Are Common Substructures Transferable? Riemannian Graph Foundation Model with Neural Vector Bundles
Pith reviewed 2026-06-28 11:42 UTC · model grok-4.3
The pith
Common substructures transfer when their functional behavior aligns with the intrinsic geometry of the representation space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
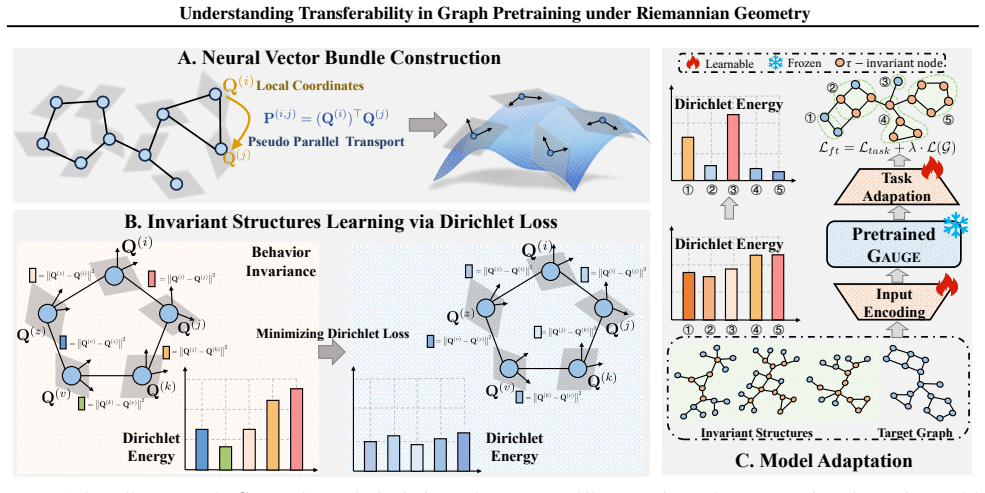
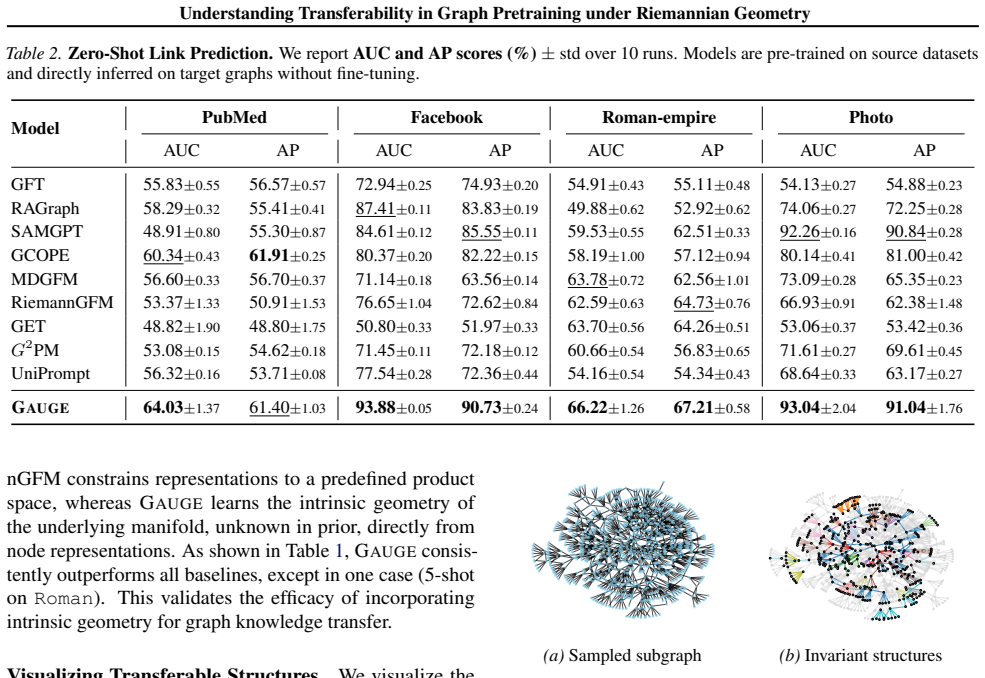
Transferable substructures are those whose functional behavior corresponds to the intrinsic geometry of the representation space; this geometry can be characterized in a Riemannian setting by the Neural Vector Bundle, which parses it with local coordinates. GAUGE is the pretrainable architecture that realizes the bundle construction, flattens geometrically compatible local coordinates, and introduces a Dirichlet loss to measure transfer effort, yielding superior expressiveness on zero-shot link prediction and graph isomorphism.
