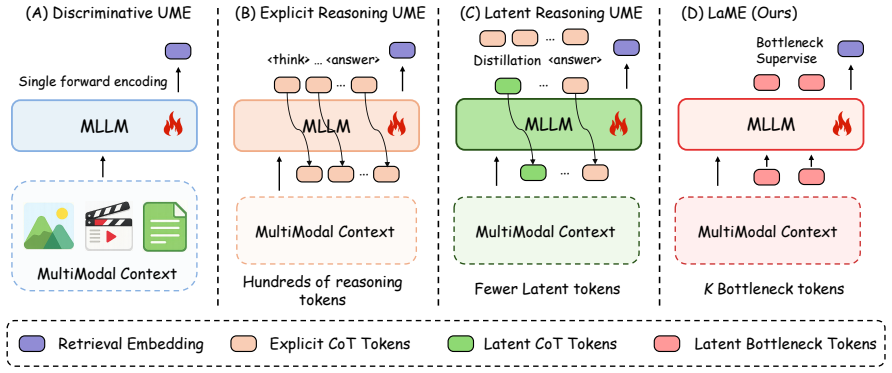
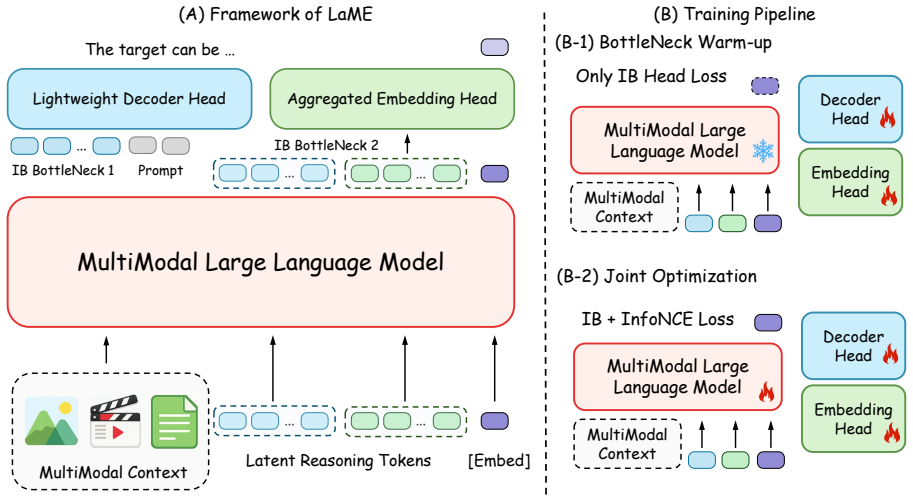
LaME formulates embedding-oriented latent reasoning as a weakly supervised information bottleneck that employs K learnable reason tokens to perform all reasoning within a single forward pass. The two weak supervision signals structurally decouple contrastive from autoregressive objectives and remove dependence on CoT annotations. A two-stage training pipeline ensures stable convergence. On MMEB-v2 and MRMR the resulting embeddings match or exceed some explicit CoT models while delivering 60x faster inference than explicit CoT methods and 2x faster than prior latent baselines, with throughput comparable to standard discriminative embedding models.
What carries the argument
K learnable reason tokens that serve as a fixed-capacity information bottleneck completing all reasoning inside one forward pass.
If this is right
- Embedding models no longer require high-quality CoT annotations for training.
- Reasoning for retrieval can finish inside a single forward pass rather than multiple autoregressive steps.
- Inference throughput becomes comparable to non-reasoning discriminative embedders while retaining reasoning capability.
- Contrastive and autoregressive losses can be optimized separately through weak supervision signals.
Where Pith is reading between the lines
- The same fixed-token bottleneck could be tested on text-only or video-only embedding tasks to check whether the latent approach transfers beyond images and text.
- Varying the token count K per task might allow a single model to allocate more capacity to harder queries without retraining the whole network.
- Because the method avoids CoT data, it opens the possibility of training on much larger unlabeled multimodal corpora that lack reasoning annotations.
Load-bearing premise
That a fixed number of learnable tokens can hold enough reasoning information to produce strong multimodal embeddings without any explicit textual chain-of-thought steps.
What would settle it
A controlled ablation showing that removing the learnable reason tokens or reducing their number to one causes accuracy on MMEB-v2 complex-reasoning tasks to fall below explicit CoT baselines while speed remains unchanged would falsify the claim that the bottleneck supplies necessary reasoning capacity.
