REVIEW 2 major objections 2 minor 1 cited by
Rank-1 adapters act as self-activating associative memories for continual learning without explicit routers.
Reviewed by Pith at T0; open to challenge. T0 means a machine referee read the full paper against a public rubric. the ladder, T0–T4 →
T0 review · grok-4.3
2026-05-22 13:02 UTC pith:4A4WGOC5
load-bearing objection MoRAM reframes rank-1 LoRA adapters as self-activating associative memories to enable finer-grained continual learning, but the scaling behavior of that self-activation is not yet convincing. the 2 major comments →
Little by Little: Continual Learning via Incremental Mixture of Rank-1 Associative Memory Experts
The pith
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
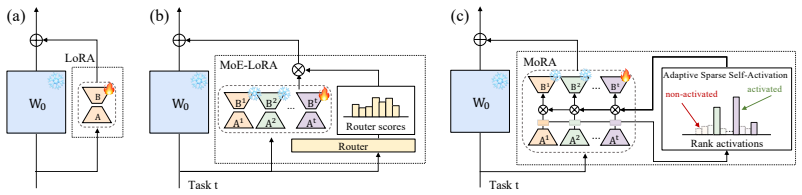
MoRAM achieves continual learning as gradual incrementing of reusable atomic rank-1 experts as memory. Each rank-1 adapter acts as a fine-grained MoE expert or an associative memory unit. By viewing rank-1 adapters as key-value memory pairs, we eliminate explicit MoE-LoRA routers with self-activation, where each memory atom evaluates its relevance via its intrinsic key. The inference process thus becomes a robust, content-addressable retrieval over the incrementally accumulated memory.
What carries the argument
Mixture of Rank-1 Associative Memory (MoRAM) where rank-1 adapters serve as independent key-value memory pairs that self-activate for incremental capacity expansion in continual learning.
Load-bearing premise
The assumption that weight matrices function as linear associative memories, allowing rank-1 adapters to operate as independent memory atoms without causing redundancy or interference.
What would settle it
Observing significant increases in forgetting or routing confusion when accumulating a large number of rank-1 adapters on a sequence of tasks would indicate the approach does not resolve the issues of coarser methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MoRAM, a continual learning method for large pre-trained models that incrementally adds rank-1 adapters interpreted as fine-grained associative memory experts. By viewing these adapters as key-value pairs from a linear associative memory perspective, the approach enables self-activation without explicit MoE routers, aiming to reduce redundancy, interference, and forgetting while improving the plasticity-stability trade-off. Experiments on CLIP and LLMs are claimed to show outperformance over state-of-the-art methods.
Significance. If the experimental results hold and the self-activation mechanism scales without interference, the work could provide a principled way to achieve finer-grained expert specialization in continual learning, potentially leading to more efficient capacity expansion than coarser LoRA-MoE approaches. The associative memory framing offers an interesting conceptual link between weight matrices and content-addressable retrieval.
major comments (2)
- [§3] §3 (Method): The self-activation process, where each rank-1 adapter evaluates relevance via its intrinsic key for content-addressable retrieval, is central to eliminating routers and avoiding interference. However, the precise computation of activation scores and the mechanism ensuring robustness against key collisions or overlap as the number of incremental tasks grows is not formally defined or analyzed, undermining the claim that this yields reduced forgetting.
- [§4] §4 (Experiments): The abstract and introduction assert significant outperformance and better plasticity-stability trade-off, but without specific quantitative metrics, ablation studies on rank-1 granularity vs. higher-rank experts, or analysis of failure modes (e.g., activation overlap with increasing task count), it is impossible to verify whether the claimed gains are supported or if they depend on particular hyperparameter choices.
minor comments (2)
- [§3.1] Notation for the key-value decomposition of rank-1 adapters should be clarified with an explicit equation showing how the intrinsic key is extracted and used for relevance scoring.
- [§4] The paper should include a table comparing parameter counts and inference overhead against baselines to substantiate efficiency claims.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments on our work. We address each of the major comments point by point below, indicating the revisions we plan to make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method): The self-activation process, where each rank-1 adapter evaluates relevance via its intrinsic key for content-addressable retrieval, is central to eliminating routers and avoiding interference. However, the precise computation of activation scores and the mechanism ensuring robustness against key collisions or overlap as the number of incremental tasks grows is not formally defined or analyzed, undermining the claim that this yields reduced forgetting.