What carries the argument
Neural Vector Bundle: a Riemannian framework that constructs a vector bundle over the graph so local coordinates can parse its intrinsic geometry.
If this is right
- GAUGE pretraining transfers common substructures by enforcing geometric compatibility through the vector bundle.
- The Dirichlet loss both trains the model and directly quantifies the transfer effort required between graphs.
- The approach improves performance on zero-shot link prediction by leveraging the parsed intrinsic geometry.
- Graph isomorphism tasks benefit because geometric compatibility of local coordinates provides an additional structural signal.
Where Pith is reading between the lines
- The same local-coordinate parsing might be tested on non-graph structured data such as point clouds or meshes to check whether the Riemannian construction generalizes.
- If the bundle construction is replaced by a simpler Euclidean encoder, transfer should degrade on the same zero-shot tasks.
- Scaling the method to graphs with millions of nodes would reveal whether the cost of maintaining local coordinates remains practical.
Load-bearing premise
Functional behavior of substructures corresponds to intrinsic geometry in the representation space that can be parsed using local coordinates in a Riemannian setting.
What would settle it
A controlled comparison in which GAUGE with the Neural Vector Bundle shows no gain in substructure transfer or task performance over a standard graph model that lacks the Riemannian local-coordinate parsing.
Figures
read the original abstract
Foundation models have sparked a revolution via a pretraining-adaptation paradigm, with recent efforts extending this success to graphs. Unlike other modalities, graphs contain rich structural patterns, yet their structural transferability remains poorly understood. Prior studies consider common substructures in the discrete realm, and we are motivated by a fundamental question: Are common substructures transferable? The underlying theory is largely underexplored. In this work, we shift toward learning transferable structures through the lens of functional behavior. Theoretically, we connect transferable substructures to intrinsic geometry of the representation space. However, characterizing such intrinsic geometry has rarely been touched. Grounded in Riemannian geometry, we develop a graph intrinsic geometry learning framework called Neural Vector Bundle, which enables parsing intrinsic geometry with local coordinates. Building on this, we design GAUGE, a pretrainable neural architecture that constructs the vector bundle, flattening geometrically compatible local coordinates, and a new Dirichlet loss, which also measures the transfer effort. We empirically validate its superior expressiveness in challenging tasks including zero-shot link prediction and graph isomorphism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that common substructures in graphs are transferable when linked to the intrinsic geometry of the representation space, which a Neural Vector Bundle framework parses via local coordinates. It introduces the GAUGE pretrainable architecture that constructs the bundle, flattens compatible coordinates, and employs a Dirichlet loss to measure transfer effort, with empirical validation on zero-shot link prediction and graph isomorphism tasks.
Significance. If the central theoretical connection and empirical results hold, the work could establish a Riemannian geometric basis for graph foundation models, moving beyond discrete substructure matching toward continuous intrinsic geometry parsing; this would be a notable advance in graph pretraining if supported by explicit derivations and reproducible experiments.
major comments (2)
- [Abstract] Abstract: the theoretical connection between transferable substructures and intrinsic geometry is asserted without any equations, construction of the Neural Vector Bundle, definition of local coordinates, or proof steps; this leaves the central claim unsupported by visible mathematics.
- [Abstract] Abstract (Dirichlet loss paragraph): the loss is described as measuring transfer effort, but no definition, relation to fitted parameters, or reduction to known quantities is supplied, preventing assessment of whether it is non-circular or load-bearing for the transferability claim.
Simulated Author's Rebuttal
We thank the referee for their comments on the abstract. We address each major comment below and will revise the abstract accordingly to improve clarity while preserving its high-level nature.
read point-by-point responses
-
Referee: [Abstract] Abstract: the theoretical connection between transferable substructures and intrinsic geometry is asserted without any equations, construction of the Neural Vector Bundle, definition of local coordinates, or proof steps; this leaves the central claim unsupported by visible mathematics.
Authors: The abstract is intentionally concise and high-level, as is standard. The full manuscript provides the explicit construction of the Neural Vector Bundle, definition of local coordinates via charts, and the theoretical derivations connecting transferable substructures to intrinsic geometry in Sections 3.1–3.3, including the relevant equations and proof sketches. To address the concern about visibility in the abstract itself, we will revise the abstract to incorporate a brief reference to the key bundle construction and one central equation. revision: yes
-
Referee: [Abstract] Abstract (Dirichlet loss paragraph): the loss is described as measuring transfer effort, but no definition, relation to fitted parameters, or reduction to known quantities is supplied, preventing assessment of whether it is non-circular or load-bearing for the transferability claim.
