AdaWeather: Adaptively Mixing Probabilistic Weather Forecasts with Logarithmic Regret
Pith reviewed 2026-06-28 15:53 UTC · model grok-4.3
The pith
AdaWeather adaptively mixes probabilistic forecasts to achieve logarithmic regret against the best static mixture in hindsight.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
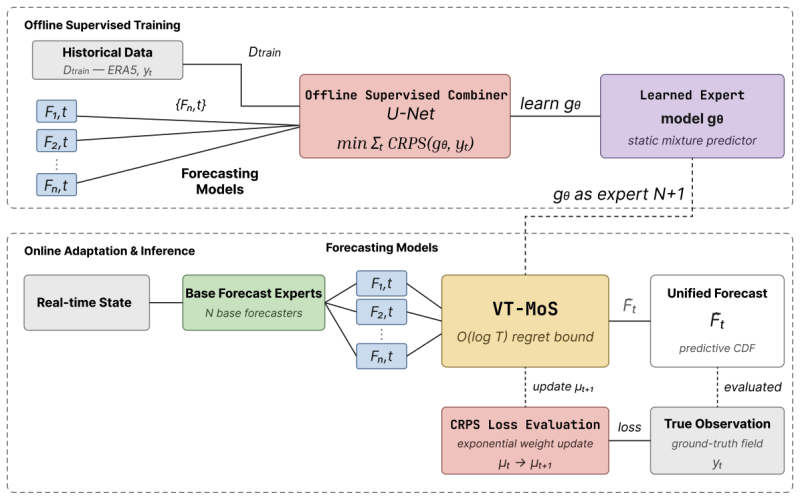
AdaWeather is an adaptive framework that combines many probabilistic forecasts using both machine learning and mixture-of-experts methods; its analysis shows logarithmic regret with respect to the best static mixture of experts in hindsight rather than merely the best single expert.
What carries the argument
The adaptive weighting procedure that extends prediction-with-expert-advice techniques to produce logarithmic regret against the best fixed convex combination of input forecasts.
If this is right
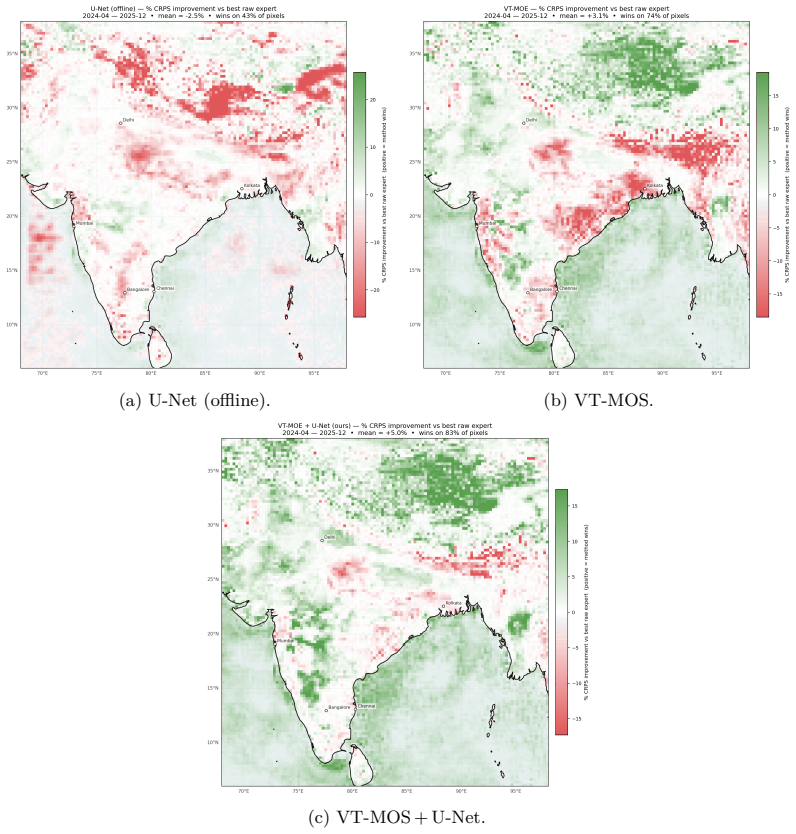
- Combined forecasts can improve on every individual input model across varying conditions.
