Muon learns balanced solutions in matrix factorization without slow saddle-to-saddle dynamics
Pith reviewed 2026-06-30 07:13 UTC · model grok-4.3
The pith
Muon optimizer in matrix factorization avoids slow saddle-to-saddle dynamics and learns top modes at equal rate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
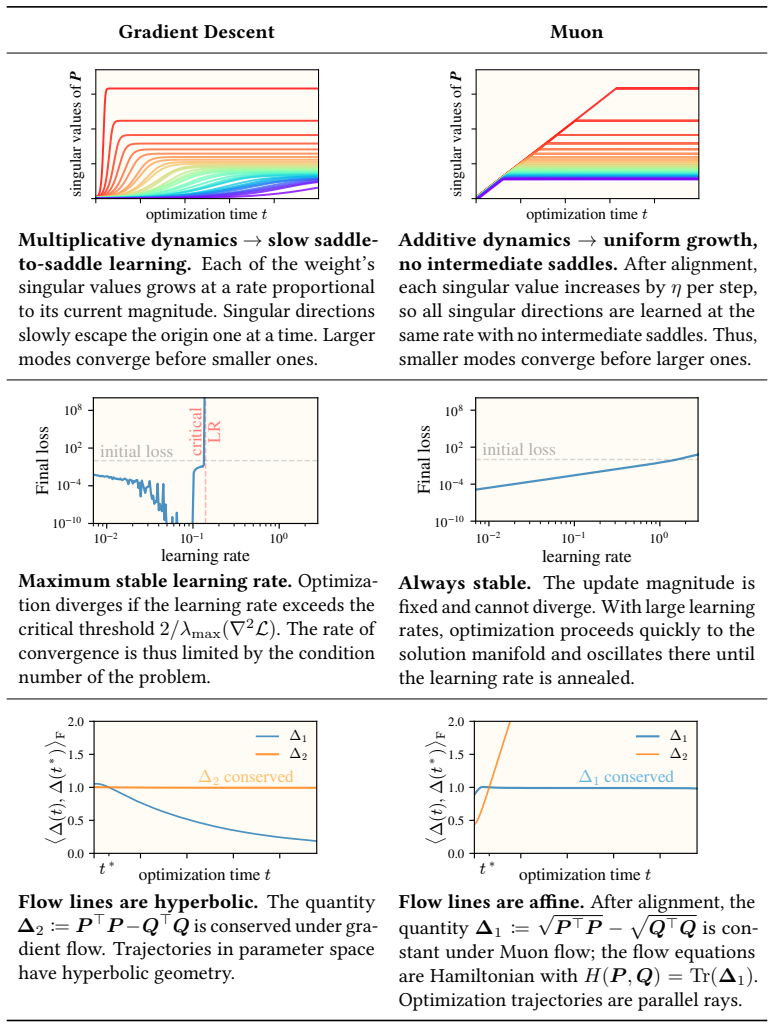
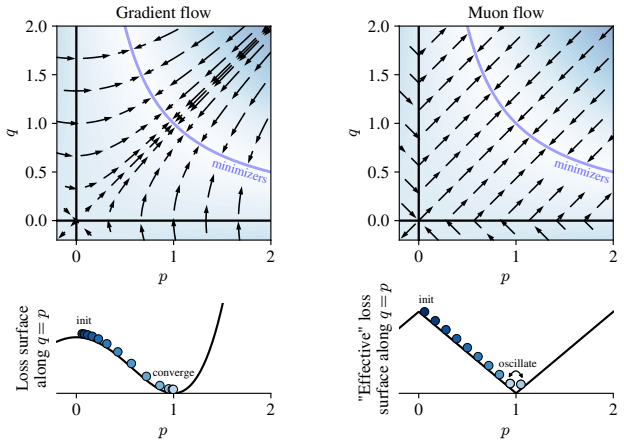
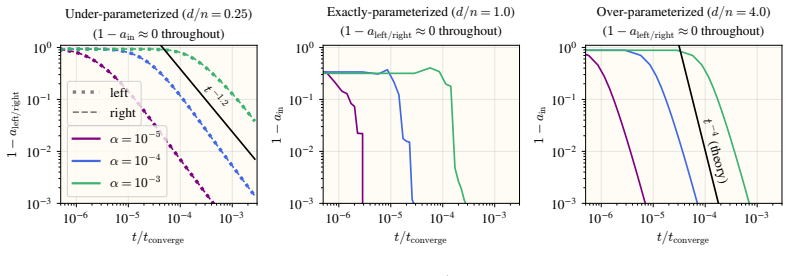
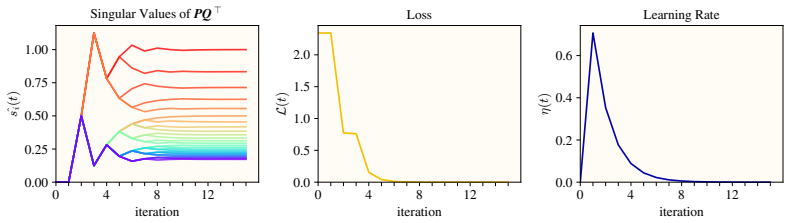
In the matrix factorization problem min ||M* - P^T Q||_F^2, Muon flow avoids slow saddle-to-saddle dynamics from small initialization by learning all top modes of M* at the same rate, with smaller modes converging first. It remains stable even when the learning rate exceeds the critical threshold given by local loss sharpness. Once weights align with each other and the target, Muon conserves the quantity sqrt(P^T P) - sqrt(Q^T Q) while gradient flow conserves P^T P - Q^T Q. Both optimizers reach the balanced solution from vanishing initialization. Alignment rates derived in simple settings predict the empirical rates in general, and structural properties of Muon yield a two-step learning-rat
What carries the argument
The distinct conserved quantity sqrt(P^T P) - sqrt(Q^T Q) under Muon flow, together with the alignment dynamics that let all leading modes of M* advance together.
If this is right
- Exponential learning-rate annealing becomes usable without being limited by the problem condition number.
- A two-step schedule suffices to reach near-perfect alignment from small random initialization.
- Alignment rates computed in simple cases extend to predict behavior in the general matrix factorization setting.
- Both Muon and gradient descent reach the balanced solution despite using different conserved quantities.
Where Pith is reading between the lines
- If the same alignment and stability properties hold in deeper nonlinear networks, Muon could shorten the early phase of training where representations form.
- The two-step alignment schedule might be adapted to other factorized or low-rank problems to reduce total optimization steps.
- Stability past the local-sharpness limit suggests Muon may tolerate aggressive step sizes in settings where gradient descent requires careful tuning.
Load-bearing premise
The dynamical differences and conserved quantity seen in linear matrix factorization arise from structural features of Muon that persist when the same optimizer is applied outside this setting.
What would settle it
Running Muon on a matrix factorization instance and observing either slow saddle-to-saddle transitions or failure to conserve sqrt(P^T P) - sqrt(Q^T Q) after alignment would contradict the reported dynamics.
