Learning Asynchronous Upper-body Task-space Trajectory Tracking Policy for Humanoid Robots
Pith reviewed 2026-06-25 21:06 UTC · model grok-4.3
The pith
Conditioning a humanoid policy on cached future trajectories and an execution-time index enables accurate upper-body tracking at low planner update rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
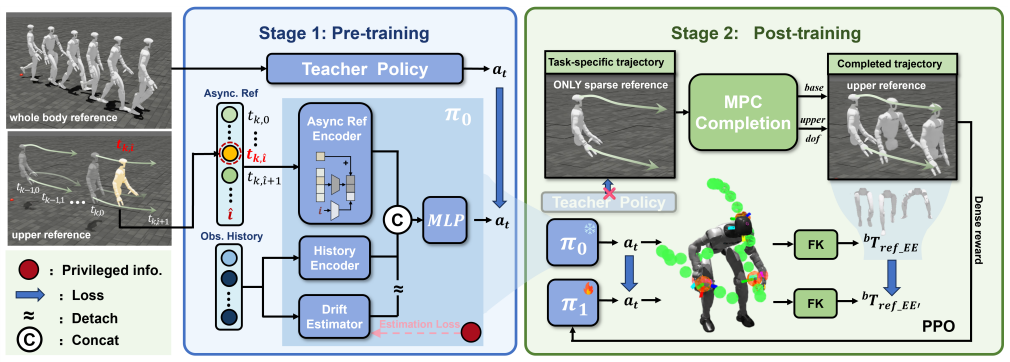
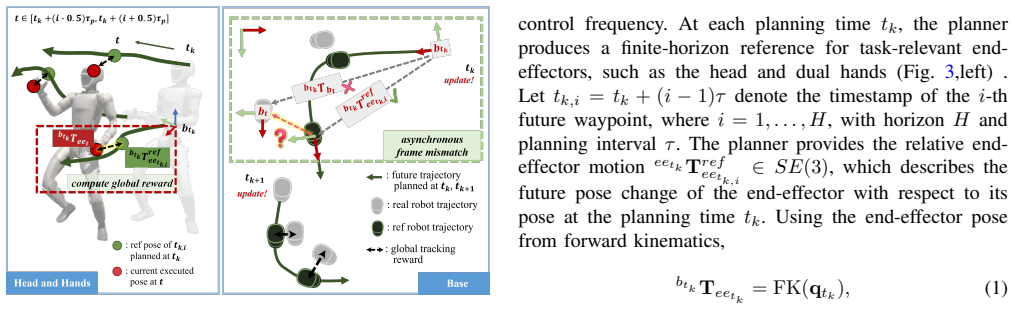
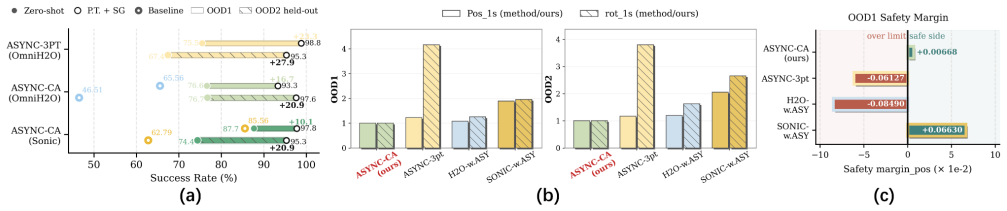
The authors introduce an asynchronous upper body task-space tracking framework in which a student policy, initialized by teacher-student distillation, receives the full cached future trajectory and an execution-time index as conditioning. Training employs a sliding-window global reward to reduce frame drift without explicit frame estimation. For task-specific refinement an MPC module converts sparse references into floating-base and upper-body guidance while action-level and forward-kinematics self-guidance terms limit policy drift. Simulation and Unitree G1 hardware results show improved tracking under low update rates, stronger performance relative to synchronous and decoupled baselines, a
What carries the argument
Student policy conditioned on the full cached future trajectory and execution-time index, trained with a sliding-window global reward.
If this is right
- Tracking accuracy improves when high-level planners update at low rates.
- Performance exceeds that of synchronous and decoupled baseline controllers.
- The policy adapts more safely to motions outside the training distribution.
- MPC-based guidance combined with self-guidance at action and kinematics levels keeps the policy from diverging.
Where Pith is reading between the lines
- The same conditioning and reward structure could be applied to lower-body policies to achieve full-body asynchronous tracking.
