Active Learning with Foundation Model Priors: Efficient Learning under Class Imbalance
Pith reviewed 2026-06-28 18:39 UTC · model grok-4.3
The pith
Foundation model priors enable active learning to reduce annotations by more than half under class imbalance and noisy labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
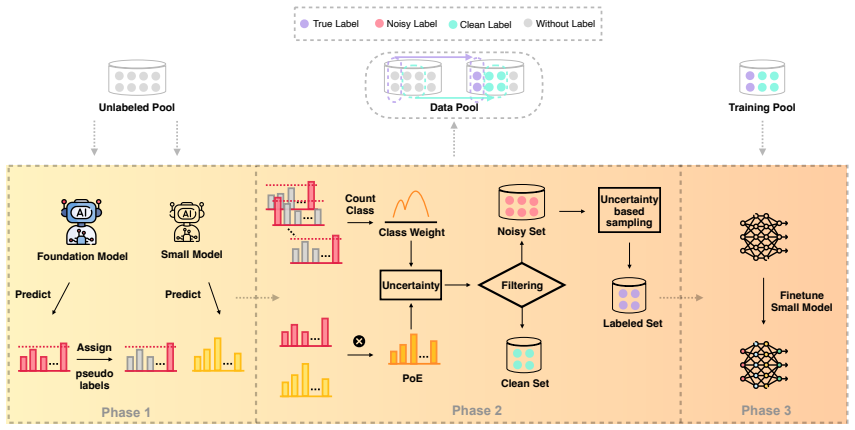
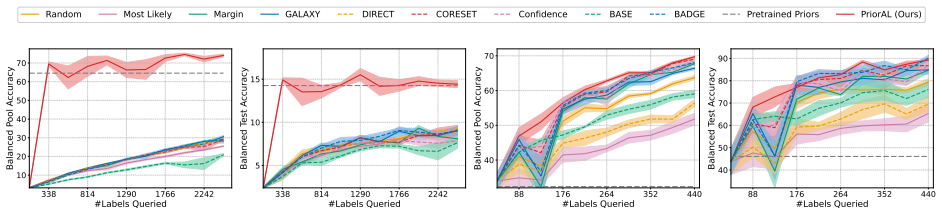
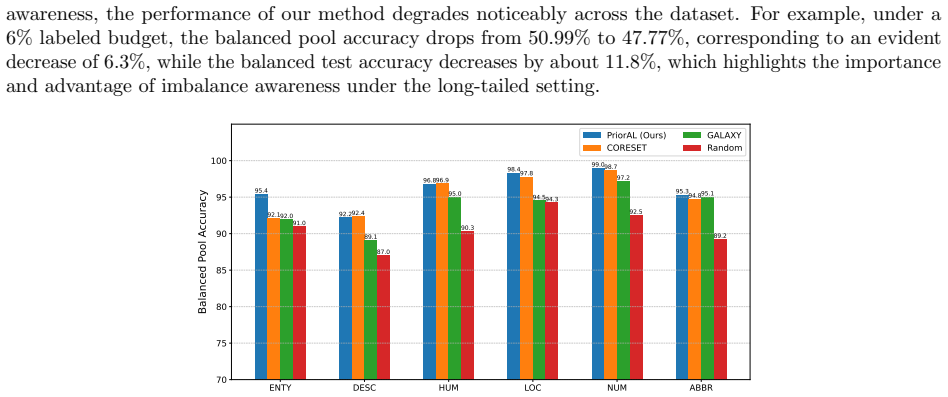
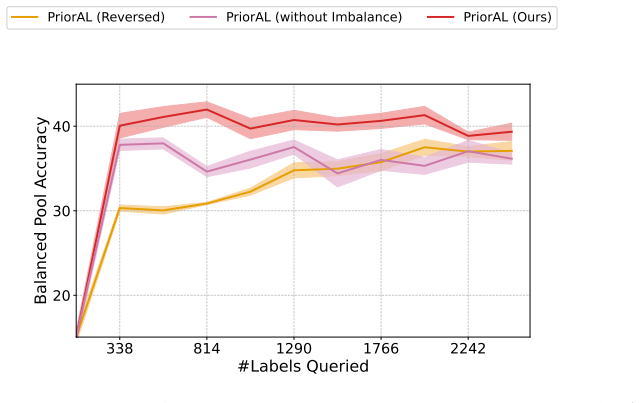
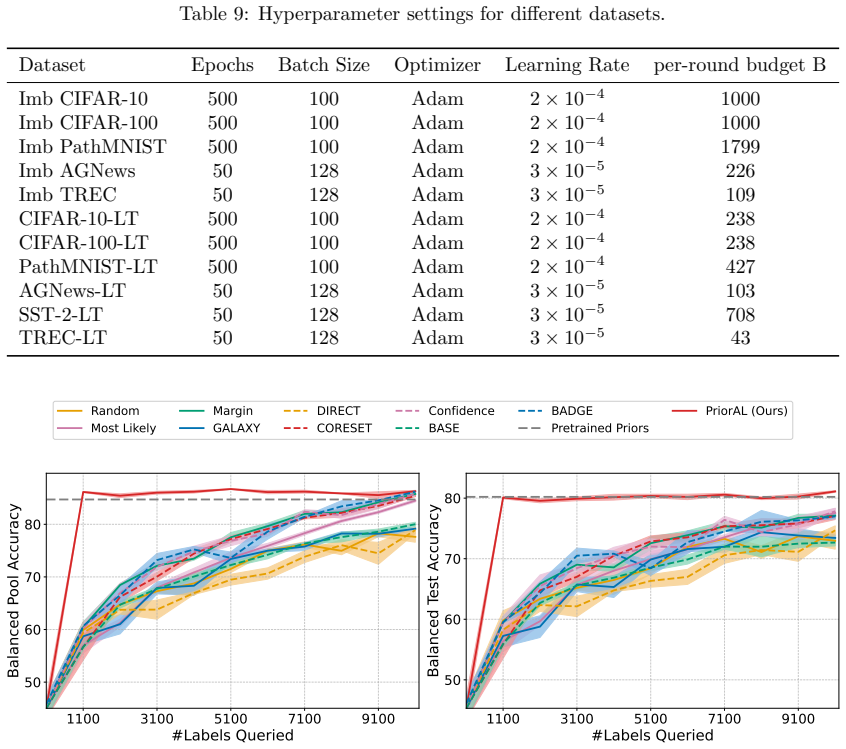
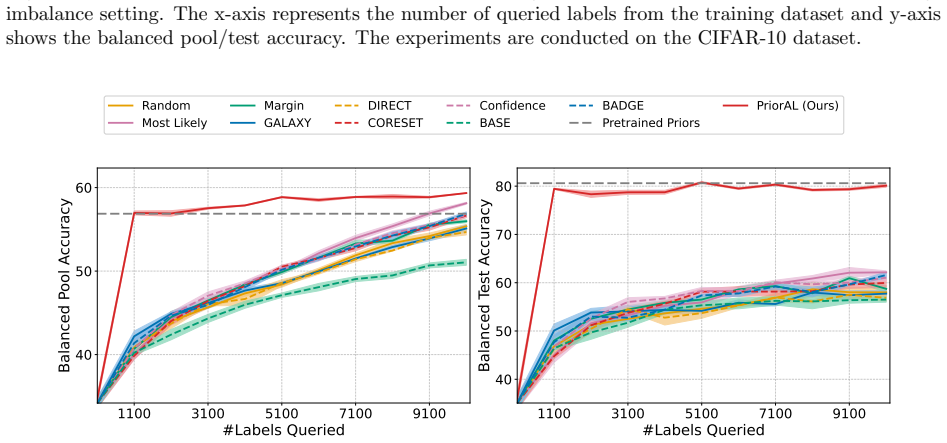
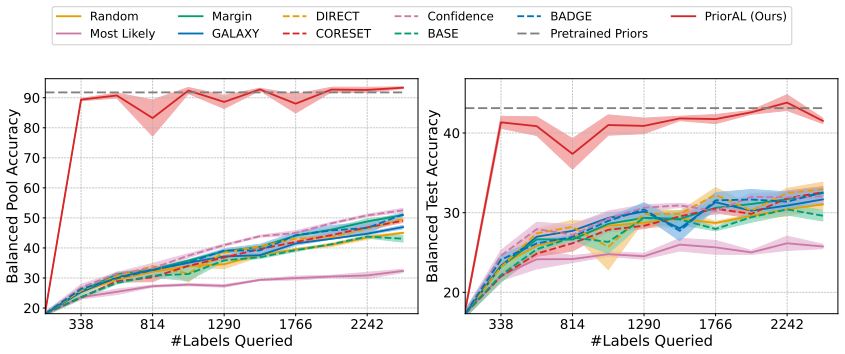
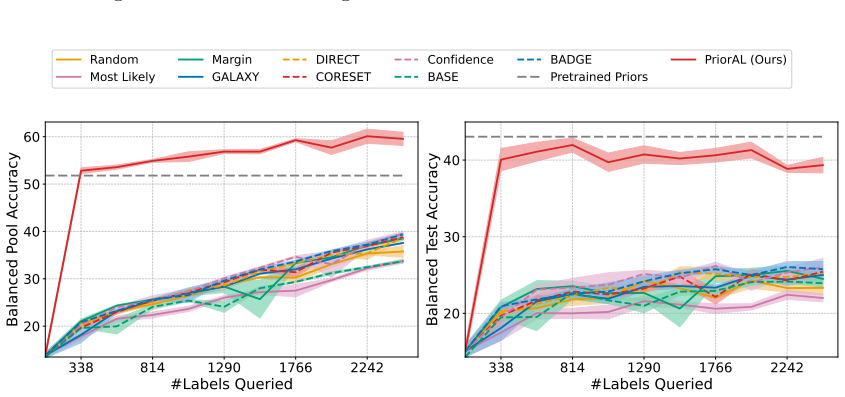
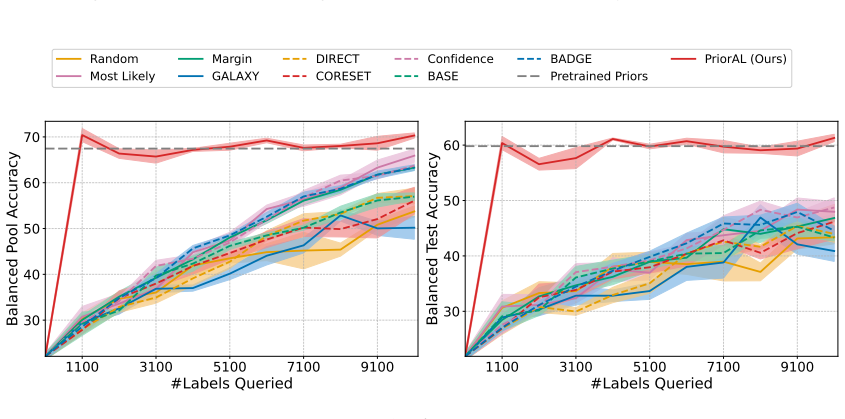
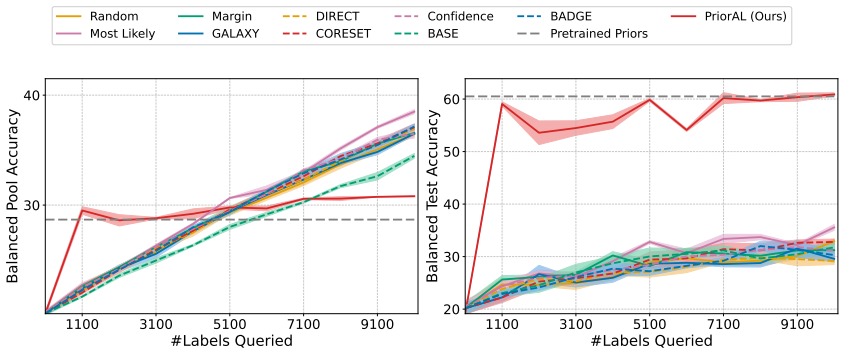
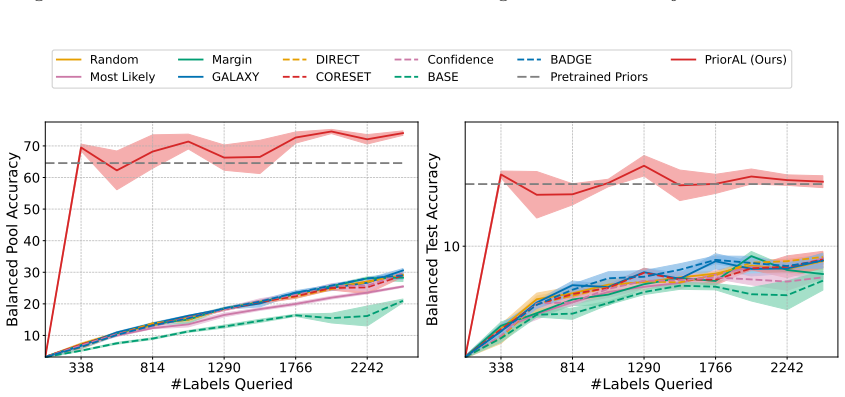
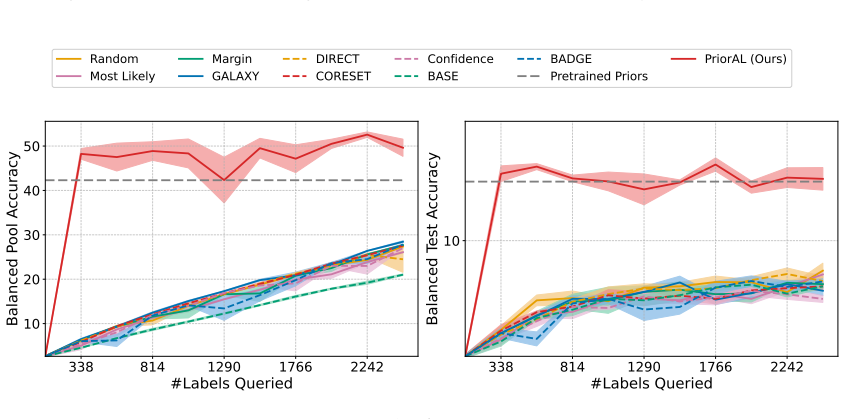
