LearniBridge: Learnable Calibration of Feature Caching for Diffusion Models Acceleration
Pith reviewed 2026-06-26 05:07 UTC · model grok-4.3
The pith
The optimal calibration update for feature caching in diffusion models lives in a shared low-rank subspace across prompts that lightweight LoRA can learn from 3-5 samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
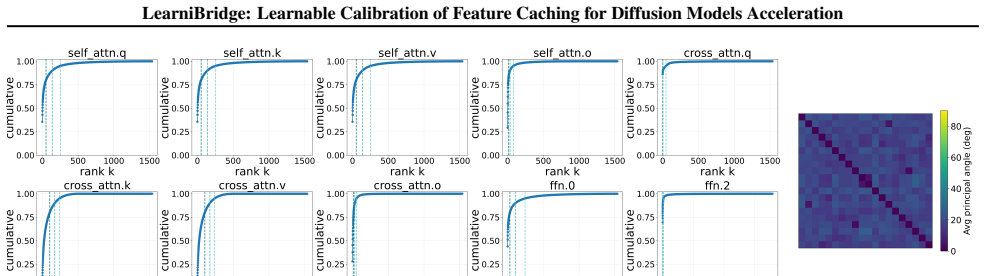
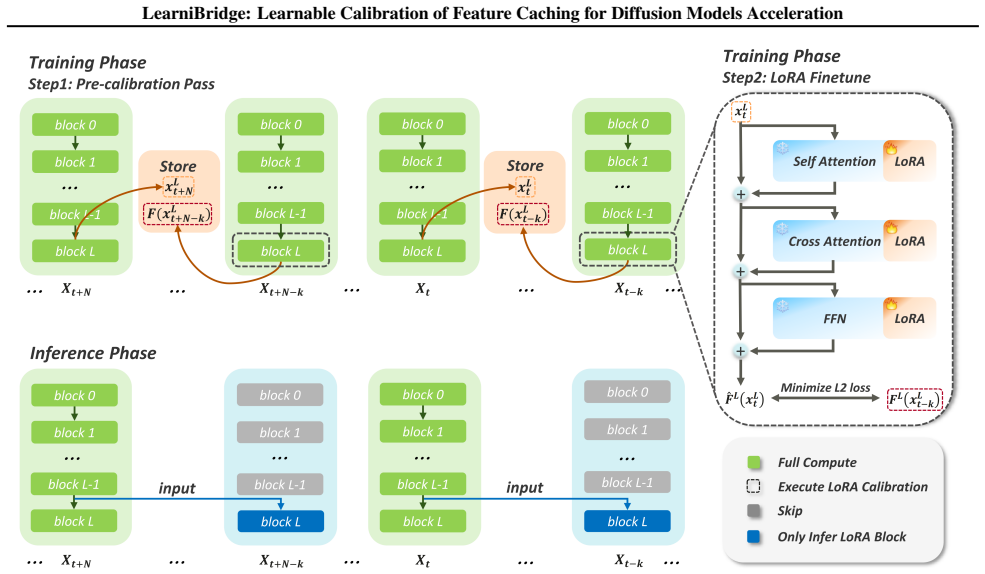
We demonstrate that the optimal calibration update is characterized by a shared low-rank subspace across diverse prompts. Guided by this structural insight, we propose LearniBridge, a learnable calibration mechanism for feature caching that bridges multiple timesteps through lightweight LoRA updates. This mechanism enables effective calibration requiring only 3-5 training samples.
What carries the argument
Shared low-rank subspace of the optimal calibration update, captured by lightweight LoRA adapters that learn a prompt-independent correction for cached features.