Figures
read the original abstract
Reasoning-driven universal multimodal embedding has advanced rapidly by introducing Chain-of-Thought (CoT) reasoning into the embedding pipeline. Despite the strong performance across both general and complex tasks, this paradigm suffers from two core limitations: (i) autoregressive CoT reasoning incurs high computational cost, making it impractical for low-latency retrieval; and (ii) embedding performance is heavily coupled with CoT annotation quality, making large-scale training unreliable. These raise fundamental questions: Is textual CoT the optimal form of reasoning for embedding, and can effective embedding reasoning be accomplished in latent space? To this end, we propose LaME (Latent Reasoning Multimodal Embedding), which formulates embedding-oriented latent reasoning as a weakly supervised information bottleneck. LaME employs K learnable reason tokens as a fixed-capacity bottleneck, completing all reasoning within a single forward pass. The two weak supervision signals structurally decouple contrastive from autoregressive objectives and eliminate dependence on CoT annotations, while a two-stage training pipeline ensures stable convergence. Experiments on MMEB-v2 and MRMR show that LaME achieves competitive performance, surpassing some explicit CoT-based models, while delivering 60x faster inference than explicit CoT methods and 2x faster than latent baselines with throughput comparable to discriminative embedding models. Code will be released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LaME, which formulates embedding-oriented latent reasoning as a weakly supervised information bottleneck using K learnable reason tokens to complete reasoning in a single forward pass. It employs two weak supervision signals to structurally decouple contrastive from autoregressive objectives, eliminating dependence on CoT annotations, along with a two-stage training pipeline. Experiments on MMEB-v2 and MRMR are claimed to show competitive performance surpassing some explicit CoT-based models, with 60x faster inference than explicit CoT methods and 2x faster than latent baselines.
Significance. If the performance and speedup claims hold with proper experimental validation, the work could offer a practical alternative to explicit CoT reasoning in multimodal embeddings by reducing inference cost and annotation requirements while maintaining effectiveness for retrieval tasks.
minor comments (1)
- [Abstract] Abstract: the claim of 'competitive performance' and specific speedups (60x, 2x) cannot be evaluated without the experimental tables, dataset statistics, or ablation studies referenced in the abstract.
Simulated Author's Rebuttal
We thank the referee for their review and for accurately summarizing the contributions of LaME. We note that the report lists no specific major comments under the MAJOR COMMENTS section. Accordingly, we provide no point-by-point responses below. We remain available to supply additional experimental details or clarifications should the editor or referee request them to address the uncertainty in the recommendation.
Circularity Check
No significant circularity; derivation relies on external weak supervision and standard training pipeline.
full rationale
The abstract and available description present LaME as introducing learnable reason tokens as a fixed-capacity bottleneck, decoupled via two external weak supervision signals, and trained in two stages. No equations, self-citations, or fitted parameters are shown reducing to the target outputs by construction. The method explicitly avoids dependence on CoT annotations and does not rename known results or import uniqueness from prior self-work. Without concrete equations or load-bearing self-citations in the supplied text, the central claims remain independent of their own outputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- K
axioms (1)
- domain assumption Information bottleneck principle can formulate embedding-oriented latent reasoning under weak supervision
invented entities (1)
-
learnable reason tokens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Liu, Yikun and others , booktitle=
-
[2]
Sun, Quan and Fang, Yuxin and Wu, Ledell and Wang, Xinlong and Cao, Yue , booktitle=
-
[3]
Proceedings of the 38th International Conference on Machine Learning (ICML) , pages=
