Scaling limit of the Random Language Model
Pith reviewed 2026-06-29 01:53 UTC · model grok-4.3
The pith
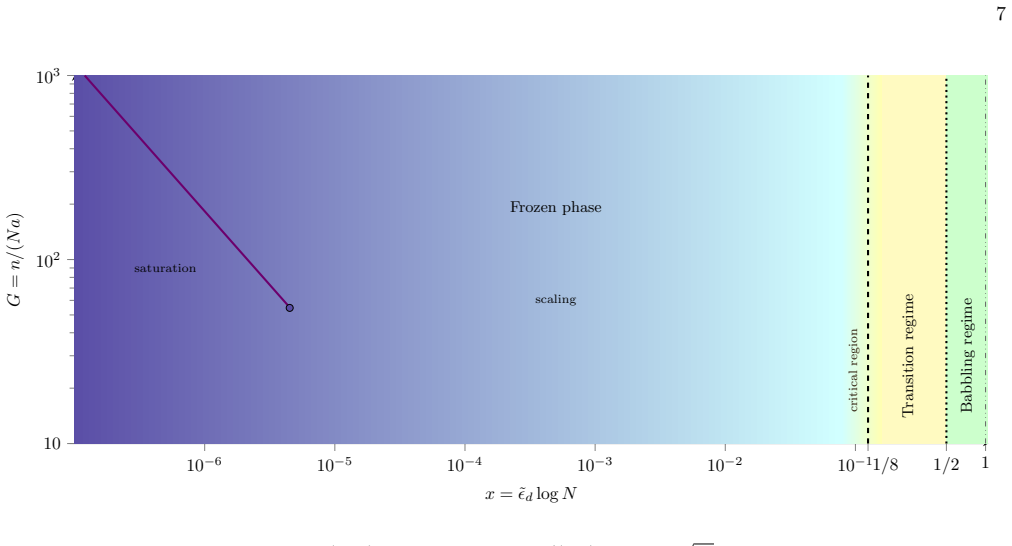
The Random Language Model condenses at a critical scaled temperature x=1/8, making language statistics depend on corpus length below that point.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
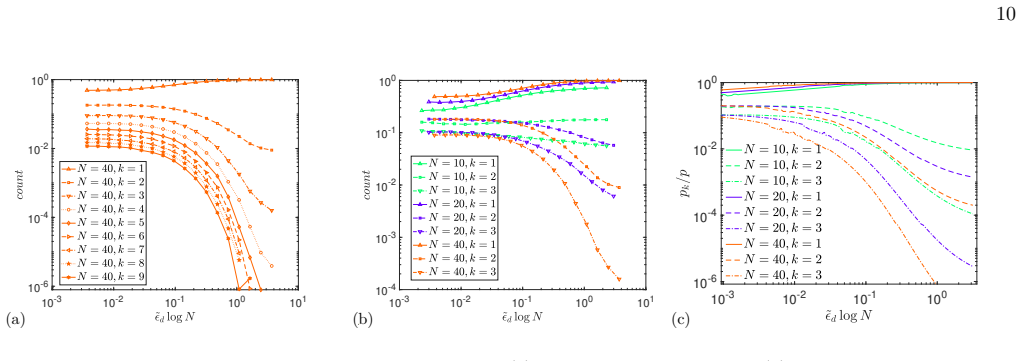
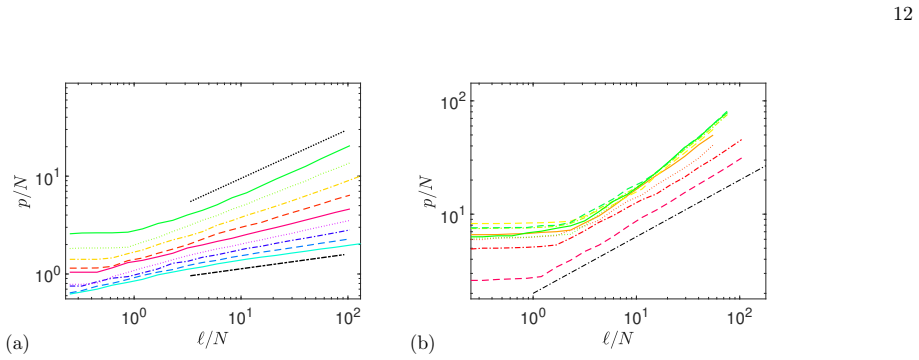
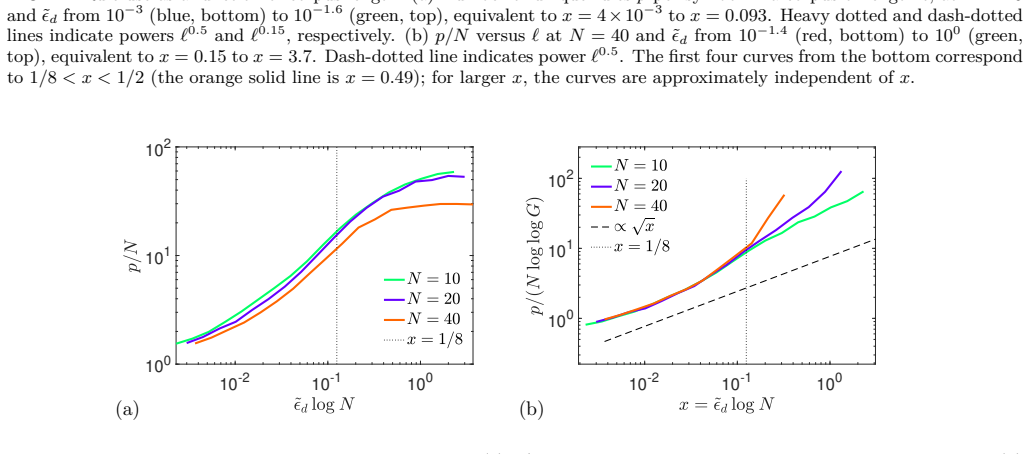
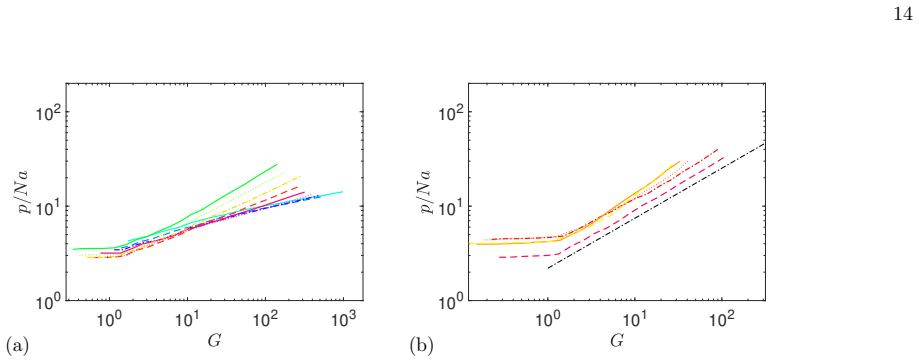
In the scaling limit defined by N to infinity and tilde-epsilon_d to zero at fixed x equals tilde-epsilon_d times log N, the Random Language Model is described by a large-deviation principle over rule-usage patterns; a semi-annealed approximation then maps it to random energy models with nontrivial combinatorics, revealing a condensation transition at x_c=1/8 below which rule usage concentrates and language statistics depend nontrivially on corpus length, plus a second characteristic scale at x=1/2 marking the onset of entropy reduction, with explicit scaling laws for observables in the scaling, saturation, and critical regimes.
What carries the argument
The scaled temperature x equals tilde-epsilon_d log N together with the large-deviation principle over rule-usage patterns and its semi-annealed mapping to random energy models.
If this is right
- Below x=1/8 rule usage concentrates and language statistics acquire a nontrivial dependence on corpus length.