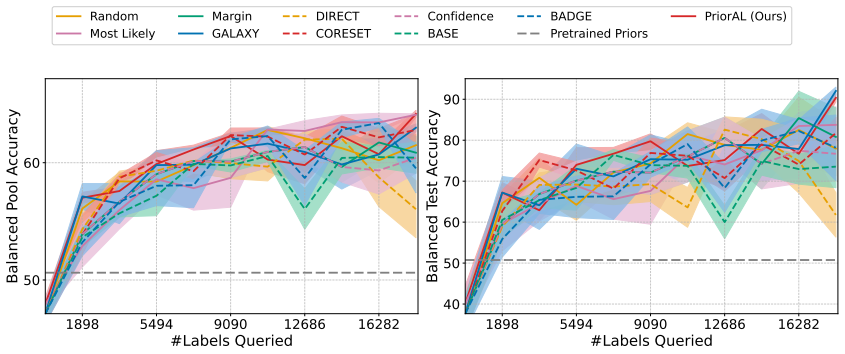
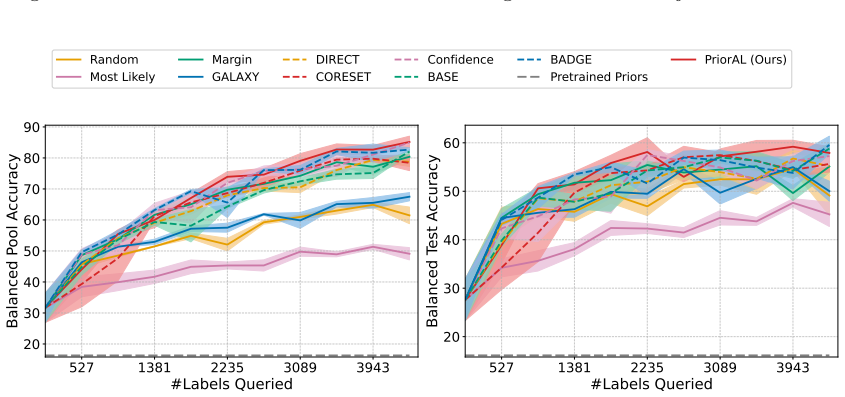
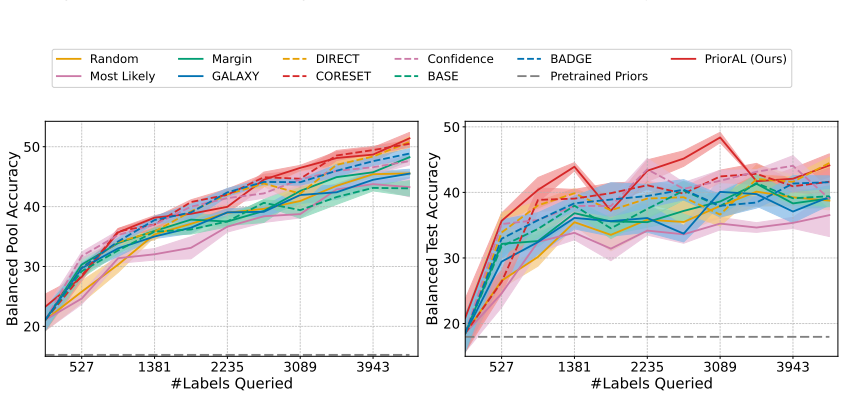
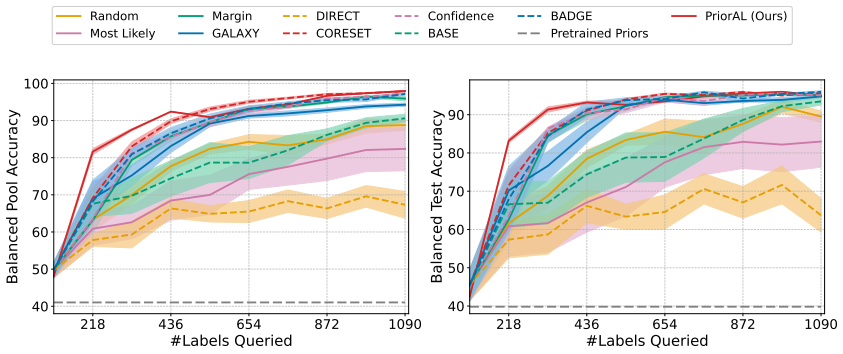
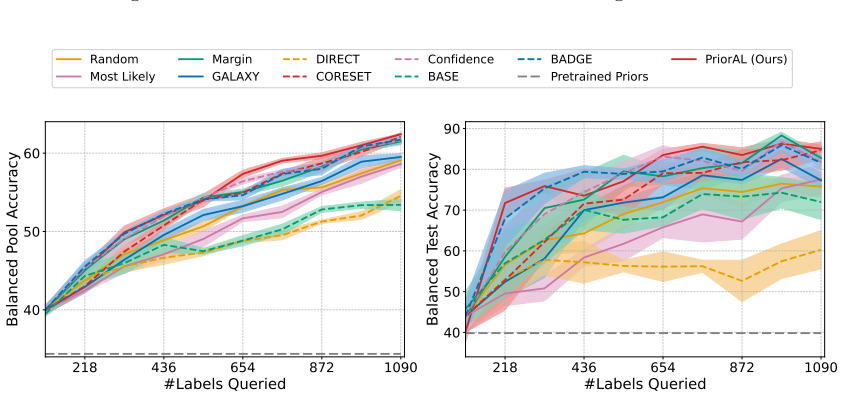
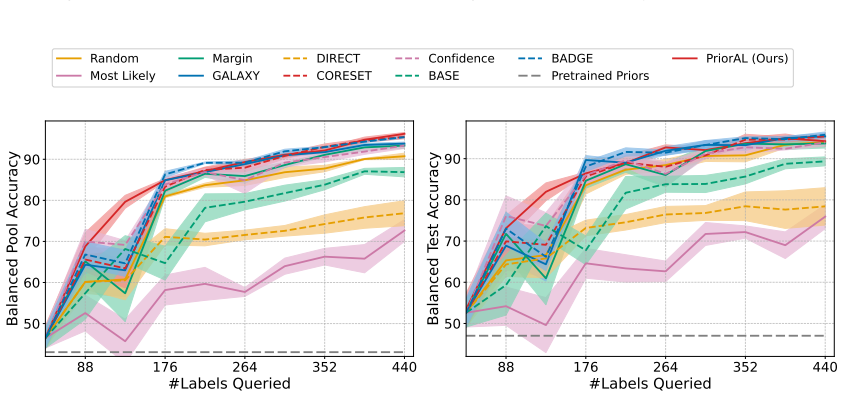
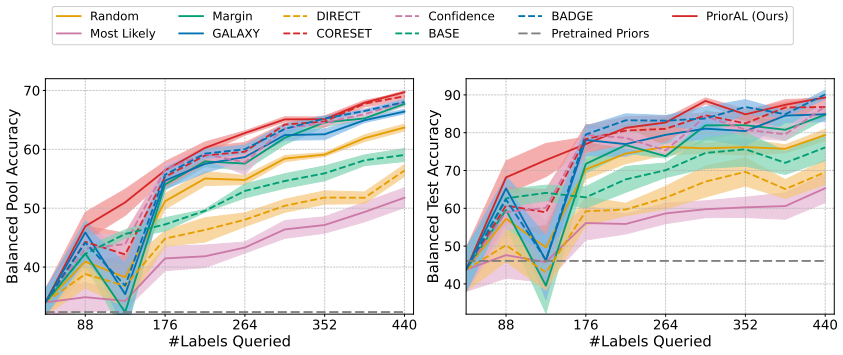
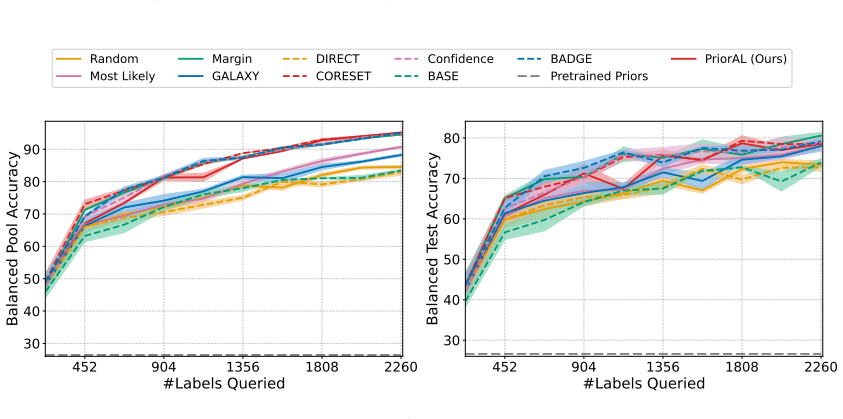
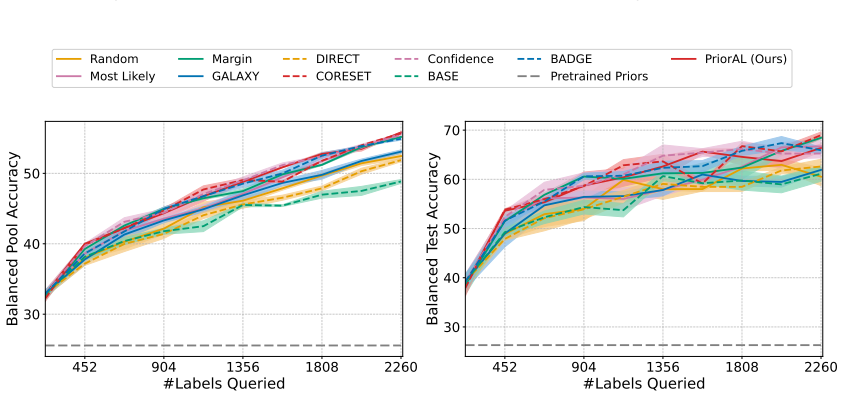
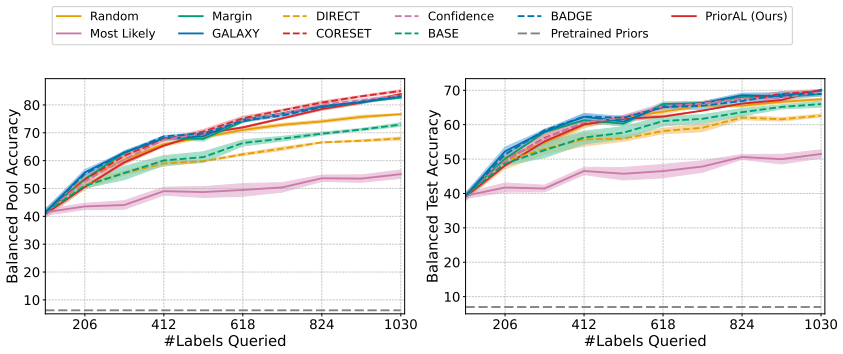
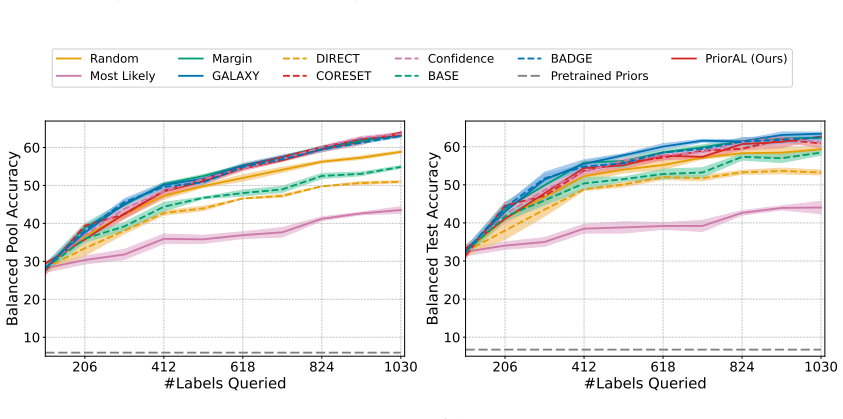
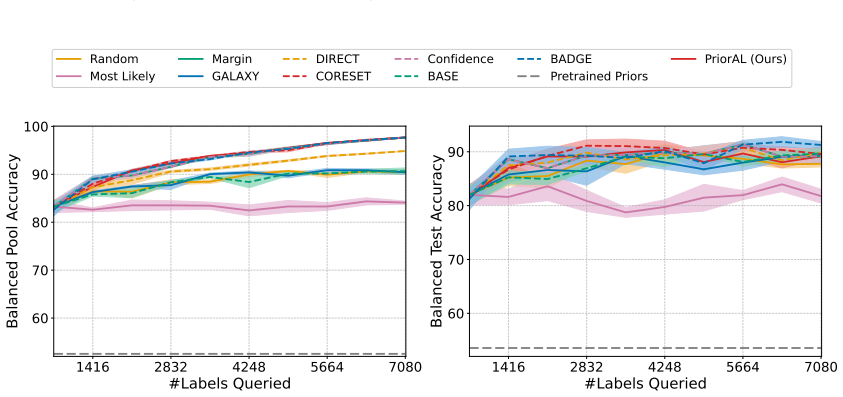
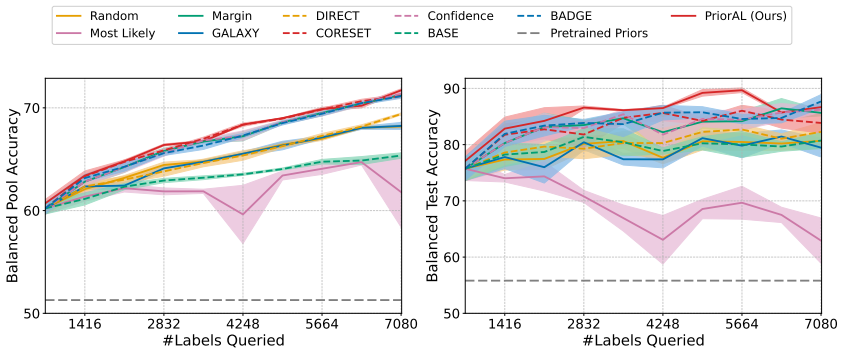
Leveraging foundation model priors, the algorithm enables imbalance-aware co-decisions between foundation model and small model to tackle noisy and imbalanced labels across various domains. It achieves substantial annotation savings over 50 percent compared to the best active learning baseline while preserving