FlowAWR: Online Adaptive Flow Reinforcement via Advantage-Weighted Rectification
Pith reviewed 2026-06-30 07:07 UTC · model grok-4.3
The pith
FlowAWR derives the optimal velocity field for flow models from KL-constrained reward maximization, expressed as a magnitude-aware advantage-weighted rectification that serves as a direct supervised regression target.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
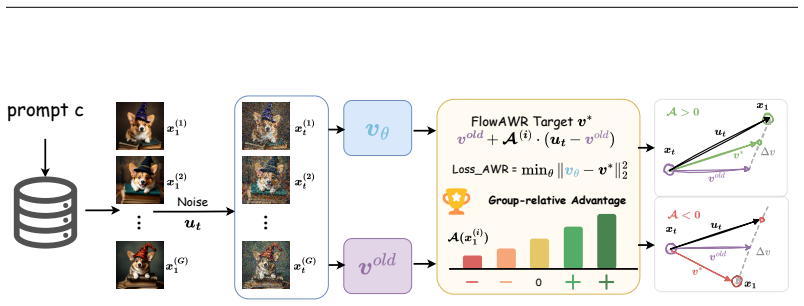
Starting from the optimal policy of a KL-constrained reward maximization, FlowAWR derives the optimal velocity field that admits a magnitude-aware, advantage-weighted rectification form. This form is then used as the supervised regression target, which yields SDE-free optimization and CFG-free generation.
What carries the argument
The magnitude-aware advantage-weighted rectification form of the optimal velocity field derived from the KL-constrained optimal policy, which converts the policy optimization problem into supervised regression on that field.
If this is right
- Optimization proceeds without constructing tractable transition kernels via SDE samplers.
- Generation requires no classifier-free guidance.
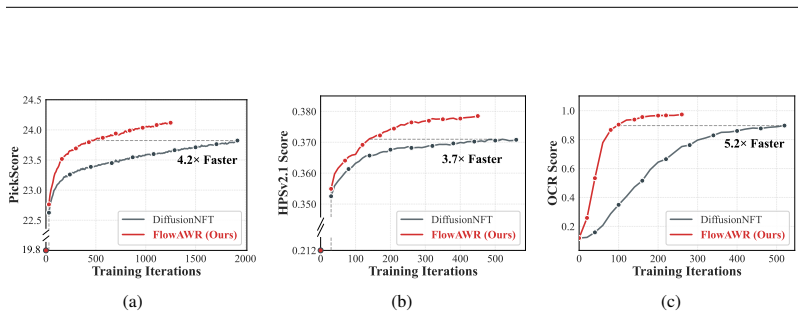
- Convergence reaches target alignment scores in 2x to 5x fewer steps than DiffusionNFT on SD3.5-Medium.
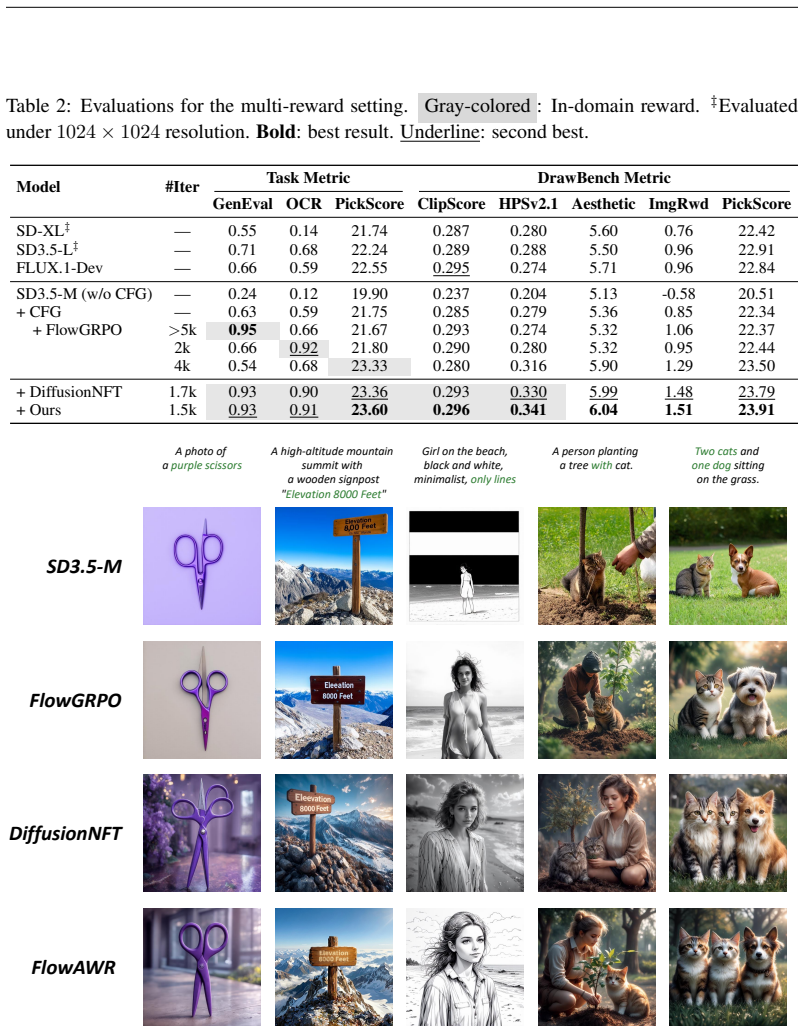
- Multi-reward training preserves structural rules and out-of-domain stability.