If this is right
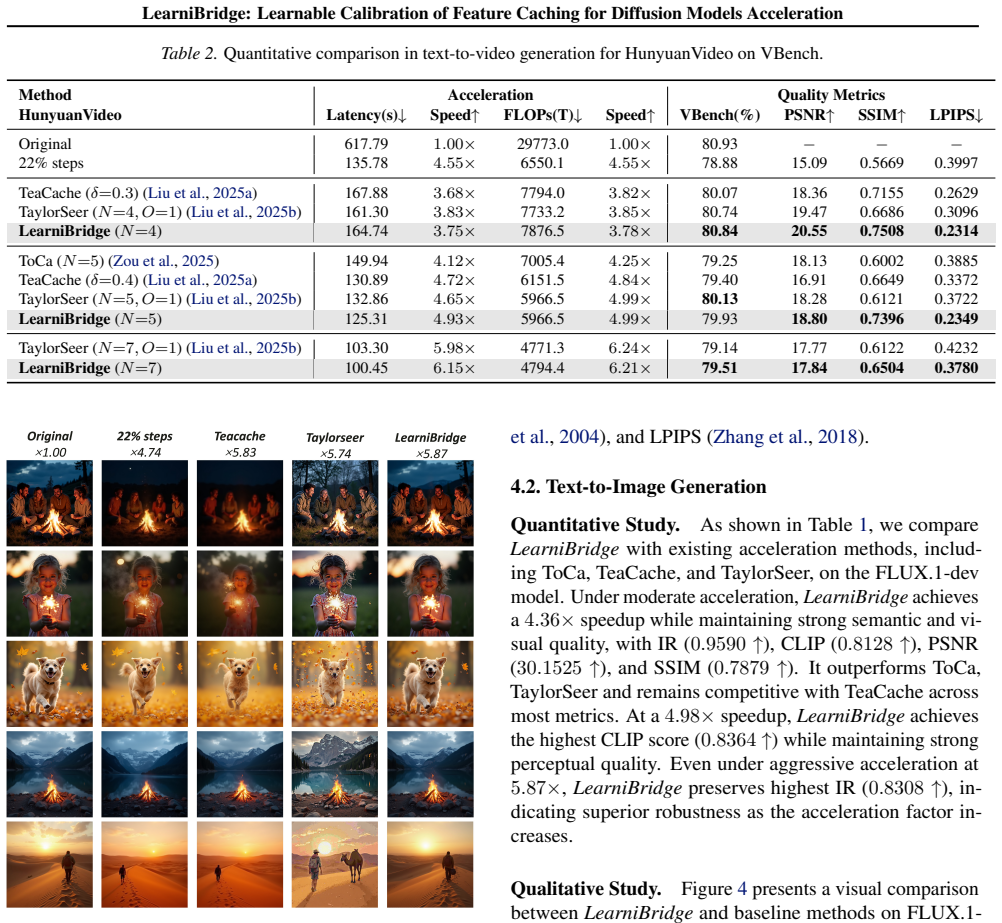
- FLUX inference reaches up to 5.87 times acceleration.
- HunyuanVideo reaches up to 5.75 times acceleration.
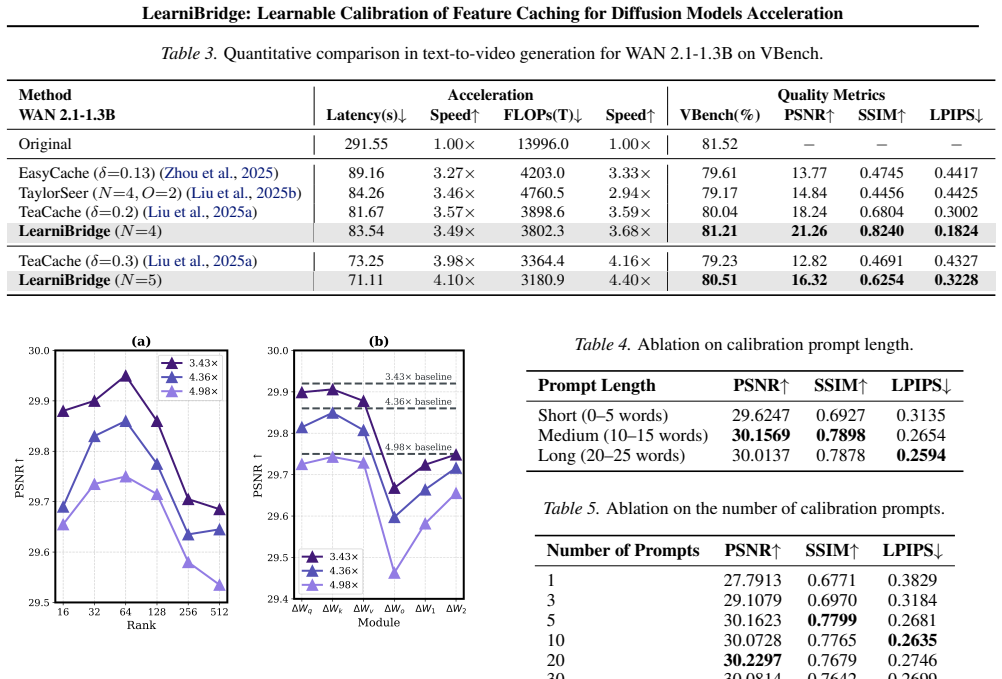
- WAN2.1 reaches 4.10 times acceleration while raising the VBench score 1.28 percent above the prior best method at that speed.