performance and robustness to label noise. The work introduces the first study to systematically explore active learning under the dual challenges of label noise and class imbalance across image and text domains.
What carries the argument
imbalance-aware co-decision mechanism between foundation model priors and a small model for selecting informative and balanced samples
If this is right
- Annotation requirements drop by over 50 percent on imbalanced datasets while accuracy holds.
- Performance on minority classes is maintained despite label noise.
- The framework applies across both image and text classification tasks.
- Active learning becomes more robust to noisy labels through the co-decision process.
Where Pith is reading between the lines
- The co-decision pattern could extend to other settings like semi-supervised learning where similar imbalance and noise issues arise.
- Testing with different foundation model sizes might show whether annotation savings increase with stronger priors.
- The method could be adapted to additional data modalities that already have foundation model support.
Load-bearing premise
Foundation model priors remain reliable for identifying informative and balanced samples even when labels are noisy and classes are imbalanced.
What would settle it
If experiments on standard imbalanced noisy datasets show annotation savings falling below 30 percent or clear drops in minority-class accuracy relative to baselines, the central claim would not hold.
Figures
read the original abstract
Real-world datasets across image and text domains are often characterized by skewed class distributions and noisy annotations, which jointly degrade model performance, particularly on minority classes. Among existing solutions, active learning offers an effective and efficient paradigm by selectively querying the most informative and balanced samples for annotation. We propose an innovative active learning framework that mitigates class imbalance and selects the most informative samples to annotate. Leveraging foundation model priors, our algorithm enables imbalance-aware co-decisions between foundation model and small model to tackle noisy and imbalanced labels across various domains. We introduce the first study to systematically explore active learning under the dual challenges of label noise and class imbalance across image and text domains. Extensive experiments on imbalanced datasets demonstrate that our method achieves substantial annotation savings-over 50% compared to the best active learning baseline-while preserving performance and robustness to label noise.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an active learning framework that leverages foundation model priors to enable imbalance-aware co-decisions between a foundation model and a small model. This is intended to select informative and balanced samples for annotation, addressing the dual challenges of class imbalance and label noise in image and text domains. The central empirical claim is that the method achieves over 50% annotation savings relative to the best active learning baseline while preserving performance and demonstrating robustness to label noise; it also positions the work as the first systematic study of active learning under these combined conditions.
