Koshur Pixel: a large-scale synthetic ocr dataset for kashmiri
Pith reviewed 2026-06-26 09:17 UTC · model grok-4.3
The pith
Koshur Pixel supplies the first large-scale synthetic OCR dataset for Kashmiri with 613,078 image-text pairs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
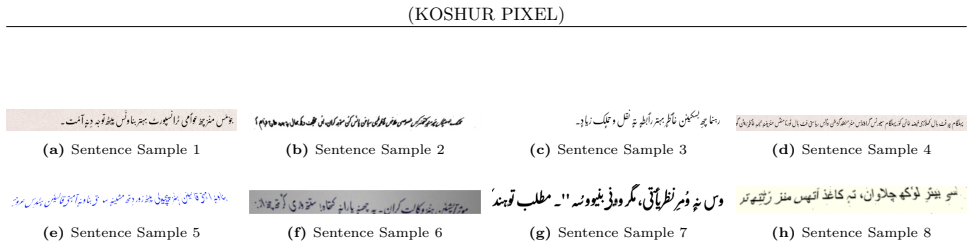
Koshur Pixel is a collection of 613,078 synthetic image-text pairs for Kashmiri, produced from the KS-PRET-5M corpus through the SynthOCR-Gen framework; the pairs cover multiple fonts, range from single words to full-page layouts, and include more than 25 augmentation strategies that emulate real-world degradations.
What carries the argument
SynthOCR-Gen framework that renders text from a large Kashmiri corpus into images across fonts and granularities while applying degradation augmentations.
If this is right
- Supplies a cost-effective substitute for manual annotation when building Kashmiri OCR systems.
- Enables training of models that can digitize existing Kashmiri textual heritage.
- Provides a foundation for language technologies serving a severely under-resourced language.
- Covers multiple fonts and document scales from isolated words to complete pages.
Where Pith is reading between the lines
- The same generation pipeline could be reused for other low-resource languages that employ Nastaliq or related Perso-Arabic scripts.
- Models trained only on the synthetic set would probably benefit from later fine-tuning on even modest amounts of real scanned data.
- Direct comparison of error rates between synthetic-only training and mixed synthetic-plus-real training would quantify the dataset's practical value.
Load-bearing premise
Synthetic images produced with the chosen fonts and augmentations are representative enough of real Kashmiri documents to train effective OCR models.
What would settle it
Train an OCR model on Koshur Pixel and measure its character or word error rate on a separate collection of scanned real-world Kashmiri documents.
Figures


read the original abstract
Optical Character Recognition (OCR) for low-resource languages is often constrained by the lack of annotated training data and the complexity of script-specific rendering. Kashmiri, written primarily in the Perso-Arabic Nastaliq script, presents additional challenges due to contextual glyph shaping, dense ligatures, and orthographic variability. We introduce Koshur Pixel, the first large-scale synthetic OCR dataset for Kashmiri, comprising 613,078 image-text pairs generated from the KS-PRET-5M corpus using the SynthOCR-Gen framework. The dataset spans multiple fonts and textual granularities, ranging from individual words to full-page documents, and incorporates more than 25 augmentation strategies that emulate real-world document degradations. Koshur Pixel provides a scalable and cost-effective alternative to manual annotation, establishing a foundational resource for training OCR systems, digitizing Kashmiri textual heritage, and advancing language technologies for a severely under-resourced language.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Koshur Pixel as the first large-scale synthetic OCR dataset for Kashmiri, comprising 613,078 image-text pairs generated from the KS-PRET-5M corpus using the SynthOCR-Gen framework. It spans multiple fonts and textual granularities (words to full pages) and applies more than 25 augmentation strategies to emulate document degradations, positioning the dataset as a scalable, cost-effective alternative to manual annotation and a foundational resource for OCR training in this low-resource language with Nastaliq script challenges.
Significance. If the synthetic generation process produces data that transfers effectively to real Kashmiri documents, the dataset could provide a valuable starting point for training OCR models where annotated real data is scarce, supporting digitization efforts for Kashmiri textual heritage. The scale and augmentation count are strengths, but the lack of any reported validation metrics means the practical significance remains unassessed.
major comments (1)
- [Abstract] Abstract: The central claim that Koshur Pixel 'establishes a foundational resource for training OCR systems' is load-bearing on the assumption that the SynthOCR-Gen pipeline and >25 augmentations produce image-text pairs representative of real Nastaliq ligatures, contextual shaping, and degradations. No quantitative support is supplied—no real-document test set, no CER/WER numbers on held-out data, no ablation on augmentation realism, and no comparison to existing low-resource OCR baselines—preventing assessment of whether models trained on the dataset generalize.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We agree that the abstract's claim requires qualification in the absence of empirical validation metrics, and we will revise the manuscript to address this directly while preserving the core contribution as a synthetic dataset release.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that Koshur Pixel 'establishes a foundational resource for training OCR systems' is load-bearing on the assumption that the SynthOCR-Gen pipeline and >25 augmentations produce image-text pairs representative of real Nastaliq ligatures, contextual shaping, and degradations. No quantitative support is supplied—no real-document test set, no CER/WER numbers on held-out data, no ablation on augmentation realism, and no comparison to existing low-resource OCR baselines—preventing assessment of whether models trained on the dataset generalize.
