The Dynamics of Human and AI-Generated Language: How Semantics Fluctuates across Different Timescales
Pith reviewed 2026-06-27 13:25 UTC · model grok-4.3
The pith
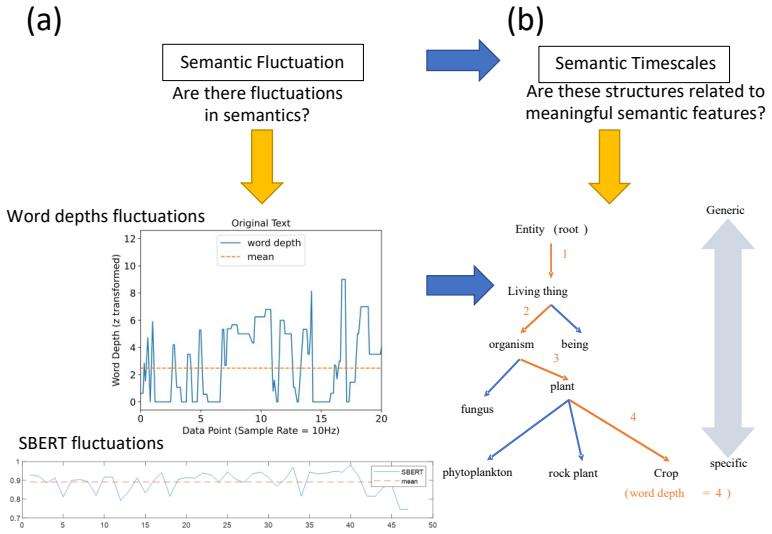
Autocorrelation on semantic time series shows generic vocabulary persists over longer timescales than specific words in both human and AI speech.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
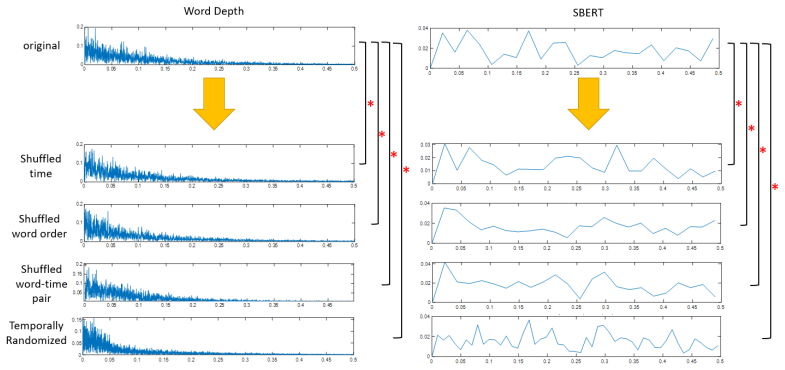
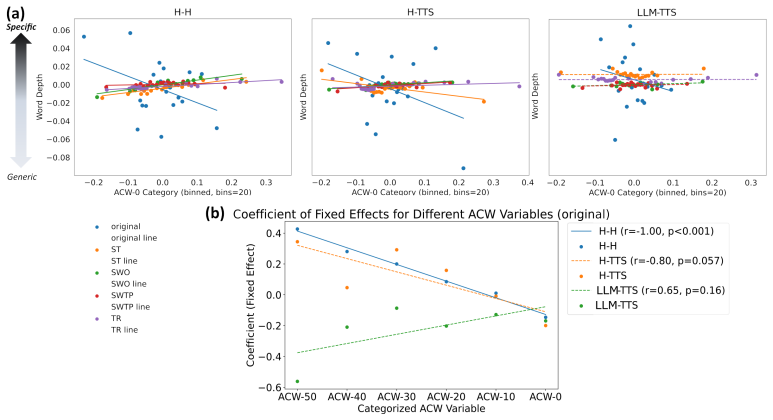
The central discovery is that segments with longer ACW-0 in the semantic time-series tend to contain more generic vocabulary, whereas segments with shorter ACW-0 are enriched in more specific words, and these associations are strongly attenuated when word order and timing are randomized.