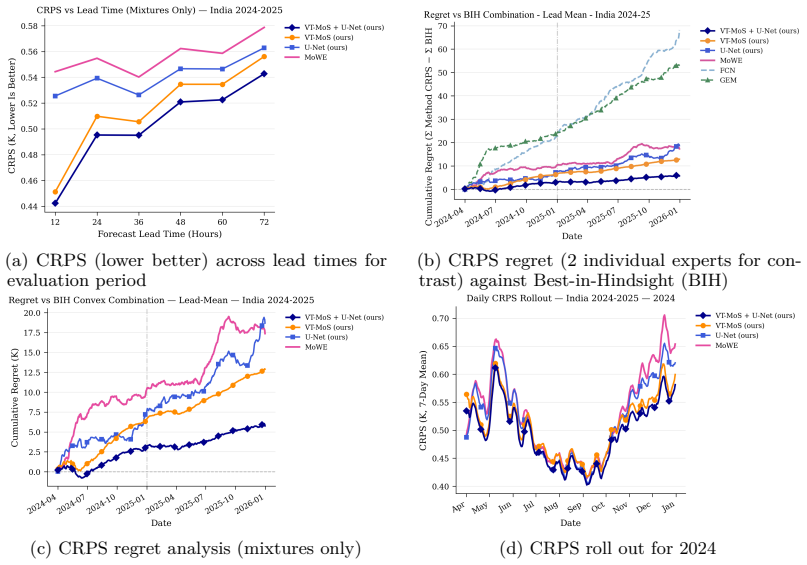
- The method supplies a regret guarantee that grows only logarithmically with the number of time steps.
- Temperature forecasts produced by the mixture show measurable gains over both single models and prior combination techniques.
- The same adaptive scheme can be applied to any collection of well-calibrated probabilistic forecasts whose accuracies differ by context.
Where Pith is reading between the lines
- The logarithmic regret bound may support stable long-horizon operation in automated forecasting pipelines.
- Similar adaptive mixing could be tested on other variables such as precipitation or wind speed where context dependence is also strong.
- The framework suggests a route to combine numerical weather prediction outputs with machine-learning models without committing to one or the other in advance.
Load-bearing premise
Relative performance among the input forecasts varies sufficiently with context that adaptive reweighting produces consistent gains while the forecasts stay well calibrated under mixing.
What would settle it
A large-scale weather dataset on which the adaptive method incurs linear (not logarithmic) regret or fails to beat the best static mixture chosen in hindsight.
Figures

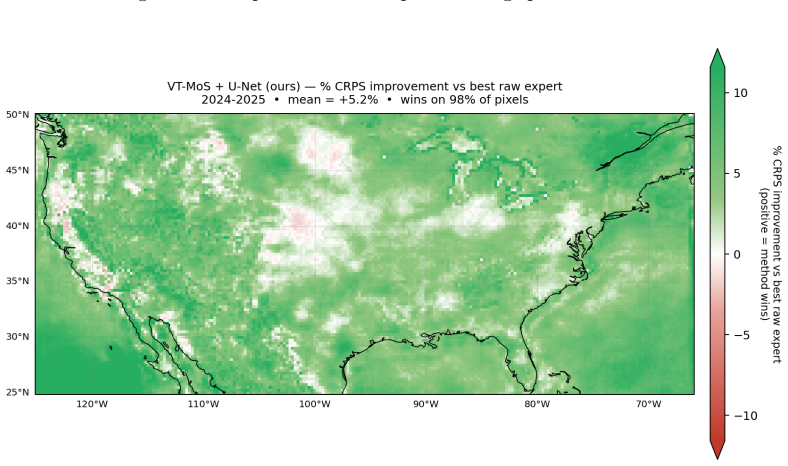
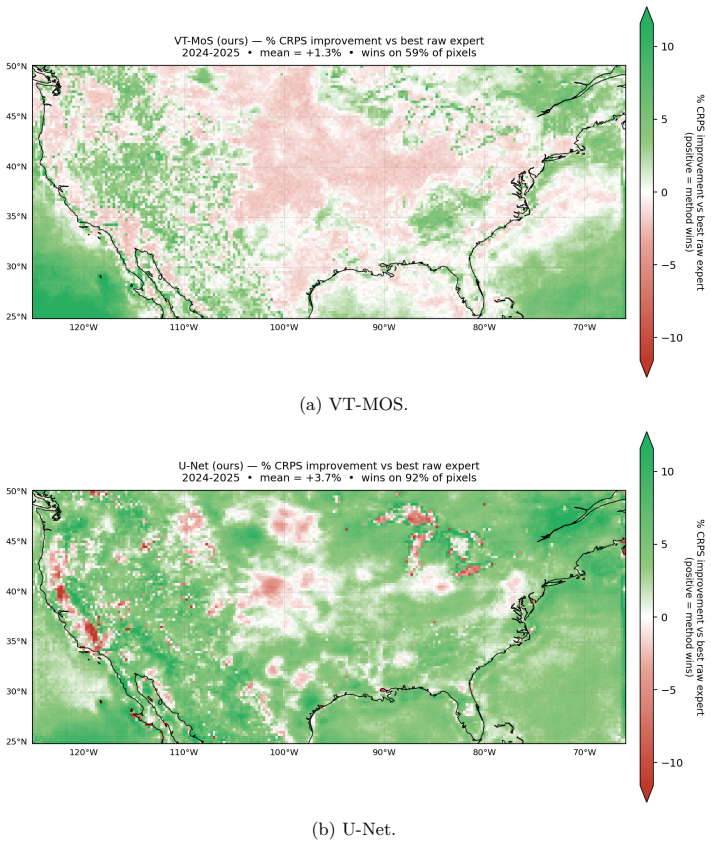
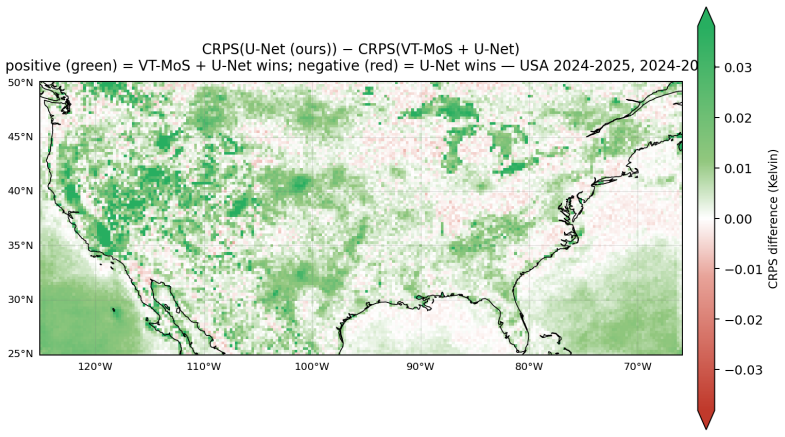
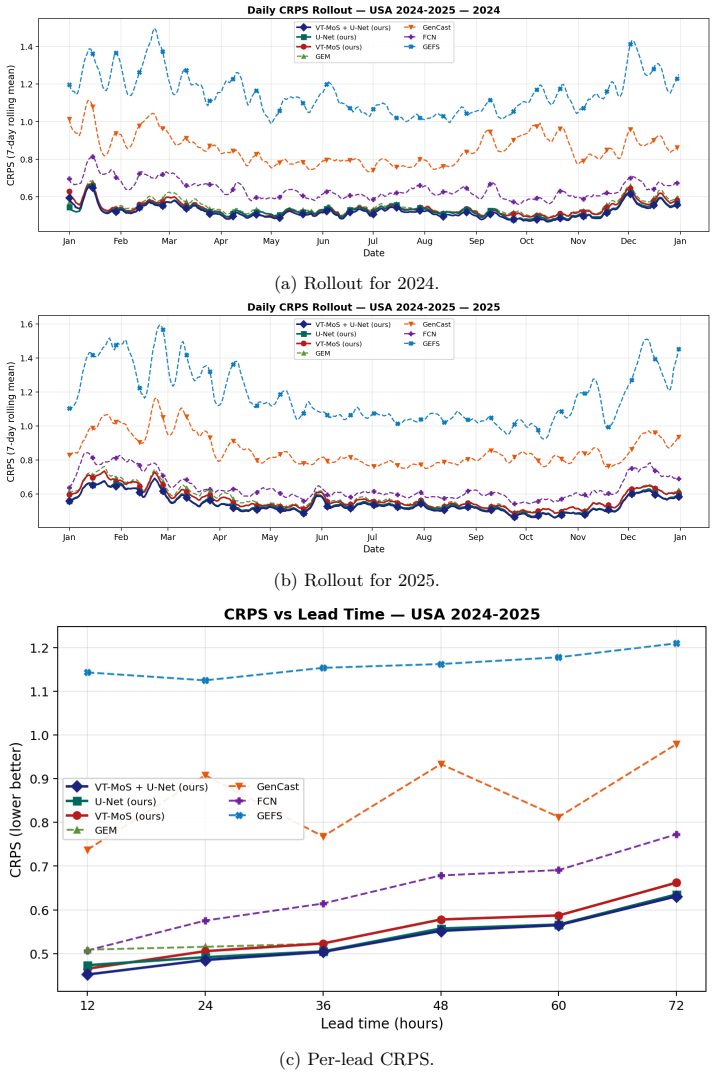
read the original abstract
Recent advances in machine learning have produced probabilistic weather forecasting models comparable to state-of-the-art numerical weather predictors. But no model consistently dominates spatio-temporally, and relative performance is highly context-dependent. This motivates adaptive methods for combining multiple forecasts to obtain improvements and robustness. While combined forecasts have been proposed in the literature, these are achieved either through supervised learning or through prediction with expert advice methods. We introduce AdaWeather, an adaptive framework that combines many probabilistic forecasts using both machine learning as well as mixture of experts to arrive at a unified improved probabilistic forecast. While traditional expert methods develop the regret bounds with respect to the best single expert in hindsight, we extend the algorithm and analysis to show our method has logarithmic regret compared to the best static mixture of experts in hindsight. Empirically, we focus on forecasting temperature, and observe improvements over existing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents AdaWeather, a framework that adaptively combines probabilistic weather forecasts from multiple models using a combination of machine learning and mixture-of-experts techniques. The key theoretical contribution is an extension of online learning algorithms to achieve logarithmic regret bounds with respect to the best static convex combination of the input forecasts in hindsight, rather than the single best expert. The empirical evaluation focuses on temperature forecasting and reports improvements over existing methods.