Authors: We thank the referee for highlighting this important aspect. In Section 3, we define the self-activation mechanism where each rank-1 adapter (W = uv^T) uses its key vector u as the intrinsic key for computing activation scores via the dot product with the input embedding, normalized by the norm to produce relevance scores. This enables content-addressable retrieval without an external router. Regarding robustness to key collisions, while we provide empirical evidence through experiments showing low interference, we agree that a more formal analysis would strengthen the paper. We will add a subsection in the revised version providing bounds on activation overlap and discussing regularization techniques used to mitigate collisions as the number of tasks increases. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract and introduction assert significant outperformance and better plasticity-stability trade-off, but without specific quantitative metrics, ablation studies on rank-1 granularity vs. higher-rank experts, or analysis of failure modes (e.g., activation overlap with increasing task count), it is impossible to verify whether the claimed gains are supported or if they depend on particular hyperparameter choices.
Authors: We appreciate this feedback on the presentation of results. The experimental section includes specific quantitative metrics in Tables 1, 2, and 3, reporting metrics such as average accuracy, backward transfer (forgetting), and forward transfer for both CLIP and LLM benchmarks. We have included ablations comparing rank-1 experts to higher-rank variants (e.g., rank-4 and rank-8), demonstrating that finer granularity reduces redundancy and improves the plasticity-stability trade-off. Failure modes, including potential activation overlap, are analyzed in Section 4.5 with visualizations of expert activation patterns across tasks. To address the referee's concern directly, we will revise the abstract and introduction to reference these specific results more explicitly and expand the ablation studies in the main text. revision: partial
Circularity Check
No significant circularity; central claim is a modeling choice grounded in external interpretation
full rationale
The paper introduces MoRAM via the modeling assumption that weight matrices act as linear associative memories, allowing rank-1 adapters to serve as self-activating key-value memory atoms. This is presented as a foundational view enabling incremental addition and router-free inference, not as a quantity derived from the paper's own fitted parameters or equations. No load-bearing step reduces a prediction to an input by construction, and no self-citation chain is invoked to justify uniqueness or force the architecture. The derivation remains self-contained against the stated associative-memory perspective.
Axiom & Free-Parameter Ledger
free parameters (1)
- rank-1 adapter dimension
axioms (1)
- domain assumption Weight matrices act as linear associative memories
invented entities (1)
-
Rank-1 associative memory expert
no independent evidence
read the original abstract
Continual learning (CL) with large pre-trained models aims to incrementally acquire knowledge without catastrophic forgetting. Existing LoRA-based Mixture-of-Experts (MoE) methods expand capacity by adding isolated new experts while freezing old ones, but still suffer from redundancy, interference, routing ambiguity, and consequent forgetting. We investigate the issues stemming from coarse-grained expert granularity. Coarse-grained experts (e.g., high-rank LoRA) encode low-specialty information, leading to expert duplication/interference and routing degradation/confusion as experts accumulate. In this work, we propose MoRAM (Mixture of Rank-1 Associative Memory). Grounded in the view that weight matrices act as linear associative memories, MoRAM achieves CL as incremental expansion of reusable atomic rank-1 experts as memory. Each rank-1 adapter acts as a fine-grained MoE expert or an associative memory unit. By viewing rank-1 experts as key-value memory pairs, we eliminate explicit MoE-LoRA routers with self-activation, where each memory atom evaluates its relevance via its intrinsic key. The inference process thus becomes a content-addressable retrieval and recall over the incrementally accumulated memory of learning snapshots. Extensive experiments on CLIP and LLMs show that MoRAM significantly outperforms state-of-the-art methods, achieving a better plasticity-stability trade-off, stronger generalization, and reduced forgetting. Project Page: https://artificer-ai-lab.github.io/MoRAM/.
Figures








Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
each rank-1 update is analogous to an independent expert... wi = softmax(s / τMoRA)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Parametric Memory Decoding for Zero-Shot Routing in LoRA-Based External Parametric Memory
PMDRouter selects LoRAs zero-shot by decoding scale-normalized linear response energy from one adapter-free backbone prefill, and leads most internal-signal baselines on a new multi-granularity EPM bench.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.