A robust PPG foundation model using multimodal physiological supervision
Pith reviewed 2026-06-27 22:19 UTC · model grok-4.3
The pith
Using ECG and respiratory signals to pick contrastive PPG samples yields a foundation model that beats priors on 14 of 15 tasks after pretraining on one-third the subjects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
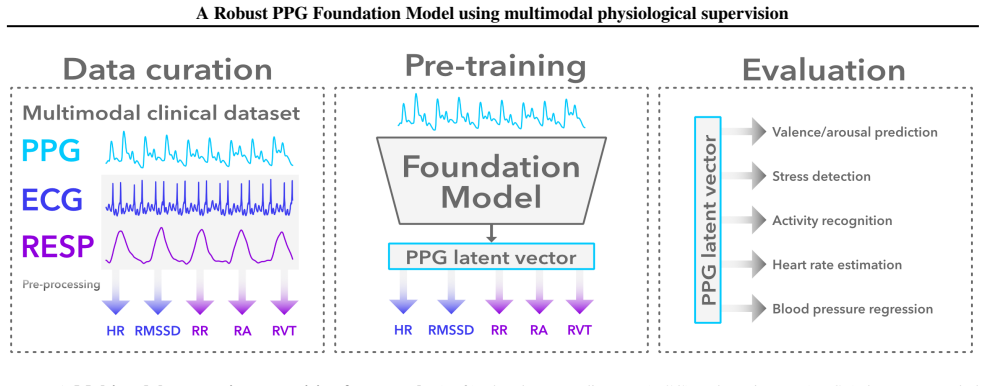
By supervising contrastive sample selection with ECG and respiratory channels from ICU recordings, a PPG model can retain noisy segments during pretraining and thereby learn representations that generalize to noisy field PPG while requiring fewer subjects than existing foundation models.
What carries the argument
Multimodal physiological supervision that uses ECG and respiratory signals to select contrastive samples during pretraining on ICU PPG data.
If this is right
- The model can be deployed on consumer wearables without access to large curated field PPG corpora for pretraining.
- Robustness at inference improves because noisy PPG segments are retained rather than filtered during training.
- Downstream performance gains appear on both clinical and daily-activity tasks that use real-world noisy signals.
- Pretraining data requirements drop because three times fewer subjects suffice to reach or exceed prior results.
Where Pith is reading between the lines
- The same supervision strategy could be tested on other biosignals where auxiliary channels exist only during training but not at deployment.
- If the auxiliary signals reduce selection bias, similar multimodal selection might improve single-channel foundation models in other sensing domains.
- Lower subject counts could make large-scale pretraining feasible for groups with limited access to ICU datasets.
Load-bearing premise
