ReAge3D: Re-Aging 3D Faces with View Consistency
Pith reviewed 2026-06-27 01:40 UTC · model grok-4.3
The pith
Re-aging 3D faces achieves detailed identity-preserving results by propagating 2D diffusion edits from a frontal pivot view to ensure multi-view consistency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Training a diffusion re-aging model on synthetic pairs and then using a Masked-DiffReaging process to reconstruct non-frontal views from a re-aged frontal pivot produces a consistent multi-view image set that supervises optimization of a highly detailed, identity-preserving 3D re-aged face representation.
What carries the argument
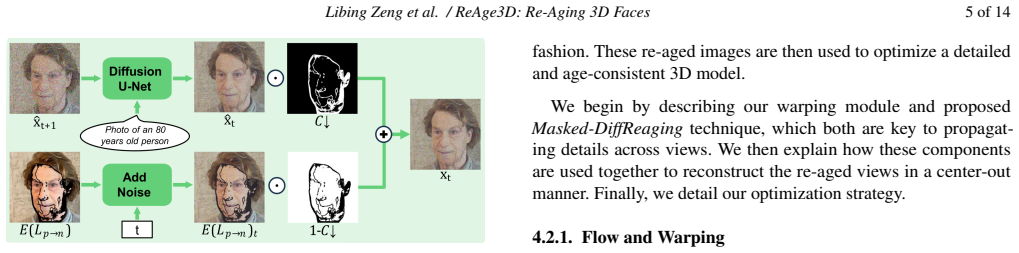
The Masked-DiffReaging process, which injects existing content at every step of the diffusion process to keep reconstructed regions coherent with already-edited pixels during center-out propagation.
If this is right
- Enables smooth, fine-grained control over age transformations in 3D face models.
- Outperforms existing 3D editing techniques both visually and quantitatively.
- Prevents over-smoothing of subtle age-related details that arise from view inconsistencies.
- Produces highly detailed and identity-preserving re-aged 3D representations.
Where Pith is reading between the lines
- The same propagation approach could extend to other facial attribute edits such as expression or lighting changes in 3D.
- Performance may improve further if the 2D model were retrained on real paired aging data instead of synthetic pairs.
- Consistent re-aged 3D outputs could support downstream tasks like age-progressed animation or virtual aging simulations.
Load-bearing premise
A 2D diffusion model trained only on synthetically generated image pairs will produce identity-preserving re-aging results that remain coherent when propagated across multiple views via warping and Masked-DiffReaging, allowing those views to reliably supervise 3D optimization.
What would settle it
Rendered novel views of the final 3D model would display visible blurring, identity changes, or mismatched age features relative to the re-aged input views.
Figures









read the original abstract
We present a novel framework for realistic and controllable 3D face re-aging which produces highly detailed, identity-preserving results. Existing 3D editing methods, while effective for coarse semantic changes, are not well suited for re-aging, as even small inconsistencies across re-aged 2D views can lead to over-smoothing of subtle but perceptually important age-related details. To address this challenge, we first introduce a 2D diffusion-based re-aging model, DiffReaging, trained on synthetically generated image pairs. We further propose a center-out editing propagation strategy that leverages this re-aging model to reconstruct multi-view-consistent re-aged images. Specifically, starting from a re-aged frontal pivot view, we reconstruct the remaining views through warping and our proposed Masked-DiffReaging process. By injecting existing content at every step of the diffusion process, Masked-DiffReaging ensures that the reconstructed regions remain coherent with existing pixels. The resulting consistent set of re-aged views supervises the optimization of the re-aged 3D representation. Our method outperforms existing 3D editing techniques both visually and quantitatively, enabling smooth, fine-grained control over age transformations in 3D face models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