What carries the argument
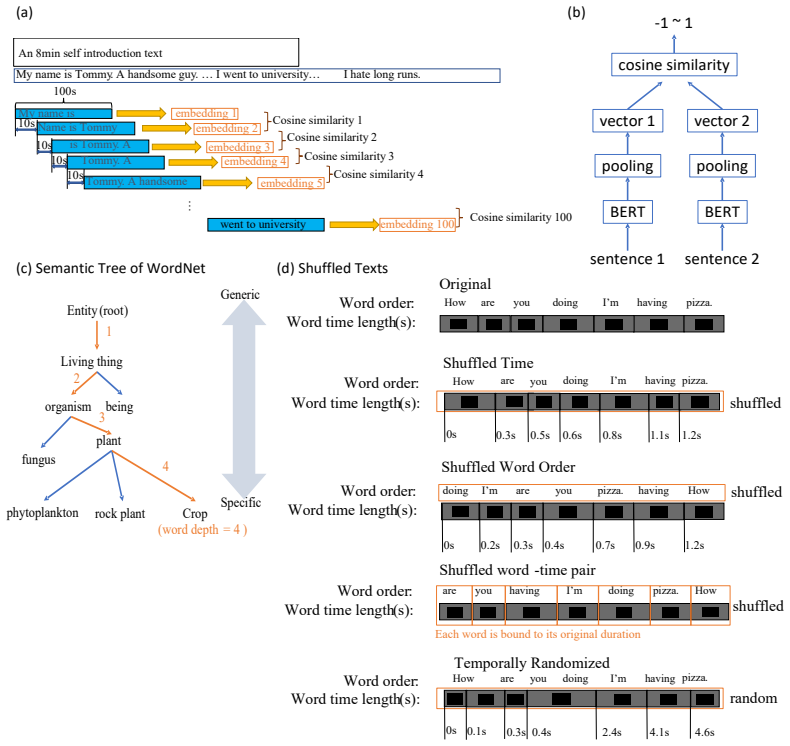
The autocorrelation-window measure ACW-0 computed on time series derived from WordNet word depth for specificity and SBERT embeddings for contextual similarity.
If this is right
- ACW-based features can be used to analyze and compare the temporal structure of human and AI-generated speech.
- The associations between ACW-0 and vocabulary specificity depend on the original sequential organization of the narrative.
- Shuffled controls confirm that the measures go beyond static lexical distributions.
- The pipeline works across human-read narratives, TTS readings, and LLM-generated texts.
Where Pith is reading between the lines
- If the measures generalize, they could help identify when AI language fails to replicate human-like semantic pacing.
- Applying the same pipeline to written text or other languages might reveal whether the pattern is modality-specific.
- Testing with different embedding models could show how robust the temporal organization signal is to the choice of semantic representation.
Load-bearing premise
That measures of word depth from WordNet and similarity from SBERT embeddings produce time series whose autocorrelation genuinely reflects the temporal organization of semantic content rather than artifacts of those resources.
What would settle it
Observing the same association between ACW-0 length and generic versus specific words even after randomizing word order and timing would falsify the claim that the measures capture non-trivial temporal organization.
Figures
read the original abstract
Spoken language, whether produced by humans or large language models (LLM), unfolds over time with varying semantic content. However, we still lack simple, interpretable time-series features that capture how generic versus specific content is distributed over time, and that can be used to compare human and AI-generated speech. We introduce a semantic-timescale analysis pipeline that turns word-level transcripts with timestamps into semantic time-series. For each spoken narrative, we compute (i) semantic specificity using WordNet-based word depth and (ii) contextual similarity using SBERT embeddings and quantify their temporal dependence using autocorrelation-window measures (ACW-0 and related metrics). We then compare original speech to multiple shuffled controls that selectively disrupt lexical identity, temporal order, and word duration. Across human-read autobiographical narratives, TTS readings, and LLM-generated texts rendered with TTS, we find that segments with longer ACW-0 in the semantic time-series tend to contain more generic vocabulary, whereas segments with shorter ACW-0 are enriched in more specific words. These associations are strongly attenuated or abolished when word order and timing are randomized, indicating that ACW-based measures capture non-trivial temporal organization of semantic content beyond static lexical distributions. Our results suggest that ACW-based semantic timescales are a useful family of features for analyzing and comparing the temporal structure of human and AI-generated speech.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a semantic-timescale analysis pipeline that transforms word-level transcripts with timestamps into semantic time-series using WordNet-based word depth for semantic specificity and SBERT embeddings for contextual similarity. It quantifies temporal dependence via autocorrelation-window measures (ACW-0 and related metrics) and compares original human autobiographical narratives, TTS readings, and LLM-generated texts against shuffled controls that disrupt lexical identity, temporal order, and word duration. The central finding is that segments with longer ACW-0 tend to contain more generic vocabulary while shorter ACW-0 segments are enriched in specific words; these associations are strongly attenuated or abolished under randomization of word order and timing, indicating that the measures capture non-trivial temporal semantic organization beyond static lexical distributions.