Selecting contrastive samples with ECG and respiratory signals from ICU datasets will produce representations that generalize to noisy field-like PPG without selection bias or loss of information unique to the PPG channel.
What would settle it
Evaluation on a held-out set of noisy field PPG recordings in which the model shows no improvement over single-channel baselines or degrades on tasks that depend on subtle PPG features absent from the auxiliary signals.
Figures
read the original abstract
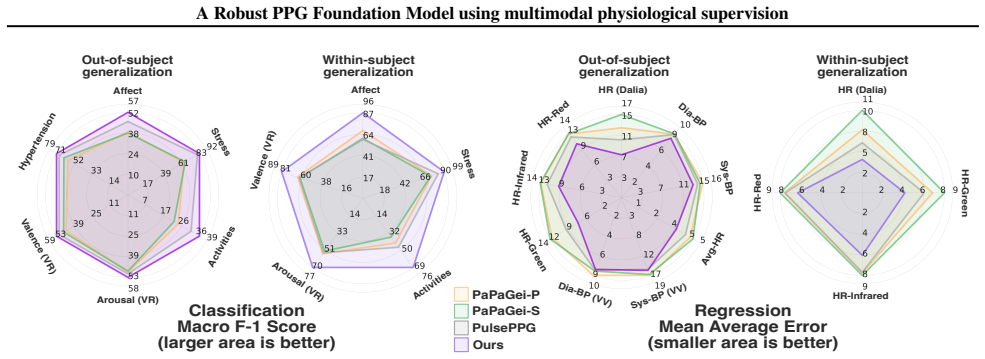
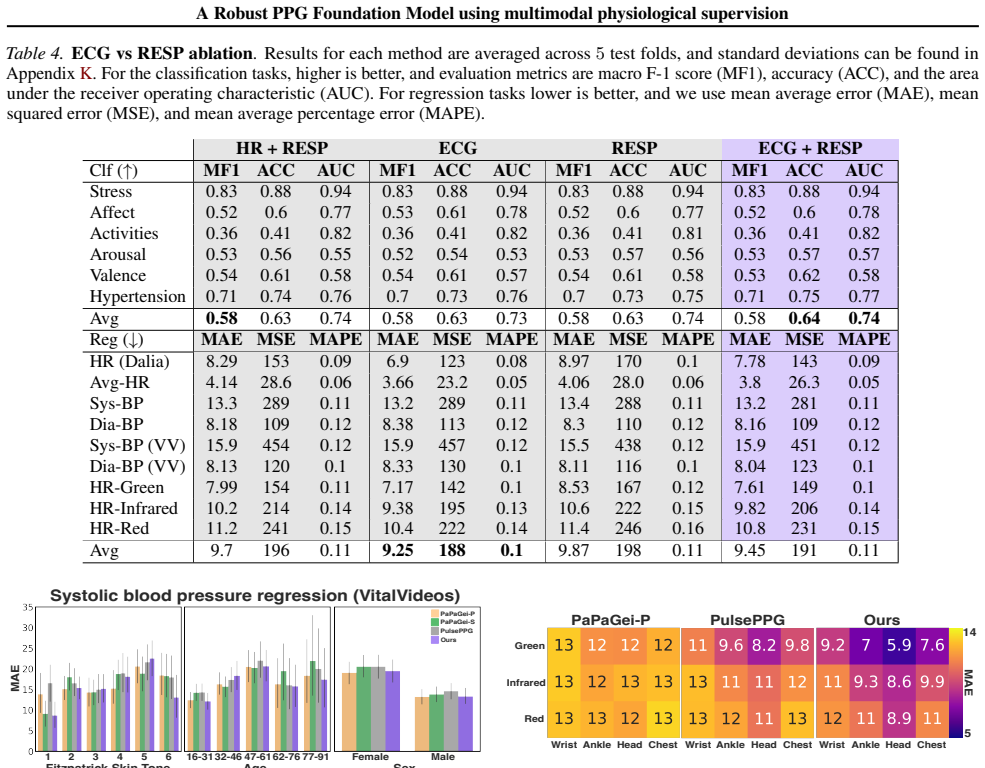
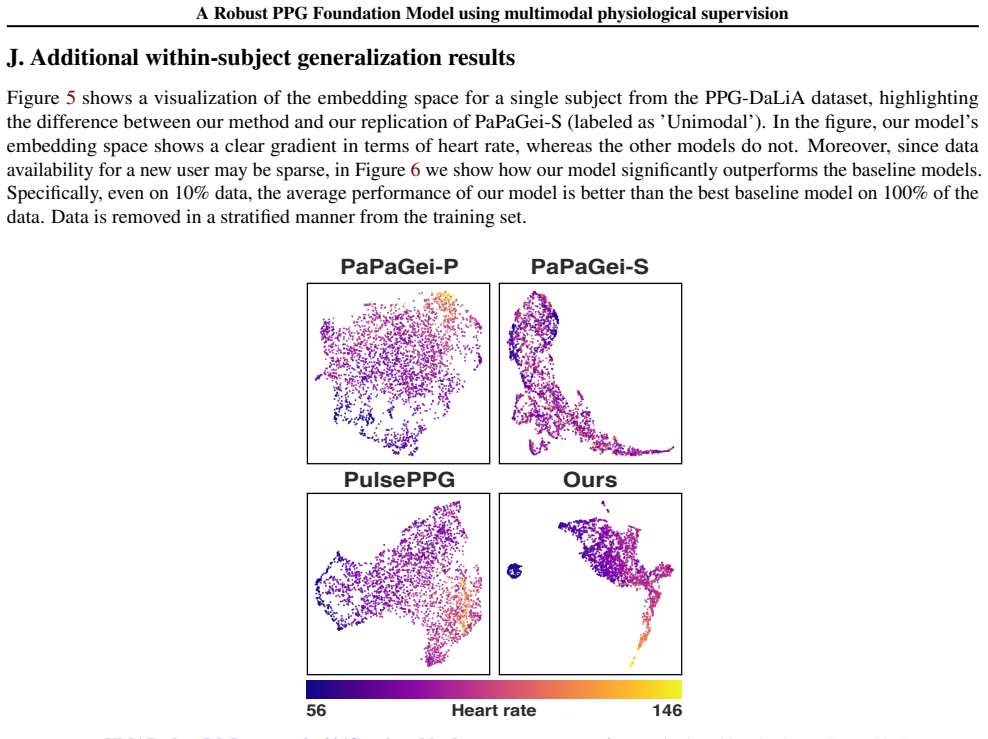
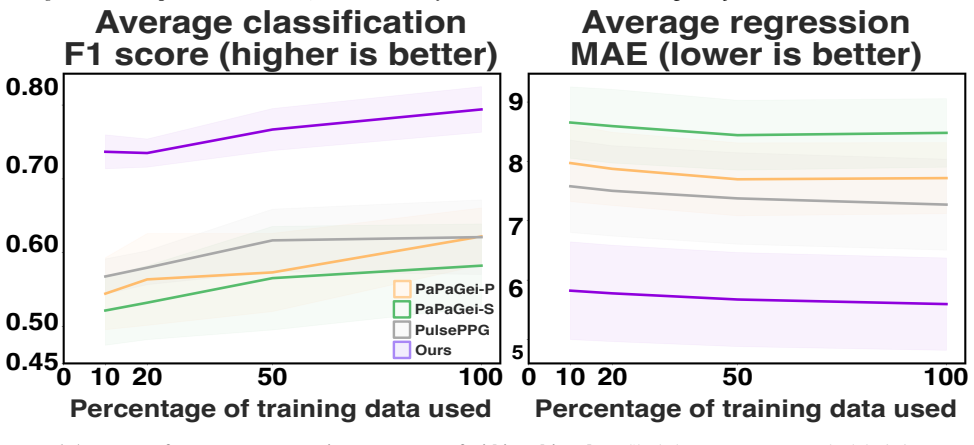
Photoplethysmography (PPG), a non-invasive measure of changes in blood volume, is widely used in both wearable devices and clinical settings. Recent PPG foundation models either use open-source ICU datasets with pretraining paradigms that require curated data and thus complicate generalization to field-like data, or use closed-source field-like PPG data. In contrast, we propose a PPG foundation model that does not require high-quality or field-like pretraining data, and instead leverages accompanying electrocardiogram and respiratory signals in ICU datasets to select contrastive samples during pretraining. Our approach allows the model to retain and learn from noisy PPG segments, improving robustness at inference. Our model, pretrained on 3x fewer subjects than existing state-of-the-art approaches, achieves performance improvements on 14 out of 15 diverse downstream tasks, including field-like daily activity and heart rate prediction. Our results demonstrate that multimodal supervision can integrate complementary physiological information to improve the robustness of PPG foundation models and enhance their generalization to consumer-grade data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a PPG foundation model pretrained on ICU datasets by using accompanying ECG and respiratory signals to select contrastive