Significance. If the empirical results and algorithmic details hold under rigorous validation, the work could be significant for practical machine learning pipelines that must contend with skewed real-world data distributions and annotation noise. Demonstrating substantial annotation cost reductions via foundation-model-assisted selection would be relevant to domains where labeling is expensive.
major comments (3)
- [Abstract] Abstract: The claim of 'substantial annotation savings-over 50% compared to the best active learning baseline' is stated without any description of the experimental protocol, datasets, baselines, metrics, number of runs, or error bars. This absence renders the central performance claim impossible to assess or reproduce from the provided text.
- [Abstract] Abstract (proposed framework paragraph): The 'imbalance-aware co-decisions between foundation model and small model' mechanism is described only at a high level with no equations, algorithm steps, pseudocode, or derivation showing how the co-decision rule is computed or why it produces the claimed savings and noise robustness. This is load-bearing for evaluating the proposed algorithm's correctness and novelty.
- [Abstract] Abstract: The assertion that the work constitutes 'the first study to systematically explore active learning under the dual challenges of label noise and class imbalance across image and text domains' is made without any citations to or discussion of prior active learning literature on imbalance or noise, making it impossible to verify the claimed novelty gap.
minor comments (1)
- [Abstract] The abstract repeatedly refers to 'our algorithm' and 'our method' without assigning a name or acronym to the proposed framework, which reduces clarity when the contribution is discussed.
Simulated Author's Rebuttal
We thank the referee for their detailed comments, which help clarify how the abstract can better support the manuscript's claims. We address each point below and will revise the abstract in the next version to incorporate additional context while preserving its conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of 'substantial annotation savings-over 50% compared to the best active learning baseline' is stated without any description of the experimental protocol, datasets, baselines, metrics, number of runs, or error bars. This absence renders the central performance claim impossible to assess or reproduce from the provided text.
Authors: We agree that the abstract would be strengthened by briefly indicating the experimental context supporting the savings claim. In the revised version, we will add a short clause such as 'evaluated across multiple imbalanced image and text datasets over 5 independent runs with error bars' to the results sentence. Full protocol details, including specific datasets, baselines, metrics, and statistical reporting, are already provided in Sections 4 and 5 of the manuscript. revision: yes
-
Referee: [Abstract] Abstract (proposed framework paragraph): The 'imbalance-aware co-decisions between foundation model and small model' mechanism is described only at a high level with no equations, algorithm steps, pseudocode, or derivation showing how the co-decision rule is computed or why it produces the claimed savings and noise robustness. This is load-bearing for evaluating the proposed algorithm's correctness and novelty.
Authors: The abstract intentionally summarizes the framework at a high level, consistent with standard practice. The full description of the imbalance-aware co-decision rule, including the mathematical formulation combining foundation-model priors with the small model's uncertainty estimates, the balancing adjustment, and the selection algorithm, appears with equations and pseudocode in Section 3. We will revise the abstract's framework paragraph to include one additional sentence outlining the high-level computation of the co-decision (e.g., how the foundation model prior modulates selection probabilities for minority classes while accounting for noise), thereby providing more insight without exceeding abstract length limits. revision: yes
-
Referee: [Abstract] Abstract: The assertion that the work constitutes 'the first study to systematically explore active learning under the dual challenges of label noise and class imbalance across image and text domains' is made without any citations to or discussion of prior active learning literature on imbalance or noise, making it impossible to verify the claimed novelty gap.
