R²-Searcher: Calibrating Retrieval and Reasoning Boundaries for Agentic Search
Pith reviewed 2026-06-30 00:30 UTC · model grok-4.3
The pith
R²-Searcher calibrates retrieval and reasoning boundaries through token-guided evidence modeling and reflection to create a mutual-enhancement loop for multi-hop QA.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
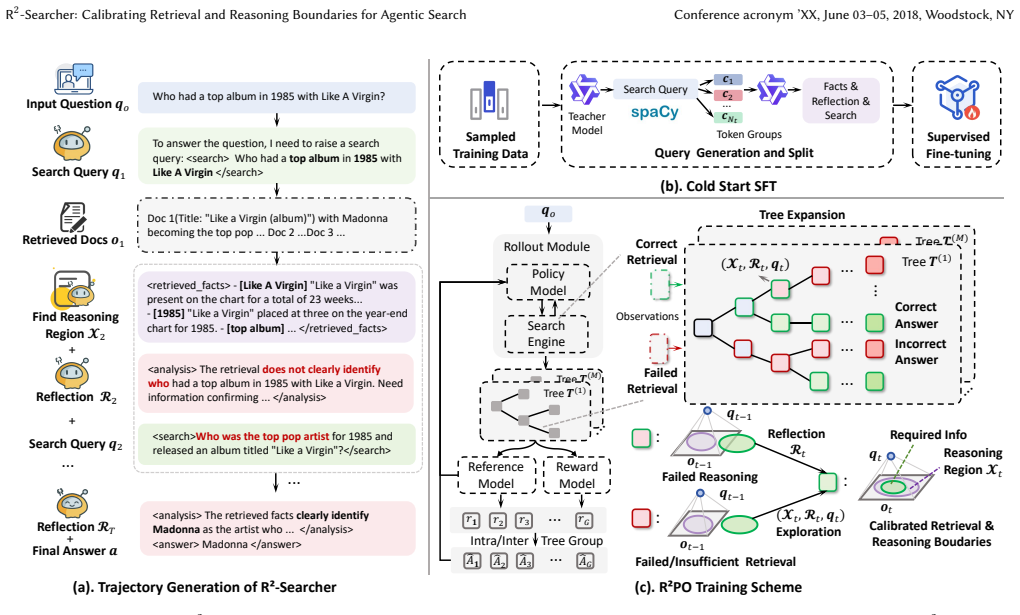
R²-Searcher constructs fine-grained reasoning contexts by extracting precise facts from retrieved content based on query token semantics, introduces a retrieval reflection mechanism that evaluates and corrects boundary deviations after each retrieval step, and employs the R²PO reinforcement learning algorithm to jointly optimize both boundaries, establishing an iterative loop where retrieval and reasoning mutually enhance each other.
What carries the argument
R²-Searcher framework that uses fine-grained query-token-guided evidence modeling combined with post-retrieval reflection and the R²PO tree-based RL optimizer to calibrate retrieval-reasoning boundaries.