Significance. If the results hold after detailed verification, the work supplies an interpretable family of time-series features for comparing the temporal structure of human and AI-generated language. The explicit randomization controls that preserve lexical items while disrupting order and timing constitute a clear methodological strength, directly testing against static distributional artifacts and supporting the claim of genuine temporal organization. This approach could enable falsifiable comparisons across language sources and timescales.
major comments (2)
- [Abstract] Abstract: The abstract describes the pipeline, controls, and directional findings but provides no implementation details, statistical tests, sample sizes, or verification that the controls fully isolate temporal effects. This absence prevents evaluation of the robustness of the reported ACW-0 associations with vocabulary specificity.
- [Methods] Methods (implied from pipeline description): The construction of semantic time-series from WordNet depth and SBERT embeddings is presented at a high level without explicit formulas for ACW-0 computation or discussion of how segment boundaries are defined; these choices are load-bearing for the central claim that longer ACW-0 segments contain more generic vocabulary.
minor comments (1)
- [Abstract] The abstract and title use 'ACW-0' without a brief parenthetical definition on first use; adding one would improve accessibility for readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for the constructive review and positive assessment of the work's potential. We address the two major comments below and have revised the manuscript accordingly to increase transparency.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract describes the pipeline, controls, and directional findings but provides no implementation details, statistical tests, sample sizes, or verification that the controls fully isolate temporal effects. This absence prevents evaluation of the robustness of the reported ACW-0 associations with vocabulary specificity.
Authors: We agree the original abstract was concise and omitted quantitative details. We have revised it to report sample sizes, the primary statistical tests and effect sizes for the ACW-0–specificity associations, and a statement that the randomization controls abolish the pattern (as verified in the results). Implementation details remain in the Methods, now cross-referenced in the abstract. revision: yes
-
Referee: [Methods] Methods (implied from pipeline description): The construction of semantic time-series from WordNet depth and SBERT embeddings is presented at a high level without explicit formulas for ACW-0 computation or discussion of how segment boundaries are defined; these choices are load-bearing for the central claim that longer ACW-0 segments contain more generic vocabulary.
Authors: We accept that explicit formulas and segment-boundary definitions were insufficiently detailed. The revised Methods section now supplies the autocorrelation function, the precise definition of ACW-0 (first lag below threshold), and the procedure for delineating segments. We also added a paragraph explaining why these choices allow the observed link between ACW length and lexical specificity to be attributed to temporal organization rather than static distributions. revision: yes
Circularity Check
No significant circularity
full rationale
The pipeline constructs semantic time-series from external resources (WordNet depths, SBERT embeddings) and applies autocorrelation measures, then tests associations against multiple shuffled controls that preserve lexical items while disrupting order and timing. The reported attenuation under randomization directly falsifies the possibility that results reduce to static properties of the lexical resources. No load-bearing step equates a derived quantity to its own inputs by definition, no self-citation chain justifies a uniqueness claim, and no fitted parameter is relabeled as a prediction. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption WordNet provides a valid hierarchy for measuring semantic specificity via word depth.
- domain assumption SBERT embeddings capture contextual similarity in a manner suitable for autocorrelation analysis.