Significance. If the logarithmic regret bound holds, this work provides a principled online learning method for combining forecasts with guarantees against the best fixed mixture, which is a stronger benchmark than the usual single best expert. This has potential significance for improving the robustness of probabilistic weather predictions in a domain where relative model performance is context-dependent.
minor comments (2)
- [Abstract] The abstract states the O(log T) regret claim against the best static mixture but supplies no derivation steps, assumptions, or loss-function details, making it difficult to assess the extension from standard Hedge-style analysis without reading the body.
- The empirical section reports improvements on temperature forecasting but lacks details on the number of input forecasts, the exact form of the probabilistic mixture (e.g., weighted densities vs. parameter averaging), and any statistical significance testing of the gains.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work and for recommending minor revision. We appreciate the recognition that logarithmic regret relative to the best static mixture provides a stronger benchmark than the single best expert.
Circularity Check
No significant circularity; derivation extends standard online learning results
full rationale
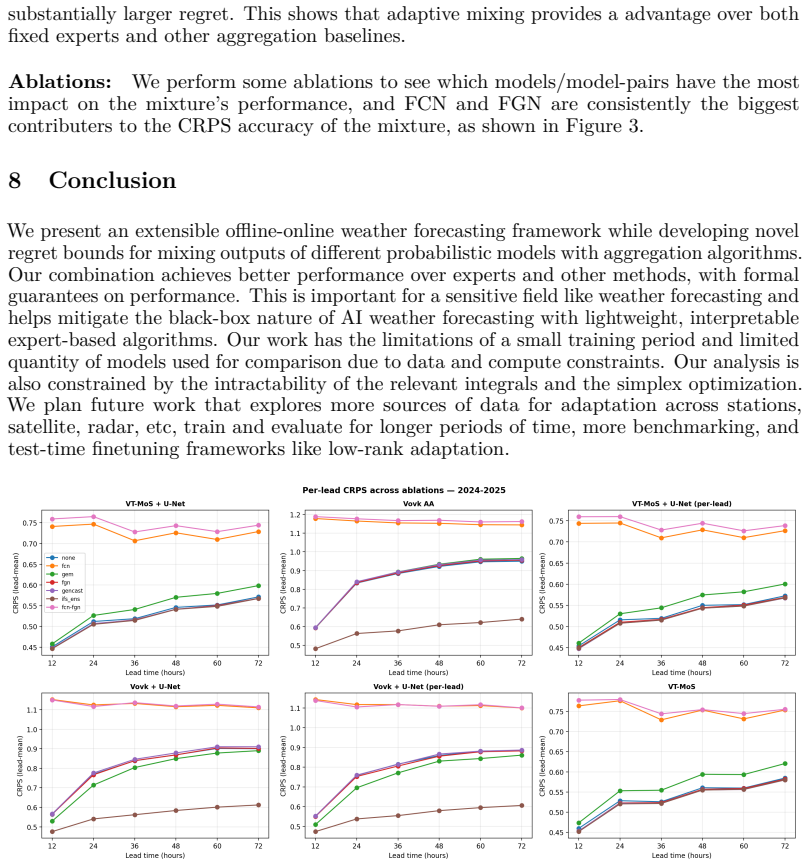
The paper introduces AdaWeather as an adaptive mixture of probabilistic forecasts and claims an extension of prediction-with-expert-advice algorithms to obtain O(log T) regret against the best fixed convex combination of experts rather than the single best expert. The abstract explicitly positions this as an extension of traditional methods, with no equations, fitted parameters, or self-citations presented as load-bearing for the regret bound. No self-definitional steps, fitted-input predictions, or ansatz smuggling are detectable from the given material. The central claim therefore remains an independent algorithmic extension whose validity rests on the correctness of the analysis rather than on re-labeling of inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jaideep Pathak, Shashank Subramanian, Peter Harrington, Sanjeev Raja, Ashesh Chattopadhyay, Morteza Mardani, Thorsten Kurth, David Hall, Zongyi Li, Kamyar Azizzadenesheli, et al. Fourcastnet: A global data-driven high-resolution weather model using adaptive fourier neural operators.arXiv preprint arXiv:2202.11214, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Ac- curate medium-range global weather forecasting with 3D neural networks.Nature, 619(7970):533–538, 2023
Kaifeng Bi, Lingxi Xie, Hengheng Zhang, Xin Chen, Xiaotao Gu, and Qi Tian. Ac- curate medium-range global weather forecasting with 3D neural networks.Nature, 619(7970):533–538, 2023
2023
-
[3]
Learningskillfulmedium-rangeglobalweatherforecasting.Science, 382(6677):1416– 1421, 2023