Figures
read the original abstract
Matrix factorization (i.e., problems of the form $\min_{\mathbf{P},\mathbf{Q}} \|\mathbf{M}^\star - \mathbf{P}^\top\mathbf{Q}\|_\mathrm{F}^2$) is a minimal learning problem that exhibits both nonlinear parameter dynamics and representation learning. In this setting, we study how parameter trajectories under the Muon optimizer differ from those of gradient descent. We identify three main dynamical differences: 1) Muon avoids the slow saddle-to-saddle dynamics from small initialization. Muon instead learns all the top modes of $\mathbf{M}^\star$ at the same rate, with the smaller modes converging first. 2) Muon remains stable even when the learning rate exceeds the critical threshold set by the local loss sharpness. This frees the learning rate from the condition number of the problem, enabling rapid convergence via exponential learning rate annealing. 3) Once the weights are aligned with each other and the target, Muon flow conserves the matrix quantity $\sqrt{\mathbf{P}^\top \mathbf{P}}-\sqrt{\mathbf{Q}^\top \mathbf{Q}}$, while gradient flow is known to conserve the matrix $\mathbf{P}^\top\mathbf{P} - \mathbf{Q}^\top\mathbf{Q}$. Despite having distinct conserved quantities, both optimizers find the so-called \textit{balanced} solution from vanishing initialization. When training from small random initialization, the weights spontaneously align early in training. We derive the alignment rates in simple settings and show that they predict the empirical alignment rates in general. Finally, we exploit structural properties of Muon to construct a learning rate schedule that achieves near-perfect alignment in only two optimization steps.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies the dynamics of the Muon optimizer versus gradient descent in the matrix factorization problem min ||M* - P^T Q||_F^2. It claims three main differences: (1) Muon avoids slow saddle-to-saddle dynamics from small initialization by learning all top modes of M* at the same rate while smaller modes converge first; (2) Muon remains stable for learning rates exceeding the local loss sharpness threshold, freeing the rate from the problem condition number and enabling exponential annealing; (3) Muon flow conserves sqrt(P^T P) - sqrt(Q^T Q) (versus P^T P - Q^T Q for gradient flow), yet both reach balanced solutions. The work derives alignment rates in simple cases that predict empirical rates, shows spontaneous early alignment from random initialization, and constructs a two-step learning-rate schedule achieving near-perfect alignment.
Significance. The explicit derivation of alignment rates that match experiments, the identification of a distinct conserved quantity, and the two-step schedule constitute clear strengths. These elements supply falsifiable predictions and a concrete, parameter-light construction inside the matrix-factorization setting. The scope is limited to linear factorization, so the results stand on their own without requiring transfer to nonlinear networks.
minor comments (2)
- [Abstract] The abstract states that alignment rates 'predict the empirical alignment rates in general' but does not indicate the number of random seeds or the precise initialization distribution used for the empirical verification; adding this detail would strengthen reproducibility.
- [Abstract] Notation for the conserved quantities is introduced without an immediate cross-reference to the corresponding theorem or proposition; a forward pointer would improve readability.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript, for highlighting the explicit derivations of alignment rates, the distinct conserved quantity, and the two-step schedule as strengths, and for recommending acceptance. We appreciate that the scope limitations to linear factorization were noted as appropriate for the results to stand on their own.
Circularity Check
No significant circularity
full rationale
The paper's central claims rest on explicit derivations of alignment rates from simple theoretical settings, identification of a distinct conserved quantity under Muon flow, and a constructed two-step LR schedule exploiting Muon structure. These steps are presented as independent of the target empirical observations; the abstract states that the derived rates 'predict the empirical alignment rates' rather than being fitted to them. No self-citations are invoked as load-bearing uniqueness theorems, no parameters are fitted on a data subset and then relabeled as predictions, and no ansatz is smuggled via prior work. The matrix-factorization setting is self-contained with no reduction of the claimed dynamical differences to tautological redefinitions of the inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2502.09863 , year=
Closed-Form Training Dynamics Reveal Learned Features and Linear Structure in Word2Vec-like Models , author=. arXiv preprint arXiv:2502.09863 , year=
-
[2]
Learning with matrix factorizations , author=
-
[3]
International Conference on Learning Representations (ICLR) , year =
Exact solutions to the nonlinear dynamics of learning in deep linear neural networks , author =. International Conference on Learning Representations (ICLR) , year =