- domain assumption Autocorrelation-window measures (ACW-0) quantify non-trivial temporal dependence in semantic time-series.
Reference graph
Works this paper leans on
-
[1]
Çatal, Y., Keskin, K., Wolman, A., Klar, P., Smith, D., & Northoff, G. (2024). Flexibility of intrinsic neural timescales during distinct behav- ioral states.Communications Biology, 7(1), 1–17. https://doi.org/10 .1038/s42003-024-07349-1
2024
-
[2]
A., Lei, M., Thai, V., Kerns, S
Henzler-Wildman, K. A., Lei, M., Thai, V., Kerns, S. J., Karplus, M., & Kern, D. (2007). A hierarchy of timescales in protein dynamics is linked to enzyme catalysis.Nature, 450(7171), 913–916. https: //doi.org/10.1038/nature06407
-
[3]
Regev, T.I., Casto, C., Hosseini, E.A. et al. (2024). Neural populations in the language network differ in the size of their temporal receptive windows.Nat Hum Behav. https://doi.org/10.1038/s41562-024-01944 -2
-
[4]
Scheffer, M., & Carpenter, S. R. (2003). Catastrophic regime shifts in ecosystems: Linking theory to observation.Trends in Ecology & Evolution, 18(12), 648–656. https://doi.org/10.1016/j.tree.2003.09.002
-
[5]
Wolff A, Berberian N, Golesorkhi M, Gomez-Pilar J, Zilio F, Northoff G. (2022). Intrinsic neural timescales: temporal inte- gration and segregation.Trends Cogn Sci, 26(2), 159-173. doi: 10.1016/j.tics.2021.11.007
-
[6]
Hasson, U., Yang, E., Vallines, I., Heeger, D. J., & Rubin, N. (2008). A hierarchy of temporal receptive windows in human cortex.The Journal of neuroscience : the official journal of the Society for Neuroscience, 28(10), 2539–2550. https://doi.org/10.1523/JNEUROSCI.5487-07.20 08
-
[7]
Lerner, Y., Honey, C. J., Silbert, L. J., & Hasson, U. (2011). Topo- graphic mapping of a hierarchy of temporal receptive windows using a narrated story.Journal of Neuroscience, 31(8), 2906-2915. https: //doi.org/10.1523/JNEUROSCI.3684-10.2011. 32
-
[8]
Himberger, K. D., Chien, H.-Y., & Honey, C. J. (2018). Principles of Temporal Processing Across the Cortical Hierarchy.Neuroscience, 389, 161–174. https://doi.org/10.1016/j.neuroscience.2018.04.030
-
[9]
J., Thesen, T., Donner, T
Honey, C. J., Thesen, T., Donner, T. H., Silbert, L. J., Carlson, C. E., Devinsky, O., Doyle, W. K., Rubin, N., Heeger, D. J., & Hasson, U. (2012). Slow cortical dynamics and the accumulation of information over long timescales.Neuron, 76(2), 423–434. https://doi.org/10.101 6/j.neuron.2012.08.011
2012
-
[10]
Levelt, W. J. M. (1989).Speaking: From intention to articulation. MIT Press
1989
-
[11]
Levelt, W. J. M., Roelofs, A., & Meyer, A. S. (1999). A theory of lexical access in speech production.Behavioral and Brain Sciences, 22(1), 1–38. https://doi.org/10.1017/S0140525X99001776
-
[12]
Levelt, W.J.M. (2001). Spoken word production: A theory of lexical access.Proc. Natl. Acad. Sci. U.S.A. 98(23), 13464-13471. https: //doi.org/10.1073/pnas.231459498
-
[13]
Verwoert, M., Amigó-Vega, J., Gao, Y. et al. (2025). Whole-brain dynamics of articulatory, acoustic and semantic speech representations. Commun Biol, 8, 432. https://doi.org/10.1038/s42003-025-07862-x
-
[14]
Thetemporal structure of parent talk to toddlers about objects.Cognition, 230, 105266
Slone, L.K., Abney, D.H., Smith, L.B., &Yu, C.(2023). Thetemporal structure of parent talk to toddlers about objects.Cognition, 230, 105266. https://doi.org/10.1016/j.cognition.2022.105266