Remi Lam, Alvaro Sanchez-Gonzalez, Matthew Willson, Peter Wirnsberger, Meire Fortunato, Ferran Alet, Suman Ravuri, Timo Ewalds, Zach Eaton-Rosen, Weihua Hu, etal. Learningskillfulmedium-rangeglobalweatherforecasting.Science, 382(6677):1416– 1421, 2023
2023
-
[4]
Simon Lang, Mihai Alexe, Mariana CA Clare, Christopher Roberts, Rilwan Adewoyin, Zied Ben Bouallègue, Matthew Chantry, Jesper Dramsch, Peter D Dueben, Sara Hahner, et al. Aifs-crps: ensemble forecasting using a model trained with a loss function based on the continuous ranked probability score.arXiv preprint arXiv:2412.15832, 2024
-
[5]
Andersson, Andrew El-Kadi, Dominic Masters, Timo Ewalds, Jacklynn Stott, Shakir Mohamed, Peter Battaglia, Remi Lam, and Matthew Willson
Ilan Price, Alvaro Sanchez-Gonzalez, Ferran Alet, Tom R. Andersson, Andrew El-Kadi, Dominic Masters, Timo Ewalds, Jacklynn Stott, Shakir Mohamed, Peter Battaglia, Remi Lam, and Matthew Willson. GenCast: Diffusion-based ensemble forecasting for medium-range weather.Nature, 2024
2024
-
[6]
Neural general circulation models for weather and climate.Nature, 2024
Dmitrii Kochkov, Janni Yuval, Ian Langmore, Peter Norgaard, Jamie Smith, Griffin Mooers, Milan Klöwer, James Lottes, Stephan Rasp, Peter Düben, et al. Neural general circulation models for weather and climate.Nature, 2024
2024
-
[7]
Gupta, and Aditya Grover
Tung Nguyen, Johannes Brandstetter, Ashish Kapoor, Jayesh K. Gupta, and Aditya Grover. ClimaX: A foundation model for weather and climate.Proceedings of the 40th International Conference on Machine Learning (ICML), 2023
2023
-
[8]
arXiv , author =:2405.13063 , file =
Cristian Bodnar, Wessel P. Bruinsma, Ana Lucic, Megan Stanley, Johannes Brandstetter, Patrick Garvan, Maik Riechert, Jonathan A. Weyn, Haiyu Dong, Anna Vaughan, et al. Aurora: A foundation model of the atmosphere.arXiv preprint arXiv:2405.13063, 2024
-
[9]
Tung Nguyen, Rohan Shah, Hritik Bansal, Troy Arcomano, Romit Maulik, Rao Kota- marthi, Ian Foster, Sandeep Madireddy, and Aditya Grover. Scaling transformer neural networks for skillful and reliable medium-range weather forecasting.arXiv preprint arXiv:2312.03876, 2024
-
[10]
WeatherBench 2: A benchmark for the next generation of data-driven global weather models.Journal of Advances in Modeling Earth Systems, 16(6), 2024
Stephan Rasp, Stephan Hoyer, Alexander Merose, Ian Langmore, Peter Battaglia, Tyler Russell, Alvaro Sanchez-Gonzalez, Vivian Yang, Rob Carver, Shreya Agrawal, et al. WeatherBench 2: A benchmark for the next generation of data-driven global weather models.Journal of Advances in Modeling Earth Systems, 16(6), 2024
2024
-
[11]
Mowe: A mixture of weather experts.arXiv preprint arXiv:2509.09052, 2025
Dibyajyoti Chakraborty, Romit Maulik, Peter Harrington, Dallas Foster, Moham- mad Amin Nabian, and Sanjay Choudhry. Mowe: A mixture of weather experts.arXiv preprint arXiv:2509.09052, 2025
-
[12]
Boosting weather forecast via generative superensemble.npj Climate and Atmospheric Science, 2025
Congyi Nai, Xi Chen, Shangshang Yang, Zimiu Xiao, and Baoxiang Pan. Boosting weather forecast via generative superensemble.npj Climate and Atmospheric Science, 2025