Authors: The abstract summarizes the Dirichlet loss at a high level. The full manuscript defines the loss explicitly in Section 4.2, derives its relation to the fitted bundle parameters, shows its reduction to a known Dirichlet energy form on the manifold, and explains why it is non-circular for the transferability claim. We agree the abstract could be more precise on this point and will revise it to include a short definitional clause or key property of the loss. revision: yes
Circularity Check
No significant circularity identified from visible derivation
full rationale
The abstract states a theoretical connection between transferable substructures and intrinsic geometry parsed via local coordinates in a Neural Vector Bundle, along with GAUGE architecture and a Dirichlet loss measuring transfer effort. However, no equations, derivation steps, self-citations, or parameter-fitting details are supplied that would allow identification of any reduction to inputs by construction. The provided text contains no load-bearing self-citation chains, fitted inputs renamed as predictions, or ansatzes smuggled via citation. Per the rules, circularity is only claimed when a specific reduction can be quoted and exhibited; absent that, the finding is no significant circularity (score 0).
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On the Opportunities and Risks of Foundation Models
On the opportunities and risks of foundation models , author =. arXiv preprint arXiv:2108.07258 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Proceedings of the 35th Advances in Neural Information Processing Systems , pages =
Ultrahyperbolic Neural Networks , author =. Proceedings of the 35th Advances in Neural Information Processing Systems , pages =
-
[3]
2023 , eprint=
Discrete Vector Bundles with Connection and the Bianchi Identity , author=. 2023 , eprint=
2023
-
[4]
Proceedings of the Thirteenth International Conference on Learning Representations , year=
Bundle Neural Network for message diffusion on graphs , author=. Proceedings of the Thirteenth International Conference on Learning Representations , year=
-
[5]
Advances in neural information processing systems (NeurIPS) , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems (NeurIPS) , volume=
-
[6]
2025 , eprint=
LLM as GNN: Graph Vocabulary Learning for Text-Attributed Graph Foundation Models , author=. 2025 , eprint=
2025
-
[7]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =
OpenGraph: Towards Open Graph Foundation Models , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =
2024
-
[8]
Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
2019
-
[9]
9th International Conference on Learning Representations,
Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby , title =. 9th International Conference on Learning Representations,
-
[10]
Learning Transferable Visual Models From Natural Language Supervision , booktitle =
-
[11]
Chunyuan Li and Zhe Gan and Zhengyuan Yang and Jianwei Yang and Linjie Li and Lijuan Wang and Jianfeng Gao , title =. Found. Trends Comput. Graph. Vis. , pages =
-
[12]
Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
A survey of large language models for graphs , author=. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[13]
Proceedings of the ACM Web Conference 2024 Companion , pages =
Large Language Models for Graphs: Progresses and Directions , author =. Proceedings of the ACM Web Conference 2024 Companion , pages =
2024
-
[14]
Proceedings of the 37th International Conference on Machine Learning , pages =
Constant Curvature Graph Convolutional Networks , author =. Proceedings of the 37th International Conference on Machine Learning , pages =
-
[15]
2025 , eprint=
Towards Text-free Graph Foundation Models: Rethinking Multi-Domain Graph Contrastive Learning , author=. 2025 , eprint=
2025
-
[16]
Proceedings of the Tenth International Conference on Learning Representations , year =
Spherical Message Passing for 3D Molecular Graphs , author =. Proceedings of the Tenth International Conference on Learning Representations , year =
-
[17]
Sheaf Diffusion Goes Nonlinear: Enhancing
Olga Zaghen and Antonio Longa and Steve Azzolin and Lev Telyatnikov and Andrea Passerini and Pietro Lio , booktitle=. Sheaf Diffusion Goes Nonlinear: Enhancing
-
[18]
Sheaf Neural Networks , author =. arXiv preprint arXiv:2012.06333 , year =
-
[19]
Advances in Neural Information Processing Systems , pages=
Hyperbolic graph convolutional neural networks , author=. Advances in Neural Information Processing Systems , pages=
-
[20]
2025 , eprint=
GraphKeeper: Graph Domain-Incremental Learning via Knowledge Disentanglement and Preservation , author=. 2025 , eprint=
2025
-
[21]
Proceedings of the 36th Advances in Neural Information Processing Systems , year=