Learning Transferable Visual Models From Natural Language Supervision , author=. Proceedings of the 38th International Conference on Machine Learning (ICML) , pages=. 2021 , publisher=
2021
-
[4]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
Sigmoid Loss for Language Image Pre-Training , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
-
[5]
2025 , publisher=
Jiang, Ziyan and Meng, Rui and Yang, Xinyi and Yavuz, Semih and Zhou, Yingbo and Chen, Wenhu , booktitle=. 2025 , publisher=
2025
-
[6]
Meng, Rui and Jiang, Ziyan and Liu, Ye and Su, Mingyi and Yang, Xinyi and Fu, Yuepeng and Qin, Can and Chen, Zeyuan and Xu, Ran and Xiong, Caiming and Zhou, Yingbo and Chen, Wenhu and Yavuz, Semih , journal=
-
[7]
Jiang, Ting and Song, Minghui and Zhang, Zihan and Huang, Haizhen and Deng, Weiwei and Sun, Feng and Zhang, Qi and Wang, Deqing and Zhuang, Fuzhen , journal=
-
[8]
Lan, Zhibin and Niu, Liqiang and Meng, Fandong and Zhou, Jie and Su, Jinsong , journal=
-
[9]
Breaking the Modality Barrier: Universal Embedding Learning with Multimodal
Gu, Tiancheng and Yang, Kaicheng and Feng, Ziyong and Wang, Xingjun and Zhang, Yanzhao and Long, Dingkun and Chen, Yingda and Cai, Weidong and Deng, Jiankang , booktitle=. Breaking the Modality Barrier: Universal Embedding Learning with Multimodal. 2025 , address=
2025
-
[10]
2023 , publisher=
Li, Junnan and Li, Dongxu and Savarese, Silviano and Hoi, Steven , booktitle=. 2023 , publisher=
2023
-
[11]
Lin, Sheng-Chieh and Mei, Chankyu and Oguz, Barlas and Xiong, Chenyan and Yih, Wen-tau and Xia, Xilun , journal=
-
[12]
2025 , publisher=
Lee, Chankyu and Roy, Rajarshi and Xu, Menber and Raiman, Jonathan and Shoeybi, Mohammad and Catanzaro, Bryan and Han, Wei , booktitle=. 2025 , publisher=
2025
-
[13]
BehnamGhader, Parishad and Adlakha, Vaibhav and Mosbach, Marius and Baez, Dzmitry and Srivastava, Maximilian and Reddy, Siva , journal=
-
[14]
arXiv preprint arXiv:2510.05014 , year=
Think Then Embed: Generative Context Improves Multimodal Embedding , author=. arXiv preprint arXiv:2510.05014 , year=
-
[15]
He, Haoxiang and Zhao, Haoxiang and others , journal=
-
[16]
Wang, Peng and Bai, Shuai and Tan, Sinan and Wang, Shijie and Fan, Zhihao and Bai, Jinze and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Fan, Yang and Dang, Kai and Du, Mengfei and Ren, Xuancheng and Men, Rui and Liu, Dayiheng and Chang, Cheng and Yu, Jingren and Lin, Junyang , journal=
-
[17]
How Far Are We to
Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others , journal=. How Far Are We to
-
[18]
2024 , url=
Liu, Haotian and Li, Chunyuan and Li, Yuheng and Li, Bo and Zhang, Yuanhan and Shen, Sheng and Lee, Yong Jae , month=. 2024 , url=
2024
-
[19]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Zhang, Ruoyu and Xu, Runxin and Zhu, Qihao and Ma, Shirong and Wang, Peiyi and Bi, Xiao and others , journal=
-
[20]
arXiv preprint arXiv:2411.04282 , year=
Language Models are Hidden Reasoners: Unlocking Latent Reasoning Capabilities via Self-Rewarding , author=. arXiv preprint arXiv:2411.04282 , year=
-
[21]
Li, Zehan and Zhang, Xin and Zhang, Yanzhao and Long, Dingkun and Xie, Pengjun and Zhang, Meishan , journal=
-
[22]
arXiv preprint arXiv:2401.00368 , year=
Improving Text Embeddings with Large Language Models , author=. arXiv preprint arXiv:2401.00368 , year=
-
[23]
Zhang, Xin and Li, Zehan and Zhang, Yanzhao and Long, Dingkun and Xie, Pengjun and Zhang, Meishan , journal=
-
[24]
Gu, Tiancheng and Yang, Kaicheng and others , journal=
-
[25]
Xiao, Zilin and Ma, Qi and Gu, Mengting and Chen, Chun-cheng Jason and Chen, Xintao and Ordonez, Vicente and Mohan, Vijai , journal=
-
[26]
Reasoning Guided Embeddings: Leveraging
Liu, Yifan and Yang, Xinyi and others , journal=. Reasoning Guided Embeddings: Leveraging
-
[27]
Jiang, Haonan and Wang, Yuji and Zhu, Yongjie and Lu, Xin and Qin, Wenyu and Wang, Meng and Wan, Pengfei and Tang, Yansong , journal=
-
[28]
The Thirteenth International Conference on Learning Representations (ICLR) , year=
Training Large Language Models to Reason in a Continuous Latent Space , author=. The Thirteenth International Conference on Learning Representations (ICLR) , year=
-
[29]
The Twelfth International Conference on Learning Representations (ICLR) , year=
Think before you speak: Training Language Models With Pause Tokens , author=. The Twelfth International Conference on Learning Representations (ICLR) , year=
-
[30]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[31]