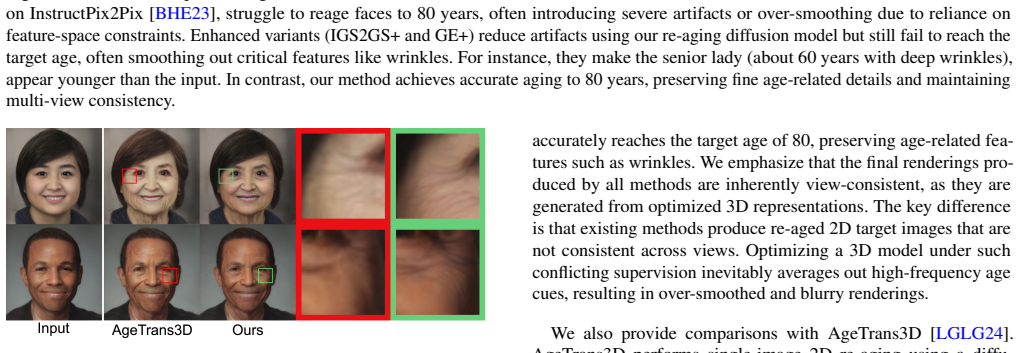
Summary. The paper presents ReAge3D, a framework for realistic and controllable 3D face re-aging. It introduces DiffReaging, a 2D diffusion model trained on synthetically generated image pairs, and a center-out editing propagation strategy that starts from a re-aged frontal view and uses warping plus Masked-DiffReaging (with content injection during diffusion) to produce multi-view consistent re-aged images. These images then supervise optimization of a re-aged 3D representation. The method claims visual and quantitative superiority over existing 3D editing techniques for fine-grained age control without over-smoothing.
Significance. If the central claims hold, the work would represent a meaningful advance in 3D face editing by solving the specific problem of view inconsistency in diffusion-based re-aging, which leads to loss of subtle age details. This could enable more practical applications in graphics, animation, and biometrics where identity-preserving, controllable 3D aging is needed.
major comments (2)
- [Abstract] Abstract: the central claim that DiffReaging trained exclusively on synthetic image pairs produces identity-preserving, view-coherent outputs that can supervise 3D optimization without over-smoothing is load-bearing, yet the abstract (and the provided description) gives no information on synthetic pair generation, real-data validation, or ablations showing that synthetic training captures aging variability; this directly affects whether the outperformance claim can be accepted.
- [Abstract] Masked-DiffReaging description: the mechanism of 'injecting existing content at every step' is presented as ensuring coherence, but without a precise definition of the mask schedule, injection strength, or quantitative analysis of drift in fine age details across propagated views, it is unclear whether the propagation step actually prevents the over-smoothing the paper seeks to avoid.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each point below and will revise the abstract accordingly to improve self-containment and clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that DiffReaging trained exclusively on synthetic image pairs produces identity-preserving, view-coherent outputs that can supervise 3D optimization without over-smoothing is load-bearing, yet the abstract (and the provided description) gives no information on synthetic pair generation, real-data validation, or ablations showing that synthetic training captures aging variability; this directly affects whether the outperformance claim can be accepted.
Authors: We agree that the abstract is too concise on these supporting elements. The full manuscript details the synthetic pair generation process, reports evaluations on real face data, and presents ablations on aging variability capture. We will revise the abstract to add a brief statement on the synthetic training approach and its validation to better ground the central claims. revision: yes
-
Referee: [Abstract] Masked-DiffReaging description: the mechanism of 'injecting existing content at every step' is presented as ensuring coherence, but without a precise definition of the mask schedule, injection strength, or quantitative analysis of drift in fine age details across propagated views, it is unclear whether the propagation step actually prevents the over-smoothing the paper seeks to avoid.