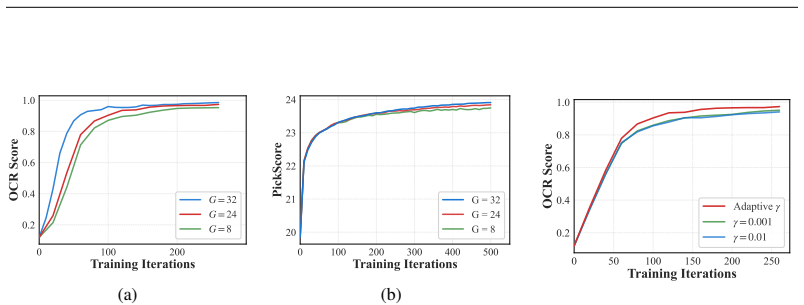
- Rectification strength automatically adapts to relative advantage within each training group.
Where Pith is reading between the lines
- The rectification approach may extend to other continuous-time generative processes whose velocity fields can be expressed in closed form under similar KL constraints.
- Removing SDE sampling during training could lower memory and compute costs enough to scale online RL alignment to larger flow architectures.
- Advantage weighting inside the rectification might interact with different reward combinations in ways that allow more stable multi-objective alignment than fixed-magnitude methods.
- If the derived field remains stable under distribution shift, the method could support iterative self-improvement loops without external preference data.
Load-bearing premise
The optimal policy under KL-constrained reward maximization directly produces a velocity field whose rectification can be used as a regression target without introducing new inconsistencies or needing further approximations.
What would settle it
A direct comparison, on the same flow model and reward, of samples generated by the FlowAWR velocity field against samples from an exact SDE-based policy gradient method that measures whether alignment metrics and sample quality diverge beyond what the paper's empirical gaps would predict.
Figures
read the original abstract
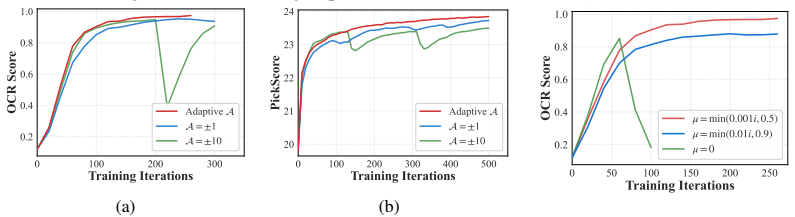
Aligning generative flow models on continuous spaces via online reinforcement learning is constrained by intractable trajectory likelihoods. Existing density-approximated policy gradient methods rely on stochastic SDE samplers to construct tractable transition kernels, which introduce training-inference inconsistencies and necessitates Classifier-Free Guidance (CFG). While implicit frameworks such as DiffusionNFT directly optimize forward-process velocity fields, its heuristic fixed-magnitude corrections prevent optimization strength from relative intra-group quality. We propose \textit{Flow Advantage-Weighted Rectification} (\textbf{FlowAWR}), a paradigm that recasts continuous generative policy optimization as supervised regression toward a theoretically optimal velocity field. Starting from the optimal policy of a KL-constrained reward maximization, FlowAWR derives the optimal velocity field that admits a magnitude-aware, advantage-weighted rectification form, yielding SDE-free optimization and CFG-free generation. In comparative evaluations on SD3.5-Medium, FlowAWR achieves improved alignment performance alongside a 2$\times$ to 5$\times$ convergence acceleration over DiffusionNFT (e.g., reaching a 24.12 PickScore in 1.2k steps, versus 23.82 in 2.0k steps for DiffusionNFT and 23.50 in $>$4k steps for FlowGRPO). Under multi-reward constraints, FlowAWR sustains generation quality, satisfying structural rules while maintaining stable out-of-domain performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FlowAWR for aligning generative flow models via online RL. It claims that starting from the optimal policy of a KL-constrained reward maximization problem, one can derive an optimal velocity field admitting a magnitude-aware advantage-weighted rectification form. This is asserted to enable SDE-free optimization and CFG-free generation. On SD3.5-Medium, it reports reaching 24.12 PickScore in 1.2k steps versus 23.82 in 2.0k steps for DiffusionNFT and 23.50 in >4k steps for FlowGRPO, with additional claims of stable performance under multi-reward constraints.