- Explicit scaling laws hold for the number of distinct rules, entropy, and related observables in distinct regimes controlled by grammar size, corpus length, and temperature.
- The slow approach to the large-N limit is explained by the dependence on log N.
- Universal statistical properties of language emerge from typical realizations of generative grammars.
Where Pith is reading between the lines
- If the condensation transition controls natural language, then statistics extracted from corpora of different sizes should show the same nontrivial length dependence predicted for x below 1/8.
- The same scaling framework could be used to analyze whether finite training data in other generative models produces analogous concentration of rule-like structures.
- Numerical checks at moderate N could confirm or rule out the location of the transition by measuring how the effective number of rules scales with log N at fixed x.
Load-bearing premise
The semi-annealed approximation maps the problem to random energy models and the large-deviation principle over rule-usage patterns gives a controlled description in the scaling limit.
What would settle it
Simulations of finite but large N grammars that check whether the fraction of distinct rules used and the entropy exhibit the predicted sharp change exactly at x=1/8 when corpus length is varied.
Figures
read the original abstract
We develop a quantitative theory of the Random Language Model (RLM), an ensemble of stochastic context-free grammars, in a scaling limit where the number of hidden symbols $N \to \infty$ while the grammar temperature $\tilde{\epsilon}_d \to 0$ at fixed $x = {\tilde\epsilon}_d \log N$. In this limit, the model admits a controlled description based on a large-deviation principle over rule-usage patterns. A semi-annealed approximation maps the problem to a class of Random Energy Models with nontrivial combinatorics. We show that the RLM exhibits a condensation transition at a critical value $x_c=1/8$, below which rule usage concentrates and language statistics acquire a nontrivial dependence on corpus length. A second characteristic scale at $x=1/2$ marks the onset of entropy reduction from its maximal value. Across these regimes, we derive explicit scaling laws for the number of distinct rules, entropy, and related observables, identifying distinct scaling, saturation, and critical regimes controlled by the interplay of grammar size, corpus length, and temperature. The theory resolves previous ambiguities regarding the existence of a thermodynamic transition and explains the slow approach to the large-$N$ limit as a consequence of the dependence on $\log N$. It further provides a unified framework in which universal statistical properties of language emerge from typical realizations of generative grammars, with implications for both natural language statistics and the behavior of large language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a quantitative theory of the Random Language Model (RLM), an ensemble of stochastic context-free grammars, in the scaling limit N→∞ with grammar temperature ilde{\epsilon}_d→0 at fixed x= ilde{\epsilon}_d log N. It employs a large-deviation principle over rule-usage patterns together with a semi-annealed approximation that maps the problem to a class of Random Energy Models with nontrivial combinatorics. The central results are a condensation transition at x_c=1/8 (below which rule usage concentrates and language statistics depend nontrivially on corpus length) and a second scale at x=1/2 marking the onset of entropy reduction; explicit scaling laws are derived for the number of distinct rules, entropy, and related observables across scaling, saturation, and critical regimes.
Significance. If the semi-annealed mapping and LDP control are valid, the work supplies a controlled analytic framework that resolves prior ambiguities about the existence of a thermodynamic transition in the RLM and accounts for the slow approach to the large-N limit via explicit log N dependence. It identifies universal statistical properties emerging from typical realizations of generative grammars, with direct implications for natural-language statistics and the behavior of large language models. The parameter-free character of the derived transition points and scaling laws (once the approximation is accepted) is a notable strength.
major comments (2)
- [Mapping to Random Energy Models and LDP control] The precise location of the condensation transition at x_c=1/8 and the distinction among the three regimes (x<1/8, 1/8<x<1/2, x>1/2) rest on the semi-annealed approximation and the assertion that the large-deviation rate function remains controlled in the joint limit. The manuscript must supply explicit error bounds or a dominance argument showing that combinatorial prefactors and approximation corrections do not shift the saddle or the critical value; without this, the claimed exact value x_c=1/8 is not yet secured.