Authors: We agree that the abstract lacks sufficient precision on the Masked-DiffReaging parameters and analysis. The manuscript provides the mask schedule, injection strength, and quantitative drift metrics in the methods and experiments sections. We will revise the abstract to include a concise description of the injection mechanism and its role in preserving age details. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The provided abstract and description outline a pipeline of training DiffReaging on synthetic image pairs followed by a center-out warping and Masked-DiffReaging propagation to produce multi-view supervision for 3D optimization. No equations, fitted parameters, or self-citations are exhibited that reduce any claimed prediction or result to its own inputs by construction. The method introduces new components (synthetic training, masking injection) whose outputs are not tautologically equivalent to the inputs, satisfying the criteria for an independent derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ACM Transactions on Graphics (TOG) , volume=
Production-ready face re-aging for visual effects , author=. ACM Transactions on Graphics (TOG) , volume=. 2022 , publisher=
2022
-
[2]
International Conference on Learning Representations (ICLR) , year=
Adam: A method for stochastic optimization , author=. International Conference on Learning Representations (ICLR) , year=
-
[3]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[4]
, author=
3D Gaussian Splatting for Real-Time Radiance Field Rendering. , author=. ACM Trans. Graph. , volume=
-
[5]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Instruct-nerf2nerf: Editing 3d scenes with instructions , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[6]
2024 , url =
Vachha, Cyrus and Haque, Ayaan , title =. 2024 , url =
2024
-
[7]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Gaussianeditor: Swift and controllable 3d editing with gaussian splatting , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[8]
arXiv preprint arXiv:2404.18929 , year=
Dge: Direct gaussian 3d editing by consistent multi-view editing , author=. arXiv preprint arXiv:2404.18929 , year=
-
[9]
arXiv preprint arXiv:2403.08733 , year=
GaussCtrl: multi-view consistent text-driven 3D Gaussian splatting editing , author=. arXiv preprint arXiv:2403.08733 , year=
-
[10]
arXiv preprint arXiv:2407.02034 , year=
TrAME: Trajectory-Anchored Multi-View Editing for Text-Guided 3D Gaussian Splatting Manipulation , author=. arXiv preprint arXiv:2407.02034 , year=
-
[11]
European Conference on Computer Vision , pages=
View-consistent 3d editing with gaussian splatting , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[12]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Instructpix2pix: Learning to follow image editing instructions , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[13]
arXiv preprint arXiv:2406.17396 , year=
SyncNoise: Geometrically Consistent Noise Prediction for Text-based 3D Scene Editing , author=. arXiv preprint arXiv:2406.17396 , year=
-
[14]
2021 , eprint=
High-Resolution Image Synthesis with Latent Diffusion Models , author=. 2021 , eprint=
2021
-
[15]
ACM Trans
Alaluf, Yuval and Patashnik, Or and Cohen-Or, Daniel , title =. ACM Trans. Graph. , issue_date =. 2021 , articleno =
2021
-
[16]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Repaint: Inpainting using denoising diffusion probabilistic models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[17]
International journal of computer vision , volume=
Bisenet v2: Bilateral network with guided aggregation for real-time semantic segmentation , author=. International journal of computer vision , volume=. 2021 , publisher=
2021
-
[18]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
A style-based generator architecture for generative adversarial networks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[19]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Analyzing and improving the image quality of stylegan , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[20]
Proceedings of the 27th annual conference on Computer graphics and interactive techniques , pages=
Acquiring the reflectance field of a human face , author=. Proceedings of the 27th annual conference on Computer graphics and interactive techniques , pages=
-
[21]
Computer graphics forum , volume=
Realistic Facial Age Transformation with 3D Uplifting , author=. Computer graphics forum , volume=. 2024 , organization=
2024
-
[22]
Journal of Visual Languages & Computing , volume=
Computational methods for modeling facial aging: A survey , author=. Journal of Visual Languages & Computing , volume=. 2009 , publisher=