-
[15]
Sandler, M., Choung, H., Ross, A., & David, P. (2025). A Linguistic Comparison Between Human and ChatGPT-Generated Conversations. In C. Wallraven, C.-L. Liu, & A. Ross (Eds.),Pattern Recognition and Artificial Intelligence(pp. 366–380). Springer Nature. https://doi.or g/10.1007/978-981-97-8702-9_25
-
[16]
Ferrer-i-Cancho, R. (2005). The variation of Zipf’s law in human lan- guage.European Physical Journal B, 44, 249–257. https://doi.org/10 .1140/epjb/e2005-00121-8
2005
-
[17]
Neophytou, K., van-Egmond, M., & Avrutin, S. (2017). Zipf’s law in aphasia across languages: A comparison of English, Hungarian, and Greek.Journal of Quantitative Linguistics, 24, 178–196. https://doi. org/10.1080/09296174.2016.1263786 33
-
[18]
Zipf, G. K. (1935).The Psycho-Biology of Language. Houghton-Mifflin
1935
-
[19]
Zipf, G. K. (1949).Human Behavior and the Principle of Least Effort. Addison-Wesley
1949
-
[20]
Kuraszkiewicz, W., & Łukaszewicz, J. (1951). Ilość różnych wyrazów w zależności od długości tekstu.Pamiętnik Literacki
1951
-
[21]
Heaps, H. S. (1978).Information retrieval: Computational and theo- retical aspects. Academic Press
1978
-
[22]
Structural Complexity of Simplified Chinese Characters
Wang, Yanru and Chen, Xinying. "Structural Complexity of Simplified Chinese Characters".Recent Contributions to Quantitative Linguistics, edited by Arjuna Tuzzi, Martina Benesová and Ján Macutek, Berlin, München, Boston: De Gruyter Mouton, 2015, pp. 229-240. https: //doi.org/10.1515/9783110420296-019
-
[23]
Sanada, H. (2011). Investigations in Japanese Historical Lexicology. Japanese Language & Literature, 45(2), 519
2011
-
[24]
Zipf, G. K. (1932).Selected Studies of the Principle of Relative Fre- quencies of Language. Cambridge, Massachusetts: Harvard University Press
1932
-
[25]
Boroda, M., & Altmann, G. (1991). A First Glance at Textual Statis- tics.Glottometrika, 12
1991
-
[26]
Variationdeladuréedelasyllabefrançaisesuivant sa place dans les groupements phonétiques.La Parole
Grégoire, A.(1899). Variationdeladuréedelasyllabefrançaisesuivant sa place dans les groupements phonétiques.La Parole
-
[27]
Therelation- ship of word length and sentence length: The inter-textual perspective
Grzybek, P., Stadlober, E., &Kelih-Emmerich, N.(2007). Therelation- ship of word length and sentence length: The inter-textual perspective. InAdvances in data analysis(pp. 611-618). Springer
2007
-
[28]
Mačutek, J., Chromý, J., & Koščová, M. (2018). Menzerath-Altmann Law and Prothetic /v/ in Spoken Czech.Journal of Quantitative Lin- guistics,26(1), 66–80. https://doi.org/10.1080/09296174.2018.1424493
-
[29]
Fletcher, J. (2010). The Prosody of Speech: Timing and Rhythm. In The Handbook of Phonetic Sciences(eds W.J. Hardcastle, J. Laver and F.E. Gibbon). https://doi.org/10.1002/9781444317251.ch15
-
[30]
Blum, F., Paschen, L., Forkel, R. et al. (2024). Consonant lengthening marks the beginning of words across a diverse sample of languages.Nat 34 Hum Behav, 8, 2127–2138. https://doi.org/10.1038/s41562-024-01988 -4
-
[31]
Holmlund, T. B., Chandler, C., Foltz, P. W., Diaz-Asper, C., Co- hen, A. S., Rodriguez, Z., & Elvevåg, B. (2023). Towards a tem- porospatial framework for measurements of disorganization in speech using semantic vectors.Schizophrenia Research, 259, 71–79. https: //doi.org/10.1016/j.schres.2022.09.020