- Calibration remains effective when the training set is limited to 3-5 samples and does not require prompt-specific retraining.
Where Pith is reading between the lines
- The same low-rank correction pattern may appear in caching schemes for other iterative generative models if their step-wise errors share comparable structure.
- If the subspace property holds across architectures, the method could be applied to reduce compute in related transformer-based samplers without new per-model redesign.
- A direct test would be to measure how much the learned adapters degrade when transferred to models trained on substantially different data distributions.
Load-bearing premise
The optimal calibration update for feature caching resides in a single low-rank subspace that stays consistent across different prompts and can be recovered by LoRA training on only 3-5 samples.
What would settle it
Train the LoRA on 3-5 samples from a given set of prompts, then measure whether error accumulation returns or quality drops when the same adapter is used at the claimed acceleration ratios on a disjoint set of prompts or on a different model family.
Figures


read the original abstract
Diffusion Transformers (DiTs) have driven substantial progress in image and video generation but suffer from prohibitive computational costs. Feature caching accelerates inference by reusing intermediate representations. Existing methods rely on historical features for implementation simplicity, yet suffer from severe error accumulation at high acceleration ratios. To address this limitation, we investigate the nature of the requisite feature correction. We demonstrate that the optimal calibration update is characterized by a shared low-rank subspace across diverse prompts. Guided by this structural insight, we propose LearniBridge, a learnable calibration mechanism for feature caching that bridges multiple timesteps through lightweight LoRA updates. This mechanism enables effective calibration requiring only 3-5 training samples. Extensive experiments on image and video generation show that LearniBridge achieves up to $5.87\times$, $5.75\times$, and $4.10\times$ acceleration on FLUX, HunyuanVideo, and WAN2.1, respectively. On WAN2.1, it improves VBench by 1.28% over the previous SOTA at $4.10\times$ acceleration. Our code is available at https://github.com/Iiiiiiirene/LearniBridge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the optimal feature correction needed for accurate feature caching in Diffusion Transformers resides in a shared low-rank subspace across diverse prompts. Guided by this observation, it introduces LearniBridge, a calibration method that applies lightweight LoRA updates (trained on only 3-5 samples) to bridge timesteps in cached features. This yields reported speedups of 5.87× on FLUX, 5.75× on HunyuanVideo, and 4.10× on WAN2.1, together with a 1.28% VBench gain over prior SOTA on WAN2.1 at the highest acceleration.
Significance. If the shared low-rank subspace property is stable across prompts, timesteps, and model families, and if the few-shot LoRA mechanism reliably captures it, the work would supply a practical, low-data route to high-ratio acceleration of DiT-based image and video generation while preserving or improving perceptual quality. The public code release would further strengthen its utility.
major comments (2)
- [Abstract (structural insight paragraph)] The load-bearing claim that optimal calibration updates occupy a shared low-rank subspace across prompts (enabling 3-5 sample LoRA generalization) is stated without quantitative support such as subspace-overlap metrics, cosine similarity of principal directions, or PCA rank analysis on held-out prompts. This directly affects whether the reported acceleration ratios and VBench gains can be expected to hold for arbitrary inputs rather than reducing to prompt-specific tuning.