- [Derivation of scaling laws] The abstract states that the description is “controlled,” yet the justification that the semi-annealed saddle remains dominant across the relevant scaling regimes is not accompanied by uniform error estimates. This is load-bearing for the claim that language statistics acquire a nontrivial corpus-length dependence only below x_c=1/8.
minor comments (2)
- Notation for the scaled temperature x and the hidden-symbol count N should be introduced with a single consistent definition early in the text to avoid repeated re-explanation.
- The abstract refers to “explicit scaling laws” for entropy and rule counts; a brief table summarizing the three regimes and their leading scalings would improve readability.
Simulated Author's Rebuttal
We thank the referee for the thorough review and for identifying key points regarding the rigor of our approximations. We respond to the major comments below.
read point-by-point responses
-
Referee: [Mapping to Random Energy Models and LDP control] The precise location of the condensation transition at x_c=1/8 and the distinction among the three regimes (x<1/8, 1/8<x<1/2, x>1/2) rest on the semi-annealed approximation and the assertion that the large-deviation rate function remains controlled in the joint limit. The manuscript must supply explicit error bounds or a dominance argument showing that combinatorial prefactors and approximation corrections do not shift the saddle or the critical value; without this, the claimed exact value x_c=1/8 is not yet secured.
Authors: We acknowledge that the manuscript does not contain explicit error bounds or a full dominance argument for the semi-annealed mapping and LDP control. The value x_c=1/8 is obtained directly from the saddle-point equation of the mapped REM after applying the large-deviation rate function; combinatorial prefactors enter only as sub-exponential corrections that do not shift the leading saddle in the scaling limit. Nevertheless, a rigorous uniform bound on the approximation error across the joint limit is absent from the present analysis. revision: no
-
Referee: [Derivation of scaling laws] The abstract states that the description is “controlled,” yet the justification that the semi-annealed saddle remains dominant across the relevant scaling regimes is not accompanied by uniform error estimates. This is load-bearing for the claim that language statistics acquire a nontrivial corpus-length dependence only below x_c=1/8.
Authors: The term “controlled” in the abstract refers to the fact that all scaling laws follow from a single saddle-point evaluation once the semi-annealed mapping is accepted. We agree that uniform error estimates justifying dominance of this saddle in every regime are not supplied. A brief clarifying paragraph can be added to the discussion section stating the assumptions under which the mapping holds, but deriving the requested bounds lies outside the scope of the current work. revision: partial
- Explicit error bounds or dominance arguments for the semi-annealed approximation and LDP control in the joint scaling limit
Circularity Check
No circularity; central claims follow from stated semi-annealed mapping and LDP without reduction to inputs
full rationale
The derivation proceeds by introducing a semi-annealed approximation that maps the RLM to a REM class, then invoking an LDP over rule-usage patterns to locate x_c=1/8 and the x=1/2 scale. These steps are presented as controlled approximations whose outputs (condensation transition, scaling laws) are derived quantities rather than inputs. No self-definitional loop, fitted parameter renamed as prediction, or load-bearing self-citation chain appears in the provided text. The result is therefore independent of its own conclusions and scores at the low end of the range.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Large-deviation principle over rule-usage patterns holds in the scaling limit
- ad hoc to paper Semi-annealed approximation is valid for mapping to Random Energy Models with nontrivial combinatorics
Reference graph
Works this paper leans on
-
[1]
= 2 ℓ − m, so that Ztree ≡ Q i P(Ti|G) = pℓ E(1 − pE)2ℓ−mZ −m tree just gives a trivial factor. The first result of [ 19] is that Z(G; m, ℓ) has a field- theoretic representation in terms of two complex scalar 2 The idea to relate belief propagation equations to the Random Energy Model is due to Alessio Giorlandino and Sebastian Goldt. ‘fields’ La, Ra, a ...