samples. This multimodal supervision is intended to allow the model to retain and learn from noisy PPG segments, yielding a representation robust to field-like artifacts. The model is pretrained on 3× fewer subjects than prior SOTA approaches and is reported to improve performance on 14 of 15 downstream tasks, including daily activity recognition and heart-rate estimation on consumer-grade data.
Significance. If the central empirical claim holds after addressing selection-bias concerns, the result would be significant: it would show that abundant, lower-quality ICU recordings can be leveraged for robust PPG pretraining without curated field data, lowering the barrier to foundation-model development for wearable PPG applications.
major comments (2)
- [§3] §3 (multimodal sample selection): the procedure that retains PPG segments whose ECG/resp agreement exceeds a threshold must be shown not to embed ICU-specific cross-channel correlations that are unavailable at inference on field PPG; without an explicit test (e.g., performance drop when the same selection rule is applied to ambulatory data or an ablation that removes ECG/resp guidance), the 14/15-task gains could be explained by retained ICU cues rather than improved robustness.
- [Results] Results section (downstream evaluation): the headline claim of improvement on 14/15 tasks is presented without reported statistical tests, confidence intervals, or per-task effect sizes; in addition, an ablation that trains the identical architecture with random (non-multimodal) contrastive sampling is required to isolate whether the reported gains are attributable to the proposed supervision rather than architecture or data volume.
minor comments (2)
- [Abstract] Abstract and §1: quantitative deltas, baseline names, and subject counts for the 3× reduction claim should be stated explicitly rather than left as qualitative assertions.