Pseudo-Riemannian Graph Convolutional Networks , author=. Proceedings of the 36th Advances in Neural Information Processing Systems , year=
-
[22]
2025 , eprint=
Graph Foundation Models: A Comprehensive Survey , author=. 2025 , eprint=
2025
-
[23]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics , pages =
Fully Hyperbolic Neural Networks , author =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics , pages =
-
[24]
2024 , booktitle =
Sun, Li and Huang, Zhenhao and Wang, Zixi and Wang, Feiyang and Peng, Hao and Yu, Philip , title =. 2024 , booktitle =
2024
-
[25]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
ASIL: Augmented Structural Information Learning for Deep Graph Clustering in Hyperbolic Space , author =. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =. 2026 , publisher =
2026
-
[26]
, booktitle =
Sun, Li and Huang, Zhenhao and Wan, Qiqi and Peng, Hao and Yu, Philip S. , booktitle =. Spiking Graph Neural Network on Riemannian Manifolds , volume =
-
[27]
Deeper with Riemannian Geometry: Overcoming Oversmoothing and Oversquashing for Graph Foundation Models , volume =
Sun, Li and Huang, Zhenhao and Zhang, Ming and Yu, Philip S , booktitle =. Deeper with Riemannian Geometry: Overcoming Oversmoothing and Oversquashing for Graph Foundation Models , volume =
-
[28]
2026 , eprint=
RiemannGL: Riemannian Geometry Changes Graph Deep Learning , author=. 2026 , eprint=
2026
-
[29]
Proceedings of the Sixth International Conference on Learning Representations , year =
Learning Mixed-Curvature Representations in Product Spaces , author =. Proceedings of the Sixth International Conference on Learning Representations , year =
-
[30]
2021 , eprint=
Switch Spaces: Learning Product Spaces with Sparse Gating , author=. 2021 , eprint=
2021
-
[31]
Procrustes Problems , author =
-
[32]
Proceedings of the Forty-Second International Conference on Machine Learning , year=
Towards Graph Foundation Models: Learning Generalities Across Graphs via Task-Trees , author=. Proceedings of the Forty-Second International Conference on Machine Learning , year=
-
[33]
Proceedings of the Seventh International Conference on Learning Representations , year =
Deep Graph Infomax , author =. Proceedings of the Seventh International Conference on Learning Representations , year =
-
[34]
Proceedings of the Seventh International Conference on Learning Representations , year=
How Powerful are Graph Neural Networks? , author=. Proceedings of the Seventh International Conference on Learning Representations , year=
-
[35]
Deep graph contrastive representation learning,
Deep Graph Contrastive Representation Learning , author =. arXiv preprint arXiv:2006.04131 , year =
-
[36]
Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages =
GraphMAE: Self-Supervised Masked Graph Autoencoders , author =. Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages =
-
[37]
Proceedings of the Fifth International Conference on Learning Representations , year=
Semi-Supervised Classification with Graph Convolutional Networks , author=. Proceedings of the Fifth International Conference on Learning Representations , year=
-
[38]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Inductive Representation Learning on Large Graphs , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[39]
Proceedings of the Sixth International Conference on Learning Representations , year =
Graph Attention Networks , author =. Proceedings of the Sixth International Conference on Learning Representations , year =
-
[40]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2 , pages =
Bo, Jianyuan and Wu, Hao and Fang, Yuan , title =. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2 , pages =
-
[41]
Proceedings of the Thirty-Eighth Advances in Neural Information Processing Systems , year=
GFT: Graph Foundation Model with Transferable Tree Vocabulary , author=. Proceedings of the Thirty-Eighth Advances in Neural Information Processing Systems , year=
-
[42]
Proceedings of the Thirty-Eighth Advances in Neural Information Processing Systems , year =
RAGraph: A General Retrieval-Augmented Graph Learning Framework , author =. Proceedings of the Thirty-Eighth Advances in Neural Information Processing Systems , year =
-
[43]
Proceedings of the ACM Web Conference 2025 , pages =
SAMGPT: Text-free Graph Foundation Model for Multi-domain Pre-training and Cross-domain Adaptation , author =. Proceedings of the ACM Web Conference 2025 , pages =
2025
-
[44]
Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
All in one: Multi-task prompting for graph neural networks , author=. Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[45]
Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
All in One and One for All: A Simple yet Effective Method towards Cross-domain Graph Pretraining , author=. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[46]