-
[2]
Entropy in the frozen region: In the frozen regime we have log z = log k∗ + 3 2k∗ − log(p/N) = log(3/2) − log log α + log α − log(p/N) = C − log a + Fz(log G2/3) with C = 2 log(3/2) − 1 2 log(2πe3) and Fz(L) = −2 log log α + log α − 3L 1 + α (59) We also have p n log e/v = 2 3 a √ 2πe3 log(α)Gβ(G) N n 1 − 1 1 + α log G = Fp(log G2/3) with Fp(L) = 2 3 √ 2π...
-
[3]
We have log z = − log a − 3 k∗ − a +
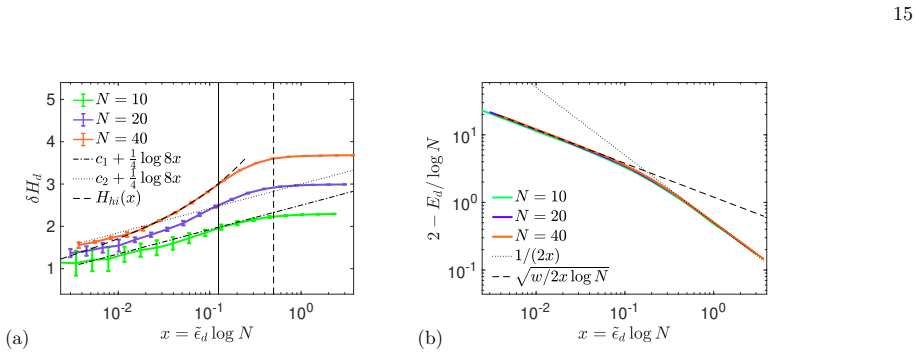
Entropy in the critical region: For x < 1/8 but close to 1/8 we obtain another con- tribution from the singularity at x = 1/8. We have log z = − log a − 3 k∗ − a + . . . with k∗ ≈ 3 4 + 1 2 a + 1 2 q a2 + a + 9 4 . Then we get (with a ∼ √ 8x/β) Hd(ℓ∞) ≈ 1 4 log 8x + 3k∗/2 (k∗ − √ 8x)2 + const x ≈ 1/8 (64) Call this prediction Hhi(x). It predicts the obser...
-
[4]
babbling
Entropy in the transition region: In the transition regime we need both log z and the p/n terms. We have, in the scaling limit, − log z + (p/n) log(e/v) = 1 + χ log N + . . . so that Hd(ℓ∞) ≈ 1 − 1 8x log N + 1 2 1/8 < x < 1/2 independent of ℓ∞ in this approximation. This result is very interesting as it implies a change of scaling Hd ∼ log N for x > 1/8 ...
2020
-
[5]
G. K. Zipf, The psycho-biology of language: An intro- duction to dynamic philology (Routledge, Milton Park, 2013)
2013
-
[6]
H. S. Heaps, Information retrieval: Computational and theoretical aspects (Academic Press, Inc., 1978)
1978
-
[7]
Shannon and W
C. Shannon and W. Weaver, The Mathematical Theory of Communication , 1st ed. (University of Illinois Press, Urbana, Illinois, USA, 1964)
1964
-
[8]
C. E. Shannon, Bell system technical journal 30, 50 (1951)
1951
-
[9]
Schürmann and P
T. Schürmann and P. Grassberger, Chaos: An Interdis- ciplinary Journal of Nonlinear Science 6, 414 (1996)
1996
-
[10]
A. M. Petersen, J. N. Tenenbaum, S. Havlin, H. E. Stan- ley, and M. Perc, Scientific reports 2, 943 (2012)
2012
-
[11]
Ferrer i Cancho and R
R. Ferrer i Cancho and R. V. Solé, Journal of Quantita- tive Linguistics 8, 165 (2001)
2001
-
[12]
Corominas-Murtra and R
B. Corominas-Murtra and R. V. Solé, Physical Review E 82, 011102 (2010)
2010
-
[13]
Corral, G
A. Corral, G. Boleda, and R. Ferrer-i Cancho, PloS one 10, e0129031 (2015)
2015
-
[14]
Bentz, D
C. Bentz, D. Alikaniotis, M. Cysouw, and R. Ferrer-i Cancho, Entropy 19, 275 (2017). 18
2017
-
[15]
Chomsky, Syntactic structures (Walter de Gruyter, Berlin, 2002)
N. Chomsky, Syntactic structures (Walter de Gruyter, Berlin, 2002)
2002
-
[16]
Chomsky, Aspects of the Theory of Syntax , Vol
N. Chomsky, Aspects of the Theory of Syntax , Vol. 11 (MIT press, Cambridge, 2014)
2014
-
[17]