Authors: We acknowledge the validity of this observation. The manuscript introduces a synthetic dataset to mitigate the absence of annotated Kashmiri OCR data, but the strong phrasing in the abstract does overstate the immediate utility without supporting experiments. Because no large-scale, publicly available annotated real-world Kashmiri document corpus exists for benchmarking, we cannot supply CER/WER results, ablation studies on real data, or baseline comparisons at present. We will revise the abstract to state that Koshur Pixel 'provides a large-scale synthetic resource intended to support the development of OCR systems' rather than claiming it 'establishes a foundational resource.' We will also add a dedicated limitations subsection discussing the synthetic nature of the data, the lack of real-document validation, and the need for future collection of annotated real samples. These changes will make the scope of the contribution explicit. revision: yes
- Provision of quantitative metrics (CER/WER, ablations, or real-document test sets) on actual Kashmiri documents, as no such annotated real-world resources are currently available for this low-resource language.
Circularity Check
No circularity: dataset generation paper with no derivations or fitted predictions
full rationale
The paper describes creation of a synthetic OCR dataset (Koshur Pixel) from the KS-PRET-5M corpus via the SynthOCR-Gen framework plus augmentations. No equations, parameter fitting, predictions, uniqueness theorems, or self-citations appear in the provided text. The central claim is simply that the generated image-text pairs exist and can serve as training data; this does not reduce to any input by construction. The work is self-contained as a resource release and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The KS-PRET-5M corpus contains representative Kashmiri text suitable for generating OCR training data.
- domain assumption More than 25 augmentation strategies can emulate real-world document degradations sufficiently for training OCR models.
Reference graph
Works this paper leans on
-
[1]
INTRODUCTION: THE DIGIT AL VOID AND LINGUISTIC INEQUITY The rapid and pervasive advancement of artificial intelligence (AI) and digital technologies has fundamentally reshaped human interaction with information, commerce, and culture. Yet, this transformative progress has not been uniformly distributed across the global linguistic landscape. A significant...
Pith/arXiv arXiv 2026
-
[2]
BACKGROUND AND RELA TED WORK: KASHMIRI NLP AND OCR EVOLUTION 2.1. The Historical Context of Kashmiri Digitization and NLP The journey of the Kashmiri language into the digital realm has been historically complex and fraught with significant technical hurdles. For several decades, the de facto standard for digital typesetting and printing of Kashmiri text ...
-
[3]
This critical technological breakthrough enabled the recovery and standardization of millions of words of previously inaccessible Kashmiri literature
developed a robust and highly accurate InPage-to-Unicode converter, achieving an impressive 98.7% conversion accuracy. This critical technological breakthrough enabled the recovery and standardization of millions of words of previously inaccessible Kashmiri literature. The output of this conversion process formed the foundational KS-PRET-5M corpus [ 2], w...
-
[4]
Nastaliq, a term derived from the Persian words naskh (copying) and ta’liq (hanging), is renowned for its aesthetic beauty and fluid, cursive nature
DEEP LINGUISTIC ANAL YSIS OF THE KASHMIRI NAST ALIQ SCRIPT Kashmiri is predominantly written in the Perso-Arabic script, specifically adopting the Nastaliq calligraphic style, which accounts for over 98.5% of its written material. Nastaliq, a term derived from the Persian words naskh (copying) and ta’liq (hanging), is renowned for its aesthetic beauty and...
-
[5]
Noise Filtering: The diacritics are often treated as extraneous visual noise, such as smudges or scanner artifacts, and are consequently filtered out or ignored during preprocessing, leading to a complete loss of phonological information
-
[6]
This results in a transcription that is orthographically incorrect and semantically altered, rendering the text linguistically meaningless
Character Substitution: The model may incorrectly substitute a unique Kashmiri character with the closest visually similar Arabic or Urdu character it has been trained on. This results in a transcription that is orthographically incorrect and semantically altered, rendering the text linguistically meaningless
-
[7]
This can lead to fragmented character recognition or incorrect bounding box predictions, further degrading accuracy
Segmentation F ailure: Due to the vertical stacking nature of many diacritics, OCR systems often struggle to correctly segment the base character from its diacritical mark. This can lead to fragmented character recognition or incorrect bounding box predictions, further degrading accuracy. A robust Kashmiri OCR system must therefore be explicitly trained o...