2025
-
[13]
Breaking silos: Adaptive model fusion unlocks better time series forecasting
ZhiningLiu, ZeYang, XiaoLin, RuizhongQiu, TianxinWei, YadaZhu, HendrikHamann, Jingrui He, and Hanghang Tong. Breaking silos: Adaptive model fusion unlocks better time series forecasting. InProceedings of the 42nd International Conference on Machine Learning (ICML), 2025
2025
-
[14]
The quiet revolution of numerical weather prediction.Nature, 525(7567):47–55, 2015
Peter Bauer, Alan Thorpe, and Gilbert Brunet. The quiet revolution of numerical weather prediction.Nature, 525(7567):47–55, 2015. 11
2015
-
[15]
Jacobs, Michael I
Robert A. Jacobs, Michael I. Jordan, Steven J. Nowlan, and Geoffrey E. Hinton. Adaptive mixtures of local experts.Neural Computation, 3(1):79–87, 1991
1991
-
[16]
Jordan and Robert A
Michael I. Jordan and Robert A. Jacobs. Hierarchical mixtures of experts and the EM algorithm.Neural Computation, 6(2):181–214, 1994
1994
-
[17]
Outrageously large neural networks: The sparsely-gated mixture- of-experts layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture- of-experts layer. InInternational Conference on Learning Representations (ICLR), 2017
2017
-
[18]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23:1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23:1–39, 2022
2022
-
[19]
Spatial mixture-of-experts
Nikoli Dryden and Torsten Hoefler. Spatial mixture-of-experts. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[20]
VA-MoE: Variables-adaptive mixture of experts for incremental weather forecasting
Hao Chen, Han Tao, Guo Song, Jie Zhang, Yonghan Dong, Yunlong Yu, and Lei Bai. VA-MoE: Variables-adaptive mixture of experts for incremental weather forecasting. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[21]
Pérez-Ortiz, P
M. Pérez-Ortiz, P. A. Gutiérrez, P. Tino, C. Casanova-Mateo, and S. Salcedo-Sanz. A mixture of experts model for predicting persistent weather patterns. InProceedings of the International Joint Conference on Neural Networks (IJCNN), 2019
2019
-
[22]
Informer: Beyond efficient transformer for long sequence time-series forecasting
Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. Informer: Beyond efficient transformer for long sequence time-series forecasting. InProceedings of the AAAI conference on artificial intelligence, volume 35, pages 11106–11115, 2021
2021
-
[23]
Autoformer: Decomposition transformers with Auto-Correlation for long-term series forecasting.NeurIPS, 2021
Haixu Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. Autoformer: Decomposition transformers with Auto-Correlation for long-term series forecasting.NeurIPS, 2021
2021
-
[24]
FEDformer: Frequency enhanced decomposed transformer for long-term series forecasting.ICML, 2022
Tian Zhou, Ziqing Ma, Qingsong Wen, Xue Wang, Liang Sun, and Rong Jin. FEDformer: Frequency enhanced decomposed transformer for long-term series forecasting.ICML, 2022
2022
-
[25]
Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam
Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. A time series is worth 64 words: Long-term forecasting with transformers. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[26]
Oreshkin, Dmitri Carpov, Nicolas Chapados, and Yoshua Bengio
Boris N. Oreshkin, Dmitri Carpov, Nicolas Chapados, and Yoshua Bengio. N-BEATS: Neural basis expansion analysis for interpretable time series forecasting. InInternational Conference on Learning Representations (ICLR), 2020
2020
-
[27]
TimesNet: Temporal 2d-variation modeling for general time series analysis.ICLR, 2023
Haixu Wu, Tengge Hu, Yong Liu, Hang Zhou, Jianmin Wang, and Mingsheng Long. TimesNet: Temporal 2d-variation modeling for general time series analysis.ICLR, 2023
2023
-
[28]
OneNet: Enhancing time series forecasting models under concept drift by online ensembling
Yi-Fan Zhang, Qingsong Wen, Xue Wang, Weiqi Chen, Liang Sun, Zhang Zhang, Liang Wang, Rong Jin, and Tieniu Tan. OneNet: Enhancing time series forecasting models under concept drift by online ensembling. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[29]
Quang Pham, Chenghao Liu, Doyen Sahoo, and Steven C. H. Hoi. Learning fast and slow for online time series forecasting. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[30]
Fast and slow streams for online time series forecasting without information leakage
Ying-ye Ava Lau, Zhiwen Shao, and Dit-Yan Yeung. Fast and slow streams for online time series forecasting without information leakage. InInternational Conference on Learning Representations (ICLR), 2025. 12
2025
-
[31]
Reinforcement learning based dynamic model combination for time series forecasting
Yuwei Fu, Di Wu, and Benoit Boulet. Reinforcement learning based dynamic model combination for time series forecasting. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2022
2022
-
[32]
Online mixture of experts: No-regret learning for optimal collective decision-making
Larkin Liu and Jalal Etesami. Online mixture of experts: No-regret learning for optimal collective decision-making. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[33]
Aggregating strategies
Volodimir G Vovk. Aggregating strategies. InProceedings of the Third Annual Workshop on Computational Learning Theory, pages 371–386. Morgan Kaufmann, 1990
1990
-
[34]
Vladimir G. Vovk. A game of prediction with expert advice. InProceedings of the Eighth Annual Conference on Computational Learning Theory, pages 51–60. ACM, 1995
1995
-
[35]
Predicting a binary sequence almost as well as the optimal biased coin
Yoav Freund. Predicting a binary sequence almost as well as the optimal biased coin. Technical report, AT&T Research, 1996
1996
-
[36]
Nick Littlestone and Manfred K. Warmuth. The weighted majority algorithm.Informa- tion and Computation, 108(2):212–261, 1994
1994
-
[37]
Cambridge University Press, 2006
Nicolò Cesa-Bianchi and Gábor Lugosi.Prediction, Learning, and Games. Cambridge University Press, 2006
2006
-
[38]
Dynamic local regret for non-convex online forecasting