- Explicit frame alignment modules may become unnecessary if global rewards are shaped over sliding windows.
- The framework suggests planners could safely run at slower rates or on cheaper hardware without sacrificing execution quality.
Load-bearing premise
The method assumes that feeding the cached future trajectory and execution index together with the sliding-window reward will reliably stop frame drift and policy divergence even when planner updates are sparse and the motion is out-of-distribution.
What would settle it
Deploy the learned policy on the Unitree G1 while deliberately lowering planner update frequency below the rates tested in the paper and measure whether task-space tracking error grows beyond the reported bounds.
Figures




read the original abstract
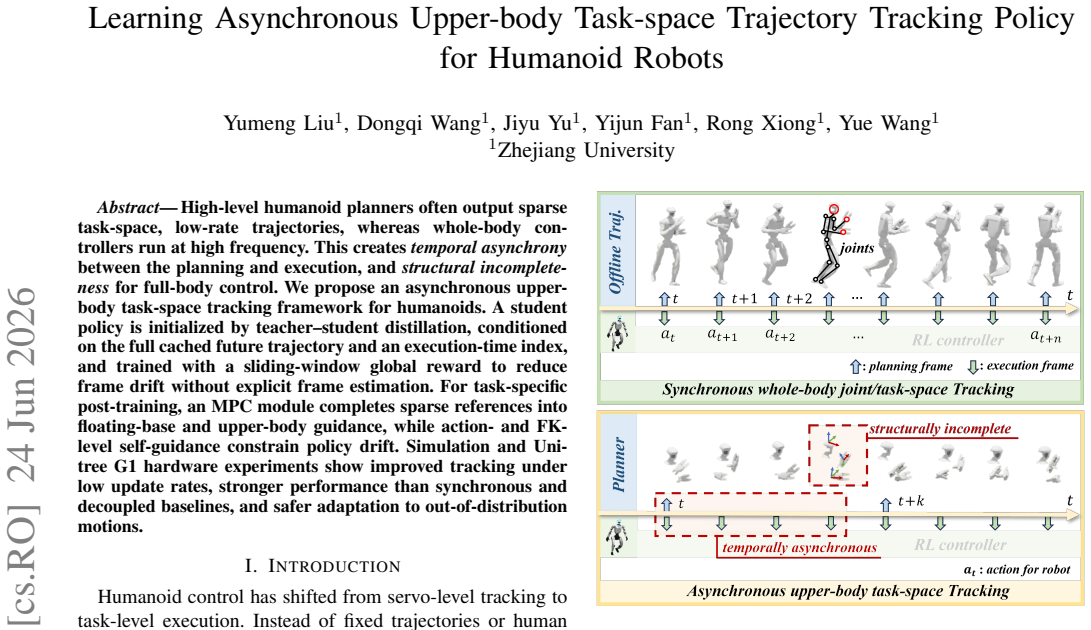
High-level humanoid planners often output sparse task-space, low-rate trajectories, whereas whole-body controllers run at high frequency. This creates temporal asynchrony between the planning and execution, and structural incompleteness for full-body control. We propose an asynchronous upper body task-space tracking framework for humanoids. A student policy is initialized by teacher-student distillation, conditioned on the full cached future trajectory and an execution-time index, and trained with a sliding-window global reward to reduce frame drift without explicit frame estimation. For task-specific post-training, an MPC module completes sparse references into floating-base and upper-body guidance, while action- and FK level self-guidance constrain policy drift. Simulation and Unitree G1 hardware experiments show improved tracking under low update rates, stronger performance than synchronous and decoupled baselines, and safer adaptation to out-of-distribution motions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an asynchronous upper-body task-space trajectory tracking framework for humanoid robots. A student policy is initialized via teacher-student distillation and conditioned on the full cached future trajectory plus an execution-time index; it is trained with a sliding-window global reward to reduce frame drift without explicit estimation. Post-training uses an MPC module to complete sparse references into floating-base and upper-body guidance, together with action- and FK-level self-guidance to constrain drift. Simulation and Unitree G1 hardware experiments are reported to demonstrate improved tracking under low update rates, stronger performance than synchronous and decoupled baselines, and safer adaptation to out-of-distribution motions.