-
[32]
Palominos, C., He, R., Fröhlich, K., Mülfarth, R. R., Seuffert, S., Som- mer, I. E., Homan, P., Kircher, T., Stein, F., & Hinzen, W. (2024). Approximating the semantic space: Word embedding techniques in psy- chiatric speech analysis.Schizophrenia, 10(1), 1–10. https://doi.org/ 10.1038/s41537-024-00524-7
-
[33]
Miller, G. A. (1995). WordNet: A lexical database for English.Com- munications of the ACM, 38(11), 39–41. doi:10.1145/219717.219748
-
[34]
(2010).WordNet
Princeton University. (2010).WordNet. Retrieved from https://word net.princeton.edu/
2010
-
[35]
Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Sentence embed- dings using Siamese BERT-networks.arXiv. https://doi.org/10.48550 /arXiv.1908.10084
Pith/arXiv arXiv 2019
-
[36]
J., Chen, J., Müsch, K., & Hasson, U
Honey, C. J., Chen, J., Müsch, K., & Hasson, U. (2016). How long is now? The multiple timescales of language processing.Behavioral and Brain Sciences, 39, e77. https://doi.org/10.1017/S0140525X15000825
-
[37]
Golesorkhi, M., Gomez-Pilar, J., Tumati, S. et al. (2021). Tempo- ral hierarchy of intrinsic neural timescales converges with spatial core- periphery organization.Commun Biol, 4, 277. https://doi.org/10.103 8/s42003-021-01785-z
2021
-
[38]
Lewis GA, Poeppel D, Murphy GL. (2015). The neural bases of tax- onomic and thematic conceptual relations: an MEG study.Neuropsy- chologia, 68, 176-89. doi: 10.1016/j.neuropsychologia.2015.01.011
-
[39]
Jamali, M., Grannan, B., Cai, J. et al. (2024). Semantic encoding during language comprehension at single-cell resolution.Nature, 631, 610–616. https://doi.org/10.1038/s41586-024-07643-2 35
-
[40]
Crossley, S., Salsbury, T., & McNamara, D. (2009). Measuring L2 lexi- cal growth using hypernymic relationships.Language Learning, 59(2), 307–334. https://doi.org/10.1111/j.1467-9922.2009.00508.x
-
[41]
Crossley, S. A., & McNamara, D. S. (2012). Predicting second language writing proficiency: The roles of cohesion and linguistic sophistication. Journal of Research in Reading, 35(2), 115–135. https://doi.org/10.1 111/j.1467-9817.2010.01449.x
arXiv 2012
-
[42]
Bolognesi, M., Burgers, C. & Caselli, T. (2020). On abstraction: decou- pling conceptual concreteness and categorical specificity.Cogn Process, 21, 365–381. https://doi.org/10.1007/s10339-020-00965-9
-
[43]
Paivio, A. (1991). Dual coding theory: Retrospect and current status. Canadian Journal of Psychology / Revue canadienne de psychologie, 45(3), 255–287. https://doi.org/10.1037/h0084295
-
[44]
Sadoski, M., & Paivio, A. (1994). A dual coding view of imagery and verbal processes in reading comprehension. In R. B. Ruddell, M. R. Ruddell, &H.Singer(Eds.),Theoretical models and processes of reading (4th ed., pp. 582–601). International Reading Association
1994
-
[45]
Binder, J. R., Conant, L. L., Humphries, C. J., Fernandino, L., Simons, S. B., Aguilar, M., & Desai, R. H. (2016). Toward a brain-based com- ponential semantic representation.Cognitive neuropsychology,33(3-4), 130–174. https://doi.org/10.1080/02643294.2016.1147426
-
[46]
F., Khachatryan, E., Chehrazad, S., Kotarcic, A., De Let- ter, M., & Van Hulle, M
Hnazaee, M. F., Khachatryan, E., Chehrazad, S., Kotarcic, A., De Let- ter, M., & Van Hulle, M. M. (2020). Overlapping connectivity patterns during semantic processing of abstract and concrete words revealed withmultivariateGrangerCausalityanalysis.Scientific Reports, 10(1),