If this is right
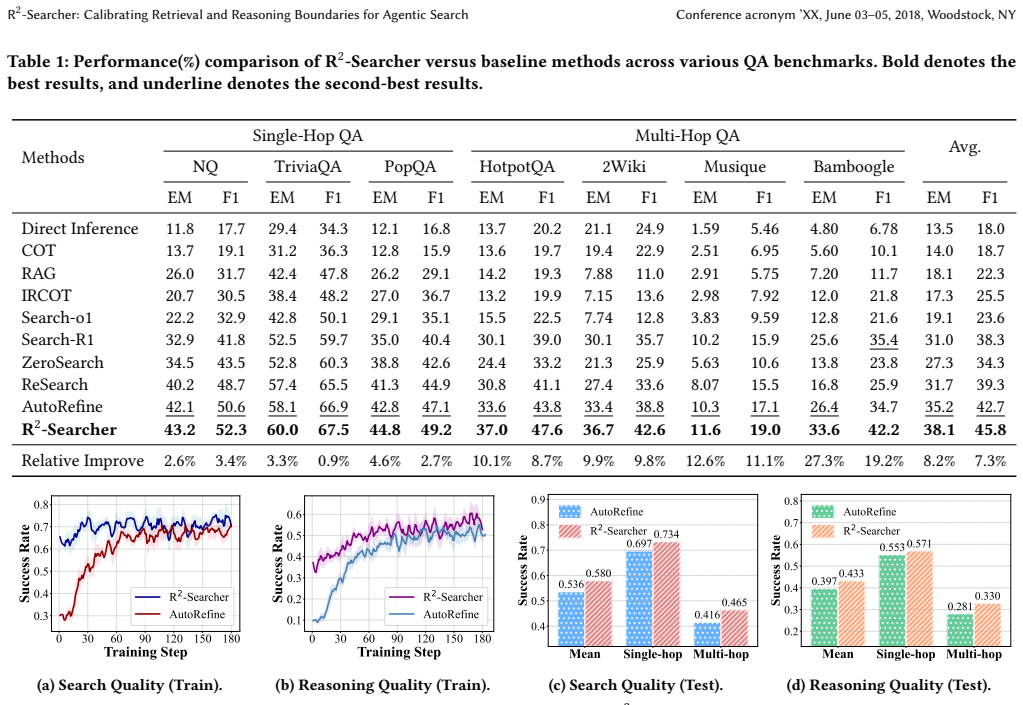
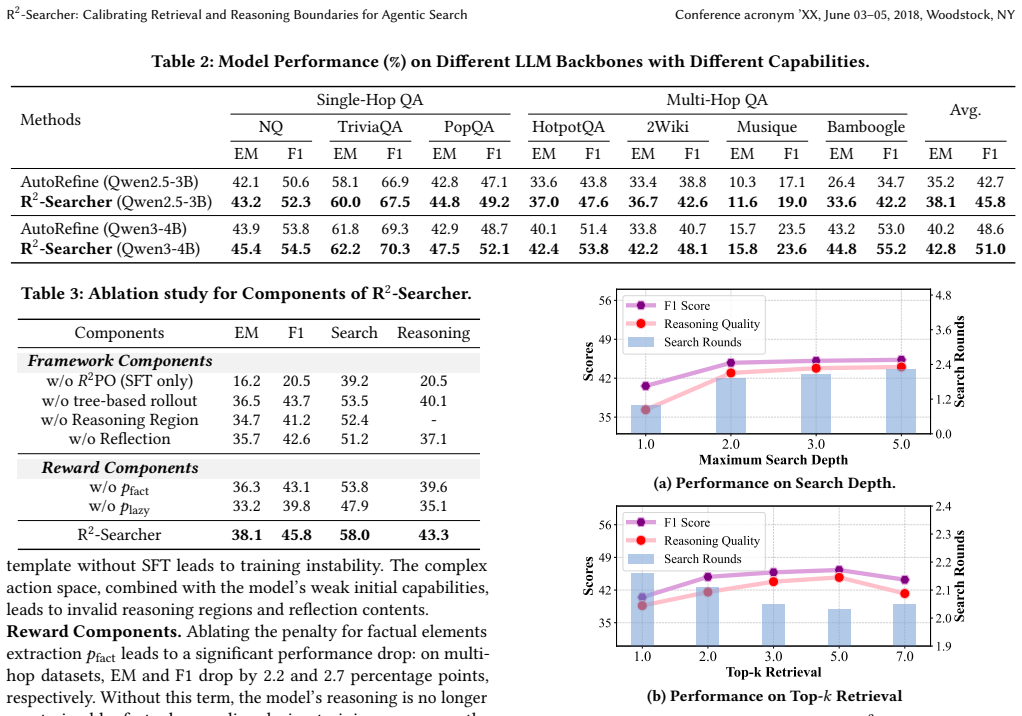
- Answer accuracy rises on seven complex multi-hop QA benchmarks compared with prior agentic search methods.