Significance. If the empirical results hold, the work addresses a practical gap between sparse high-level planning and high-frequency whole-body control in humanoids. The combination of distillation-based initialization, trajectory conditioning, sliding-window rewards, MPC completion, and multi-level self-guidance offers a concrete method for drift mitigation that could improve robustness in real-world asynchronous settings.
minor comments (2)
- [Abstract] Abstract: the claims of 'improved tracking' and 'stronger performance' are stated without any numerical values, error metrics, or statistical comparisons; adding one or two key quantitative results would make the summary more informative.
- The description of the teacher policy and the exact distillation procedure would benefit from additional implementation details (e.g., loss weights, data collection protocol) to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The referee's description of the framework, including teacher-student distillation, trajectory conditioning, sliding-window rewards, MPC completion, and multi-level self-guidance, accurately reflects the manuscript. No major comments were provided in the report.
Circularity Check
No circularity in empirical framework
full rationale
The manuscript presents an empirical robotics learning method: teacher-student distillation initializes a student policy conditioned on cached trajectories and an index, trained via sliding-window reward plus MPC/self-guidance modules. All central claims (improved asynchronous tracking, robustness to low rates and OOD motions) rest on simulation and Unitree G1 hardware experiments that directly measure the stated conditions. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear that would reduce any result to its inputs by construction. The approach is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Learning human-to-humanoid real-time whole-body teleoperation,
T. Heet al., “Learning human-to-humanoid real-time whole-body teleoperation,” inIEEE/RSJ International Conference on Intelligent Robots and Systems, 2024
2024
-
[2]
GMT: General motion tracking for humanoid whole- body control,
Z. Chenet al., “GMT: General motion tracking for humanoid whole- body control,”arXiv preprint arXiv:2506.14770, 2025
arXiv 2025
-
[3]
Hover: Versatile neural whole-body controller for humanoid robots,
T. Heet al., “Hover: Versatile neural whole-body controller for humanoid robots,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025
2025
-
[4]
Hiwet: Hierarchical world-frame end-effector tracking for long-horizon humanoid loco-manipulation,
Z. Caoet al., “Hiwet: Hierarchical world-frame end-effector tracking for long-horizon humanoid loco-manipulation,” inRobotics: Science and Systems (RSS), 2026, accepted
2026
-
[5]
Learning humanoid end-effector control for open-vocabulary visual loco-manipulation,
R. Dong, Z. Li, X. He, and S. Gupta, “Learning humanoid end-effector control for open-vocabulary visual loco-manipulation,”arXiv preprint arXiv:2602.16705, 2026
Pith/arXiv arXiv 2026
-
[6]
GR00T N1: An open foundation model for generalist humanoid robots,
NVIDIAet al., “GR00T N1: An open foundation model for generalist humanoid robots,”arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[7]
AgiBot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems,
Q. Buet al., “AgiBot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025
2025
-
[8]
Towards bridging the gap between large-scale pre- training and efficient finetuning for humanoid control,
W. Huanget al., “Towards bridging the gap between large-scale pre- training and efficient finetuning for humanoid control,” inInternational Conference on Learning Representations (ICLR), 2026
2026
-
[9]
Unlocking in-the-wild loco-manipulation with robot- free egocentric demonstration,
M. Shiet al., “Unlocking in-the-wild loco-manipulation with robot- free egocentric demonstration,” inRobotics: Science and Systems (RSS), 2026, accepted
2026
-
[10]
Ψ 0: An open foundation model towards universal hu- manoid loco-manipulation,
S. Weiet al., “Ψ 0: An open foundation model towards universal hu- manoid loco-manipulation,” inRobotics: Science and Systems (RSS), 2026, accepted
2026
-
[11]
SONIC: Supersizing motion tracking for natural hu- manoid whole-body control,
Z. Luoet al., “SONIC: Supersizing motion tracking for natural hu- manoid whole-body control,”arXiv preprint arXiv:2511.07820, 2025
Pith/arXiv arXiv 2025
-
[12]
Trajbooster: Boosting humanoid whole-body manip- ulation via trajectory-centric learning,