2020
-
[47]
https://doi.org/10.1038/s41598-020-59473-7
-
[48]
Bi Y. (2021). Dual coding of knowledge in the human brain.Trends Cogn Sci, 25(10), 883-895. doi: 10.1016/j.tics.2021.07.006
-
[49]
Vignali, L., Xu, Y., Turini, J., Collignon, O., Crepaldi, D., & Bottini, R. (2023). Spatiotemporal dynamics of abstract and concrete semantic representations.Brain and language, 243, 105298. https://doi.org/10 .1016/j.bandl.2023.105298
arXiv 2023
-
[50]
Müller, Meinard (2007). Dynamic Time Warping. InInformation 36 Retrieval for Music and Motion, chapter 4, pages 69-84. Springer. doi:10.1007/978-3-540-74048-3
-
[51]
García, A.M., & Ibáñez, A. (Eds.). (2022).The Routledge Handbook of Semiosis and the Brain(1st ed.). Routledge. https://doi.org/10.4324/ 9781003051817
2022
-
[52]
Smith, D., Wolff, A., Wolman, A., Ignaszewski, J., & Northoff, G. (2022). Temporal continuity of self: Long autocorrelation windows mediate self-specificity.NeuroImage, 257, 119305. https://doi.org/10 .1016/j.neuroimage.2022.119305
arXiv 2022
-
[53]
(2024).GPT-4[Large language model]
OpenAI. (2024).GPT-4[Large language model]. https://openai.com
2024
-
[54]
Pawar, A., & Mago, V. (2018). Calculating the similarity between words and sentences using a lexical database and corpus statistics.In- ternational Journal of Computer Applications, 182(34), 1–10
2018
-
[55]
Theiler, J., & Prichard, D. (1996). Constrained-realization Monte- Carlo method for hypothesis testing.Physica D: Nonlinear Phenom- ena, 94(4), 221–235. https://doi.org/10.1016/0167-2789(96)00050-4
-
[56]
Brown, M. B. (1975). 400: A Method for Combining Non-Independent, One-Sided Tests of Significance.Biometrics, 31(4), 987–92. https: //doi.org/10.2307/2529826
-
[57]
Poole, W., Gibbs, D.L., Shmulevich, I., Bernard, B., &Knijnenburg, T. A. (2016). Combining dependent P-values with an empirical adaptation of Brown’ s method.Bioinformatics (Oxford, England), 32(17), i430– i436. https://doi.org/10.1093/bioinformatics/btw438
-
[58]
(2023).Dynamic Time Warping (DTW) in Python
dtaidistance. (2023).Dynamic Time Warping (DTW) in Python. Available at: https://github.com/wannesm/dtaidistance
2023
-
[59]
(2022).Signal Processing Toolbox for MATLAB
MathWorks. (2022).Signal Processing Toolbox for MATLAB. The MathWorks, Inc. Available at: https://www.mathworks.com/products /signal.html
2022
-
[60]
Seabold, S. and Perktold, J. (2010). Statsmodels: Econometric and Modeling with Python.9th Python in Science Conference, Austin, 28 June-3 July, 2010, 57-61. https://doi.org/10.25080/Majora-92bf1922-0 11 37
-
[61]
Murray, J., Bernacchia, A., Freedman, D. et al. (2014). A hierarchy of intrinsic timescales across primate cortex.Nat Neurosci, 17, 1661–
2014
-
[62]
https://doi.org/10.1038/nn.3862
-
[63]
Chaudhuri, R., Knoblauch, K., Gariel, M.-A., Kennedy, H., & Wang, X.-J. (2015). A Large-Scale Circuit Mechanism for Hierarchical Dy- namical Processing in the Primate Cortex.Neuron, 88(2), 419–431. https://doi.org/10.1016/j.neuron.2015.09.008
-
[64]
Phipson, B., & Smyth, G. K. (2010). Permutation P-values should never be zero: calculating exact P-values when permutations are ran- domly drawn.Statistical applications in genetics and molecular biology, 9, Article39. https://doi.org/10.2202/1544-6115.1585