Proceedings of the Thirteenth International Conference on Learning Representations , year =
Fully-inductive Node Classification on Arbitrary Graphs , author =. Proceedings of the Thirteenth International Conference on Learning Representations , year =
-
[47]
Proceedings of the ACM Web Conference 2025 , pages =
RiemannGFM: Learning a Graph Foundation Model from Riemannian Geometry , author =. Proceedings of the ACM Web Conference 2025 , pages =
2025
-
[48]
The Fourteenth International Conference on Learning Representations , year=
Multi-Domain Riemannian Graph Gluing for Building Graph Foundation Models , author=. The Fourteenth International Conference on Learning Representations , year=
-
[49]
Proceedings of the Forty-Second International Conference on Machine Learning , year=
Multi-Domain Graph Foundation Models: Robust Knowledge Transfer via Topology Alignment , author=. Proceedings of the Forty-Second International Conference on Machine Learning , year=
-
[50]
Proceedings of the Forty-Second International Conference on Machine Learning , year=
GraphGPT: Generative Pre-trained Graph Eulerian Transformer , author=. Proceedings of the Forty-Second International Conference on Machine Learning , year=
-
[51]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Generative Graph Pattern Machine , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[52]
arXiv preprint arXiv:2509.22416 , year =
One Prompt Fits All: Universal Graph Adaptation for Pretrained Models , author =. arXiv preprint arXiv:2509.22416 , year =
-
[53]
Proceedings of the Thirty-Ninth Advances in Neural Information Processing Systems , year =
GRAVER: Generative Graph Vocabularies for Robust Graph Foundation Models Fine-tuning , author =. Proceedings of the Thirty-Ninth Advances in Neural Information Processing Systems , year =
-
[54]
Proceedings of the Forty-Second International Conference on Machine Learning , year =
Graph Generative Pre-trained Transformer , author =. Proceedings of the Forty-Second International Conference on Machine Learning , year =
-
[55]
Proceedings of the Forty-First International Conference on Machine Learning , year =
LLaGA: Large Language and Graph Assistant , author =. Proceedings of the Forty-First International Conference on Machine Learning , year =
-
[56]
2020 , booktitle =
Hu, Weihua and Fey, Matthias and Zitnik, Marinka and Dong, Yuxiao and Ren, Hongyu and Liu, Bowen and Catasta, Michele and Leskovec, Jure , title =. 2020 , booktitle =
2020
-
[57]
and Salakhutdinov, Ruslan , title =
Yang, Zhilin and Cohen, William W. and Salakhutdinov, Ruslan , title =. 2016 , booktitle =
2016
-
[58]
A critical look at the evaluation of
Oleg Platonov and Denis Kuznedelev and Michael Diskin and Artem Babenko and Liudmila Prokhorenkova , booktitle=. A critical look at the evaluation of
-
[59]
Multi-Scale attributed node embedding , year=
Benedek Rozemberczki,Carl Allen and Rik Sarkar , journal=. Multi-Scale attributed node embedding , year=
-
[60]
2019 , eprint=
Pitfalls of Graph Neural Network Evaluation , author=. 2019 , eprint=
2019
-
[61]
2018 , eprint=
MoleculeNet: A Benchmark for Molecular Machine Learning , author=. 2018 , eprint=
2018
-
[62]
TUDataset: A collection of benchmark datasets for learning with graphs
TUDataset: A collection of benchmark datasets for learning with graphs , author=. ICML 2020 Workshop on Graph Representation Learning and Beyond (GRL+ 2020) , archivePrefix=. 2007.08663 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[63]
and Luu, Anh Tuan and Laurent, Thomas and Bengio, Yoshua and Bresson, Xavier , title =
Dwivedi, Vijay Prakash and Joshi, Chaitanya K. and Luu, Anh Tuan and Laurent, Thomas and Bengio, Yoshua and Bresson, Xavier , title =. J. Mach. Learn. Res. , month = jan, articleno =. 2023 , issue_date =
2023
-
[64]
Kingma and Jimmy Ba , title =
Diederik P. Kingma and Jimmy Ba , title =. Proceedings of the 3rd International Conference on Learning Representations (ICLR) , year =
-
[65]
Representation Learning with Contrastive Predictive Coding
A. Representation Learning with Contrastive Predictive Coding , journal =. 2018 , eprinttype =. 1807.03748 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[66]
1992 , publisher=
Riemannian Geometry , author=. 1992 , publisher=
1992
-
[67]
Nature Machine Intelligence , volume =
Multi-Modal Molecule Structure--Text Model for Text-Based Retrieval and Editing , author =. Nature Machine Intelligence , volume =
-
[68]
ICLR 2025 Workshop on Deep Generative Model in Machine Learning: Theory, Principle and Efficacy , year=
UniMoT: Unified Molecule-Text Language Model with Discrete Token Representation , author=. ICLR 2025 Workshop on Deep Generative Model in Machine Learning: Theory, Principle and Efficacy , year=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.