- [Experiments section (implied by abstract claims)] The experimental results (acceleration factors and VBench deltas) are presented without error bars, ablation tables on training-sample count, or controls that isolate the contribution of the low-rank LoRA versus simpler caching baselines. This makes it impossible to assess whether the central empirical claims are robust.
minor comments (1)
- Clarify whether the LoRA rank and training hyperparameters are held constant across the three evaluated models or tuned per model; this affects reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying the evidence in the manuscript and outlining planned revisions to strengthen the quantitative support and experimental robustness.
read point-by-point responses
-
Referee: [Abstract (structural insight paragraph)] The load-bearing claim that optimal calibration updates occupy a shared low-rank subspace across prompts (enabling 3-5 sample LoRA generalization) is stated without quantitative support such as subspace-overlap metrics, cosine similarity of principal directions, or PCA rank analysis on held-out prompts. This directly affects whether the reported acceleration ratios and VBench gains can be expected to hold for arbitrary inputs rather than reducing to prompt-specific tuning.
Authors: The manuscript demonstrates the shared low-rank subspace property via the consistent effectiveness of 3-5 sample LoRA calibration across diverse prompts in image and video DiTs, as evidenced by the reported acceleration and quality metrics. However, we agree that explicit quantitative metrics such as subspace overlap or PCA analysis on held-out prompts are not included. In revision we will add these analyses, including cosine similarities of principal directions across prompt sets and rank analysis, to directly support the generalization claim. revision: yes
-
Referee: [Experiments section (implied by abstract claims)] The experimental results (acceleration factors and VBench deltas) are presented without error bars, ablation tables on training-sample count, or controls that isolate the contribution of the low-rank LoRA versus simpler caching baselines. This makes it impossible to assess whether the central empirical claims are robust.
Authors: We agree that error bars, ablations on training sample count, and explicit controls isolating LoRA from simpler baselines would improve assessment of robustness. The current results include comparisons against prior caching methods, but we will add error bars from repeated runs, an ablation table varying sample counts, and controls contrasting LoRA updates against non-learnable caching in the revised manuscript. revision: yes
Circularity Check
No circularity detected; empirical method with observed structural property
full rationale
The paper presents LearniBridge as an empirical method guided by an observed structural property (shared low-rank subspace of optimal calibration updates across prompts), demonstrated via experiments on FLUX, HunyuanVideo, and WAN2.1 with reported speedups and VBench gains. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that reduce the central claim to its own inputs by construction. The load-bearing premise is an empirical discovery rather than a mathematical reduction, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2503.06923 , year=
From reusing to forecasting: Accelerating diffusion models with taylorseers , author=. arXiv preprint arXiv:2503.06923 , year=
-
[2]
The Thirteenth International Conference on Learning Representations , year=
Accelerating Diffusion Transformers with Token-wise Feature Caching , author=. The Thirteenth International Conference on Learning Representations , year=
-
[3]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Timestep Embedding Tells: It's Time to Cache for Video Diffusion Model , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[4]
arXiv preprint arXiv:2507.02860 , year=
Less is Enough: Training-Free Video Diffusion Acceleration via Runtime-Adaptive Caching , author=. arXiv preprint arXiv:2507.02860 , year=
-
[5]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[6]
Advances in neural information processing systems , volume=
Diffusion models beat gans on image synthesis , author=. Advances in neural information processing systems , volume=
-
[7]
arXiv preprint arXiv:2311.15127 , year=
Stable video diffusion: Scaling latent video diffusion models to large datasets , author=. arXiv preprint arXiv:2311.15127 , year=
-
[8]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[9]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Scalable diffusion models with transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[10]
Advances in neural information processing systems , volume=
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps , author=. Advances in neural information processing systems , volume=
-
[11]
2025 , url=
Muyang Li and Yujun Lin and Zhekai Zhang and Tianle Cai and Junxian Guo and Xiuyu Li and Enze Xie and Chenlin Meng and Jun-Yan Zhu and Song Han , booktitle=. 2025 , url=
2025
-
[12]