-
[8]
METHODOLOGY I: THE KS-PRET-5M TEXT CORPUS PIPELINE The efficacy and linguistic fidelity of any synthetic OCR dataset are fundamentally contingent upon the quality and representativeness of its underlying text corpus. For the Koshur Pixel dataset, the foundation is the KS-PRET-5M corpus [ 2], which stands as the most extensive and meticulously cleaned colle...
-
[9]
was assembled from diverse digitized sources, including historical archives, literary texts, news articles, and web-crawled content. Owing to substantial heterogeneity in encoding standards, orthographic conventions, and document quality, the raw corpus underwent an extensive eleven-stage normalization pipeline designed to maximize linguistic consistency ...
-
[10]
METHODOLOGY II: THE SYNTHOCR-GEN RENDERING ENGINE The second, and arguably most critical, phase in the construction of the Koshur Pixel dataset involves the high-fidelity rendering of the cleaned Unicode text from the KS-PRET-5M corpus into visual images. This process is executed by the SynthOCR-Gen pipeline [ 1], a specialized, fully client-side and brow...
-
[11]
METHODOLOGY III: ADV ANCED VISUAL AUGMENT A TION SUITE A critical challenge in the development of synthetic datasets for computer vision, particularly for OCR, is the ”synthetic-to-real” gap. This phenomenon refers to the performance degradation observed when a model trained exclusively on clean, artificially generated images is deployed in real-world sce...
-
[12]
DA T ASET ST A TISTICS, DIVERSITY, AND PURITY ANAL YSIS The Koshur Pixel dataset, generated through the meticulously designed pipeline described in Sections 4, 5, and 6, comprises a total of 613,078 high-fidelity image-text pairs. This section provides a comprehensive statistical and qualitative analysis of the dataset, highlighting its scale, linguistic ...
-
[13]
DISCUSSION: SOCIO-TECHNICAL IMP ACT, USE CASES, AND COMPUTE BARRIERS The creation and release of the Koshur Pixel dataset represent a significant milestone in the digital trajectory of the Kashmiri language. Beyond its immediate utility as a machine learning resource, this work has profound socio-technical implications, enabling new applications while als...
-
[14]
for kashmiri to disambiguate visually similar words based on context). 8.3. The Compute Constraint: A New Barrier While Koshur Pixel effectively dismantles the ”data barrier” for Kashmiri OCR, it simultaneously highlights a new, formidable challenge: the ”compute barrier. ” Training or even fine-tuning state-of-the-art deep learning models on a dataset of...
-
[15]
CONCLUSION AND FUTURE WORK In this paper, we have presented Koshur Pixel , a groundbreaking and meticulously constructed large-scale synthetic OCR dataset specifically tailored for the Kashmiri language. By generating 613,078 high-fidelity image-text pairs, we have successfully provided a critical and unprecedented resource that effectively breaks the lon...
-
[16]
Generative Handwriting Synthesis: A significant challenge remains in recognizing Kashmiri handwriting, which exhibits even greater variability than printed text. We plan to explore the development of advanced generative models, such as Diffusion models or Generative Adversarial Networks (GANs), to synthesize realistic Kashmiri handwriting based on Unicode...
-
[17]
End-to-End Document Understanding: While Koshur Pixel includes page-level renders, real-world historical documents often feature highly complex and non-standard layouts, including marginalia, stamps, watermarks, and multi-column poetry. Future work will focus on expanding the dataset to include more diverse and challenging document layouts, and subsequent...
-
[18]
We will investigate how models trained on the Perso-Arabic Koshur Pixel dataset can be adapted or transferred to recognize these other scripts
Cross-Script and Cross-Lingual T ransfer Learning: Kashmiri is also written in the Devanagari script (primarily by Kashmiri Pandits) and historically in the Sharada script. We will investigate how models trained on the Perso-Arabic Koshur Pixel dataset can be adapted or transferred to recognize these other scripts. Furthermore, we will explore the potenti...