- [§3] Notation in §3: the precise definition of the contrastive loss and the ECG/resp agreement metric (e.g., cross-correlation threshold) should be given as an equation rather than prose description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate revisions to the manuscript.
read point-by-point responses
-
Referee: §3 (multimodal sample selection): the procedure that retains PPG segments whose ECG/resp agreement exceeds a threshold must be shown not to embed ICU-specific cross-channel correlations that are unavailable at inference on field PPG; without an explicit test (e.g., performance drop when the same selection rule is applied to ambulatory data or an ablation that removes ECG/resp guidance), the 14/15-task gains could be explained by retained ICU cues rather than improved robustness.
Authors: We agree that it is important to confirm the gains arise from robustness rather than retained ICU correlations. The selection procedure is applied exclusively during pretraining; inference uses PPG alone. We will add an ablation that trains the identical architecture with random (non-multimodal) contrastive sampling on the same data to isolate the contribution of ECG/resp guidance. We note that directly applying the selection rule to ambulatory data is not possible, as those datasets lack the auxiliary ECG and respiratory channels required to compute agreement. revision: partial
-
Referee: Results section (downstream evaluation): the headline claim of improvement on 14/15 tasks is presented without reported statistical tests, confidence intervals, or per-task effect sizes; in addition, an ablation that trains the identical architecture with random (non-multimodal) contrastive sampling is required to isolate whether the reported gains are attributable to the proposed supervision rather than architecture or data volume.
Authors: We accept that statistical reporting and the requested ablation are needed for rigor. The revised manuscript will include per-task statistical tests, confidence intervals, and effect sizes for all 15 downstream tasks. We will also report the ablation using random contrastive sampling with the same architecture and data to attribute gains specifically to the multimodal supervision. revision: yes
- Direct application of the multimodal selection rule to ambulatory data, as such datasets lack the ECG and respiratory signals required to compute the agreement threshold.
Circularity Check
No circularity; purely empirical pretraining with held-out evaluation
full rationale
The paper presents an empirical contrastive pretraining method that selects samples using accompanying ECG/respiratory channels from ICU data, then evaluates the resulting encoder on 15 downstream tasks (including field-like ones) using held-out data. No equations, derivations, uniqueness theorems, or fitted parameters are described that reduce a claimed prediction to the method's own inputs by construction. The central performance claims (14/15 improvements, 3x fewer subjects) are external benchmarks, not self-referential. This matches the default non-circular case for empirical ML work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2312.05409 , year=
Abbaspourazad, S., Elachqar, O., Miller, A. C., Emrani, S., Nallasamy, U., and Shapiro, I. Large-scale training of foundation models for wearable biosignals.arXiv preprint arXiv:2312.05409,
-
[2]
Abbaspourazad, S., Mishra, A., Futoma, J., Miller, A. C., and Shapiro, I. Wearable accelerometer foundation mod- els for health via knowledge distillation.arXiv preprint arXiv:2412.11276,
-
[3]
On the Opportunities and Risks of Foundation Models