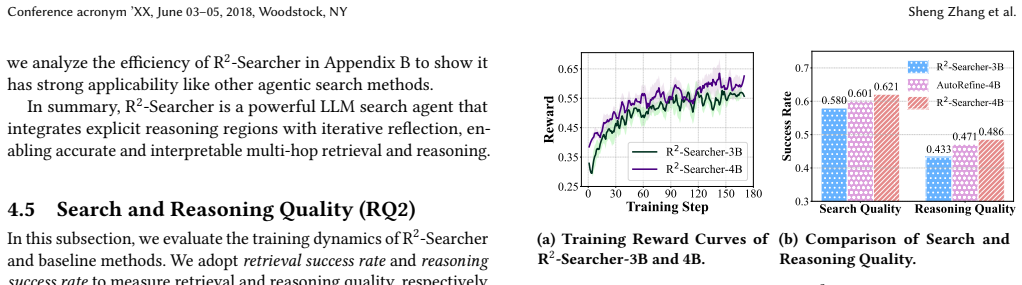
- Retrieval-reasoning quality improves because each component supplies better inputs to the other in an iterative loop.
- The R²PO algorithm enables joint optimization of the two boundaries through tree-based exploration of reasoning regions and reflections.
- Ablation studies isolate the contribution of boundary calibration to the observed gains.
Where Pith is reading between the lines
- The same boundary-calibration loop could be tested on agentic tasks outside QA, such as code generation or tool-use chains, to check whether mutual enhancement generalizes.
- If the reflection step proves robust, it might allow smaller base models to reach performance levels currently requiring larger ones by reducing wasted retrieval steps.
- A direct comparison of token-level evidence extraction against coarser passage-level methods on the same benchmarks would quantify how much granularity matters for boundary control.
Load-bearing premise
The fine-grained evidence modeling and retrieval reflection mechanisms will reliably calibrate boundaries without introducing new errors or requiring extensive post-hoc tuning.
What would settle it
Run the seven benchmarks with the boundary-calibration components ablated and measure whether answer accuracy and retrieval-reasoning quality scores remain statistically indistinguishable from the full model.
Figures


read the original abstract
Recent search agents for multi-hop reasoning often fail by either retrieving incomplete evidence or reasoning over irrelevant portions of the retrieved content, leading to a retrieval-reasoning boundary shift. We propose R$^2$-Searcher, a novel framework that explicitly explores and calibrates the retrieval and reasoning boundaries via fine-grained, query-token-guided evidence modeling and post-retrieval reflection. Specifically, R$^2$-Searcher: (1) constructs fine-grained reasoning contexts by extracting precise facts from retrieved content based on query token semantics (e.g., subjects, actions, temporal markers, and degree modifiers), thereby guiding the attention of search agent; (2) introduces a retrieval reflection mechanism that evaluates and corrects boundary deviations after each retrieval step, guiding the generation of improved queries grounded in the extracted reasoning contexts; and (3) employs an end-to-end reasoning-reflection-guided reinforcement learning algorithm, R$^2$PO, which jointly optimizes both boundaries through a tree-based exploration of reasoning regions and reflections. Our method significantly enhances the quality of both retrieval and reasoning, establishing an iterative loop where retrieval and reasoning mutually enhance each other. Extensive experiments on seven complex multi-hop QA benchmarks demonstrate that R$^2$-Searcher significantly outperforms state-of-the-art agentic search methods in answer accuracy and retrieval-reasoning quality. Ablation studies further confirm the critical role of retrieval-reasoning boundary calibration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes R²-Searcher, a framework for agentic search in multi-hop QA that calibrates retrieval and reasoning boundaries through (1) query-token-guided fine-grained fact extraction from retrieved content, (2) post-retrieval reflection to correct boundary deviations and generate improved queries, and (3) the R²PO end-to-end RL algorithm that jointly optimizes both boundaries via tree-based exploration. It claims this creates a mutually enhancing iterative loop and yields significant gains in answer accuracy and retrieval-reasoning quality over SOTA methods on seven benchmarks, with ablations confirming the role of boundary calibration.