J. Liuet al., “Trajbooster: Boosting humanoid whole-body manip- ulation via trajectory-centric learning,” in2026 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2026
2026
-
[13]
Openvla: An open-source vision-language-action model,
M. J. Kimet al., “Openvla: An open-source vision-language-action model,” inProceedings of The 8th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, P. Agrawal, O. Kroemer, and W. Burgard, Eds., vol. 270. PMLR, 06–09 Nov 2025, pp. 2679– 2713
2025
-
[14]
π 0.5: a vision-language-action model with open- world generalization,
K. Blacket al., “π 0.5: a vision-language-action model with open- world generalization,” inProceedings of The 9th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, J. Lim, S. Song, and H.-W. Park, Eds., vol. 305. PMLR, 27–30 Sep 2025, pp. 17–40
2025
-
[15]
Wholebodyvla: Towards unified latent vla for whole-body loco-manipulation control,
H. Jianget al., “Wholebodyvla: Towards unified latent vla for whole-body loco-manipulation control,” inInternational Conference on Learning Representations (ICLR), 2026
2026
-
[16]
HOMIE: Humanoid loco-manipulation with isomor- phic exoskeleton cockpit,
Q. Benet al., “HOMIE: Humanoid loco-manipulation with isomor- phic exoskeleton cockpit,” inProceedings of Robotics: Science and Systems, Los Angeles, CA, USA, June 2025
2025
-
[17]
Humanoid manipulation interface: Humanoid whole- body manipulation from robot-free demonstrations,
R. Naiet al., “Humanoid manipulation interface: Humanoid whole- body manipulation from robot-free demonstrations,”arXiv preprint arXiv:2602.06643, 2026
arXiv 2026
-
[18]
REFINE-DP: Diffusion policy fine-tuning for hu- manoid loco-manipulation via reinforcement learning,
Z. Guet al., “REFINE-DP: Diffusion policy fine-tuning for hu- manoid loco-manipulation via reinforcement learning,”arXiv preprint arXiv:2603.13707, 2026
arXiv 2026
-
[19]
Exbody2: Advanced expressive humanoid whole-body control,
M. Jiet al., “Exbody2: Advanced expressive humanoid whole-body control,” in2026 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2026
2026
-
[20]
FRoM-W1: Towards general humanoid whole-body control with language instructions,
P. Liet al., “FRoM-W1: Towards general humanoid whole-body control with language instructions,”arXiv preprint arXiv:2601.12799, 2026
arXiv 2026
-
[21]
Towards adaptive humanoid control via multi-behavior distillation and reinforced fine-tuning,
Y . Zhaoet al., “Towards adaptive humanoid control via multi-behavior distillation and reinforced fine-tuning,” inProceedings of the AAAI Conference on Artificial Intelligence, 2026
2026
-
[22]
General humanoid whole-body control via pretraining and fast adaptation,
Z. Wanget al., “General humanoid whole-body control via pretraining and fast adaptation,”arXiv preprint arXiv:2602.11929, 2026
arXiv 2026
-
[23]
PPF: Pre-training and preservative fine-tuning of humanoid locomotion via model-assumption-based regularization,
H. Junget al., “PPF: Pre-training and preservative fine-tuning of humanoid locomotion via model-assumption-based regularization,” IEEE Robotics and Automation Letters, 2025
2025
-
[24]
Omnih2o: Universal and dexterous human-to-humanoid whole-body teleoperation and learning,
T. Heet al., “Omnih2o: Universal and dexterous human-to-humanoid whole-body teleoperation and learning,” inProceedings of The 8th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, P. Agrawal, O. Kroemer, and W. Burgard, Eds., vol. 270. PMLR, 06–09 Nov 2025, pp. 1516–1540
2025
-
[25]
Object motion guided human motion synthesis,
J. Li, J. Wu, and C. K. Liu, “Object motion guided human motion synthesis,”ACM Transactions on Graphics, vol. 42, no. 6, pp. 197:1– 197:11, 2023
2023
-
[26]
GRAB: A dataset of whole-body human grasping of objects,
O. Taheri, N. Ghorbani, M. J. Black, and D. Tzionas, “GRAB: A dataset of whole-body human grasping of objects,” inEuropean Conference on Computer Vision, 2020, pp. 581–600
2020
-
[27]
Hold my beer: Learning gentle humanoid locomotion and end-effector stabilization control,
Y . Liet al., “Hold my beer: Learning gentle humanoid locomotion and end-effector stabilization control,” inConference on Robot Learning (CoRL), 2025, poster
2025
-
[28]
Mobile-television: Predictive motion priors for humanoid whole-body control,
C. Luet al., “Mobile-television: Predictive motion priors for humanoid whole-body control,” in2025 IEEE International Conference on Robotics and Automation (ICRA), 2025, pp. 5364–5371. APPENDIXI MPC FORMULATION We adopt an OCS2-based kinematic MPC formulation to complete the sparse upper-body reference with floating-base and upper-body joint guidance. At ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.