Bommasani, R. On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
ncbi.nlm.nih.gov/books/NBK482414/
URL https://www. ncbi.nlm.nih.gov/books/NBK482414/. [Up- dated 2023 Jun 5]. Capulli, E., Druda, Y ., Palmese, F., Butt, A. H., Domenicali, M., Macchiarelli, A. G., Silvani, A., Bedogni, G., and Ingravallo, F. Ethical and legal implications of health monitoring wearable devices: A scoping review.Social Science & Medicine, pp. 117685,
2023
-
[5]
Chien, H.-Y . S., Goh, H., Sandino, C. M., and Cheng, J. Y . Maeeg: Masked auto-encoder for eeg representation learning.arXiv preprint arXiv:2211.02625,
-
[6]
Bert: Pre-training of deep bidirectional transformers for lan- guage understanding
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pre-training of deep bidirectional transformers for lan- guage understanding. InProceedings of the 2019 confer- ence of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186,
2019
-
[7]
Fang, C., Sandino, C., Mahasseni, B., Minxha, J., Pouransari, H., Azemi, E., Moin, A., and Zippi, E. Pro- moting cross-modal representations to improve multi- modal foundation models for physiological signals.arXiv preprint arXiv:2410.16424,
-
[8]
L., Pouransari, H., Sandino, C., Nie, J., Goh, H., Azemi, E., and Moin, A
Liu, R., Zippi, E. L., Pouransari, H., Sandino, C., Nie, J., Goh, H., Azemi, E., and Moin, A. Frequency- aware masked autoencoders for multimodal pretraining on biosignals.arXiv preprint arXiv:2309.05927,
-
[9]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
doi: 10.3758/ s13428-020-01516-y. URL https://doi.org/10. 3758%2Fs13428-020-01516-y. McInnes, L., Healy, J., and Melville, J. Umap: Uniform manifold approximation and projection for dimension reduction.arXiv preprint arXiv:1802.03426,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
Nie, Y ., Nguyen, N. H., Sinthong, P., and Kalagnanam, J. A time series is worth 64 words: Long-term forecasting with transformers.arXiv preprint arXiv:2211.14730,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Pa- pagei: Open foundation models for optical physiological signals.arXiv preprint arXiv:2410.20542,
Pillai, A., Spathis, D., Kawsar, F., and Malekzadeh, M. Pa- pagei: Open foundation models for optical physiological signals.arXiv preprint arXiv:2410.20542,
-
[12]
A., Mao, W., Neupane, S., Rehg, J
Saha, M., Xu, M. A., Mao, W., Neupane, S., Rehg, J. M., and Kumar, S. Pulse-ppg: An open-source field-trained ppg foundation model for wearable applications across lab and field settings.arXiv preprint arXiv:2502.01108,
-
[13]
URL https://arxiv.org/ abs/2211.10831. Thapa, R., He, B., Kjaer, M. R., Moore IV , H., Ganjoo, G., Mignot, E., and Zou, J. Y . Sleepfm: Multi-modal representation learning for sleep across ecg, eeg and res- piratory signals. InAAAI 2024 Spring Symposium on Clinical Foundation Models,
-
[14]
Tonekaboni, S., Eytan, D., and Goldenberg, A. Unsuper- vised representation learning for time series with temporal neighborhood coding.arXiv preprint arXiv:2106.00750,
-
[15]
Toye, P.-J. Vital videos: A dataset of face videos with ppg and blood pressure ground truths.arXiv preprint arXiv:2306.11891,
-
[16]
Cardiorespiratory dynamic response to mental stress: A multivariate time-frequency analysis.Computational and mathematical methods in medicine, 2013(1):451857,
Widjaja, D., Orini, M., Vlemincx, E., and Van Huffel, S. Cardiorespiratory dynamic response to mental stress: A multivariate time-frequency analysis.Computational and mathematical methods in medicine, 2013(1):451857,
2013
-
[17]
A., Moreno, A., Wei, H., Marlin, B
Xu, M. A., Moreno, A., Wei, H., Marlin, B. M., and Rehg, J. M. Rebar: Retrieval-based reconstruction for time-series contrastive learning.arXiv preprint arXiv:2311.00519,