Significance. If the experimental validation and component-level error analysis were provided and confirmed the calibration mechanisms improve performance without net error propagation, the work could meaningfully advance agentic search by demonstrating a stable retrieval-reasoning feedback loop. However, the absence of any quantitative results, boundary metrics, or failure-case analysis in the manuscript prevents assessing whether this potential is realized.
major comments (2)
- [Abstract] Abstract (experiments paragraph): the central claim that R²-Searcher 'significantly outperforms state-of-the-art agentic search methods in answer accuracy and retrieval-reasoning quality' on seven benchmarks is asserted without any reported numbers, baselines, tables, error rates, or boundary-specific metrics (e.g., pre/post-reflection error comparison), making it impossible to trace the claimed gains to the proposed calibration components rather than other factors such as base LLM or search depth.
- [Abstract] Abstract (R²PO description): the claim that R²PO 'jointly optimizes both boundaries through a tree-based exploration of reasoning regions and reflections' is presented without any equations, optimization details, or validation that the mechanism avoids introducing new errors or requiring extensive post-hoc tuning, directly undermining the load-bearing assumption that the iterative loop is stable and reliable.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. The abstract is intended as a high-level summary, with full quantitative results, baselines, and component analyses provided in the main body (Sections 4–5). We will revise the abstract to better connect the claims to these results and to the R²PO details.
read point-by-point responses
-
Referee: [Abstract] Abstract (experiments paragraph): the central claim that R²-Searcher 'significantly outperforms state-of-the-art agentic search methods in answer accuracy and retrieval-reasoning quality' on seven benchmarks is asserted without any reported numbers, baselines, tables, error rates, or boundary-specific metrics (e.g., pre/post-reflection error comparison), making it impossible to trace the claimed gains to the proposed calibration components rather than other factors such as base LLM or search depth.
Authors: We agree the abstract would be strengthened by explicit linkage to the reported results. In revision we will insert concise references to the accuracy gains, baseline comparisons, and ablation outcomes from Tables 1–3 and Section 5, including boundary-error reductions, so readers can directly trace improvements to the calibration components rather than confounding factors. revision: yes
-
Referee: [Abstract] Abstract (R²PO description): the claim that R²PO 'jointly optimizes both boundaries through a tree-based exploration of reasoning regions and reflections' is presented without any equations, optimization details, or validation that the mechanism avoids introducing new errors or requiring extensive post-hoc tuning, directly undermining the load-bearing assumption that the iterative loop is stable and reliable.
Authors: The abstract summarizes the high-level mechanism; the full equations, tree-based exploration procedure, and stability validation (via ablations showing no net error increase) appear in Section 3.3. We will add a short clause in the revised abstract referencing these details and the empirical confirmation of loop stability. revision: yes
Circularity Check
No detectable circularity; abstract-only text supplies no equations or derivation steps
full rationale
The supplied document consists solely of the abstract. It describes a framework with three components (fine-grained evidence modeling, retrieval reflection, and R²PO RL) and claims mutual enhancement via an iterative loop, plus benchmark outperformance. No equations, parameter-fitting procedures, self-citations, or uniqueness theorems appear. Consequently none of the enumerated circularity patterns (self-definitional, fitted-input-called-prediction, self-citation load-bearing, etc.) can be exhibited by quoting paper text and showing reduction to inputs. The central claim rests on experimental results rather than an internal derivation chain that collapses by construction. This is the expected honest non-finding when no mathematical steps are present to inspect.