Chomsky, The minimalist program (MIT press, 2014)
N. Chomsky, The minimalist program (MIT press, 2014)
2014
-
[18]
De Saussure, Course in general linguistics 1, 65 (1916)
F. De Saussure, Course in general linguistics 1, 65 (1916)
1916
-
[19]
Jurafsky and J
D. Jurafsky and J. H. Martin, Computational Linguistics, and Speech Recognition, Prentice Hall 2 (2000)
2000
-
[20]
Ferrer-i Cancho, C
R. Ferrer-i Cancho, C. Gómez-Rodríguez, J. L. Esteban, and L. Alemany-Puig, Physical Review E 105, 014308 (2022)
2022
-
[21]
DeGiuli, Phys
E. DeGiuli, Phys. Rev. Lett. 122, 128301 (2019)
2019
-
[22]
J. C. Kieffer and E.-H. Yang, IEEE Transactions on In- formation Theory 46, 737 (2000)
2000
-
[23]
De Giuli, Journal of Physics A: Mathematical and Theoretical 52, 504001 (2019)
E. De Giuli, Journal of Physics A: Mathematical and Theoretical 52, 504001 (2019)
2019
-
[24]
Mézard, G
M. Mézard, G. Parisi, and M. Virasoro, Spin glass the- ory and beyond: An Introduction to the Replica Method and Its Applications , Vol. 9 (World Scientific Publishing Company, 1987)
1987
-
[25]
Nakaishi and K
K. Nakaishi and K. Hukushima, Physical Review Re- search 4, 023156 (2022)
2022
-
[26]
Lalegani and E
F. Lalegani and E. De Giuli, Physical Review E 109, 054313 (2024)
2024
-
[27]
Derrida, Physical Review Letters 45, 79 (1980)
B. Derrida, Physical Review Letters 45, 79 (1980)
1980
-
[28]
Derrida, Phys
B. Derrida, Phys. Rev. B 24, 2613 (1981)
1981
-
[29]
Phase struc- ture of the random language model,
A. Giorlandino, E. D. Giuli, and S. Goldt, “Phase struc- ture of the random language model,” (2026)
2026
-
[30]
T. L. Booth, in 10th annual symposium on switching and Automata Theory (swat 1969) (IEEE, 1969) pp. 74–81
1969
-
[31]
C. S. Wetherell, ACM Computing Surveys (CSUR) 12, 361 (1980)
1980
-
[32]
Mézard and A
M. Mézard and A. Montanari, Information, physics, and computation (Oxford University Press, 2009)
2009
-
[33]
De Giuli, Journal of Physics A: Mathematical and Theoretical 55, 489501 (2022)
E. De Giuli, Journal of Physics A: Mathematical and Theoretical 55, 489501 (2022)
2022
-
[34]
Ben Arous, L
G. Ben Arous, L. V. Bogachev, and S. A. Molchanov, Probability theory and related fields 132, 579 (2005)
2005
-
[35]
J. M. Kosterlitz and D. J. Thouless, Journal of Physics C: Solid State Physics 6, 1181 (1973)
1973
-
[36]
Kosterlitz, Journal of Physics C: Solid State Physics 7, 1046 (1974)
J. Kosterlitz, Journal of Physics C: Solid State Physics 7, 1046 (1974)
1974
-
[37]
Zinn-Justin, Quantum field theory and critical phe- nomena (Clarendon Press, 1996)
J. Zinn-Justin, Quantum field theory and critical phe- nomena (Clarendon Press, 1996)