Ma, Xinyin and Jiang, Guangnian and Gong, Yifei and Hu, Zhiyuan , journal=
-
[32]
Explicit
Deng, Yuntian and Choi, Yejin and Bowman, Samuel , journal=. Explicit
-
[33]
Think Silently, Think Fast: Dynamic Latent Compression of
Lu, Jinghui and others , booktitle=. Think Silently, Think Fast: Dynamic Latent Compression of
-
[34]
Shen, Zhenyi and Yan, others , booktitle=
-
[35]
Xing, Heming and others , booktitle=
-
[36]
Xu, Yige and Guo, Xu and Zeng, Zhiwei and Miao, Chunyan , booktitle=
-
[37]
arXiv preprint arXiv:2602.10229 , year=
Latent Thoughts Tuning: Bridging Context and Reasoning with Fused Information in Latent Tokens , author=. arXiv preprint arXiv:2602.10229 , year=
-
[38]
Jin, Jiajie and Zhang, Yanzhao and Li, Mingxin and Long, Dingkun and Xie, Pengjun and Zhu, Yutao and Dou, Zhicheng , journal=
-
[39]
Zhang, Yifei and others , journal=
-
[40]
Zhang, Jintian and Chen, Yulin and Wang, Ningyu and Zhang, Huajun , journal=
-
[41]
arXiv preprint arXiv:2507.06203 , year=
A Survey on Latent Reasoning , author=. arXiv preprint arXiv:2507.06203 , year=
-
[42]
arXiv preprint arXiv:2604.22280 , year=
Beyond Chain-of-Thought: Rewrite as a Universal Interface for Multimodal Embedding , author=. arXiv preprint arXiv:2604.22280 , year=
-
[43]
Liu, Yifan and Liang, Feng and others , journal=
-
[44]
Jian, Wenhao and Zhang, Fan and others , journal=
-
[45]
arXiv preprint physics/0004057 , year=
The Information Bottleneck Method , author=. arXiv preprint physics/0004057 , year=
-
[46]
Proceedings of the 5th International Conference on Learning Representations (ICLR) , year=
Deep Variational Information Bottleneck , author=. Proceedings of the 5th International Conference on Learning Representations (ICLR) , year=
-
[47]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Representation Learning with Contrastive Predictive Coding , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[48]
Proceedings of the 7th International Conference on Learning Representations (ICLR) , year=
Learning Deep Representations by Mutual Information Estimation and Maximization , author=. Proceedings of the 7th International Conference on Learning Representations (ICLR) , year=
-
[49]
Proceedings of the 42nd International Conference on Machine Learning (ICML) , year=
Learning Optimal Multimodal Information Bottleneck Representations , author=. Proceedings of the 42nd International Conference on Machine Learning (ICML) , year=
-
[50]
The Thirteenth International Conference on Learning Representations (ICLR) , year=
Projection Head is Secretly an Information Bottleneck , author=. The Thirteenth International Conference on Learning Representations (ICLR) , year=
-
[51]
, author=
Contrastive Learning via Variational Information Bottleneck. , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
-
[52]
Ji, Yingrui and others , booktitle=
-
[53]
Proceedings of the 42nd International Conference on Machine Learning (ICML) , year=
Aligning Multimodal Representations through an Information Bottleneck , author=. Proceedings of the 42nd International Conference on Machine Learning (ICML) , year=
-
[54]
arXiv preprint arXiv:2604.11095 , year=
Bottleneck Tokens for Unified Multimodal Retrieval , author=. arXiv preprint arXiv:2604.11095 , year=
-
[55]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Matryoshka Representation Learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[56]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[57]
Rajbhandari, Samyam and Rasley, Jeff and Rber, Olatunji and He, Yuxiong , booktitle=
-
[58]
Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL) , year=
Direct Preference Optimization of Video Large Multimodal Models from Language Model Reward , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL) , year=
2025
-
[59]
2025 , publisher=
Faysse, Manuel and Sibille, Hugues and Monet, Tony and Music, Elia and Music, Martin and Musik, Benjamin and Musik, Lucas , booktitle=. 2025 , publisher=
2025
-
[60]
2025 , publisher=
Yu, Shi and Tang, Chaoyue and Xu, Bokai and Cui, Junbo and Ran, Junhao and Yan, Yukun and Liu, Zhenghao and Wang, Shuo and Han, Xu and Liu, Zhiyuan and Sun, Maosong , booktitle=. 2025 , publisher=
2025
-
[61]
Zhang, Siyue and Gao, Yuan and Zhou, Xiao and Zhao, Yilun and Song, Tingyu and Cohan, Arman and Luu, Anh Tuan and Zhao, Chen , journal=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.