Axiom & Free-Parameter Ledger
invented entities (2)
-
R²-Searcher
no independent evidence
-
R²PO
no independent evidence
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
Mingyang Chen, Linzhuang Sun, Tianpeng Li, Haoze Sun, Yijie Zhou, Chenzheng Zhu, Haofen Wang, Jeff Z Pan, Wen Zhang, Huajun Chen, et al . 2025. Learn- ing to reason with search for llms via reinforcement learning.arXiv preprint arXiv:2503.19470(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V Le, Sergey Levine, and Yi Ma. 2025. Sft memorizes, rl generalizes: A comparative study of foundation model post-training.arXiv preprint arXiv:2501.17161(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [5]
-
[6]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2024. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Mohammed A El-Shorbagy, Anas Bouaouda, Laith Abualigah, and Fatma A Hashim. 2025. Atom Search Optimization: a comprehensive review of its variants, applications, and future directions.PeerJ Computer Science11 (2025), e2722
2025
-
[8]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. 2025. Deepseek-r1: Incen- tivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Bernal Jiménez Gutiérrez, Yiheng Shu, Weijian Qi, Sizhe Zhou, and Yu Su. 2025. From rag to memory: Non-parametric continual learning for large language models.arXiv preprint arXiv:2502.14802(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps.arXiv preprint arXiv:2011.01060(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[12]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.Iclr1, 2 (2022), 3
2022
-
[13]
Mengkang Hu, Tianxing Chen, Qiguang Chen, Yao Mu, Wenqi Shao, and Ping Luo. 2025. Hiagent: Hierarchical working memory management for solving long-horizon agent tasks with large language model. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 32779–32798
2025
- [14]
-
[15]
Yulong Hui, Chao Chen, Zhihang Fu, Yihao Liu, Jieping Ye, and Huanchen Zhang
- [16]
-
[17]
Jeongyeon Hwang, Junyoung Park, Hyejin Park, Dongwoo Kim, Sangdon Park, and Jungseul Ok. 2025. Retrieval-augmented generation with estimation of source reliability. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 34267–34291
2025
-
[18]
Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong C Park
- [19]
- [20]
-
[21]
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. 2025. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. 2017. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. arXiv preprint arXiv:1705.03551(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick SH Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open-Domain Question Answering.. InEMNLP (1). 6769–6781
2020
-
[24]
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. 2019. Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics7 (2019), 453–466
2019
-
[25]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems33 (2020), 9459–9474
2020
- [26]
-
[27]
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. 2025. Search-o1: Agentic search-enhanced large reasoning models.arXiv preprint arXiv:2501.05366(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2023. Lost in the middle: How language models use long contexts.arXiv preprint arXiv:2307.03172(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [29]
-
[30]
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 9802–9822
2023
-
[31]
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A Smith, and Mike Lewis. 2023. Measuring and narrowing the compositionality gap in language models. InFindings of the Association for Computational Linguistics: EMNLP 2023. 5687–5711
2023
- [32]
-
[33]
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. 2025. Zep: a temporal knowledge graph architecture for agent memory. arXiv preprint arXiv:2501.13956(2025). Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Sheng Zhang et al
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [35]
-
[36]
Hao Sun, Zile Qiao, Jiayan Guo, Xuanbo Fan, Yingyan Hou, Yong Jiang, Pengjun Xie, Yan Zhang, Fei Huang, and Jingren Zhou. 2025. Zerosearch: Incentivize the search capability of llms without searching.arXiv preprint arXiv:2505.04588 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [37]