1996
-
[38]
P. M. Chaikin and T. C. Lubensky, Principles of Con- densed Matter Physics (Cambridge University Press, Cambridge, U.K., 2000)
2000
-
[39]
T. M. Cover and J. A. Thomas, Elements of information theory (John Wiley & Sons, 1999)
1999
-
[40]
R. F. i Cancho and R. V. Solé, Proceedings of the Na- tional Academy of Sciences 100, 788 (2003)
2003
-
[41]
Mazzolini, J
A. Mazzolini, J. Grilli, E. De Lazzari, M. Osella, M. C. Lagomarsino, and M. Gherardi, Physical review E 98, 012315 (2018)
2018
-
[42]
Mazzolini, A
A. Mazzolini, A. Colliva, M. Caselle, and M. Osella, Physical Review E 98, 052139 (2018)
2018
-
[43]
T. OLMo, P. Walsh, L. Soldaini, D. Groeneveld, K. Lo, S. Arora, A. Bhagia, Y. Gu, S. Huang, and M. Jordan, arXiv preprint arXiv:2501.00656 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
C. Scheibner, L. M. Smith, and W. Bialek, arXiv preprint arXiv:2512.24969 (2025)
-
[45]
Nakaishi and K
K. Nakaishi and K. Hukushima, Physical Review Re- search 6, 033216 (2024)
2024
-
[46]
Y. Toji, J. Takahashi, V. Roychowdhury, and H. Miya- hara, Physical Review E 113, 015305 (2026)
2026
-
[47]
Longobardi, The handbook of contemporary syntactic theory , 562 (2001)
G. Longobardi, The handbook of contemporary syntactic theory , 562 (2001)
2001
-
[48]
Longobardi and A
G. Longobardi and A. Treves, in A Cartesian dream: A geometrical account of syntax. In honor of Andrea Moro. , Vol. Rivista di Grammatica Generativa/Research in Gen- erative Grammar., edited by M. Greco and D. Mocci (Lingbuzz Press, 2023)
2023
-
[49]
Yarahmadi, K
H. Yarahmadi, K. I. Ryom, G. Longobardi, and A. Treves, Physical Review E 113, 034312 (2026)
2026
-
[50]
Berthier and G
L. Berthier and G. Biroli, Reviews of Modern Physics 83, 587 (2011)
2011
-
[51]
Mosam, D
F. Mosam, D. Vidaurre, and E. De Giuli, Physical Re- view E 104, 024305 (2021)
2021
- [52]
-
[53]
Bernard, J.-P
M. Bernard, J.-P. Bouchaud, and P. Le Doussal, Physical Review E 113, L032101 (2026)
2026
-
[54]
Lalegani, Insights from Random Language Model , Ph.D
F. Lalegani, Insights from Random Language Model , Ph.D. thesis, Toronto Metropolitan University (2024)
2024
-
[55]
I. J. Good, The Annals of Mathematical Statistics 34, 911 (1963)
1963
-
[56]
Barvinok, Combinatorics, Probability and Computing 19, 517 (2010)
A. Barvinok, Combinatorics, Probability and Computing 19, 517 (2010). Appendix A: Counting derivations Suppose we have p rules ar → brcr, r = 1, . . . , p and q rules tr → Br. Write Mabc = X r δ(abc),(ar,br,cr), O aB = X r δ(aB),(tr,Br). (A1) The partition function Z(G; m, ℓ) then counts how many configurations can be made with this grammar. We will evalu...