-
[18]
A., Narain, J., Darnell, G., Hallgrimsson, H., Jeong, H., Forde, D., Fineman, R., Raghuram, K
Xu, M. A., Narain, J., Darnell, G., Hallgrimsson, H., Jeong, H., Forde, D., Fineman, R., Raghuram, K. J., Rehg, J. M., and Ren, S. Relcon: Relative contrastive learning for a motion foundation model for wearable data.arXiv preprint arXiv:2411.18822,
-
[19]
Zhang, Y ., Ayush, K., Qiao, S., Heydari, A. A., Narayan- swamy, G., Xu, M. A., Metwally, A. A., Xu, S., Garrison, J., Xu, X., et al. Sensorlm: Learning the language of wear- able sensors.arXiv preprint arXiv:2506.09108,
-
[20]
ECG and RESP pre-processing We identify sessions containing more than one hour of continuous data across all three modalities: ECG, RESP, and PPG
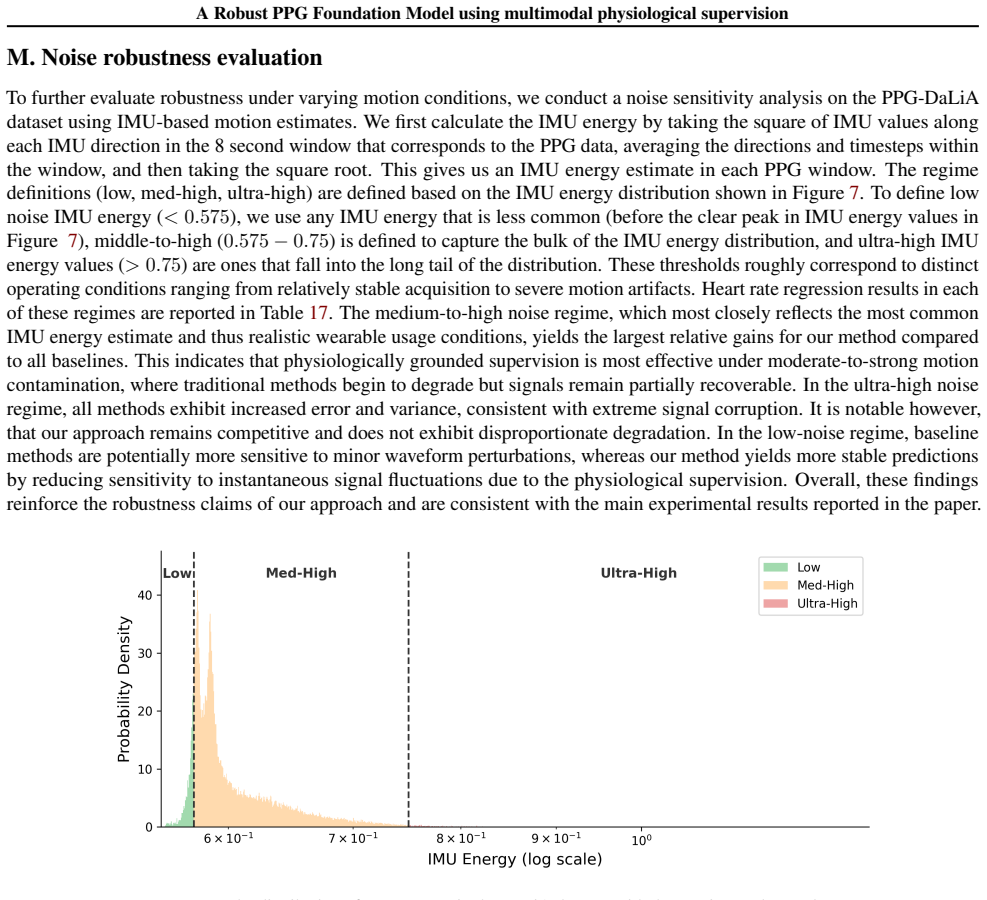
13 A Robust PPG Foundation Model using multimodal physiological supervision A. ECG and RESP pre-processing We identify sessions containing more than one hour of continuous data across all three modalities: ECG, RESP, and PPG. The ECG and RESP signals are filtered using NeuroKit (Makowski et al., 2021), and then used to detect peaks: R-peaks in ECG and res...
2021
-
[21]
Although the dataset records data from a variety of physiological sensors, we only select the PPG data, which is recorded with a 64Hz sensor
contains 15 subjects recorded in a lab setting. Although the dataset records data from a variety of physiological sensors, we only select the PPG data, which is recorded with a 64Hz sensor. In terms of PPG preprocessing we follow (Xu et al., 2023), whose preprocessing code is available on GitHub. We adapt the preprocessing code to obtain 10s non-overlappi...
2023
-
[22]
The study consists of baseline dataset collection, a VR familiarity task, and then a set of VR stimuli with post-exposure questionnaires
measures PPG data at 125Hz while 37 subjects are wearing a virtual reality (VR) headset. The study consists of baseline dataset collection, a VR familiarity task, and then a set of VR stimuli with post-exposure questionnaires. To evoke specific levels of arousal and valence, the authors use annotated 360 ◦ videos from a public database (Li et al., 2017), ...
2017
-
[23]
There are three PPG recordings for each subject that last around 2 second each, and 219 subjects in total
released the PPG blood pressure dataset ( PPG-BP), with PPG sampled at 1000Hz. There are three PPG recordings for each subject that last around 2 second each, and 219 subjects in total. We noticed some issues with resampling the data, so we decided to linearly interpolate the data instead. Using np.interp (Harris et al., 2020), we interpolate each segment...
2020
-
[24]
The dataset records data from 16 subjects, and each PPG sensor records at 128 Hz
released the WildPPG database. The dataset records data from 16 subjects, and each PPG sensor records at 128 Hz. The ground truth estimate of the heart rate is estimated with an ECG trace recorded from each subject’s sternum. The dataset contains data for three types of PPG sensors: green, red, and infrared (IR), and four types of locations: wrist, head, ...
2019
-
[25]
Checkpoint selection.During pretraining we save checkpoints for the backbone every 5000 steps
The output embedding for our model is thus a (2×batch size,512)tensor. Checkpoint selection.During pretraining we save checkpoints for the backbone every 5000 steps. To select the final checkpoint that we use for comparisons, we evaluate each checkpoint on every single downstream cross-subject task, except the WildPPG tasks. To ensure there is no data lea...
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.