Authors: We will revise the abstract to include citations to representative prior works on active learning under class imbalance and under label noise (separately), and briefly note that none jointly address both challenges across image and text domains with foundation-model priors. This will allow readers to assess the novelty claim directly. The main text already contains a related-work discussion; we will ensure the abstract points to it. revision: yes
Circularity Check
No significant circularity: empirical framework with no derivation chain exposed
full rationale
The paper presents an empirical active learning method that leverages foundation model priors for imbalance-aware sample selection under noisy labels. No equations, proofs, or first-principles derivations appear in the abstract or described framework; performance claims rest on experimental results rather than any mathematical reduction that could be checked for equivalence to inputs by construction. The work is therefore self-contained as an algorithmic proposal validated externally via benchmarks, with no load-bearing steps that reduce to self-definition, fitted parameters renamed as predictions, or self-citation chains.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Foundation models supply useful priors that enable effective imbalance-aware co-decisions with small models under label noise.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Jordan T Ash, Chicheng Zhang, Akshay Krishnamurthy, John Langford, and Alekh Agarwal. Deep batch active learning by diverse, uncertain gradient lower bounds.arXiv preprint arXiv:1906.03671,
-
[3]
An experimental design framework for label-efficient supervised finetuning of large language models
Gantavya Bhatt, Yifang Chen, Arnav Das, Jifan Zhang, Sang Truong, Stephen Mussmann, Yinglun Zhu, Jeff Bilmes, Simon Du, Kevin Jamieson, et al. An experimental design framework for label-efficient supervised finetuning of large language models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 6549–6560,
2024
-
[4]
Yifang Chen, Karthik Sankararaman, Alessandro Lazaric, Matteo Pirotta, Dmytro Karamshuk, Qifan Wang, Karishma Mandyam, Sinong Wang, and Han Fang. Improved adaptive algorithm for scalable active learning with weak labeler.arXiv preprint arXiv:2211.02233,
-
[5]
Adversarial Active Learning for Deep Networks: a Margin Based Approach
12 Melanie Ducoffe and Frederic Precioso. Adversarial active learning for deep networks: a margin based approach.arXiv preprint arXiv:1802.09841,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Active learning at the imagenet scale.arXiv preprint arXiv:2111.12880,
Zeyad Ali Sami Emam, Hong-Min Chu, Ping-Yeh Chiang, Wojciech Czaja, Richard Leapman, Micah Goldblum, and Tom Goldstein. Active learning at the imagenet scale.arXiv preprint arXiv:2111.12880,
-
[7]
Deep Active Learning over the Long Tail
Yonatan Geifman and Ran El-Yaniv. Deep active learning over the long tail.arXiv preprint arXiv:1711.00941,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Revisiting active learning in the era of vision foundation models.arXiv preprint arXiv:2401.14555,
Sanket Rajan Gupte, Josiah Aklilu, Jeffrey J Nirschl, and Serena Yeung-Levy. Revisiting active learning in the era of vision foundation models.arXiv preprint arXiv:2401.14555,
-
[9]
Neural active learning on heteroskedastic distributions.arXiv preprint arXiv:2211.00928,
Savya Khosla, Chew Kin Whye, Jordan T Ash, Cyril Zhang, Kenji Kawaguchi, and Alex Lamb. Neural active learning on heteroskedastic distributions.arXiv preprint arXiv:2211.00928,
-
[10]
Newsweeder: Learning to filter netnews
Ken Lang. Newsweeder: Learning to filter netnews. InMachine learning proceedings 1995, pages 331–339. Elsevier,
1995
-
[11]
Learning question classifiers
Xin Li and Dan Roth. Learning question classifiers. InCOLING 2002: The 19th International Conference on Computational Linguistics,
2002
-
[12]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Active Learning for Convolutional Neural Networks: A Core-Set Approach
Ozan Sener and Silvio Savarese. Active learning for convolutional neural networks: A core-set approach. arXiv preprint arXiv:1708.00489,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Recursive deep models for semantic compositionality over a sentiment treebank
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language processing, pages 1631–1642,
2013
-
[15]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ ee Lacroix, Baptiste Rozi` ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Transformers: State-of-the-art natural language processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, et al. Transformers: State-of-the-art natural language processing. InProceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations, pages 38–45,
2020
-
[17]
Cold-start active learning through self- supervised language modeling
Michelle Yuan, Hsuan-Tien Lin, and Jordan Lee Boyd-Graber. Cold-start active learning through self- supervised language modeling. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 7935–7948,
2020
-
[18]
Towards Multimodal Active Learning: Efficient Learning with Limited Paired Data
Jiancheng Zhang and Yinglun Zhu. Towards multimodal active learning: Efficient learning with limited paired data.arXiv preprint arXiv:2510.03247,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Jifan Zhang, Yifang Chen, Gregory Canal, Stephen Mussmann, Arnav M Das, Gantavya Bhatt, Yinglun Zhu, Jeffrey Bilmes, Simon Shaolei Du, Kevin Jamieson, et al. Labelbench: A comprehensive framework for benchmarking adaptive label-efficient learning.arXiv preprint arXiv:2306.09910, 2023a. Yifan Zhang, Bingyi Kang, Bryan Hooi, Shuicheng Yan, and Jiashi Feng. ...
-
[20]
In the image domain, Gupte et al
demonstrate that active learning can be effectively combined with large language models (LLMs) to guide data selection and improve LLM training. In the image domain, Gupte et al. (2024) further show that leveraging the rich representations learned by foundation models can substantially enhance active learning performance. More recently, Zhang and Zhu (202...
2024
-
[21]
In our setting, we assume the presence of a single annotator, the same assumption made in Nuggehalli et al
primarily aim to detect instances where the weak and strong oracle annotators diverge, enabling selective reliance on the strong annotator for such ambiguous samples. In our setting, we assume the presence of a single annotator, the same assumption made in Nuggehalli et al.. Building on this practically important and widely prevalent setting (Song et al.,...
2022
-
[22]
and PathMNIST (Yang et al., 2023)-as well as datasets in the text domain including 20NG (Lang, 1995), SST-2 (Socher et al.,
2023
-
[23]
The original forms of these datasets are roughly balanced across 10, 100, or 9 classes in the image domain, and across 20, 2, or 6 classes in the text domain
and Trec (Li and Roth, 2002). The original forms of these datasets are roughly balanced across 10, 100, or 9 classes in the image domain, and across 20, 2, or 6 classes in the text domain. Except the SST-2 dataset with only two classes, we generate the imbalanced datasets by merging a large number of classes into a single majority class. For example, give...
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.