-
[19]
H. N. Malik, K. M. Shafi, and T. A. Reshi, “Synthocr-gen: A synthetic ocr dataset generator for low-resource languages- breaking the data barrier,” arXiv preprint arXiv:2601.16113, 2026
arXiv 2026
-
[20]
Ks-pret-5m: A 5 million word, 12 million token kashmiri pretraining dataset,
H. N. Malik and N. Nissar, “Ks-pret-5m: A 5 million word, 12 million token kashmiri pretraining dataset,” arXiv preprint arXiv:2604.11066, 2026
Pith/arXiv arXiv 2026
-
[21]
UNESCO, Atlas of the world’s languages in danger, https://en.unesco.org/languages- atlas, Accessed: 2026-06-19
2026
-
[22]
wikipedia
Wikipedia contributors, Inpage, https : / / en . wikipedia . org / wiki / InPage, Accessed: 2026-06-20, 2026
2026
-
[23]
Recovering the lost generation: A robust inpage-to-unicode converter for kashmiri,
H. N. Malik, “Recovering the lost generation: A robust inpage-to-unicode converter for kashmiri,” Journal of Digital Humanities and Linguistic Preservation , vol. 12, no. 4, pp. 45–58, 2024
2024
-
[24]
Historical review of ocr research and development,
S. Mori, C. Y. Suen, and K. Yamamoto, “Historical review of ocr research and development,” Proceedings of the IEEE , vol. 80, no. 7, pp. 1029–1058, 1992. doi: 10.1109/5.156468
-
[25]
Hidden markov model based optical character recognition in the presence of deterministic transformations,
S.-L. Kuo and O. E. Agazzi, “Hidden markov model based optical character recognition in the presence of deterministic transformations,” Pattern Recognition , vol. 26, no. 12, pp. 1813–1826, 1993. doi: 10 . 1016 / 0031 - 3203(93)90178-Y
1993
-
[26]
A. Graves, S. Fernández, F. Gomez, and J. Schmidhuber, “Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks,” in Proceedings of the 23rd International Conference on Machine Learning , 2006, pp. 369–376. doi: 10.1145/1143844.1143891
-
[28]
Trocr: Transformer-based optical character recognition with pre-trained models,
M. Li et al., “Trocr: Transformer-based optical character recognition with pre-trained models,” arXiv preprint arXiv:2109.10282, 2021. doi: 10. 48550/arXiv.2109.10282 arXiv: 2109.10282 [cs.CL]
arXiv 2021
-
[29]
Design Initiative for a 10 TeV pCM Wakefield Collider,
G. Kim et al., “Ocr-free document understanding transformer,” arXiv preprint arXiv:2111.15664, 2021. doi: 10.48550/arXiv. 2111.15664 arXiv: 2111.15664 [cs.LG]
work page internal anchor Pith review doi:10.48550/arxiv 2021
-
[30]
Synthetic data for text localisation in natural images,
A. Gupta, A. Vedaldi, and A. Zisserman, “Synthetic data for text localisation in natural images,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2016
2016
-
[31]
kashmirilanguage
Kashmiri Language, Kashmiri language fonts and resources , https : / / www . kashmirilanguage . com/ , Accessed: 2026-06-22, 2026
2026
-
[32]
Development of a unicode compliant kashmiri font: Issues 13 KOSHUR PIXEL: A LARGE-SCALE SYNTHETIC OCR DATASET FOR KASHMIRI and resolution,
A. A. Lawey and N. Mehdi, “Development of a unicode compliant kashmiri font: Issues 13 KOSHUR PIXEL: A LARGE-SCALE SYNTHETIC OCR DATASET FOR KASHMIRI and resolution,” Interdisciplinary Journal of Linguistics, vol. 4, pp. 195–200, 2011. [Online]. A vailable: https : / / linguistics . uok . edu . in / Files / f6ec3740 - 422d - 4ac1 - 9f52 - ddfe2cffcb28 / J...
2011
-
[33]
Paligemma: A versatile 3b vlm for transfer,
L. Beyer et al., “Paligemma: A versatile 3b vlm for transfer,” arXiv preprint arXiv:2407.07726 ,
-
[34]
doi: 10.48550/arXiv.2407.07726 arXiv: 2407.07726 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.07726
-
[35]
Indicbert: A monolingual and multilingual benchmark for indic languages,
D. Kakwani et al., “Indicbert: A monolingual and multilingual benchmark for indic languages,” in Findings of the Association for Computational Linguistics: EMNLP , 2020
2020
-
[36]
An overview of the tesseract ocr engine,
R. Smith, “An overview of the tesseract ocr engine,” in Ninth International Conference on Document Analysis and Recognition (ICDAR) , 2007
2007
-
[37]
Koshur diacritizer: A byte-level sequence-to-sequence model for kashmiri diacritic restoration,
H. N. Malik, N. Nissar, and F. Iqbal, “Koshur diacritizer: A byte-level sequence-to-sequence model for kashmiri diacritic restoration,” arXiv preprint arXiv:2606.15883 , 2026. arXiv: 2606. 15883 [cs.CL] . [Online]. A vailable: https : / / arxiv.org/abs/2606.15883 A. VISUAL SAMPLES AND DA T ASET DIVERSITY This appendix provides a comprehensive visual overv...
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.