Sergul Aydore, Tianhao Zhu, and Dean Foster. Dynamic local regret for non-convex online forecasting. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[39]
Mark Herbster and Manfred K. Warmuth. Tracking the best expert.Machine Learning, 32(2):151–178, 1998
1998
-
[40]
Seshadhri
Elad Hazan and C. Seshadhri. Efficient learning algorithms for changing environments. InProceedings of the 26th International Conference on Machine Learning (ICML), 2009
2009
-
[41]
On- line optimization: Competing with dynamic comparators.Proceedings of the 18th International Conference on Artificial Intelligence and Statistics (AISTATS), 2015
Ali Jadbabaie, Alexander Rakhlin, Shahin Shahrampour, and Karthik Sridharan. On- line optimization: Competing with dynamic comparators.Proceedings of the 18th International Conference on Artificial Intelligence and Statistics (AISTATS), 2015
2015
-
[42]
Raftery, Anton H
Tilmann Gneiting, Adrian E. Raftery, Anton H. Westveld, and Tom Goldman. Calibrated probabilistic forecasting using ensemble model output statistics and minimum CRPS estimation.Monthly Weather Review, 133(5):1098–1118, 2005
2005
-
[43]
Raftery, Tilmann Gneiting, Fadoua Balabdaoui, and Michael Polakowski
Adrian E. Raftery, Tilmann Gneiting, Fadoua Balabdaoui, and Michael Polakowski. Using Bayesian model averaging to calibrate forecast ensembles.Monthly Weather Review, 133(5):1155–1174, 2005
2005
-
[44]
Tilmann Gneiting and Adrian E. Raftery. Strictly proper scoring rules, prediction, and estimation.Journal of the American Statistical Association, 102(477):359–378, 2007
2007
-
[45]
Cover and Erik Ordentlich
Thomas M. Cover and Erik Ordentlich. Universal portfolios with side information. IEEE Transactions on Information Theory, 42(2):348–363, 1996
1996
-
[46]
Vladimir V. V’yugin and Vladimir Trunov. Online aggregation of probability forecasts with confidence.arXiv preprint arXiv:2109.14309, 2021
-
[47]
David Haussler, Jyrki Kivinen, and Manfred K. Warmuth. Tight worst-case loss bounds for predicting with expert advice.Technical Report UCSC-CRL-94-36, University of California, Santa Cruz, 1994
1994
-
[48]
T. N. Krishnamurti, C. M. Kishtawal, Timothy E. LaRow, David R. Bachiochi, Zhan Zhang, C. Eric Williford, Sulochana Gadgil, and Sajani Surendran. Improved weather and seasonal climate forecasts from multimodel superensemble.Science, 285(5433):1548– 1550, 1999. 13
1999
-
[49]
DeepAR: Probabilistic forecasting with autoregressive recurrent networks.International Journal of Forecasting, 36(3):1181–1191, 2020
David Salinas, Valentin Flunkert, Jan Gasthaus, and Tim Januschowski. DeepAR: Probabilistic forecasting with autoregressive recurrent networks.International Journal of Forecasting, 36(3):1181–1191, 2020
2020
-
[50]
Reversible instance normalization for accurate time-series forecasting against distribution shift
Taesung Kim, Jinhee Kim, Yunwon Tae, Cheonbok Park, Jang-Ho Choi, and Jaegul Choo. Reversible instance normalization for accurate time-series forecasting against distribution shift. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[51]