2009
-
[23]
EURASIP Journal on Image and Video Processing , volume=
Age estimation via face images: a survey , author=. EURASIP Journal on Image and Video Processing , volume=. 2018 , publisher=
2018
-
[24]
Image and Vision Computing , volume=
Modeling of facial aging and kinship: A survey , author=. Image and Vision Computing , volume=. 2018 , publisher=
2018
-
[25]
Neurocomputing , volume=
Age progression: Current technologies and applications , author=. Neurocomputing , volume=. 2016 , publisher=
2016
-
[26]
Advances in neural information processing systems , volume=
Generative adversarial nets , author=. Advances in neural information processing systems , volume=
-
[27]
Proceedings of the IEEE international conference on computer vision , pages=
Unpaired image-to-image translation using cycle-consistent adversarial networks , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[28]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Illumination-aware age progression , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[29]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Automatic face aging in videos via deep reinforcement learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[30]
arXiv preprint arXiv:2311.11642 , year=
Video face re-aging: Toward temporally consistent face re-aging , author=. arXiv preprint arXiv:2311.11642 , year=
-
[31]
arXiv preprint arXiv:2408.15922 , year=
DiffAge3D: Diffusion-based 3D-aware Face Aging , author=. arXiv preprint arXiv:2408.15922 , year=
-
[32]
ICML , year =
Learning Transferable Visual Models from Natural Language Supervision , author =. ICML , year =
-
[33]
and Wang, P
Shi, Y. and Wang, P. and Ye, J. and Mai, L. and Li, K. and Yang, X. , journal =
-
[34]
Jiatao Gu and Lingjie Liu and Peng Wang and Christian Theobalt , booktitle =
-
[35]
and Lin, C
Liu, Y. and Lin, C. and Zeng, Z. and Long, X. and Liu, L. and Komura, T. and Wang, W. , journal =
-
[36]
Liu, Minghua and Shi, Ruoxi and Chen, Linghao and Zhang, Zhuoyang and Xu, Chao and Wei, Xinyue and Chen, Hansheng and Zeng, Chong and Gu, Jiayuan and Su, Hao , journal =
-
[37]
Zheng, Chuanxia and Vedaldi, Andrea , journal =
-
[38]
IEEE Transactions on Image Processing (TIP) , volume=
Sface: Sigmoid-constrained hypersphere loss for robust face recognition , author=. IEEE Transactions on Image Processing (TIP) , volume=. 2021 , publisher=
2021
-
[39]
Yu Deng and Jiaolong Yang and Jianfeng Xiang and Xin Tong , booktitle =
-
[40]
Yang Xue and Yuheng Li and Krishna Kumar Singh and Yong Jae Lee , booktitle =
-
[41]
arXiv preprint arXiv:2208.05751 , year =
Jingbo Zhang and Xiaoyu Li and Ziyu Wan and Can Wang and Jing Liao , title =. arXiv preprint arXiv:2208.05751 , year =
-
[42]
Yang Hong and Bo Peng and Haiyao Xiao and Ligang Liu and Juyong Zhang , booktitle =
-
[43]
NERF: Representing Scenes as Neural Radiance Fields for View Synthesis , author =. Proc. ECCV , year =
-
[44]
Neural Computing and Applications , volume =
AW-GAN: Face Aging and Rejuvenation Using Attention with Wavelet GAN , author =. Neural Computing and Applications , volume =
-
[45]
ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages =
Look Globally, Age Locally: Face Aging with an Attention Mechanism , author =. ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages =. 2020 , publisher =
2020
-
[46]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
Disentangled Lifespan Face Synthesis , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
-
[47]
Global and Local Consistent Age Generative Adversarial Networks , author =. Proc. ICPR , pages =. 2018 , publisher =
2018
-
[48]
European Conference on Computer Vision (ECCV) , year=
Hierarchical face aging through disentangled latent characteristics , author=. European Conference on Computer Vision (ECCV) , year=
-
[49]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Efficient geometry-aware 3D generative adversarial networks , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[50]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[51]
Custom Structure Preservation in Face Aging , author =. Proc. ECCV , year =
-
[52]
A Style-Based Generator Architecture for Generative Adversarial Networks , year=
Karras, Tero and Laine, Samuli and Aila, Timo , booktitle=. A Style-Based Generator Architecture for Generative Adversarial Networks , year=
-
[53]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
MaskGAN: Towards Diverse and Interactive Facial Image Manipulation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=. 2020 , organization=
2020
-
[54]
Analyzing and Improving the Image Quality of