Significance. If the central derivation holds without hidden approximations, the approach could provide a cleaner supervised-regression route for policy optimization in continuous flow models, avoiding SDE-induced inconsistencies. The reported convergence speed-up would be a practical contribution to RL alignment of generative models, though the lack of verifiable steps and error analysis makes the significance currently difficult to assess.
major comments (2)
- [Abstract] Abstract (derivation paragraph): The mapping from the KL-optimal policy π* to a velocity field v* whose rectification is exactly magnitude-aware and advantage-weighted is stated as direct but supplies no equations, intermediate identities, or regularity assumptions on the probability path or reward. This step is load-bearing for the SDE-free and CFG-free claims.
- [Experiments] Experimental section: Reported PickScore numbers (24.12, 23.82, 23.50) lack error bars, dataset/evaluation protocol details, and an ablation isolating the magnitude-aware component, so the comparative claims and the contribution of the rectification cannot be verified.
minor comments (1)
- [Abstract] The abstract states '2× to 5× convergence acceleration' without a table or explicit step counts per baseline; adding such a comparison table would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract (derivation paragraph): The mapping from the KL-optimal policy π* to a velocity field v* whose rectification is exactly magnitude-aware and advantage-weighted is stated as direct but supplies no equations, intermediate identities, or regularity assumptions on the probability path or reward. This step is load-bearing for the SDE-free and CFG-free claims.
Authors: The abstract serves as a high-level summary. The full derivation from the KL-constrained optimal policy π* to the optimal velocity field v*, including all intermediate identities and regularity assumptions on the probability path and reward, appears in Section 3 of the manuscript. We will revise the abstract to include an explicit reference to the central equation that establishes the magnitude-aware advantage-weighted rectification form. revision: partial
-
Referee: [Experiments] Experimental section: Reported PickScore numbers (24.12, 23.82, 23.50) lack error bars, dataset/evaluation protocol details, and an ablation isolating the magnitude-aware component, so the comparative claims and the contribution of the rectification cannot be verified.