-
[38]
Zoltán Gendler Szabó. 2015. Major parts of speech.Erkenntnis80, Suppl 1 (2015), 3–29
2015
-
[40]
Transactions of the Association for Computational Linguistics10 (2022), 539–554
MuSiQue: Multihop Questions via Single-hop Question Composition. Transactions of the Association for Computational Linguistics10 (2022), 539–554
2022
-
[41]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal
-
[42]
InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers)
Interleaving retrieval with chain-of-thought reasoning for knowledge- intensive multi-step questions. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers). 10014–10037
-
[43]
Fei Wang, Xingchen Wan, Ruoxi Sun, Jiefeng Chen, and Sercan O Arik. 2025. Astute rag: Overcoming imperfect retrieval augmentation and knowledge con- flicts for large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 30553–30571
2025
-
[44]
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. 2022. Text embeddings by weakly-supervised contrastive pre-training.arXiv preprint arXiv:2212.03533(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [45]
- [46]
-
[47]
Zihan Wang, Zihan Liang, Zhou Shao, Yufei Ma, Huangyu Dai, Ben Chen, Ling- tao Mao, Chenyi Lei, Yuqing Ding, and Han Li. 2025. InfoGain-RAG: Boosting Retrieval-Augmented Generation via Document Information Gain-based Rerank- ing and Filtering.arXiv preprint arXiv:2509.12765(2025)
-
[48]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
2022
-
[49]
Nirmalie Wiratunga, Ramitha Abeyratne, Lasal Jayawardena, Kyle Martin, Stew- art Massie, Ikechukwu Nkisi-Orji, Ruvan Weerasinghe, Anne Liret, and Bruno Fleisch. 2024. CBR-RAG: case-based reasoning for retrieval augmented gen- eration in LLMs for legal question answering. InInternational Conference on Case-Based Reasoning. Springer, 445–460
2024
- [50]
-
[51]
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang
-
[52]
A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Cheng- peng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei Li, Mingfen...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W Cohen, Ruslan Salakhutdinov, and Christopher D Manning. 2018. HotpotQA: A dataset for di- verse, explainable multi-hop question answering.arXiv preprint arXiv:1809.09600 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [56]
-
[57]
Hongli Yu, Tinghong Chen, Jiangtao Feng, Jiangjie Chen, Weinan Dai, Qiying Yu, Ya-Qin Zhang, Wei-Ying Ma, Jingjing Liu, Mingxuan Wang, et al. 2025. MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent.arXiv preprint arXiv:2507.02259(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Qianhao Yuan, Jie Lou, Zichao Li, Jiawei Chen, Yaojie Lu, Hongyu Lin, Le Sun, Debing Zhang, and Xianpei Han. 2025. MemSearcher: Training LLMs to Reason, Search and Manage Memory via End-to-End Reinforcement Learning.arXiv preprint arXiv:2511.02805(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [59]
-
[60]
Sheng Zhang, Junyi Li, Yingyi Zhang, Pengyue Jia, Yichao Wang, Xiaowei Qian, Wenlin Zhang, Maolin Wang, Yong Liu, and Xiangyu Zhao. 2026. MemSearch-o1: Empowering Large Language Models with Reasoning-Aligned Memory Growth in Agentic Search.arXiv preprint arXiv:2604.17265(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[61]
Wenlin Zhang, Kuicai Dong, Junyi Li, Yingyi Zhang, Xiaopeng Li, Pengyue Jia, Yi Wen, Derong Xu, Maolin Wang, Yichao Wang, et al. 2026. To search or not to search: Aligning the decision boundary of deep search agents via causal intervention. InProceedings of the ACM Web Conference 2026. 2049–2059
2026
- [62]
-
[63]
Yingyi Zhang, Pengyue Jia, Xianneng Li, Derong Xu, Maolin Wang, Yichao Wang, Zhaocheng Du, Huifeng Guo, Yong Liu, Ruiming Tang, et al. 2025. Lsrp: A leader-subordinate retrieval framework for privacy-preserving cloud-device collaboration. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 3889–3900
2025
-
[64]
Zijian Zhou, Ao Qu, Zhaoxuan Wu, Sunghwan Kim, Alok Prakash, Daniela Rus, Jinhua Zhao, Bryan Kian Hsiang Low, and Paul Pu Liang. 2025. MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents.arXiv preprint arXiv:2506.15841(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.