Tero Karras and Samuli Laine and Miika Aittala and Janne Hellsten and Jaakko Lehtinen and Timo Aila , booktitle =. Analyzing and Improving the Image Quality of
-
[55]
Proceedings of the IEEE International Conference on Computer Vision (ICCV) , pages=
S2GAN: Share Aging Factors Across Ages and Share Aging Trends Among Individuals , author=. Proceedings of the IEEE International Conference on Computer Vision (ICCV) , pages=
-
[56]
arXiv preprint arXiv:2010.02502 , year=
Denoising diffusion implicit models , author=. arXiv preprint arXiv:2010.02502 , year=
Pith/arXiv arXiv 2010
-
[57]
arXiv preprint arXiv:2207.12598 , year=
Classifier-free diffusion guidance , author=. arXiv preprint arXiv:2207.12598 , year=
-
[58]
Advances in Neural Information Processing Systems , pages=
Generative Adversarial Nets , author=. Advances in Neural Information Processing Systems , pages=
-
[59]
ECCV , pages=
Lifespan age transformation synthesis , author=. ECCV , pages=
-
[60]
and Wonka, Peter , title =
Abdal, Rameen and Zhu, Peihao and Mitra, Niloy J. and Wonka, Peter , title =. ACM Transactions on Graphics , articleno =. 2021 , issue_date =
2021
-
[61]
arXiv preprint arXiv:2004.02546 , year=
GANSpace: Discovering Interpretable GAN Controls , author=. arXiv preprint arXiv:2004.02546 , year=
arXiv 2004
-
[62]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Attribute-aware face aging with wavelet-based generative adversarial networks , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[63]
Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI) , pages=
Dual Conditional GANs for Face Aging and Rejuvenation , author=. Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI) , pages=
-
[64]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Interpreting the latent space of GANs for semantic face editing , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[65]
arXiv preprint arXiv:2304.08465 , year =
Masactrl: Tuning-free Mutual Self-Attention Control for Consistent Image Synthesis and Editing , author =. arXiv preprint arXiv:2304.08465 , year =
-
[66]
arXiv preprint arXiv:2312.06193 , year =
DisControlFace: Disentangled Control for Personalized Facial Image Editing , author =. arXiv preprint arXiv:2312.06193 , year =
-
[67]
2023 , eprint=
FSGS: Real-Time Few-Shot View Synthesis using Gaussian Splatting , author=. 2023 , eprint=
2023
-
[68]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Diffusion Models Beat GANs on Image Synthesis , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[69]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Null-Text Inversion for Editing Real Images using Guided Diffusion Models , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[70]
arXiv preprint arXiv:2307.04725 , year =
Animatediff: Animate Your Personalized Text-to-Image Diffusion Models Without Specific Tuning , author =. arXiv preprint arXiv:2307.04725 , year =
-
[71]
Proceedings of the IEEE/CVF International Conference on Computer Vision , year=
Zero-1-to-3: Zero-shot one image to 3d object , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , year=
-
[72]
Proceedings of the IEEE/CVF International Conference on Computer Vision , year=
Adding conditional control to text-to-image diffusion models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , year=
-
[73]
Rasmus Rothe and Radu Timofte and Luc Van Gool , booktitle =
-
[74]
arXiv preprint arXiv:2303.12326 , year =
Make Encoder Great Again in 3D GAN Inversion Through Geometry and Occlusion-Aware Encoding , author =. arXiv preprint arXiv:2303.12326 , year =
-
[75]
Bhattarai and Matthias Nießner and Artem Sevastopolsky , journal =
Ananta R. Bhattarai and Matthias Nießner and Artem Sevastopolsky , journal =
-
[76]
arXiv preprint arXiv:2208.01626 , year=
Prompt-to-Prompt Image Editing with Cross Attention Control , author=. arXiv preprint arXiv:2208.01626 , year=
-
[77]
Proceedings of the 34th British Machine Vision Conference (BMVC) , year=
Face Aging via Diffusion-Based Editing , author=. Proceedings of the 34th British Machine Vision Conference (BMVC) , year=
-
[78]
arXiv preprint arXiv:2011.12799 , year=
StyleSpace Analysis: Disentangled Controls for StyleGAN Image Generation , author=. arXiv preprint arXiv:2011.12799 , year=
arXiv 2011
-
[79]
ACM Transactions on Graphics (TOG) , volume=
Only a Matter of Style: Age Transformation Using a Style-Based Regression Model , author=. ACM Transactions on Graphics (TOG) , volume=
-
[80]
arXiv preprint arXiv:2106.09685 , year=
LoRA: Low-Rank Adaptation of Large Language Models , author=. arXiv preprint arXiv:2106.09685 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.