2010
-
[57]
Similarly H∗L1 ≈ 2gℓ/N
Corrections to leading order To examine the corrections, we have H∗L1 = 2gp N [ℓ/p + log(N/2gℓ) + log(H1L∗ − 2ghL∗)] and then ℓe−ℓ/peN H1L∗/(2gp) = ℓ + 2p log(N/2gℓ) + 2p log(H1L∗ − 2ghL∗) giving H1L∗ ≈ 2gℓ/N up to logarithmic corrections. Similarly H∗L1 ≈ 2gℓ/N. To obtain the corrections we write H1L∗ = 2gℓ/N + a, H∗L1 = 2gℓ/N + b, giving b = (gℓ/N) h eN...
-
[58]
This means that the average sentence length ℓ/m cannot grow faster than linearly in N
The approximation further requires a, b ≲ 1 which reduce to 4p2g2 (2p2 − ℓ2) mp N ≲ 1 which can only hold if 5 ℓ < √ 2p ≲ 4 √ 2N m. This means that the average sentence length ℓ/m cannot grow faster than linearly in N
-
[59]
contingency tables
Quenched grammar average The above results can be extended to computation of log Z, the quenched average over grammars. Using the replica method log Z = lim q→0 d(Zq)/dq = lim q→0 dZq/dq we need to replicate all {η, ζ, ξ, La, Ra}, adding a replica index α = 1 , . . . , q. The key point is that the exponential coupling gets replaced by eηHaLaRa → e ∑ α ηαH...
-
[60]
Then ˜n is fixed by n = N en/pa X k≥1 kz k k − a ≈ N en/pa X k zk = N en/paz/(1 − z) (C1) where z = N a/2xe−˜n and we have assumed a ≪ 1, which is 8x ≪ 1
F rozen regime To orient ourselves consider the frozen regime r = 0, which means that x < 1/8. Then ˜n is fixed by n = N en/pa X k≥1 kz k k − a ≈ N en/pa X k zk = N en/paz/(1 − z) (C1) where z = N a/2xe−˜n and we have assumed a ≪ 1, which is 8x ≪ 1. This gives z−1 = 1 + en/p/G. 25 where G = n/N a. We still have to fix p through p = X k pk = N en/pa X k≥1 ...
-
[61]
High temperature regime: For small trees it is convenient to make an approximation considering only the k = 1 and k = 2 terms in the sums. At high temperature and in small trees, most rules are used uniquely; if we keep only the k = 1 and k = 2 terms we have n ≈ N 3en/pe−˜n[g1 + 2g2e−˜n] (C6) p ≈ N 3en/pe−˜n[g1 + g2e−˜n] (C7) so that e−˜n = −g1 4g2 " −1 +...
-
[62]
Then ˜n is fixed by n = vN a X k k k + mc − 1 mc − 1 zk k − a ≈ vN a X k k + mc − 1 mc − 1 zk = vN a 1 (1 − z)mc − 1 where we assume 1 ≫ a, i.e
F rozen regime Again start with the frozen regime r = 0, which means that x < 1/8. Then ˜n is fixed by n = vN a X k k k + mc − 1 mc − 1 zk k − a ≈ vN a X k k + mc − 1 mc − 1 zk = vN a 1 (1 − z)mc − 1 where we assume 1 ≫ a, i.e. x ≪ 1/8. This is solved z = 1 − (1 + G/v)−1/mc (D1) 27 Now we need to find p and v. Since v = e ∑ k′ pk′ N log ( 1+ k′ mc −1 ) ha...
-
[63]
For example if r = 1 so that 1/8 < x < 1/2, then we simply replace g1 by the other asymptotic expression
T ransition regime The same technique can be adapted to other regions. For example if r = 1 so that 1/8 < x < 1/2, then we simply replace g1 by the other asymptotic expression. This results in z = 1 − 0 BB@1 + 1 v 2 664G − N 2 a vzm ce1/4˜ϵd e−X∗ + vzm c | {z } Gtrans 3 775 1 CCA −1/mc . 1/8 < x < 1/2 (D20) 31 For log(Gtrans/v) ≪ mc we get zmc ≈ log(Gtran...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.