Authors: We agree that additional experimental details are needed for verifiability. The revised manuscript will report error bars over multiple random seeds, provide complete dataset and evaluation protocol information, and include an ablation isolating the magnitude-aware component to quantify its contribution to the observed gains. revision: yes
Circularity Check
No circularity: derivation presented as independent theoretical step from KL-optimal policy
full rationale
The abstract describes deriving an optimal velocity field from the KL-constrained optimal policy, yielding a rectification form for supervised regression. No equations, self-citations, fitted parameters renamed as predictions, or ansatzes are provided in the given text that would allow exhibiting a reduction by construction. The central mapping is stated as a derivation rather than a redefinition or fit, and no load-bearing self-citation chain appears. This is the expected non-finding when the source supplies only high-level claims without inspectable identities.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Ale- man, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Training Diffusion Models with Reinforcement Learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning.arXiv preprint arXiv:2305.13301,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Directly Fine-Tuning Diffusion Models on Differentiable Rewards
Kevin Clark, Paul Vicol, Kevin Swersky, and David J Fleet. Directly fine-tuning diffusion models on differentiable rewards.arXiv preprint arXiv:2309.17400,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capa- bilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment
Hanze Dong, Wei Xiong, Deepanshu Goyal, Yihan Zhang, Winnie Chow, Rui Pan, Shizhe Diao, Jipeng Zhang, Kashun Shum, and Tong Zhang. Raft: Reward ranked finetuning for generative foundation model alignment.arXiv preprint arXiv:2304.06767,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Soft Actor-Critic Algorithms and Applications
Tuomas Haarnoja, Aurick Zhou, Kristian Hartikainen, George Tucker, Sehoon Ha, Jie Tan, Vikash Kumar, Henry Zhu, Abhishek Gupta, Pieter Abbeel, et al. Soft actor-critic algorithms and appli- cations.arXiv preprint arXiv:1812.05905,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Clipscore: A reference-free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning. InProceedings of the 2021 conference on empirical methods in natural language processing, pp. 7514–7528,
2021
-
[8]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Planning with Diffusion for Flexible Behavior Synthesis
11 Michael Janner, Yilun Du, Joshua B Tenenbaum, and Sergey Levine. Planning with diffusion for flexible behavior synthesis.arXiv preprint arXiv:2205.09991,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Inference-time alignment control for diffusion models with reinforcement learning guidance
Luozhijie Jin, Zijie Qiu, Jie Liu, Zijie Diao, Lifeng Qiao, Ning Ding, Alex Lamb, and Xipeng Qiu. Inference-time alignment control for diffusion models with reinforcement learning guidance. arXiv preprint arXiv:2508.21016,
-
[11]
Aligning Text-to-Image Models using Human Feedback
Kimin Lee, Hao Liu, Moonkyung Ryu, Olivia Watkins, Yuqing Du, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, and Shixiang Shane Gu. Aligning text-to-image models using human feedback.arXiv preprint arXiv:2302.12192,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review
Sergey Levine. Reinforcement learning and control as probabilistic inference: Tutorial and review. arXiv preprint arXiv:1805.00909,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE
Junzhe Li, Yutao Cui, Tao Huang, Yinping Ma, Chun Fan, Miles Yang, and Zhao Zhong. Mixgrpo: Unlocking flow-based grpo efficiency with mixed ode-sde.arXiv preprint arXiv:2507.21802,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Flow-GRPO: Training Flow Matching Models via Online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Xue Bin Peng, Aviral Kumar, Grace Zhang, and Sergey Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning.arXiv preprint arXiv:1910.00177,
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[18]
Mihir Prabhudesai, Anirudh Goyal, Deepak Pathak, and Katerina Fragkiadaki. Aligning text-to- image diffusion models with reward backpropagation.arXiv preprint arXiv:2310.03739,
-
[19]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Seedream 4.0: Toward Next-generation Multimodal Image Generation
Team Seedream, Yunpeng Chen, Yu Gao, Lixue Gong, Meng Guo, Qiushan Guo, Zhiyao Guo, Xiaoxia Hou, Weilin Huang, Yixuan Huang, et al. Seedream 4.0: Toward next-generation multi- modal image generation.arXiv preprint arXiv:2509.20427,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathemati- cal reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456,
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[23]
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models.arXiv preprint arXiv:2303.01469,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to- image synthesis.arXiv preprint arXiv:2306.09341,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
DanceGRPO: Unleashing GRPO on Visual Generation
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al. Dancegrpo: Unleashing grpo on visual generation.arXiv preprint arXiv:2505.07818,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Energy-weighted flow matching for offline reinforcement learning,
Shiyuan Zhang, Weitong Zhang, and Quanquan Gu. Energy-weighted flow matching for offline reinforcement learning.arXiv preprint arXiv:2503.04975,
-
[29]
DiffusionNFT: Online Diffusion Reinforcement with Forward Process
Kaiwen Zheng, Huayu Chen, Haotian Ye, Haoxiang Wang, Qinsheng Zhang, Kai Jiang, Hang Su, Stefano Ermon, Jun Zhu, and Ming-Yu Liu. Diffusionnft: Online diffusion reinforcement with forward process.arXiv preprint arXiv:2509.16117,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Fine-Tuning Language Models from Human Preferences
Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences.arXiv preprint arXiv:1909.08593,
work page internal anchor Pith review Pith/arXiv arXiv 1909
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.