-
[65]
Kolmogorov, A. N. (1933). Sulla determinazione empirica di una legge di distribuzione.Giornale dell’Istituto Italiano degli Attuari, 4, 83–91
1933
-
[66]
Smirnov, N. (1948). Table for Estimating the Goodness of Fit of Em- pirical Distributions.The Annals of Mathematical Statistics, 19(2), 279-281. https://doi.org/10.1214/aoms/1177730256
-
[67]
Spearman, C. (1904). The Proof and Measurement of Association be- tween Two Things.The American Journal of Psychology, 15(1), 72–
1904
-
[68]
https://doi.org/10.2307/1412159
-
[69]
Hasson, U., Chen, J., & Honey, C. J. (2015). Hierarchical process memory: memory as an integral component of information processing. Trends in Cognitive Sciences, 19(6), 304-313. https://doi.org/10.101 6/j.tics.2015.04.006
2015
-
[70]
T., Beltz, B
Kello, C. T., Beltz, B. C., Holden, J. G., & Van Orden, G. C. (2007). The emergent coordination of cognitive function.Journal of experi- mental psychology. General, 136(4), 551–568. https://doi.org/10.103 7/0096-3445.136.4.551
2007
-
[71]
Janssen, N., Meij, M.v.d., López-Pérez, P.J. et al. (2020). Exploring the temporal dynamics of speech production with EEG and group ICA. Sci Rep, 10, 3667. https://doi.org/10.1038/s41598-020-60301-1
-
[72]
Chang, C. H. C., Nastase, S. A., & Hasson, U. (2022). Information flow across the cortical timescale hierarchy during narrative construction. Proceedings of the National Academy of Sciences of the United States 38 of America, 119(51), e2209307119. https://doi.org/10.1073/pnas.220 9307119
-
[73]
Zhu, Y., Xu, M., Lu, J. et al. (2022). Distinct spatiotemporal patterns of syntactic and semantic processing in human inferior frontal gyrus. Nat Hum Behav, 6, 1104–1111. https://doi.org/10.1038/s41562-022-0 1334-6
-
[74]
Murphy, E., Forseth, K.J., Donos, C. et al. (2023). The spatiotemporal dynamics of semantic integration in the human brain.Nat Commun, 14, 6336. https://doi.org/10.1038/s41467-023-42087-8
-
[75]
Levy, R., & Jaeger, T. F. (2007). Speakers optimize information density through syntactic reduction. In B. Schölkopf, J. Platt, & T. Hofmann (Eds.),Advances in Neural Information Processing Systems 19
2007
-
[76]
Hale, J. (2001). A Probabilistic Earley Parser as a Psycholinguistic Model. InProceedings of the Second Meeting of the North American Chapter of the Association for Computational Linguistics
2001
-
[77]
Resnik, P. (1995). Using information content to evaluate semantic sim- ilarity in a taxonomy. InProceedings of the 14th international joint conference on Artificial intelligence - Volume 1(pp. 448–453). Mor- gan Kaufmann Publishers Inc
1995
-
[78]
An intrinsic information content metric for semantic similarity in WordNet
Seco, Veale, & Hayes (2004)."An intrinsic information content metric for semantic similarity in WordNet"inECAI 2004, pp. 1089–1090
2004
-
[79]
Altmann EG, Pierrehumbert JB, Motter AE (2009) Beyond Word Fre- quency: Bursts, Lulls, and Scaling in the Temporal Distributions of Words. PLOS ONE 4(11): e7678. https://doi.org/10.1371/journal.po ne.0007678
-
[80]
Kello CT, Brown GD, Ferrer-I-Cancho R, Holden JG, Linkenkaer- Hansen K, Rhodes T, Van Orden GC. (2010). Scaling laws in cognitive sciences.Trends Cogn Sci, 14(5), 223-32. doi: 10.1016/j.tics.2010.02.005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.