-
[4]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Implicit regularization in matrix factorization , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[5]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Implicit regularization in deep matrix factorization , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[6]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Implicit regularization of discrete gradient dynamics in linear neural networks , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[7]
International Conference on Learning Representations (ICLR) , year =
Towards resolving the implicit bias of gradient descent for matrix factorization: Greedy low-rank learning , author =. International Conference on Learning Representations (ICLR) , year =
-
[8]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Closed-form training dynamics reveal learned features and linear structure in word2vec-like models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[9]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =. 2022 , note =
2022
-
[10]
International Conference on Learning Representations (ICLR) , year =
Neural networks as kernel learners: The silent alignment effect , author =. International Conference on Learning Representations (ICLR) , year =
-
[11]
International Conference on Learning Representations (ICLR) , year =
Gradient descent aligns the layers of deep linear networks , author =. International Conference on Learning Representations (ICLR) , year =
-
[12]
arXiv preprint arXiv:2003.06340 , year =
On alignment in deep linear neural networks , author =. arXiv preprint arXiv:2003.06340 , year =
-
[13]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Algorithmic regularization in learning deep homogeneous models: Layers are automatically balanced , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[14]
arXiv preprint arXiv:2106.15933 , year =
Saddle-to-saddle dynamics in deep linear networks: Small initialization training, symmetry, and sparsity , author =. arXiv preprint arXiv:2106.15933 , year =
-
[15]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Abide by the law and follow the flow: Conservation laws for gradient flows , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[16]
2024 , howpublished =
Muon: An optimizer for hidden layers in neural networks , author =. 2024 , howpublished =
2024
-
[17]
Muon is scalable for
Liu, Jingyuan and Su, Jianlin and Yao, Xingcheng and Jiang, Zhejun and Lai, Guokun and Du, Yulun and Qin, Yidao and Xu, Weixin and Lu, Enzhe and Yan, Junjie and others , journal =. Muon is scalable for
-
[18]
Old Optimizer, New Norm: An Anthology
Old optimizer, new norm: An anthology , author =. arXiv preprint arXiv:2409.20325 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Spectral flattening is all
Nguyen and others , journal =. Spectral flattening is all
-
[20]
On the convergence analysis of
Shen, Wei and Huang, Ruichuan and Huang, Minhui and Shen, Cong and Zhang, Jiawei , journal =. On the convergence analysis of
-
[21]
arXiv preprint arXiv:2511.00674 , year =
Isotropic curvature model for understanding deep learning optimization: Is gradient orthogonalization optimal? , author =. arXiv preprint arXiv:2511.00674 , year =
-
[22]
To Use or not to Use Muon: How Simplicity Bias in Optimizers Matters
Dragutinovi. To use or not to use. arXiv preprint arXiv:2603.00742 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Wang, Shuche and Zhang, Fengzhuo and Li, Jiawei and Du, Cunxiao and Du, Chao and Pang, Tianyu and Yang, Zhuoran and Hong, Mingyi and Tan, Vincent Y. F. , journal =
-
[24]
Vasudeva, Bhavya and Deora, Puneesh and Zhao, Yize and Sharan, Vatsal and Thrampoulidis, Christos , journal =. How
-
[25]
Implicit bias of spectral descent and
Fan, Chen and Schmidt, Mark and Thrampoulidis, Christos , booktitle =. Implicit bias of spectral descent and. 2025 , note =
2025
-
[26]
arXiv preprint arXiv:2601.22652 , year =
Spectral gradient descent mitigates anisotropy-driven misalignment: A case study in phase retrieval , author =. arXiv preprint arXiv:2601.22652 , year =
-
[27]
When do spectral gradient updates help in deep learning? , author =. arXiv preprint arXiv:2512.04299 , year =
-
[28]
Li, Binghui and Wang, Kaifei and Zhong, Han and Lu, Pinyan and Wang, Liwei , journal =
-
[29]
Advances in Neural Information Processing Systems , volume=
Hyperparameter transfer enables consistent gains of matrix-preconditioned optimizers across scales , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
Preconditioning benefits of spectral orthogonalization in
Ma, Jianhao and Huang, Yu and Chi, Yuejie and Chen, Yuxin , journal =. Preconditioning benefits of spectral orthogonalization in
-
[31]
Uniform spectral growth and convergence of
Kang, Changmin and Yun, Jihun and Shin, Baekrok and Cho, Yeseul and Yun, Chulhee , journal =. Uniform spectral growth and convergence of
-
[32]
2025 , note =
Zhang, Yuanhe and Liu, Fanghui and Chen, Yudong , booktitle =. 2025 , note =
2025
-
[33]
arXiv preprint arXiv:2310.17813 , year=
A spectral condition for feature learning , author=. arXiv preprint arXiv:2310.17813 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.