SAN: Self-adaptive normalization for non-stationary time series forecasting
Zhiding Liu, Mingyue Cheng, Zhi Li, Zhenya Huang, Qi Liu, Yanyan Xie, and Enhong Chen. SAN: Self-adaptive normalization for non-stationary time series forecasting. Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[52]
McClelland, Bruce L
James L. McClelland, Bruce L. McNaughton, and Randall C. O’Reilly. Why there are complementary learning systems in the hippocampus and neocortex: Insights from the successes and failures of connectionist models of learning and memory.Psychological Review, 102(3):419–457, 1995
1995
-
[53]
McClelland
Dharshan Kumaran, Demis Hassabis, and James L. McClelland. What learning systems do intelligent agents need? complementary learning systems theory updated.Trends in Cognitive Sciences, 20(7):512–534, 2016
2016
-
[54]
Gradient episodic memory for continual learning
David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[55]
The problem of concept drift: Definitions and related work.Technical Report TCD-CS-2004-15, Trinity College Dublin, 2004
Alexey Tsymbal. The problem of concept drift: Definitions and related work.Technical Report TCD-CS-2004-15, Trinity College Dublin, 2004
2004
-
[56]
A survey on concept drift adaptation.ACM Computing Surveys, 46(4):1–37, 2014
João Gama, Indr˙ e Žliobait˙ e, Albert Bifet, Mykola Pechenizkiy, and Abdelhamid Bouchachia. A survey on concept drift adaptation.ACM Computing Surveys, 46(4):1–37, 2014
2014
-
[57]
Online learning and online convex optimization.Foundations and Trends in Machine Learning, 4(2):107–194, 2012
Shai Shalev-Shwartz. Online learning and online convex optimization.Foundations and Trends in Machine Learning, 4(2):107–194, 2012
2012
-
[58]
Foundations and Trends in Optimization, 2016
Elad Hazan.Introduction to Online Convex Optimization. Foundations and Trends in Optimization, 2016
2016
-
[59]
Distributional regression: CRPS-error bounds for model fitting, model selection and convex aggregation
Clément Dombry and Ahmed Zaoui. Distributional regression: CRPS-error bounds for model fitting, model selection and convex aggregation. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[60]
Contribution of expert aggregation to temperature prediction, part I.Preprint, 2025
Leo Pfitzner, Olivier Wintenberger, Olivier Mestre, and Marion Riverain. Contribution of expert aggregation to temperature prediction, part I.Preprint, 2025
2025
-
[61]
Helmbold, Robert E
Nicoló Cesa-Bianchi, Yoav Freund, David Haussler, David P. Helmbold, Robert E. Schapire, and Manfred K. Warmuth. How to use expert advice.J. ACM, 44(3):427–485, may 1997
1997
-
[62]
Ethan Perez, Florian Strub, Harm de Vries, Vincent Dumoulin, and Aaron Courville. FiLM: Visual reasoning with a general conditioning layer. September 2017. 14 Appendix Contents A Broader Impact 16 B Data 16 C Experiments 16 C.1 Training . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 C.2 Evaluation . . . . . . . . . . . . ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.