The Thirteenth International Conference on Learning Representations , year=
Real-Time Video Generation with Pyramid Attention Broadcast , author=. The Thirteenth International Conference on Learning Representations , year=
-
[13]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Deepcache: Accelerating diffusion models for free , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[14]
Advances in Neural Information Processing Systems , volume=
Ditfastattn: Attention compression for diffusion transformer models , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Forty-first international conference on machine learning , year=
Scaling rectified flow transformers for high-resolution image synthesis , author=. Forty-first international conference on machine learning , year=
-
[16]
The Twelfth International Conference on Learning Representations , year=
PixArt- : Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis , author=. The Twelfth International Conference on Learning Representations , year=
-
[17]
arXiv preprint arXiv:2407.01425 , year=
Fora: Fast-forward caching in diffusion transformer acceleration , author=. arXiv preprint arXiv:2407.01425 , year=
-
[18]
arXiv preprint arXiv:2503.20314 , year=
Wan: Open and advanced large-scale video generative models , author=. arXiv preprint arXiv:2503.20314 , year=
-
[19]
arXiv preprint arXiv:2412.03603 , year=
Hunyuanvideo: A systematic framework for large video generative models , author=. arXiv preprint arXiv:2412.03603 , year=
-
[20]
2024 , howpublished =
FLUX , author =. 2024 , howpublished =
2024
-
[21]
Advances in neural information processing systems , volume=
Photorealistic text-to-image diffusion models with deep language understanding , author=. Advances in neural information processing systems , volume=
-
[22]
Advances in Neural Information Processing Systems , volume=
Imagereward: Learning and evaluating human preferences for text-to-image generation , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
Clipscore: A reference-free evaluation metric for image captioning , author=. Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
2021
-
[24]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Vbench: Comprehensive benchmark suite for video generative models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[25]
IEEE transactions on image processing , volume=
Image quality assessment: from error visibility to structural similarity , author=. IEEE transactions on image processing , volume=. 2004 , publisher=
2004
-
[26]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
The unreasonable effectiveness of deep features as a perceptual metric , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[27]
International Conference on Learning Representations , year=
Denoising Diffusion Implicit Models , author=. International Conference on Learning Representations , year=
-
[28]
International Conference on Machine Learning , pages=
Consistency Models , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[29]
Progressive Distillation for Fast Sampling of Diffusion Models , author=
-
[30]
2023 , eprint=
On Distillation of Guided Diffusion Models , author=. 2023 , eprint=
2023
-
[31]
Structural Pruning for Diffusion Models , volume =
Fang, Gongfan and Ma, Xinyin and Wang, Xinchao , booktitle =. Structural Pruning for Diffusion Models , volume =
-
[32]
Advances in Neural Information Processing Systems , volume=
Dip-go: A diffusion pruner via few-step gradient optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
2025 IEEE International Symposium on High Performance Computer Architecture (HPCA) , pages=
Ditto: Accelerating Diffusion Model via Temporal Value Similarity , author=. 2025 IEEE International Symposium on High Performance Computer Architecture (HPCA) , pages=. 2025 , organization=
2025
-
[34]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Q-diffusion: Quantizing diffusion models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[35]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Post-training quantization on diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[36]
International conference on machine learning , pages=
Deep unsupervised learning using nonequilibrium thermodynamics , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[37]
International Conference on Medical image computing and computer-assisted intervention , pages=
U-net: Convolutional networks for biomedical image segmentation , author=. International Conference on Medical image computing and computer-assisted intervention , pages=. 2015 , organization=
2015
-
[38]
European Conference on Computer Vision , pages=
Pixart- : Weak-to-strong training of diffusion transformer for 4k text-to-image generation , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[39]
2025 , eprint=
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer , author=. 2025 , eprint=
2025
-
[40]
arXiv preprint arXiv:2412.20404 , year=
Open-sora: Democratizing efficient video production for all , author=. arXiv preprint arXiv:2412.20404 , year=
-
[41]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.